

本文最初发表于 Medium 博客,经原作者 Natan Silnitsky 授权,InfoQ 中文站翻译并分享。
2021 年,我们的团队致力于将 Wix (国外比较火的一款建站平台)的 2000 个微服务从自托管的 Kafka 集群迁移到多集群的 Confluent Cloud 平台( Confluent Enterprise 的云端托管服务),整个过程是无缝的方式,无需服务所有者参与,且迁移是在正常通信中进行,没有任何停机。
这是我所领导过的最有挑战的项目,本文,我将与你分享我们作出的关键设计决策,并提供这种迁移的最佳实践和技巧。
分割过载集群
最近几年,由于事件驱动架构中的服务数量不断增多,Wix 业务 中大量的 OLTP 服务对 Kafka 的运转造成了负担。
我们的自托管集群规模从 2019 年的 5K Topics,大于 45K 分区增加到 2021 年的 20K Topics, 大于 200K 分区。
流量也从每天约 4.5 亿条记录增长到每个集群每天产生 25 亿多条记录。

迁移前 Wix 的 Kafka 使用情况
由于需要将所有元数据都加载到分区中,从而给集群控制器的启动时间带来了很大压力,这使得 leader 的选举时间大大增加。如果单个 broker 发生故障,也会极大影响其启动时间,从而造成更多的分区复制不足事件。
为防止 Kafka 集群在生产中出现不稳定的情况,我们决定将自托管的 Kafka 集群迁移到 Confluent Cloud,并将每个数据中心的单集群分割成多个集群。
为什么要云托管 Kafka 集群?
自管理一个 Kafka 集群并非易事,尤其是在执行一些任务时,例如重新平衡 brokers 之间的分区,或者升级 brokers 版本等,这些必须认真规划和实施。特别是集群中过载了元数据时,这一点尤为明显,正如我们的情况一样。
以下是使用 Kafka 云平台,特别是 Confluent Cloud 的 4 个好处:
更好的集群性能和灵活性
其中的 brokers 分区的重新平衡让其不会成为性能瓶颈,可以轻松扩大或缩小集群容量,以实现成本效益。
透明的版本升级
Kafka 的代码库不断得到改进,尤其是专注于 KIP-500:元数据将存储在 Kafka 内的分区中,而不是存储在 ZooKeeper,控制器将成为该分区的 leader。除了 Kafka 本身,不需要配置和管理外部元数据系统。这个项目一旦完成,将会极大地提高每个集群和 brokers 所能容纳的元数据量。通过管理,你可以实现对版本的自动更新,这样就可以改进性能并修正 Bug。
轻松添加新集群
如果你需要一个新的集群。设置它是非常简单的。
分层存储
Confluent 平台提供了分层存储,使得 Kafka 的记录保留期大大延长,而且不需要支付高昂的磁盘空间费用,通过将旧的记录转移到更便宜的 S3 存储,而不增加新的费用。
将 2000 个微服务切换到多集群 Kafka 架构
在 Wix,我们拥有一个标准的 JVM 库和代理服务,用于与 Kafka 进行交互,称为 Greyhound。这是一个开源的先进 SDK,可以为 Apache Kafka 提供诸如并发消息处理、批量处理、重试等其他特性。
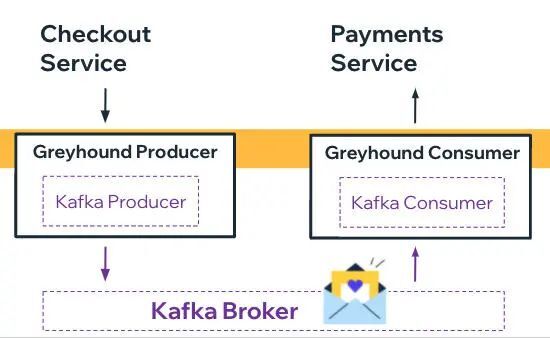
Greyhound 是 Wix 约 2200 个微服务的事件驱动主干,因此,引入多集群的概念仅需在一些地方(包括库和代理服务)就可以进行。由于旧的集群会自动映射,所以新主题的生产者(producer)和消费者(consumer)必须清楚地指明集群。当构建 Greyhound 消费者或生产者时,开发人员只要定义集群的逻辑名称即可,如下图所示:

如何分割?
我们决定根据不同的服务级别协议(Service-level agreement,SLA)对 Kafka 集群进行分割。例如,在 CI/CD 管道和数据迁移案例中,服务级别协议是有别于生产服务的。请注意,由于每个数据中心的作用不同,并非所有数据中心都拥有同样数目的 Kafka 集群。
Greyhound(Wix 自己的 Kafka SDK)懂得当服务实例在目前运行的数据中心集群不可用时,该如何处理这个问题并防止发生故障。
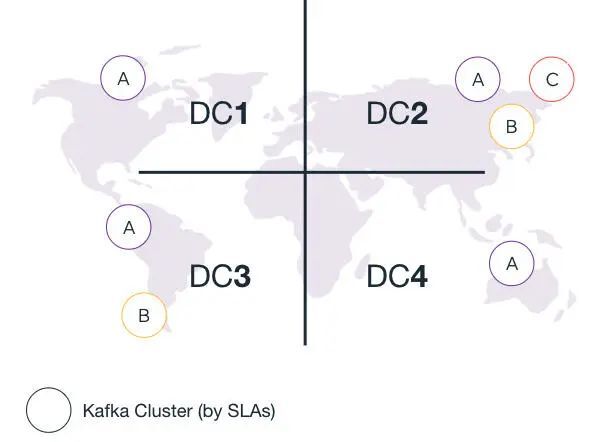
流量耗尽的数据中心?
为了使 2000 个微服务的生产者和消费者更容易迁移到多个管理式 Kafka 集群,最初的设计依赖于首先将每个数据中心(data center,DC)的流量全部耗尽。
这样的设计意味着只需要将生产者和消费者的连接细节切换到新的 Kafka 集群。因为 Wix 微服务通过 Greyhound 层与 Kafka 集群相连,所以只要在 Greyhound 的生产配置就可以更改连接(同时保证仅有一个数据中心受到影响)。
虽然这种设计非常简单,但是很遗憾,它不可能实现和执行。
有以下理由:
有些服务只部署在其中一个数据中心,并且难以进行迁移。这种设计意味着,(只可能出现两种极端局面)要么全有要么全无,并且当流量返回时,就会面临巨大的风险。未被切换的边缘案例可能会遭受数据丢失。数据中心的流量不能在很长一段时间内完全耗尽,因为这将极大提高一些服务的停机风险。
取而代之的是,计划了一种新的设计,包括在实时流量期间进行迁移。
零宕机迁移
在实时流量中执行迁移,就意味着必须进行细致的规划和实施。
这个过程需要逐步进行(一次只能对少量微服务产生影响,从而降低发生故障时的“爆炸半径”),并且可以实现完全的自动化,从而降低人为失误,其中包括自动化的回滚过程。
首先迁移生产者(在消费者之前)并非一种选项,这就意味着要花大量的时间来保证所有的消费者都已处理好了自托管集群中找到的所有记录,并能够安全地切换到新的集群主题。这会在处理过程中导致相当大的延迟,并且可能会损害某些 OTLP 业务流和用户。此外,如果没有数据丢失,由于一些意想不到的问题而回滚消费者是不可能的。
活跃的 Kafka 消费者在保证没有消息丢失和最小程度的重新处理记录的情况下,必须首先进行切换。唯一的方法是将所有消耗的主题记录从自己的主机集群复制到目标管理式集群。
复制
为了保证在迁移过程中不会出现消息处理的丢失,我们创建了一个专门的复制服务。一旦所有的消费者主题被确定,复制器(replicator)服务就会被要求在适当的云集群中创建主题,并开始消费来自自托管集群的记录,并将它们生成到目标集群中。
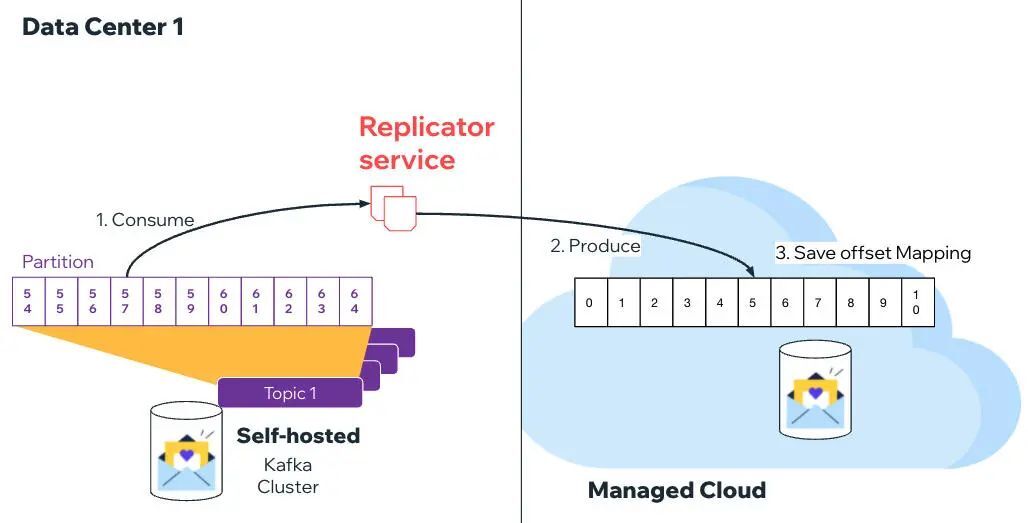
消费者迁移
为了促进消费者迁移,复制器还坚持为每个分区提供偏移量映射,这样 Greyhound 消费者就可以从正确的偏移量开始处理云集群中的记录——该偏移量是从自托管集群中第一个未提交的偏移量映射而来的。
除了复制器外,还有一个迁移编排器(Migration Orchestrator),它可以确保一个主题被复制,所有的偏移量被映射,并继续请求 Greyhound 消费者从自托管集群中取消订阅。在验证成功后,编排器就会要求消费者在寻求正确的映射偏移时订阅云集群。
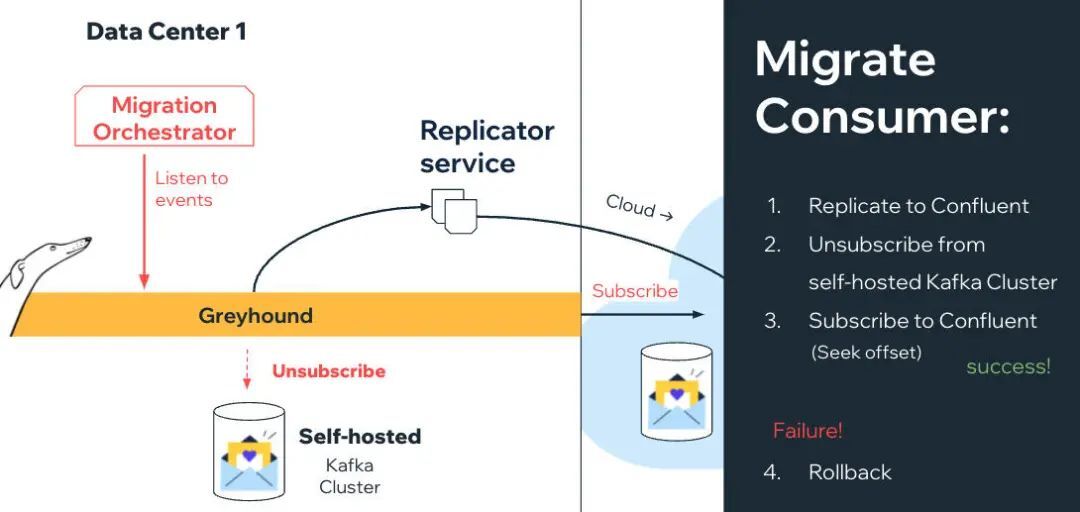
如果出现失败的情况,编排器能够要求消费者恢复到自托管集群。
所有这些编排器与消费者之间的通信都是通过专门的 Kafka 迁移主题实现的。Greyhound 消费者在启动时就开始监听它们。
生产者迁移
一旦某个主题的所有消费者都迁移了,就可以迁移其生产者。
最初的迁移设计需要请求生产者切换集群连接,同时仍然接受传入的生产请求。这就意味着将这些请求缓存到内存中,而且被人们认为相当危险。
之后,我们提出了一种更加简便的设计方案,它依赖于 Wix 的渐进式 Kubernetes 部署过程。每个新的 pod 只会在它的全部健康测试正常时,才会开始接受传入的请求,包括与 Kafka 的连接。因为这个过程都是逐步进行的,所以总会有“老”的 pod 在运行,所以服务作为一个整体,总是能接受到传入的请求。
在 pod 启动时,Greyhound 生产者会简单地查看数据库来确定他们要连接的集群。这要比动态的集群切换和记录缓存更加简单。这就意味着可以安全地进行迁移,不会出现请求丢失,并且服务可以维持高可用性。
复制的瓶颈
只有在迁移了生产者之后,才能终止对主题的复制。但是要想迁移生产者,就得把其所有的主题消费者都迁移出去。
事实证明,许多主题有来自不同服务的多个消费者,这就意味着,复制器消费者需要处理和复制的流量越来越多。
这就产生了一个问题,由于我们相对较老的自托管 Kafka brokers 版本的技术局限性,使得消费者能够处理的主题数量有限。在几次尝试增加 message.max.bytes 的结果都适得其反(参阅 KAFKA-9254 bug),并造成了严重的问题后,我们决定简单地增加复制器消费者,并在它们之间分片处理要复制的主题。
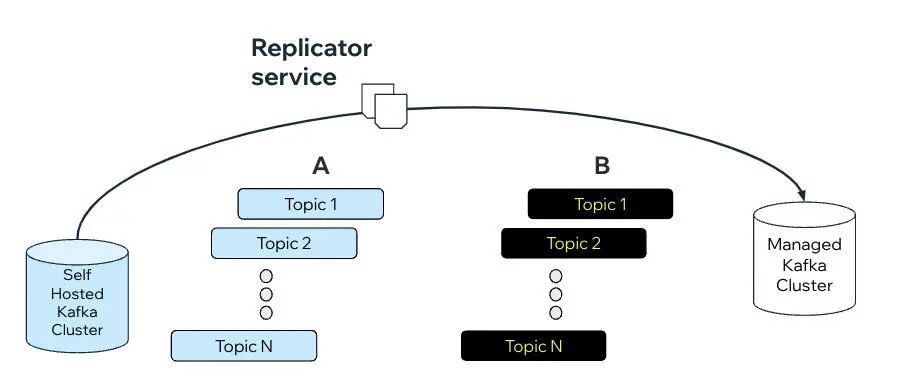
迁移之外——外部消费者控制
这种“有流量”的迁移设计为动态改变 Greyhound 消费者的配置或状态,提供了很多新的可能性,而无需在生产中采用新的版本。
现在,我们已经有了基础设施,使 Greyhound 消费者能够监听传入的命令来改变状态或配置。这样的命令可以包括:
切换集群:取消订阅当前集群并订阅另一个集群。跳过记录:跳过不能处理的记录。改变处理率:动态地增加或减少并行处理量,或为节流和背压添加延迟。重新分配记录:如果一个分区的延迟越来越大,则能够在所有分区之间重新分配记录(并跳过旧的记录)。
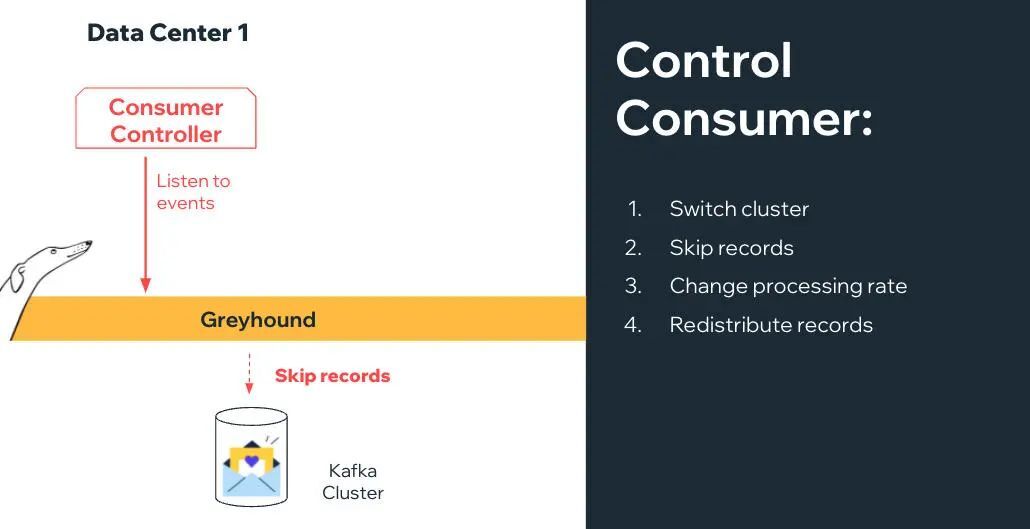
目前,这些都是理论上的,但利用已经存在的迁移基础设施就可以更容易地实现。
最佳实践和提示
以下是成功进行 Kafka 集群迁移的最佳实践和技巧清单:
创建一个脚本,自行检查状态,如果没有达到预期状态就停止
让迁移过程尽可能地自动化是关键,所以让脚本能够自行检查是否能够进入下一阶段,这会极大地加速迁移过程。而另一方面,自动回滚和自我修复是很难做到的,因此,还是要交给人工干预。
准备好随时可以使用回滚
无论你的迁移代码测试得有多好,生产环境都是不确定的。为每个阶段准备一个现成的回滚选项是非常重要的。一定要提前准备好,并在开始运行迁移之前进行尽可能多的测试。
先从测试 / 中继主题和无影响主题入手
由于记录有可能丢失,或者恢复过程可能会很痛苦,因此迁移过程会非常危险。请确保用测试主题开始测试你的迁移代码。这样才能得到真正的检验。利用测试主题,通过将真实的生产记录复制到特定的测试应用中,实际模仿生产主题。这样,在消费者迁移时,万一发生失败,也不会影响到生产,但是会给你一个更加真实的生产模拟。
创建自定义的指标仪表板,以显示当前和演变的状态
即便你创建了一个自动化的、完全无人值守的迁移过程,你也必须能够监控所发生的一切,并且当问题发生时,你拥有相关的工具可以进行调查。一定要事先准备好自定义的监控仪表板,以明确地显示你正在迁移的消费者和生产者的当前和历史状态。
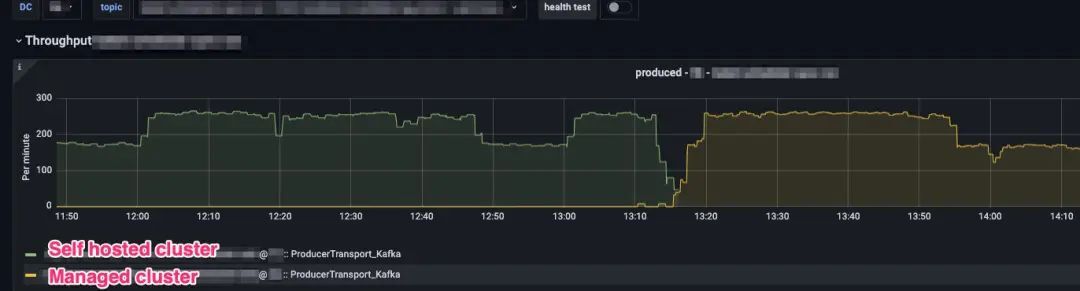
在下图中,我们可以看出,生产者是如何成功地从自托管集群切换到管理式集群的(随着越来越多的 Pod 被重新启动并读取新的配置,因此吞吐量会降低)。
确保自托管 Kafka 代理是最新的补丁版本
因为我们的自托管 Kafka brokers 没有使用最新的补丁版本,所以在我们多次试图提高 message.max.bytes 的值时,我们最后还是发生了一个生产事故(详见本文的“复制的瓶颈”部分)。我的忠告是,先更新自托管集群 Kafka brokers 版本。如果不是最新版本,那至少也要安装最新的补丁。
总结
我们利用 Greyhound 和专用编排服务和脚本,以便在实时流量期间以无缝方式实现自动、安全和逐步的迁移。
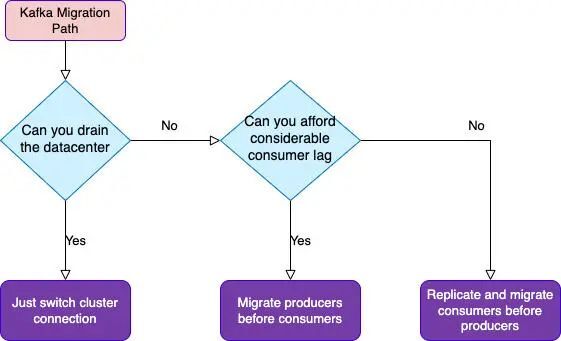
这可不是一件简单的事情。如果你可以充分利用数据中心完全耗尽流量的时间,或者可以承受得住处理的停机时间,那么我强烈建议将生产者和消费者切换到新集群,而不是首先复制数据。这样的设计更加容易,你也可以节省更多的时间。
否则,当你在流量下进行迁移时,你必须小心地按照执行的顺序(消费者在生产者之前 / 之后)进行迁移,并且要保证你明白这个决策的后果(回滚的能力,丢失数据的可能)。
下面你会看到一张流程图,使你容易理解各种选择。
作者介绍:
Natan Silnitsky,供职于 Wix,后端基础设施开发者。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论