

此前,我们常常收到知友们的反馈说「好烦哦,TA 又不友善了」、「我要举报 XX,TA 在评论区又开始杠上了」、「这种辱骂他人的人,你们都不处理吗?」等等。我们一直鼓励知友们好好说话、认真讨论,对于那些不友善的内容和行为,我们都会坚决处理。为了更快速地处理这些不友善内容,我们的机器人瓦力也在不断升级自己的覆盖范围和识别准确度,希望可以做到真正地「围追堵截」不友善。
今年年初,我们开始尝试用深度学习算法辅助审核人员处理不友善问题,经过近三个月的探索和尝试,目前该算法第一版已经上线,并且取得相对不错的效果。
知乎不友善文本识别应用的场景和策略
目前,瓦力识别不友善的算法已经应用在知友们的举报和社区实时产生的内容中。针对这两种内容的不同场景和特点,我们采用了不同的处理策略:
举报内容的处理策略
瓦力有效地提升了我们的举报处理效率和响应速度。目前,我们每天约收到知友们近 25,000 条举报。在这些举报中,大约有 7,000 条是关于不友善的内容。模型训练阶段,我们利用经过人工标注的举报内容进行模型训练。线上预测阶段,如果模型预测某条内容属于不友善的概率 x 大于阈值 p_abuse,瓦力会在 0.3 秒间完成判断并直接删除,内容被处理后,知友们也会收到相应的私信通知;如果模型预测该内容属于非不友善类型的概率 x 大于阈值 p_friend,则认为该内容属于非不友善内容,那么该举报会被忽略;不满足以上条件的内容,我们会进行多次人工审核判断,人工审核后的判断标准也会用于下一轮模型的迭代和升级。
我们重视每一个举报,并根据举报内容增强瓦力可识别的范围和准确度,还会每日人工复核知友们的举报,针对可能存在不同处理意见的举报,会根据规范与实际的应用场景多次复审。在这里,我们也非常感谢知友们的每一次举报,感谢大家与我们一起并肩维护社区氛围,我们也正是在知友们的举报中逐渐形成统一的判断标准。
全量内容的处理策略
我们会对每天新产生的内容进行全量审核,每天可以实时拦截处理 3,000 条内容。在实际的操作过程中,我们发现全量内容有如下两个特点使其不能跟举报内容共用模型和策略:
不友善样本和非不友善样本分布非常不均衡;
词语分布和举报内容有区别。比如,举报内容中包含「SB、NC」之类的脏词的基本属于不友善类型;但是在全量内容中脏字、脏词可能出现在影视作品讨论、陈述自己的经历等场景等非不友善内容中,例如:坑到你头皮发麻。———《鲁班智商二百五》
由于数据不均衡、数据排查标注成本较高和上述数据的分布特点,全量内容模型要做到准确率 98% 以上非常困难,因此我们根据人工审核量,选择一个适宜的阈值,在保证每天召回量的基础上,维持召回内容的处理准确率到 80% 以上,并将召回的内容进行人工审核。
知乎社区不友善文本识别系统基本框架
目前,不友善内容处理系统架构如下图所示(以知友举报内容识别识别系统为例,全量内容识别系统与其类似)
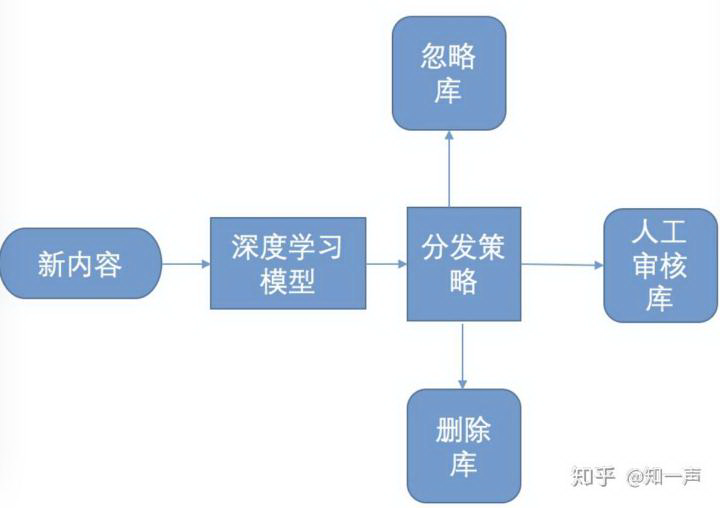
图 1 不友善内容处理系统框图
我们在选择模型时在小批量数据集上对比了 lstm 模型、svm 和朴素贝叶斯模型,lstm 模型表现最好,因此我们的模型优化工作主要集中在深度学习模型上。
词向量
将词用「词向量」表示是深度学习模型处理 NLP 问题的关键一步,我们的系统中使用 Google 提出的 word2vec 词向量模型,训练数据采用来自知乎社区 300 多万条真实的提问、评论、回答数据,内容涉及娱乐、政治、新闻、科学等各个领域,词向量维度采用 128 维,训练模型窗口大小 5。
Word2vec 的原理和使用方法这里就不做过多介绍了,有兴趣的可以阅读文献[1],Python 版本实现的可以参考 gensim官方文档。
text-cnn
TextCNN 是利用卷积神经网络对文本进行分类的算法,2014 年由 Yoon Kim 提出(见参考[3])。 TextCNN 的结构比较简单,其模型的结构如下图:
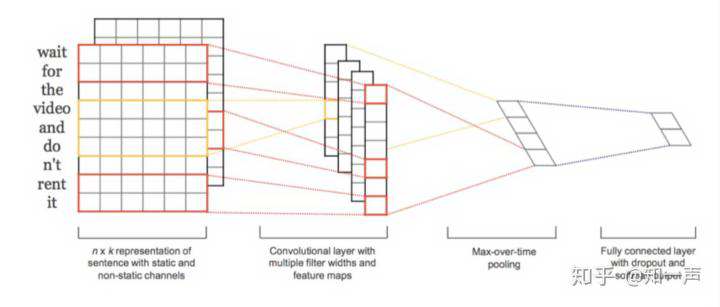
图 2 text-cnn 网络结构
下面分别介绍每一层:
Embedding Layer——该层将输入的自然语言编码成 distributed representation,我们的模型该层使用 word2vec 预先训练好的词向量,同时该层设置为 trainable。
Convolution Layer——这一层主要是通过卷积,提取文本的 n-gram 特征,输入文本通过 embedding layer 后,会转变成一个二维矩阵,假设文本的长度为 |T|,词向量的大小为 |d|,则该二维矩阵的大小为 |T|x|d|,接下的卷积工作就是对这一个 |T|x|d| 的二维矩阵进行的。卷积核的大小一般设为 n x |d|,n 是卷积核的长度,|d| 是卷积核的宽度(LP 中通常取词向量的维度)。我们的模型中 n 取 [2,3,4,5]4 个值,每个值固定取 128 个 filter。
Max Pooling Layer——最大池化层,对卷积后得到的若干个一维向量取最大值,然后拼接在一块,作为本层的输出值。如果卷积核的 size=2,3,4,5 每个 size 有 128 个 filter,则经过卷积层后会得到 4x128 个一维的向量,再经过 max-pooling 之后,会得到 4x128 个 scalar 值,拼接在一块,最终得到一个 512x1 的向量。max-pooling 层的意义在于对卷积提取的 n-gram 特征,提取激活程度最大的特征。
Fully-connected Layer——将 max-pooling layer 后再拼接一层,作为输出结果。实际中为了提高网络的学习能力,可以拼接多个全连接层。
Softmax——根据类别数目设定节点数,我们不友善文本识别项目是二分类问题,设置一个节点,激活函数选择 sigmoid。
Bi-LSTM
CNN 最大问题是固定 filter_size 的视野,无法建模更长的序列信息,自然语言处理中更常用的是 RNN,因为 RNN 能够更好的表达上下文信息。在文本分类任务中,由于语句过长,会出现梯度消失或梯度爆炸的问题,基本的 RNN 网络难于处理语言中的长程依赖问题,为了解决这个问题,人们提出了 LSTM 模型。我们在对比 LSTM 和 Bi-LSTM 效果后选择了 Bi-LSTM,Bi-LSTM 从某种意义上可以理解为可以捕获变长且双向的「n-gram」信息。图 3 是 Bi-LSTM 用于分类问题的网络结构,黄色的节点分别是前向和后向 RNN 的输出,示例中的是利用最后一个词的结果直接接全连接层 softmax 输出了。我们的实际使用的网络结构在全联接层之后加了一层 dropout 层,dropout 输出接 sigmoid 二元分类层。RNN、LSTM、BI-LSTM 可以参考文献[4]。
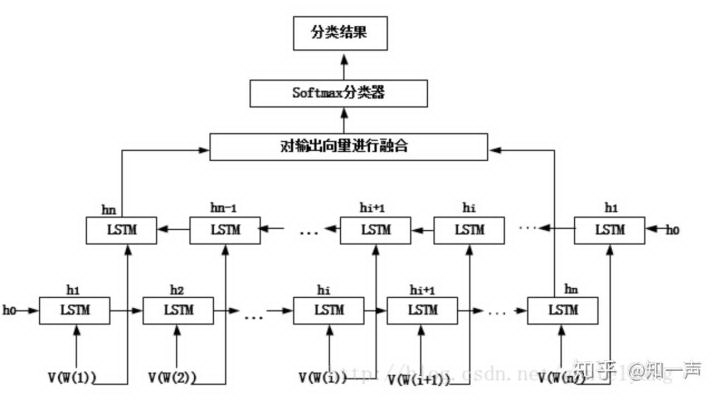
图 3 用于文本分类的双向 LSTM 网络结构
CNN-LSTM
我们参考论文 A C-LSTM Neural Network for Text Classification 来实现 CNN-LSTM 文本分类模型,模型的网络结构如下所示(该图直接来自论文)
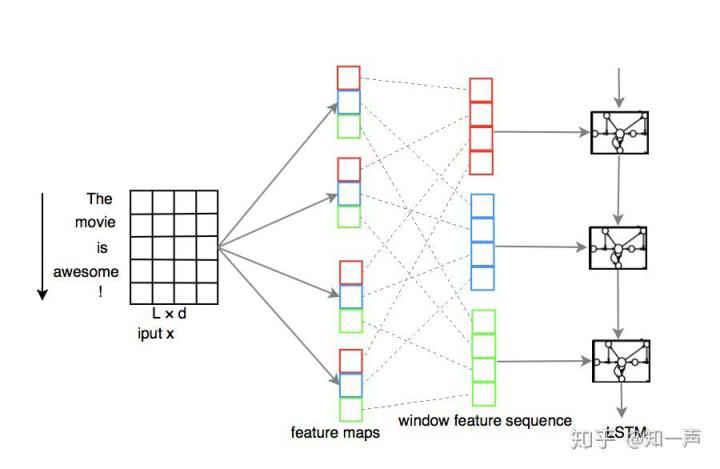
图 4 CNN-ISTM 网络结构
模型用 CNN 对文本的词向量以某一长度的 filter 进行卷积抽取特征,这样原来的纯粹词向量序列就变成了经过卷积的抽象含义序列。最后对原句子的 encoder 使用 lstm,由于使用了抽象的含义向量,因此其分类效果将优于传统的 lstm,这里的 CNN 可以理解为起到了特征提取 N-gram 的作用。
效果
举报的内容
知友举报内容不管是直接删除还是直接忽略,都要求算法有较高的准确率(本文准确率没有特别说明的情况下指 precision),经过对比不同模型的评测效果,目前线上选用模型和准确率、召回率如下:
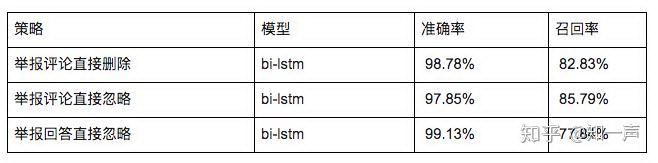
全量内容
经过模型调优和对比不同模型的评测效果,目前线上使用的模型和准确率、召回率如下:
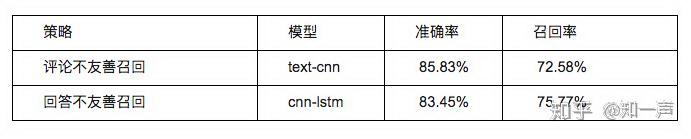
后续工作
我们会利用更多数据模型,尝试更复杂定神经网络并进行语义分析。通过分析实际操作中的 bad case 可以发现,有些文本带有脏字、脏词但并不属于不友善类别,同时也存在一些很隐晦的不友善内容,主要有以下三类:
影视、社会热点事件讨论中,评价影视作品中的人物或者热点事件当事人,例如:这个视频难道不是货车司机的错,有时候又想去延安路龙翔桥附近斑马线前停一天车,MDZZ 规定。
陈述自己等经历,例如:我当时竟然信了,觉得当时的自己就是 FJ 。
诙谐词语或反语,例如:你真聪明,连这都不会;有哪些人工 ZZ 发明。
我们会继续尝试用深度学习做语义分析,对文本进行语义角色标注(见参考文献[6]),抽取句子的施事者(Agent)、受事者(Patient)、客体及其对应的描述词;通过语义相似度构建语义词典;将语义信息融合到我们的不友善文本识别模型中。
以上是算法关于不友善识别的原理和策略,希望我们对社区良好氛围的维护,可以更好的帮助大家在这里分享知识、经验和见解。如果各位知友想继续和我们深度讨论,也可以私信联@知一声 哦。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论