

4 月 30 日,谷歌宣布开源 TensorFlow RunTime (TFRT),这是其 TensorFlow 机器学习框架的一个新运行时,它提供了统一的、可扩展的基础架构层,在各种硬件上都具有高性能。TFRT 可以减少开发、验证和部署企业级模型所需的时间。并且,谷歌方面透露 TFRT 未来有望取代现有 TensorFlow 运行时。
现有 TensorFlow 运行时将被取代
TensorFlow 的根本意义,在于简化用户在多种设备之上构建以及部署机器学习模型的具体流程。但“构建及部署 ML 模型”的具体含义会随时间发生变化,并不断受到机器学习生态系统发展与演进的影响。
在 TensorFlow 堆栈的上半部分,持续出现的创新成果带来了更复杂的模型与部署方案。越来越多需要巨量算力的全新算法从研究人员手中诞生,并由应用程序开发者在跨边缘/服务器层面用于增强自己的开发成果。
而在堆栈的下半部分,由于摩尔定律逐渐失效,计算需求与计算成本增长带来的压力逼近各半导体厂商不得不针对特定 ML 用例开发新型硬件。时至今日,各大传统芯片制造商、初创企业以及软件公司(包括谷歌)都已经在投资研发自己的 AI 专用型芯片。
结果就是,机器学习生态系统的需求与 4 到 5 年之前 TensorFlow 刚刚诞生时完全不同。虽然我们从 2.x 版本开始就一直在保持项目迭代,但目前的 TensorFlow 堆栈才刚刚针对图执行进行过优化,且在分派单一操作时会产生不小的资源开销。
很明显,要延续当前发展趋势并在未来继续支撑各类创新举措,用户们迫切需要一套高性能的低级运行时。
因此,谷歌今天宣布开源了新的运行时 TFRT。
GitHub 开源地址:https://github.com/tensorflow/runtime
作为新的 TensorFlow 运行时,TFRT 的核心目标,是为各类专用性质的 AI 硬件提供具有上佳性能水平的统一、可扩展基础架构层。TFRT 能够高效利用多线程 CPU、支持全异步编程模式,同时专注于低级执行效率。
谷歌表示,TFRT 将能够满足研究人员在急切模式下开发复杂的新模型时希望获得更快的迭代速度与更好的错误报告的需求,以及助力应用程序开发人员在模型的训练与生产支持过程中获得更好的性能表现。此外,它还能帮助硬件制造商以模块化方式将边缘与数据中心内设备整合至 TensorFlow 当中。
简而言之就是,TFRT 可以减少开发、验证和部署企业级模型所需的时间,调查显示,这种模型的时间从几周到几个月(或几年)不等。
它还可能击败 Facebook 的 PyTorch 框架。后者是 OpenAI、Preferred Networks 和优步(Uber)等公司广泛使用的框架。
TFRT 在 GitHub 上以开源的形式发布之前,在今年早些时候举行的 2020 TensorFlow 开发峰会上,TFRT 在一次关键的基准测试中加速了核心循环。
TFRT 产品经理 Eric Johnson 表示,TFRT 将取代现有的 TensorFlow 运行时。
TFRT 是什么?
TFRT 是一种新的运行时方案。它负责在目标硬件上高效执行内核(特定于某些设备的低级基元)。
通过以下 TensorFlow 训练堆栈简化图,可以看到 TFRT 在急切执行与图执行当中都扮演着至关重要的角色:
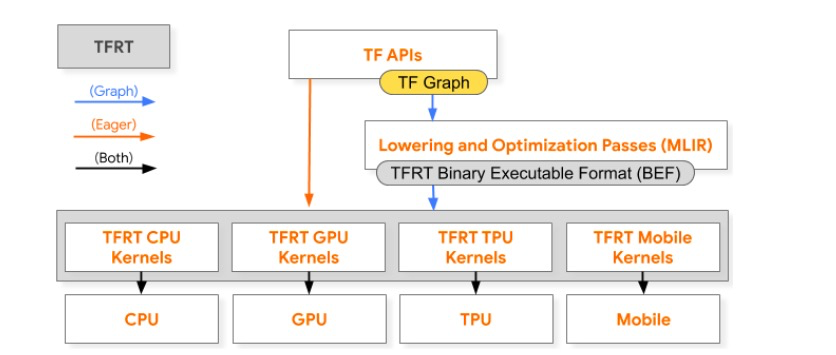
TFRT 在 TensorFlow 训练堆栈的图与急切执行中扮演的角色
请注意,所有灰色元素都属于 TFRT 的组成部分。
在急切执行时,TensorFlow API 会在 TFRT 中直接调用;而在图执行中,程序的计算图会转化为针对特定目标进行优化的专用程序,并被分派给 TFRT。
在这两种执行路径当中,新的运行时都会调用一组内核,这些内核负责调用底层硬件以完成模型执行,具体如黑色箭头所示。
设计要点
现有 TensorFlow 运行时最初是专为图执行与训练类工作负载所构建的;而在新的运行时中,急切执行与推理则成为核心负载类型,执行需求放在第一位,同时高度强调架构的可扩展性与模块化要素。
更具体地讲,TFRT 在设计当中包含以下关注要点:
为了获得更高性能,TFRT 采用无锁图执行器。该执行器能够以较低的同步开销支持并发操作执行,并可凭借经过简化的急切操作调度堆栈异步执行急切 API 调用,同时显著提高执行效率。
为了降低 TensorFlow 堆栈的扩展难度,TFRT 将设备运行时与主机运行时(分别负责驱动主机 CPU 与 I/O 工作负载的核心 TFRT 组件)区分开来。
为了保证行为一致性,TFRT 在急切执行与图执行之间使用通用抽象定义,包括形状函数及内核等。
借助 MLIR 的力量
TFRT 亦与 MLIR 紧密集成。例如:
TFRT 利用 MLIR 编译器基础架构为运行时执行的计算图生成针对特定目标经过优化的表示。
利用 MLIR 的可扩展类型系统,TFRT 得以在运行时中支持任意 C++类型,消除了以往只支持特定张量的局限性。
TFRT 与 MLIR 的结合,将改善 TensorFlow 的统一性、灵活性以及可扩展性。
初步成果
从结果来看,推理与服务用例的初步性能表现令人振奋。
作为 TensorFlow Dev Summit 2020 基准测试研究的一部分,谷歌将 TFRT 与 TensorFlow Serving 集成起来,并测量了向模型发送请求并返回预测结果的具体时长。
在测试中,谷歌选择了通用型 MLPerf 模型 ResNet-50,并将批处理大小设定为 1、数据精度设定为 FP16,借此保证将研究重点放在与运行时相关的操作调度开销身上。
谷歌表示,在性能测试中,TFRT 将训练过的 ResNet-50 模型(一种流行的图像识别算法)在显卡上的平均推理时间与 TensorFlow 当前运行时相比提高了 28%。
TFRT 产品经理 Eric Johnson 和 TFRT 技术负责人 Mingsheng Hong 在博客中表示,“这一早期结果验证了 TFRT 的不俗实力,我们希望它能大大提高性能”,“高性能、低水平的运行时是实现当今趋势和推动未来创新的关键,TFRT 将使广大用户受益“。
下一步目标
据了解,TFRT 已经被集成在 TensorFlow 当中,初步以可选形式启用,确保开发团队能有时间继续修复错误并进一步完成性能调优。
目前,TFRT 仍处在早期开发阶段,目前对 TFRT GitHub 存储库的贡献有限,且在稳定的 TensorFlow 版本中尚不提供 TFRT。但谷歌表示,它将很快通过一个 opt-in 标志实现。
最终,TFRT 将成为 TensorFlow 的默认运行时。
延伸阅读:
https://blog.tensorflow.org/2020/04/tfrt-new-tensorflow-runtime.html

InfoQ记者

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论