

维基百科上有一个词条:各国交通事故死亡率列表,数字非常触目惊心。很大部分都是因为分心驾驶导致的车祸事故。如果能使用人工智能技术帮助检测司机的分心状况,一旦发现司机出现分心的苗头,就立即提醒,车祸就可以避免了。幸运的是,有这么一些年轻人,利用深度学习开发并开源了司机分心驾驶检测的项目。真可谓功德无量。我们再一次见证了:科技改变人生,开源改变世界!
本文和项目是 Amey Athaley、Apoorva Jasti、Sadhana Koneni、Satya Naren Pachigolla、Jayant Raisinghani 在 Joydeep Ghosh 教授的指导下共同贡献的,请访问 GitHub 仓库 以获取我们的实现代码。
引言
开车是一项复杂的活儿,需要司机保持全神贯注。分心驾驶是指驾驶时注意力指向与正常驾驶不相关的活动,从而导致驾驶操作能力下降的一种现象。一些研究已经确定了注意力分散的三种主要类型:视觉干扰(司机的视线不在道路上)、手控分心(司机的手离开方向盘)和认知分心(司机的注意力不在开车任务上)。
美国国家公路交通安全管理局(The National Highway Traffic Safety Administration,NHTSA)报告称,2018 年有 36750 人死于车祸,其中 12% 是由于分心驾驶造成的。发短信是最让人分心的事情。收发短信会让你的视线离开道路长达 5 秒钟。以每小时 88.51 公里的时速行驶来计算,这 5 秒钟就相当于闭着眼睛行驶了整个足球场那么长。
现在,在美国有许多州都立法禁止开车时发短信、打电话和其他分心的事情。我们相信,计算机视觉技术可以加强政府的这些努力,以防止因分心驾驶造成的事故。我们的算法能够自动检测司机的分心迹象并向他们发出警报。为了防止因分心驾驶造成事故,我们设想将这类产品嵌入到汽车中。
数据
我们采用了 StateFarm 数据集,其中包含了安装在汽车中的行车记录仪拍摄的视频快照。训练集中大约有 个标记样本,这些样本在各类之间分布均匀,另外还有 个未标记的测试样本。图像分为 10 类:

图:训练数据中的样本图像
评估指标
在继续构建模型之前,重要的是选择正确指标来评估其性能。正确率(Accuracy)是我们想到的第一个指标。但是,正确率并不是分类问题的最佳指标。正确率只考虑预测的正确性,即预测的标签是否与真实的标签相同。但是,我们将司机的行为归类为分心的置信度(Confidence)对于评估模型的性能非常重要。值得庆幸的是,我们有一个指标可以捕捉到这一点:对数损失(Log Loss)。
对数损失(Logarithmic loss,与交叉熵有关)衡量分类模型的性能,其中预测输入是介于 0 和 1 之间的概率值。我们的机器学习模型的目标就是最小化这个值。一个理想的模型的对数损失应为 0,并且随着预测概率与实际标签的偏离而增加。因此,当实际观测标签为 1 时,预测概率为 0.3 将会导致较高的对数损失。
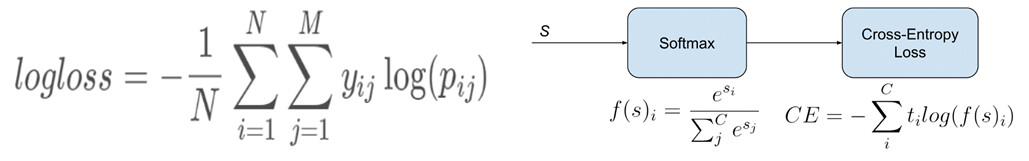
图:评估指标
数据泄露
在了解了需要实现的目标之后,我们从头开始构建卷积神经网络(Convolutional Neural Network,CNN)模型。我们添加了常见的可疑因素:卷积批量归一化、最大池化和密集层。结果表明,在 3 个轮数内,验证集的正确度为 99.6%,损失率为 0.014。
表:初始模型结果
嗯,我们考虑了一下,就意外地构建了世界上最好的卷积神经网络架构。因此,我们使用这个模型来预测未标记测试集的类。
关键时刻
我们更深入地研究了可能出问题的地方,发现我们的训练数据中,有多张同一个人在同一个类的图像,只不过是角度、高度或宽度略有变化而已。这就导致了数据泄露问题,因为相似的图像也在验证中,也就是说,模型接受的训练与它试图预测的信息基本相同。
数据泄露的解决方案
为了解决数据泄露的问题,我们根据人员 ID 来分割图像,而不是使用随机的 80-20 分割。
现在,当我们将模型与修改后的训练集和验证集进行拟合时,我们看到了更加真实的结果。我们实现了 1.76 的损失和 38.5 的正确率。
图:应对数据泄露后的模型拟合。
为了进一步提高结果,我们探索使用经过反复测试的深度神经网络架构。
译注:epoch 译为轮数,1 个 epoch 等于使用训练集中的全部样本训练一次。举个例子,训练集有 10000 个样本,batchsize=10,训练完整个样本集需要:1000 次 iteration,1 次 epoch。
迁移学习
迁移学习是一种将为相关任务开发的模型重用为第二个任务上的模型起点的方法。我们可以重用针对标准计算机视觉基准数据集开发的预训练模型的权重,如 ImageNet 图像识别挑战。一般来说,带有 softmax 激活函数的最后一层被替换,以适应我们数据集中类的数量。在大多数情况下,还会添加额外的层来针对特定任务定制解决方案。
考虑到开发用于图像分类的神经网络模型需要耗费大量的算力和时间资源,因此,这是一种流行的深度学习方法。此外,这些模型通常在数百万张图像上进行训练,这一点很有用,特别是当你的训练集很小的时候。这些模型架构中的大多数都是公认的赢家:VGG16、RESNET50、Xception 和 Mobilenet 模型,我们利用这些模型在 ImageNet 挑战中取得了非凡的成绩。
图像增强
图像增强的示例代码
由于我们的训练图像集只有大约 张图像,因此,我们希望从训练集中综合得到更多的图像,以确保模型不会发生过拟合,因为神经网络有数以百万计的参数。图像增强是一种通过改变宽度和/或高度、旋转和/或缩放等操作来从原始图像创建更多图像的技术。要了解关于图像增强的更多信息,请参阅这篇文章:How to Configure Image Data Augmentation in Keras(如何在 Keras 中配置图像数据增强)。

图:在我们的数据集中实现的图像增强的类型
对于我们的项目,图像增强还有一些额外的优势。有时,来自两个不同类的图像之间的差异可能非常微妙。在这种情况下,通过不同的角度对同一张图片进行多次观察将会有所帮助。如果你看下面的图片,你会发现它们几乎是相似的,但第一张图片是属于这个类:Talking on the Phone — Right(“用右手打电话”),而第二张图片则属于这个类“Hair and Makeup(“头发和化妆”)。

图:图像类混淆样本(1)打电话(2)头发和化妆
冗余层
为了使迁移学习的价值最大化,我们添加了一些冗余层(Extra layers)来帮助模型适应我们的用例,每层的用途如下:
全局平均池化(Global average pooling) 层只保留每个 patch 中值的平均值。
Dropout 层有助于控制过拟合,因为它会丢弃一部分参数。(特别提示:尝试不同的 Dropout 值是个好主意)
批归一化(Batch normalization) 层对将下一层的输入进行归一化,从而使训练更快、更具弹性。
密集(Dense) 层是具有特定激活函数的规则全连接层。
需要训练哪些层?
在进行迁移学习时,要解决的第一个问题是,我们是应该只训练添加到现有架构中的冗余层呢,还是应该训练所有层?当然,我们从使用 ImageNet 权重开始,只训练新层,因为要训练的参数数量较少,模型训练速度将会更快。我们看到,验证集的正确率在历经 25 个轮数后稳定在 。但是,通过训练所有层的话,我们就能够得到 的正确率。因此,我们决定继续进行所有层的训练。
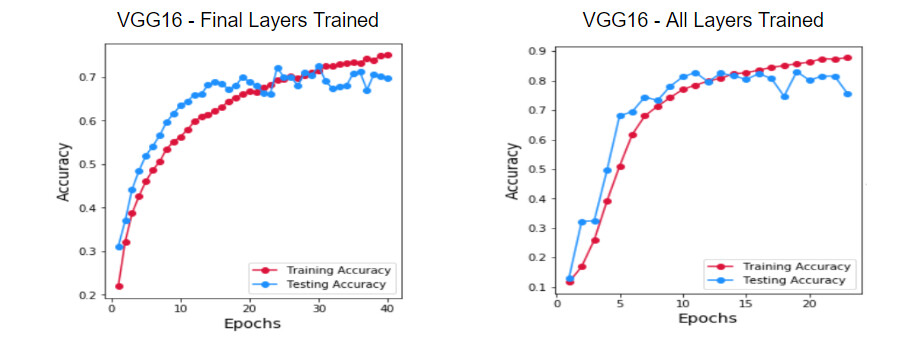
图:最终训练层与所有训练层的模型正确率的比较
使用哪个优化器?
优化器通过对参数的目标函数 w.r.t. 的梯度的相反方向上更新参数,使通过模型参数进行参数化的目标函数最小化。要了解有关不同优化器如何工作的更多信息,可以参考这个博客:An overview of gradient descent optimization(梯度下降优化综述)。
深度学习领域中最流行的算法是 ADAM,它结合了 SGD 和 RMSProp 算法。对于大多数问题,它始终比其他优化器的表现得更好。然而,在我们的案例中,当 SGD 正在逐渐学习时,Adam 表现出不稳定的下降模式。通过文献调研,我们发现,在少数情况下,SGD 优于 Adam,是因为 SGD 具有更好的泛化(Generalizes)。(请参阅此论文:The Marginal Value of Adaptive Gradient Methods in Machine Learning)。由于 SGD 给出了稳定的结果,因此我们将其用于所有的模型。
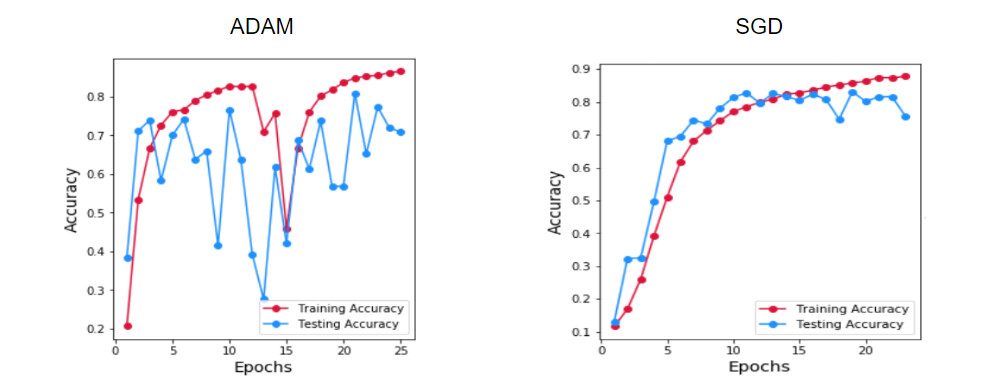
图:使用(1)Adam(2)SGD 跨轮数的正确率
使用哪种架构?
我们用在 ImageNet 数据集上训练得到的权重,即预训练的权重,尝试了多种迁移学习模型。
VGG16
VGG16 模型有 16 层。它主要采用卷积技术以及零填充、Dropout、最大池化和平坦化(Flattening)。
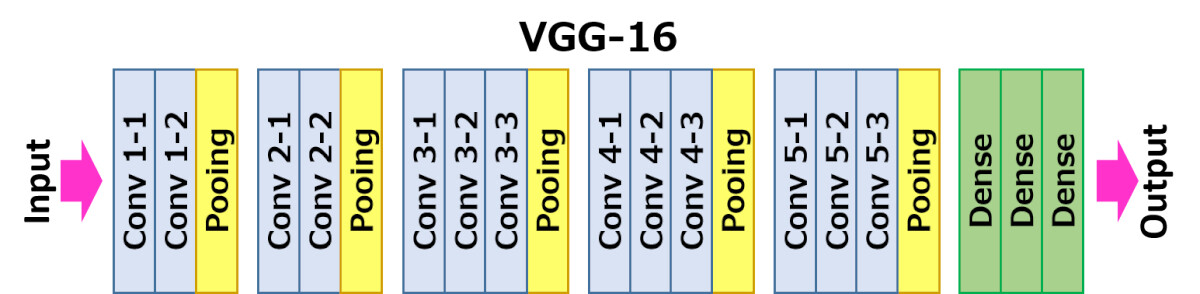
图:VGG16 架构
RESNET50
RESNET50 是 VGG16 的扩展,有 50 层。针对较深层次网路难以训练的问题,引入了参考层输入的“shortcut connections”前馈神经网络。
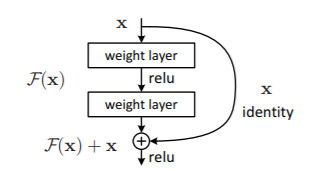
图:残差学习(Residual learning):一个构建块
创建残差网络(RESNET)的目的是获得层次更深的网络,而创建 Xception 的目的是为了通过引入深度可分离( Depthwise Separable Convolution)的卷积来获得更广泛的网络。通过将标准卷积层分解为深度卷积(Depthwise convolution)和逐点卷积(Pointwise convolutions),计算量显著减少。由于多个过滤器处于同一级别上,因此模型的性能也有所提高。
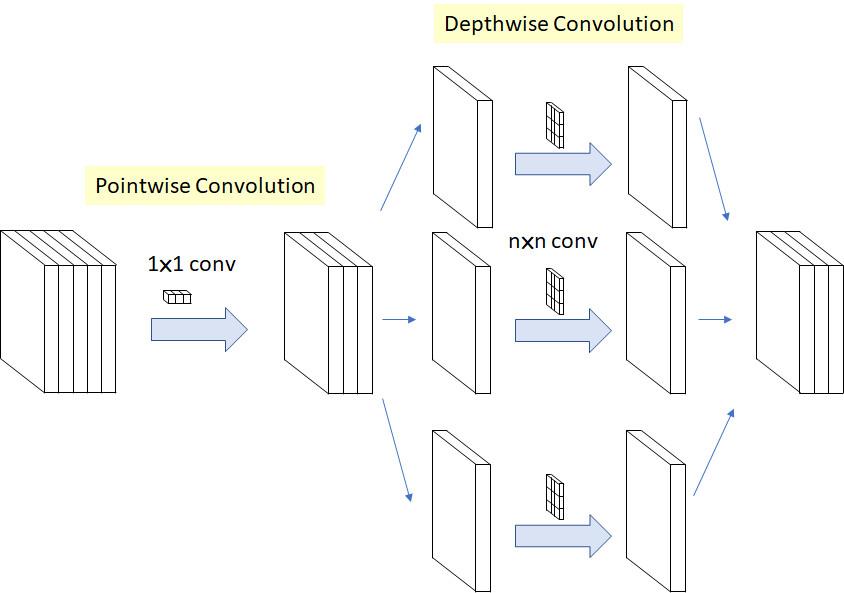
图:改进的深度可分离卷积在 Xception 的应用
MobileNet
MobileNet 是 Google 为基于移动的视觉应用开发的模型。它被证明可以减少至少 9 倍的计算成本。MobileNet 使用深度可分离卷积来构建轻量级的深度神经网络。它有两个简单的全局超参数,可以有效地在延迟和正确率之间进行权衡。
迁移学习模型的性能
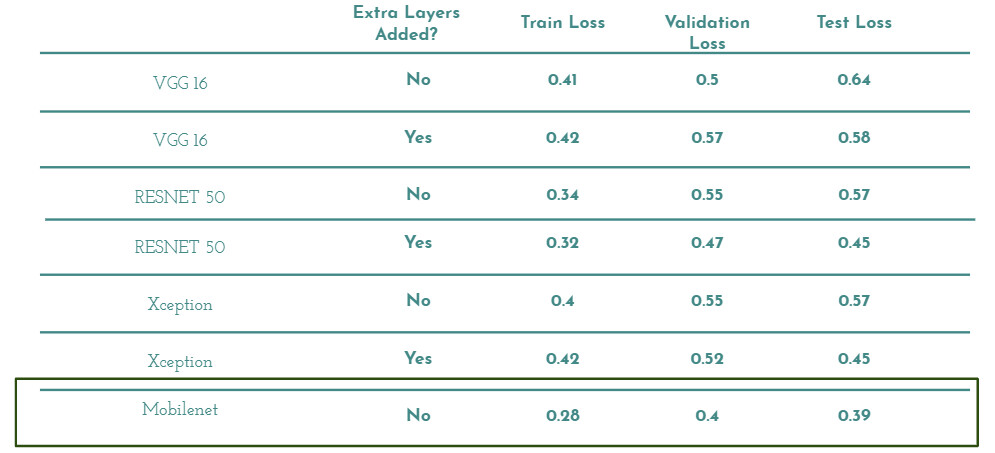
图:迁移学习模型的比较。MobileNet 在测试集上的损失最小
比较最佳模型
虽然上面的每个架构都给我们带来了很好的结果,但是对于各个类,每个模型的性能还是存在很大的差异。从下表中,我们注意到不同的模型对每个类都有最佳的正确率。因此,我们决定构建一个这些模型的概观。
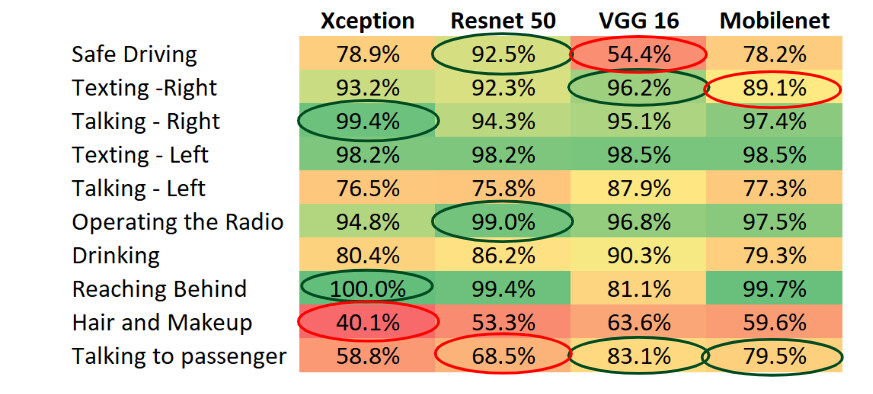
图:每个类不同算法的正确率
上图中列出了每个模型针对特定类的正确率。绿色到红色的变化表示了正确率从高到低。
集成模型
现在,我们已经有了 7 个最佳模型,这些模型之间的后验概率差异很大,我们尝试了多种集成技术,以进一步改善对数损失。
均值集成(Mean Ensembling):这是最简单,也是使用最广泛的集成方法,其中后验概率被计算为来自组件模型的预测概率的平均值。
修剪均值集成(Trimmed Mean Ensembling):这是通过从每个图像的组件模型中排除最大和最小的概率的均值集成。它有助于进一步使我们的预测平坦化,从而降低对数损失值。
用于集成的 K 近邻算法(KNN for Ensembling):由于这些图片都是在司机正在进行分心的活动或开车时从视频片段中截取的,因此有相当数量的同一类的图片是相似的。基于这一前提,找到相似的图像,并对这些图像的概率进行均值,可以帮助我们平滑每个类的预测概率。为了找到 10 个最近的邻居,我们使用 VGG16 迁移学习模型倒数第二层的输出作为验证集的特征。
表:以 MobileNet 模型为基准的集成模型比较。
学习
我们相信,从我们的经验中学到的这些知识,将会使那些像我们这样第一次从事深度学习项目的人们受益:
1. 使用 Pickle 文件: 你可以为你的项目使用的一个免费资源是“Google Colab”。你可以使用 GPU 来处理并行计算产生的海量数据。使用 Colab 时,可以执行必要的预处理步骤,方法是读取所有图像一次并将其保存在 Pickle 文件中。这样,你就可以通过直接加载 Pickle 文件来从上次终端的地方继续之前的工作。然后你就可以开始训练模型了。
2. 提前停止和回调: 一般来说,深度学习模型的训练都会经过大量的轮数。在这个过程中,模型可能会在几个轮数之内提高正确率,然后就开始偏离。训练结束时所存储的最终权重并不是最佳值,也就是说,它们可能不会给出最小的对数损失。我们可以使用 Keras 中的回调(CallBacks)函数,仅在模型经历一个轮数之后出现改进时,它才会保存模型的权重。你可以通过使用提前停止(Early Stopping)来减少训练时间,也可以设置一个阈值,在模型停止改善后可以运行的轮数的数量。
3. 均值或修剪均值优于集合的模型融合(Model Stacking): 融合模型的输入将具有很高的相关性,这会导致输出较高的方差。因此,在这种情况下,更简单的方法就是最佳方法。
4. 永远不要忽视最终的应用:对 7 个模型进行集成,然后在输出上运行 K 近邻算法,我们得到了不错的成绩,但如果我们必须选择一个单一模型,用最少的资源来得到良好但更快的预测,那么,MobileNet 将是显而易见的选择。因为 MobileNet 的开发特别考虑了计算限制,最适合汽车应用,在 7 种独立模型中,它的对数损失最低。
我们相信,在汽车上安装的摄像头,是可以做到跟踪司机的动作并向他们发出警报,这有助于防止事故的发生。
为了真正理解这一点,我们制作了一个小视频,演示如何使用我们这个模型:
请下载并上传此视频,网址为
参考文献
Stanford CS231N lecture series for CNN:
https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLzUTmXVwsnXod6WNdg57Yc3zFx_f-RYsq&index=1
How to implement CNN using Keras, TensorFlow:
https://www.youtube.com/watch?v=wQ8BIBpya2k&list=PLQVvvaa0QuDfhTox0AjmQ6tvTgMBZBEXN
CNN Architectures:
Transfer learning articles:
https://towardsdatascience.com/transfer-learning-using-mobilenet-and-keras-c75daf7ff299
http://cs229.stanford.edu/proj2016/report/SamCenLuo-ClassificationOfDriverDistraction-report.pdf
作者介绍:
Satya Naren Pachigolla,数据科学爱好者。目前在德克萨斯州大学奥斯汀分校攻读商业分析硕士学位。
本文最初发表在 Medium 博客,经原作者 Satya Naren Pachigolla 授权,InfoQ 中文站翻译并分享。
原文链接:
https://towardsdatascience.com/distracted-driver-detection-using-deep-learning-e893715e02a4

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论