

在今年的KubeCon峰会上海站,作为开源领域的贡献者和推进者,华为开源了面向高性能计算的云原生批量计算平台 Volcano [vɒlˈkeɪnəʊ]。该项目基于华为云容器平台大规模高性能计算应用管理的最佳实践,在原生 K8s 的基础上,补齐了作业(Job)调度和设备管理等多方面的短板。目前,Volcano 在华为云上对接了包括一站式 AI 开发平台 ModelArts、云容器实例 CCI、云容器引擎 CCE 在内的多款服务,是整个高性能计算领域不可或缺的基座。自开源以来,项目已经吸引了来自腾讯,百度,快手以及 AWS 等多个公司的贡献者。
随着容器化以及容器编排技术的普及,越来越多的上层业务正开始拥抱 K8s 生态,但无法否认的是,针对人工智能和大数据作业场景,原生 K8s 的支持度不高,终端用户如果想要将现有的业务迁移到 K8s 平台,很有可能会遇到下面的问题:
成组调度(Gang Scheduling):一个 BigData/AI 的作业通常会包含多个任务,而业务逻辑一般要求 Pod 要么同时启动,要么不启动。比如,一个 Tensorflow 作业如果仅单独拉起一种角色的任务(Ps or Worker)是没法正常执行的。
资源公平调度(Fair-share):部署的 K8s 集群会存在多个 Namespace,而每个 Namespace 也可能提交多个作业,如何调度资源才能避免某个 Namespace 的资源被无限制压缩,又如何才能确保作业之间的资源调度公平?
GPU Topology 感知(GPU Topology Awareness):一个常见的 AI 训练和推理作业,为了达到更高的性能,往往需要使用多个 GPU 共同完成,此时 GPU 的 Topology 结构以及设备之间的传输性能会对计算性能造成很大影响。目前, K8s 提供的扩展资源调度机制还无法满足调度时 Topology 感知的问题。
集群自动配置(Cluster Configuration):许多上层工具在业务启动之前,需要用户配置工具的集群状态,方便系统内部节点互通和识别,以 MPI(Message Passing Interface)作业为例,需要用户以命令行参数“—host”配置集群的所有节点信息,并且还依赖节点之间 SSH 互通。所以,用户还要考虑怎样自动配置和管理业务集群。
此外,如何监控整个作业集群的状态?单个 Pod 失败如何处理?怎么解决任务依赖的问题等,都是需要处理的问题。
基于此,Volcano 在解决此类问题的基础上提供了一个针对 BigData 和 AI 场景下,通用、可扩展、高性能、稳定的原生批量计算平台,方便以Kubeflow、KubeGene、Spark为代表的上层业务组件集成和使用。
概述
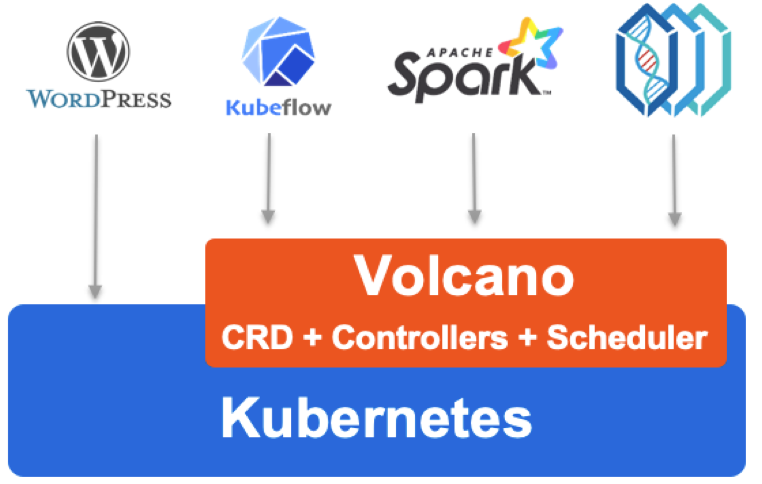
图 2: Volcano 业务全景
如图 2 所示,Volcano 在 K8s 之上抽象了一个批量计算的通用基础层,向下弥补 K8s 调度能力的不足,向上提供灵活通用的 Job 抽象。目前,该项目最重要的两个组件分别是 Volcano-Scheduler 和 Volcano-Controller。
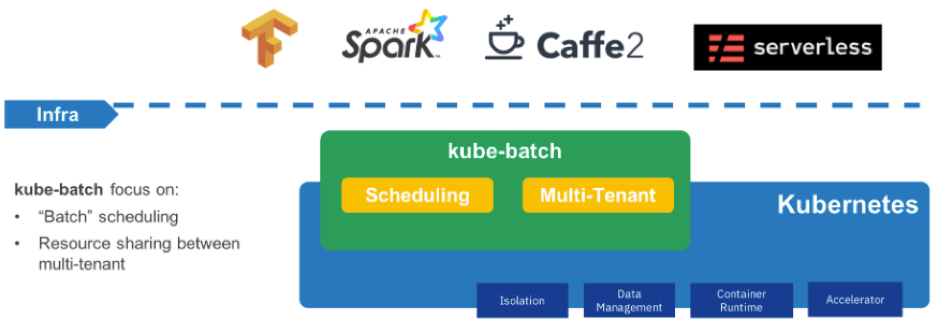
图 3: Kube-Batch 介绍
Volcano-Scheduler:这个组件最开始来自社区的 Scheduling SIG 子项目项目Kube-Batch, 是一个可扩展的增强调度器,主要支持的能力有:
Actions:
Allocate: 正常的资源分配动作。
Preempt: 抢占,当系统中存在高优先级作业,且系统资源无法满足请求时,会触发资源抢占操作。
Reclaim: 资源回收, Kube-Batch 会使用队列(queue)将资源按照比例分配,当系统中新增或移除队列时,Reclaim 会负责回收和重新分配资源到剩余队列中去。
Plugins:
DRF: 即 Domaint Resource Fairness, 目的是为了确保在多种类型资源共存的环境下,尽可能满足分配的公平原则,其理论最早来自于 UC 伯克利大学的论文《Dominant Resource Fairness: Fair Allocation of Multiple Resource Types》[5]。
Conformance: 资源一致性,确保系统关键资源不被强制回收使用。
Gang: 资源成组,确保作业内的成组 Pod 资源不被强制驱逐。
而 Volcano-Scheduler 在 Kube-Batch 的基础上又更进一步,引入了更多领域性的动作和插件,包括 BinPack、GPUShare、GPUTopoAware 等。
Volcano-Controller:Volcano 通过 CRD 的方式提供了通用灵活的 Job 抽象 Volcano Job (batch.volcano.sh/jobs),Controller 则负责与 Scheduler 配合,管理 Job 的整个生命周期。主要功能包括:
自定义的 Job 资源: 跟 K8s 内置的 Job(作业)资源相比,Volcano Job 有了更多增强配置,比如: 任务配置,提交重试,最小调度资源数,作业优先级, 资源队列等。
Job 生命周期管理: Volcano Controller 会监控 Job 的创建,创建和管理对应的子资源(Pod, ConfigMap, Service),刷新作业的进度概要,提供 CLI 方便用户查看和管理作业资源等。
任务执行策略: 单个 Job 下面往往会关联多个任务(Task),而且任务之间可能存在相互依赖关系,Volcano Controller 支持配置任务策略,方便异常情况下的任务间关联性重试或终止。
扩展插件: 在提交作业、创建 Pod 等多个阶段,Controller 支持配置插件用来执行自定义的环境准备和清理的工作,比如常见的 MPI 作业,在提交前就需要配置 SSH 插件,用来完成 Pod 资源的 SSH 信息配置。
下面以一个 MPI Job 作业的 YAML 片段为例,带大家从整体上了解 Job Controller 的功能(扩展功能相关字段已添加注释,方便理解)。
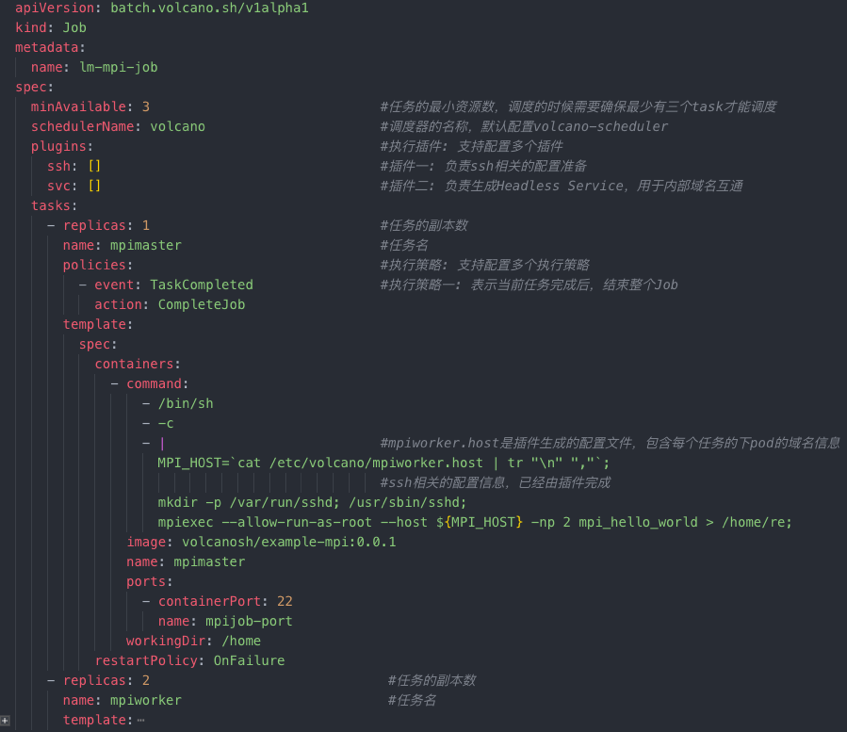
图 4: Volcano Job 样例(/example/integrations/mpi/mpi-example.yaml)
有了上面的介绍,回过头来参照图 5 梳理 Volcano 一次普通作业的执行流程也就很容易理解了。
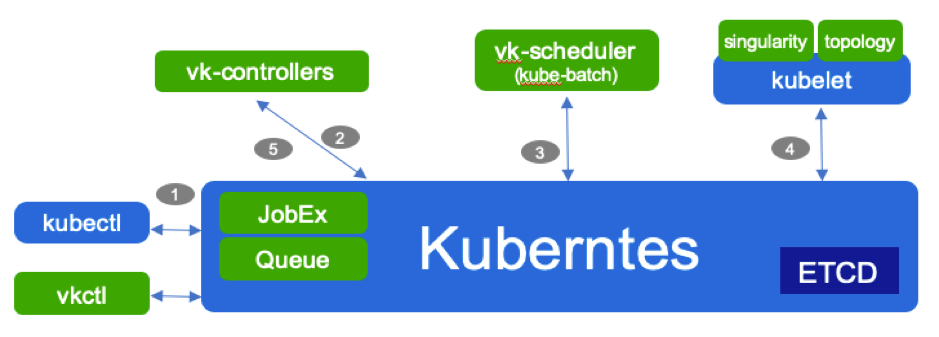
图 5: Volcano 组件与调度流程
用户通过 kubectl 创建 Volcano Job 资源。
Volcano Controller 监测到 Job 资源创建,校验资源有效性,依据 JobSpec 创建依赖的 Pod, Service, ConfigMap 等资源,执行配置的插件。
Volcano Scheduler 监听 Pod 资源的创建,依据策略,完成 Pod 资源的调度和绑定。
Kubelet 负责 Pod 资源的创建,业务开始执行。
Volcano Controller 负责 Job 后续的生命周期管理(状态监控,事件响应,资源清理等)。
调度效率
除去易用性和扩展性,在 BigData 和 AI 场景下,资源调度的效率(成功率)通常能有效减少业务的运行时间,提高底层硬件设备的使用率,从而降低使用成本,我们以 Volcano Scheduler 和原生 Scheduler 在 Gang Scheduling 的场景下做了一个简单的 TF Job 执行时间对比:
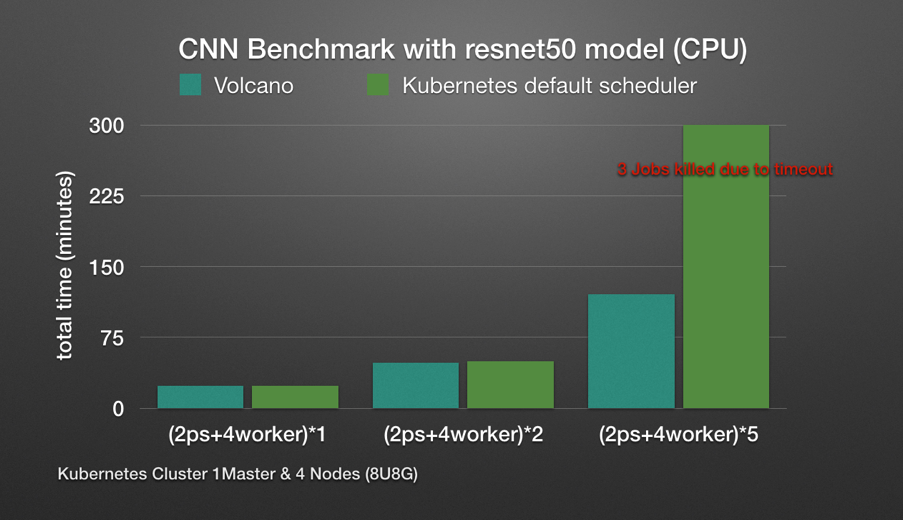
图 6: Volcano 与 Default Scheduler 调度作业执行时间对比(Gang Scheduling)
参考图 6 发现,单个作业的执行环境,两种执行方式在运行时间上并无明显区别,但是当集群中存在多个作业时,因为原生 Scheduler 无法保证调度的成组性,直接导致极端的情况出现: 作业之间出现资源竞争,互相等待,上层业务无法正常运行,直至超时,此时的调度效率大打折扣。
社区和贡献
Volcano 项目目前还在不断的发展壮大中,更多特性也在设计和开发阶段,如果广大开发者有兴趣,欢迎随时加入Slack讨论,提问题给意见或者贡献代码。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论