

短视频信息流产品是目前最炙手可热的互联网产品,完全占领了用户的碎片时间,据艾瑞统计 2018 年短视频产品月独立设备数有 6 亿+台。爱奇艺也有自己的视频信息流产品矩阵,如爱奇艺热点、小视频、爱奇艺 PPS、 纳逗、姜饼等。每天有大量新的 UGC 视频被生产出来,短视频质量变得参差不齐,批量化的准确识别视频质量有助于提升用户体验,优化推荐算法对于高质量视频的露出
短视频/小视频的主要低质问题可归纳如下:
封面图质量:模糊,黑边,拉伸变形,画面暗,无主体,无意义等。
视频内容质量:视频无意义,无聊,不清晰,花屏,广告,低俗等。
文本质量:标题过于简单,特殊符号多,句子不通顺,语法结构不正常,标题党,图文不符等。
基于对以上低质原因的分析,我们构建了综合视频文本、图像、内容、声音等多种输入信息的视频质量模型,主要内容如下:
封面图质量模型:基于卷积模型提取的深度特征和人工设计特征的图像质量模型。
视频内容质量模型:端到端训练的基于多模态的深度内容质量模型。
文本质量模型:基于文本结构特征和文本语义特征的文本质量分类模型。
应用场景
视频质量模型主要的功能是输出视频不同模态的质量评估分,如下图所示:
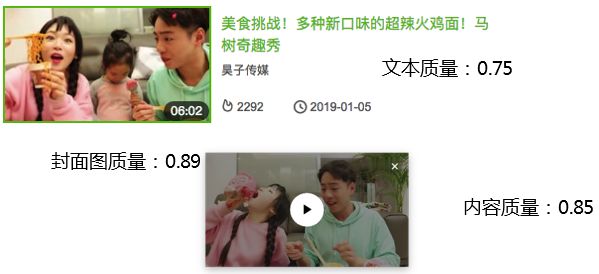
视频的质量评估信息可以应用在视频的生命周期多个阶段,如 uploader 上传提示,corpus 进退场和算法侧引入质量分 boost 高质量视频等场景。
Uploader 上传提示:当用户上传视频时,质量模型会给出视频的多模态质量分,系统根据质量分来决定是否提示用户上传质量更改的封面图,从源头保证视频的质量。
corpus 进退场: 爱奇艺信息流推荐致力于构建健康的用户生态,大量生产成本低的低质量视频进入 corpus 不符合产品的长期目标。利用视频的多模态质量评估信息可以实时过滤新增的低质量视频进入 corpus, 大幅度降低人工审核成本。目前该服务已经在热点推荐上线,目前已识别超过 1M+的低质量视频。从 AB 测试的结论来看,产品部分指标如留存也是正向的。
Boost 优质视频露出:在推荐的召回和排序模型引入视频质量分,同时优化视频的后验和先验信息,推荐给用户质量高、转化好的视频。目前已经加入到的小视频业务的召回模型,AB 测试显示增益明显。
视频质量模型算法方案
由于视频标题,封面图和内容的低质问题在质量定义上差异比较大,三种信息的异构性也比较明显。 在建模上采用了单独建模,综合评估视频质量的方式。
封面图质量模型:
人工特征

基础质量特征(Low-Level Feature)
边缘的空间分布:快照非机构化而杂乱(边缘分布均匀),专业相片主题明确边缘清晰(边缘聚焦在图像中心附近),将图像进行拉普拉斯滤波与其类别拉普拉斯图像均值的 L1 距离进行度量。
颜色分布、色调计数、对比度与亮度:基于图像的 RGB 或者 HSV 颜色空间来统计。
模糊程度:模糊图像可以看做是清晰图像,基于各种模糊 kernel 的作用而得,基于这些核算法可以评估图像或图像像素的锐度或聚焦程度。
我们实现了 6 组不同模糊核计算的模糊特征(14 个),以及它们的统计均值,方差,最大值,最小值,同时考虑到图像的局部模糊性,每个模糊特征会分图像的 4 个区域进行分别统计。我们模糊算子包括:
基于梯度(Gradient-based operators),该算法假设清晰图像相比模糊图像有更锐利的线条;
基于拉普拉斯变换(Laplacian-based operators),统计图像中线条的占比;
其他包括基于小波算子(Wavelet-based operator);基于统计算子(Statistic-based operators);基于离散余弦算子(Discrete cosine transform);基于局部表示和滤波相结合(Miscellaneous operators)。
迁移学习 & ImageNet Fine-tuning
基于预训练的 ImageNet 模型在训练数据较少的目标任务上进行迁移学习已经是当前比较流行的做法,且效果明显。在一些主流的视觉任务如目标检测、图像分割、行为识别上都获得了 state-of-the-art 的效果。
在我们的质量分类任务上,由于数据规模有限(万级别规模),目标任务分类体系和 ImageNet 的分类体系差异较大,通过实验对比选择了保留中间层以上的 layers。实际操作上,使用了 Resnet50 作为预训练主网络,固定的是 block3 以上的层。
Wide & Deep:深度和人工特征都很重要
为了同时收益于 ImageNet 预训练网络的深度表示学习和人工特征,封面图质量模型采用的是 deep&wide 模型结构,同时针对 deep 和 wide 侧的特征交叉和训练优化进行了针对性的改良优化,以下是模型结构:
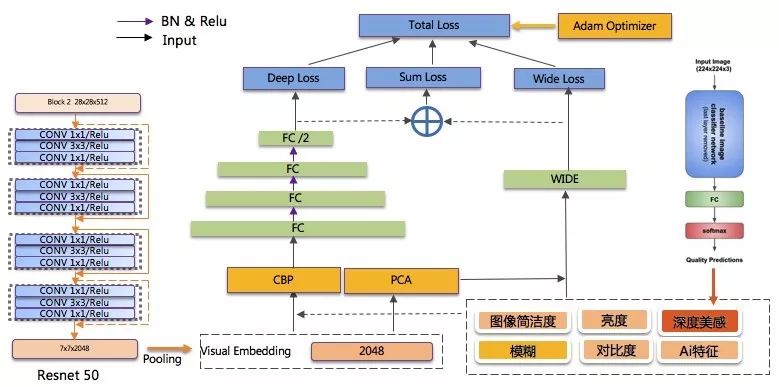
Deep 侧(泛化): 基于 Resnet-50 作为特征抽取器, 抽取中间层作为图像的 deep 表示,再接上多层隐层来优化目标任务,层与层之间都加入 BN。
Wide 侧(记忆):除了前面介绍的基础特征外, 引入了美感特征和 AI 特征。使用 Google NIMA 深度美感模型的结果作为特征,高质量图片美感上普遍优于低质量图像。
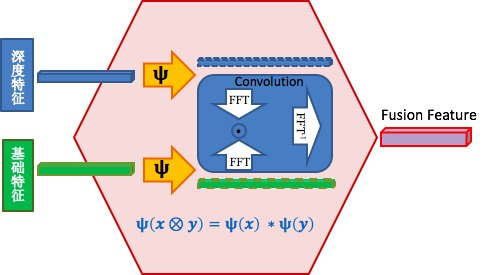
特征融合
传统的 Deep 侧特征和 Wide 侧特征作为两种独立且有效的特征表示,二者之间并没有交互。而我们知道有效的特征组合能生产出更有价值的特征表示,所以我们用精简双线性池化( Compact Bilinear Pooling,CBP) 学习深度特征和基础特征的交叉,特征交叉后作为 Deep 侧输入。
视频内容质量模型
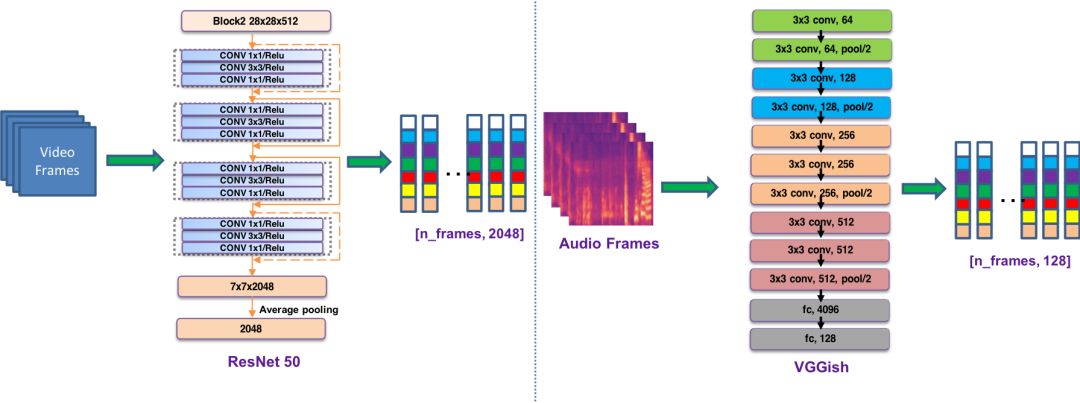
视频内容质量模型是有监督的分类模型,我们在参考当前 state-of-the-art 的视频分类模型基础上,实现了基于视频抽帧表示,光流表示和音频表示的多模态视频质量分类模型。
由于我们的训练数据规模较小,3D 卷积和 LSTM 分类都不太适合我们的场景。 考虑到 NetVlad 模型和双流问题的差异性,在解决问题维度上存在互补,同时我们引入了音频信息输入解决音质差的低质量视频问题。
我们的模型结构如下:
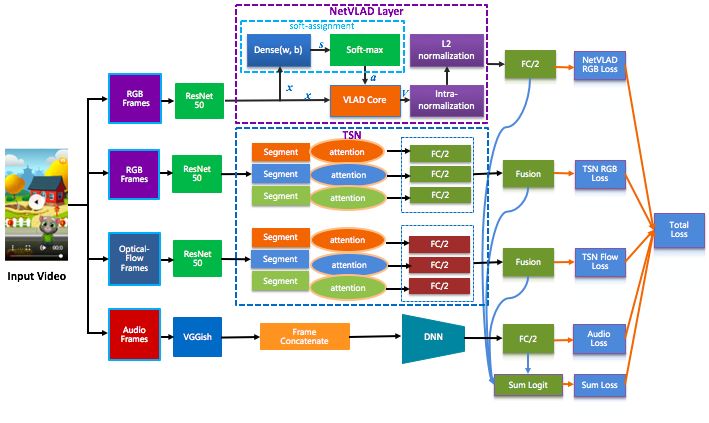
视频抽帧和音频抽帧的细节如下:
NetVlad
NetVlad 是图像位置识别任务中提出的模型,解决了传统 vlad 算法基于无监督的聚类过程学习图像的视觉主题表示,主要改进在于聚类过程变成端到端的有监督学习,聚类中心通过反向传播进行调整和优化。
我们将其扩展到了视频质量分类场景,端到端学习视频抽帧图像表示的聚类分布,从而获得 video-level 的特征表示。相对于一般的视频抽帧特征的聚合方法如 average pooling 或最大池化,NetVlad 能获得更好的视频表示,在比较明显的视频画面低质问题上作用较大, 如黑屏,光线暗,不清晰等。
TSN
TSN(Temporal Segment Network)是比较经典的双流网络结构,如下图,主要用于捕捉视频时序信息。而模型的运动先验信息我们使用的是光流,光流本质是捕捉同一位置的像素在时序上运动信息。
高质量视频的光流,轨迹比较有规律,且运动区域清晰。低质量视频的光流轨迹比较杂乱无章,静止画面的视频甚至没有运动轨迹。如下,左图是高质量视频,右图是低质量视频。

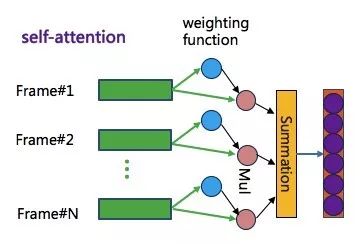
帧间 self-attention:每个 segment 会随机抽取 K 帧,正常是用类似 average 池化的方法对 K 帧的 CNN 表示进行特征聚合,获得该视频片段的特征表示。我们认为不同的视频抽帧对于目标的重要性不同,因此引入了 self-attention 学习不同帧的重要性权重。
Multimodal 多路内容质量模型
NetVlad 和 TSN 分别建模了视频的视觉表示和运动表示,我们还引入了音频的特征表示来识别音质差,没有声音等低质量视频。音频特征主要是基于预训练网络 vggish 抽取而得,每个音频帧可以抽取得到 128 维的特征。正如前面的模型图所示,我们采用的是 multi-way 的端到端网络结构,NetVlad,TSN 和音频 DNN 是模型的三路主模型。
文本质量模型
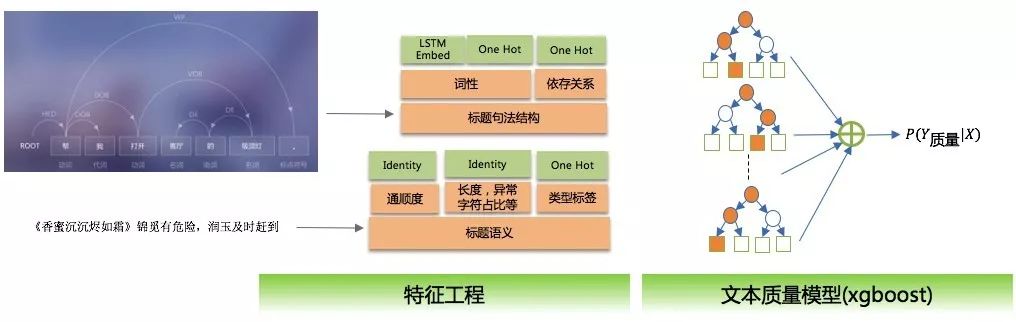
文本质量模型主要是基于视频标题、描述等文本信息评估视频的文本质量,主要重点在于特征抽取,包括语义抽取和句法结构抽取,模型是 xgboost 分类模型。
总结和规划
结合业务场景,我们从文本、封面图和视频内容分别构建了对应质量模型,已应用信息流业务的不同模块。但仍然存在一些不足,未来我们会从特征优化,算法模型优化和自适应业务场景等维度进行:
特征提取优化:视频的图像特征、部分内容特征等的提取成本还比较高,也影响线上效率。目标是实现特征提取深度化,优先使用深度模型来提取多模态特征,这样整个模型训练过程也更简洁。
算法模型优化:目前多模态输入信息的使用和模型的框架仍比较简单,未来会考虑学习多模态特征的共享表示。视频内容质量模型会尝试更适合的模型学习潜在的 spatial-temporal 的 pattern。 当前、文本、图像和视频的质量模型是隔离训练的,我们期望能训练端到端的 multi-task 模型。
自适应业务场景:不同业务的数据质量分布差异比较大,需要构建更通用的质量模型。未来会升级为积木式质量模型,构建不同低质原因的质量识别子模型,业务根据自身需求选择合适的子模型进行组合使用。
作者简介:奇文。本文转载自公众号“爱奇艺技术产品团队”。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论