

在深度学习领域,理解高维数据,并使用无监督方法将这些知识提取为有用的特征表示仍然是一个非常具有挑战性的问题。表征解构是一种用来解决该问题的途径,它意味着模型可以对给定的场景提取一组相互独立的特征。即改变其中的一个特征,其他的特征并不会受影响。通过特征解构,机器学习系统可以在真实世界“畅通无阻”。特征解构可以提高机器学习模型在已知数据上习得的知识的泛化能力,例如自动驾驶汽车和机器人可以通过对目标或周围环境的解构对当前状态做出更精确的响应。尽管无监督的解构方法已经在很多领域有所应用,但是近期的一些研究很难告诉我们这些方法的有效性及其局限性。
在 ICML2019 的最佳论文《Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations》中,谷歌 AI 对近期的一些无监督解构方法进行了大规模的评估,同时对一些通用的猜想进行挑战,进而提出了一些建议以促进解构学习在未来的发展。研究人员在七个不同的大规模实验数据上利用 2.52 个 GPU 年的算力训练了超过 12000 个模型。同时,谷歌 AI 也开源了实验过程中的代码与上千个预训练模型,并发布了结果库——disentanglement_lib供相关学者进行实验复现与更深入的探索。
什么是表征解构
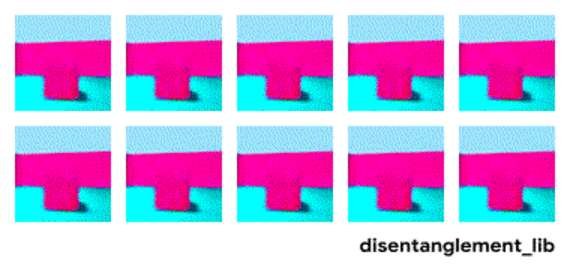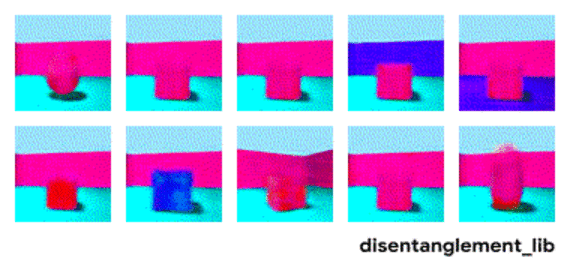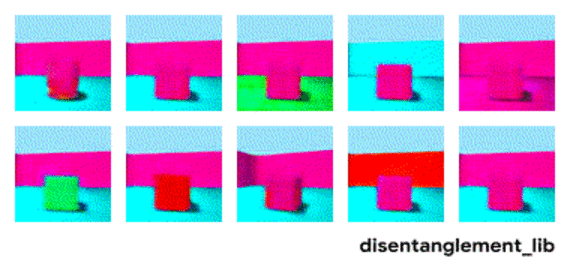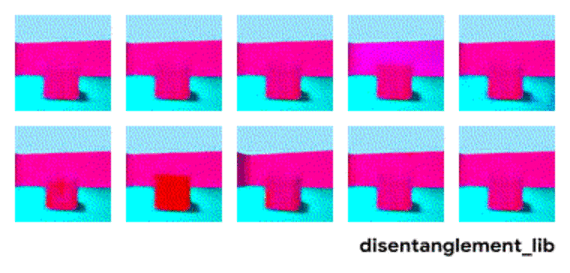
为了更好的理解表征解构的本质,首先来看一下面这个动图中的每个独立变化的元素。下图是通过改变 Shapes3D 数据库的不通过因子而得到不同 3D 模型的示例。第一张图反映了控制地板的因子,第二张图表示了控制墙的颜色的因子,同时还有控制球的颜色、尺寸、形状、以及摄像机视角的因子。
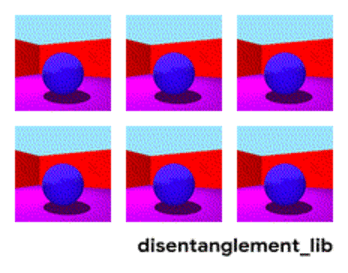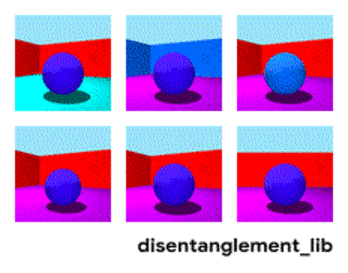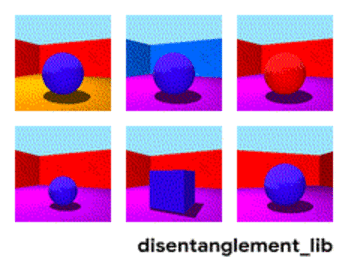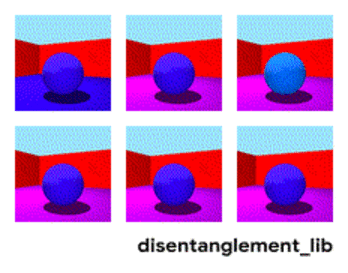
表征解构的目标是建立能够在特征向量中捕获这些具有可解释性因子的模型。下图显示了具有 10 维表示向量的模型。 十个面板中的可视化结果分别展示了十个不同的维度所表示的属性信息。从右上角和顶部中间的面板可以看出模型已成功地解构出地板颜色的影响因子,而左下方的两个面板表明物体颜色和尺寸仍然纠缠在一起。
主要研究成果
虽然学术界已经提出了各种无监督的方法来学习基于变分自编码器(VAE)的解构表示,并且已经设计了不同的度量来量化它们的解构水平。但谷歌 AI 的研究人员提到,该领域仍缺乏一个大规模的性能测评和对比研究。因此谷歌 AI 的研究人员提出了一个公平且可复现的实验方案,通过实施六种不同的最先进模型(BetaVAE,AnnealedVAE,FactorVAE,DIP-VAE I / II 和 Beta-TCVAE)和六种解构度指标(BetaVAE 分数,FactorVAE 分数,MIG,SAP,Modularity 和 DCI Disentanglement)来对无监督解构学习目前的状况进行基准测试。
总的来说,研究人员在 7 个数据集上训练并评估了 12,800 个这样的模型。通过对实验结果的分析,研究人员得出了以下几个结论:
没有任何经验证据表明实验所用的模型可以在无监督的方式下可靠地学习解构表征,因为随机种子和超参数似乎比模型选择更重要。也就是说,即使训练大量的模型并且其中一些可以得到解构表征,这些被解构出的表征并不能在没有真实标签的情况下被识别出来。此外,在上述研究中,针对不同的数据集,模型在最优时使用的超参数并不一致。这些结果与论文中提出的定理一致,该定理指出:如果没有数据集和模型的归纳偏置,则无法进行解构表示的无监督学习(即,必须对数据集做出假设并将其归入模型中)。
对于所考虑的模型和数据集,解构工作对下游任务是否有用尚待验证。例如,利用解构表征可以用较少标签来进行学习。
下图展示了实验过程中的一些发现。不同实验中随机种子的选择对解构分数的影响大于模型选择(左)和正则化的强度(右),可以看出更强的正则化并没有带来更好的解构效果。一个使用了较差的超参数的很好的模型可以很轻松地超越使用了好的超参数的比较差的模型。
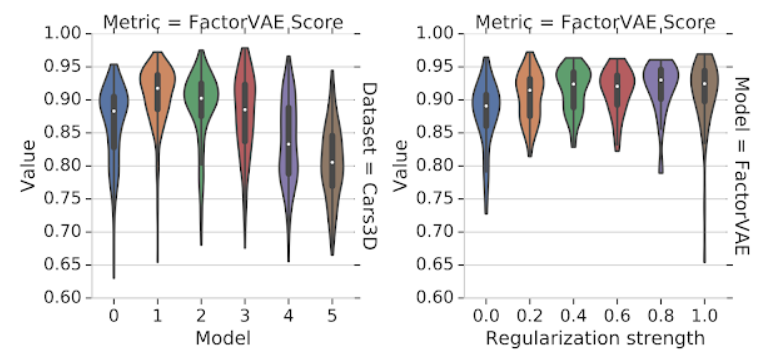
这组小提琴图显示了不同模型在 Cars3D 数据集上获得的 FactorVAE 分数的分布。左图显示了在使用不同的解构模型时分数的分布如何变化;而右图则显示了不同正则化强度对 FactorVAE 模型的影响。很明显的一点是小提琴图基本上重叠,这表明所有方法的结果都强烈依赖于随机种子。
基于上述的结果,研究人员提出了四个与未来研究相关的结论:
在不给出归纳偏置的情况下,想要得到无监督解构表征学习的理论性成果是不可能的。未来的工作应当明确描述强加的归纳偏置以及隐性和显性监督信息的作用。
为横数据集的无监督模型寻找一个有效的归纳偏置将会成为关键的开放性问题。
应当强调解构学习在各个特定领域所带来的实际应用价值以及潜在的应用方向,包括机器人、抽象推理和公平性等。
未来的工作应当在各种多样性数据集上具有可复现性。
开源 disentanglement_lib
为了让其他人对实验结果进行验证,谷歌 AI 发布了 disentanglement_lib,它是用来创建上述实验研究的库。Disentanglement_lib 包含了论文中提到的解构方法和以及解构度指标的开源实现,标准化的训练和测试规则,同时 disentanglement_lib 还包含了可视化工具以便更好的理解模型训练。
这个库的优点包含三个层面。首先,在命令行中使用不到四行代码就可以能复现论文中提到的所有模型。其次,它可以被方便的改造以验证新的假设。第三,disentanglement_lib 易于扩展,可将其用于其他的解构表示学习的研究中。
对于论文中的所有实验,全部复现需要约 2.52 个 GPU 年的算力,对一般的科研人员来说这种算力只能望而却步(谷歌 AI 原话“which can be prohibitive”)。因此谷歌 AI 的研究人员也开放了超过 10000 个预训练的 disentanglement_lib 模型,它可以与 disentanglement_lib 搭配使用。谷歌 AI 希望通过对 disentanglement_lib 开源加速对解构表征学习的研究。
相关链接:
英文原文链接:
https://ai.googleblog.com/2019/04/evaluating-unsupervised-learning-of.html

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论