

最近讨论过数据层传感器融合问题,特别是最近采用深度学习方法估计深度图的方法。主要是激光雷达等深度传感器的数据比较稀疏分辨率低(特别是便宜的低线束激光雷达),好处是数据可靠性高;而摄像头传感器获取的图像比较致密并分辨率高,缺点是获取的深度数据可靠性差。下面介绍一下最近看到的深度学习方法。
“HMS-Net: Hierarchical Multi-scale Sparsity-invariant Network for Sparse Depth Completion ”2018
密集的深度线索对于各种计算机视觉任务很重要。在自动驾驶中,激光雷达传感器用于获取车辆周围的深度测量值以感知周围环境。然而,由于其硬件限制,激光雷达的深度图通常是稀疏的。最近深度图完整吸引了越来越多的关注,其目的是从输入的稀疏深度图生成密集的深度图。
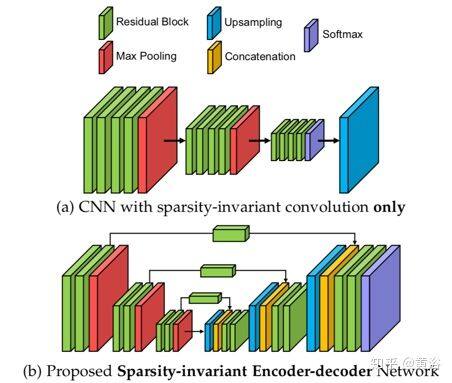
为了有效利用多尺度特征,这里提出 3 种稀疏性不变(sparsity-invariant)操作。基于此,稀疏不变(sparsity-invariant)分层多尺度编码器/解码器网络(hierarchical multi-scale encoder-decoder network,HMS-Net)用于处理稀疏输入和稀疏特征图。可以合并其他 RGB 特征,以进一步提高深度完整系统的性能。
如图所示:(a)稀疏不变卷积的 CNN 只能逐渐对特征图进行下采样,在以后阶段失去大量分辨率;(b)提出的稀疏不变编码器-解码器网络可以有效地融合来自不同层的多尺度特征做深度完整。
以下依次是三个稀疏不变操作:(a) 稀疏不变双线性上采样、(b) 稀疏不变叠加、和 © 联合稀疏不变的联结和卷积。
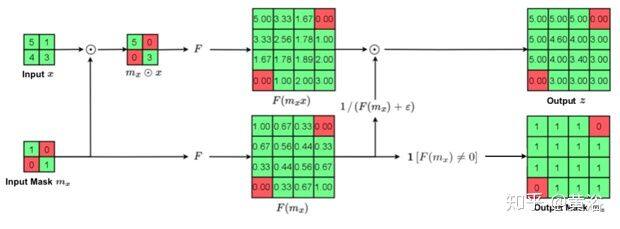
a
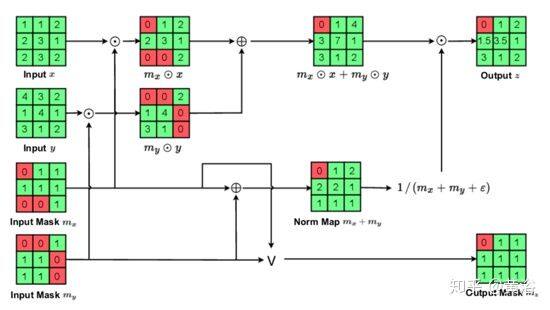
b
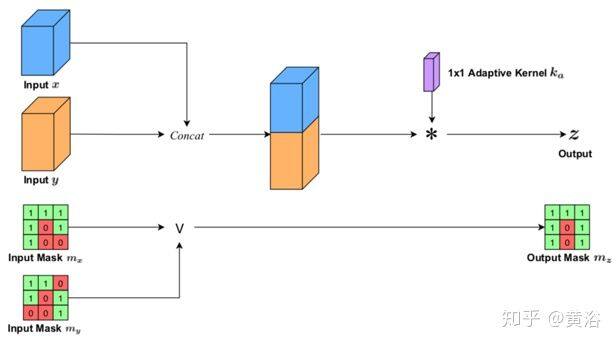
c
之前用于密集像素分类的多尺度编码器-解码器网络结构有 U-Net、特征金字塔网络(FPN)和全分辨率残差网络(FRN)。将稀疏不变卷积直接集成到这些多尺度结构不可行,因为那些结构还需要其他操作做多尺度特征融合,如稀疏不变特征上采样,加法和串联。
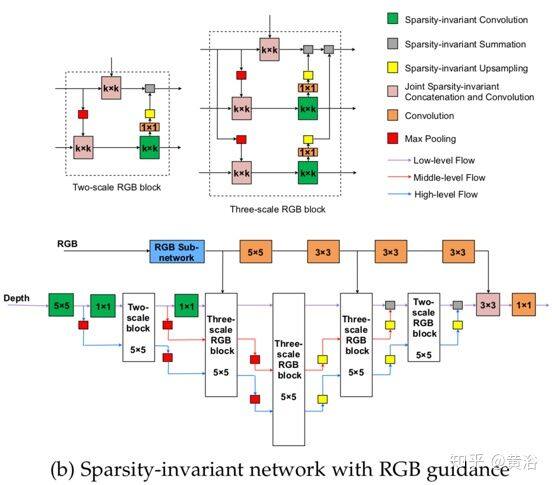
如图是基于上述三个稀疏不变操作的的分级多尺度编码器-解码器网络(HMS-Net)结构,用于深度图完整化,(a)是不带 RGB 引导的架构,(b)是带 RGB 引导的架构。
图(a)提出两个基本构建块,一个 2-尺度块和一个 3-尺度块,由稀疏不变操作组成。2-尺度块具有一条上路径,通过 k×k 稀疏不变卷积非线性地变换全分辨率低层特征。而一条下路径将下采样的低层特征作为输入,通过另一个 k×k 卷积学习高层特征(k = 5)。然后,对生成的高层特征进行上采样,并添加到全分辨率低层特征。与 2-尺度块相比,3-尺度块将特征从两个较高层融合到上低层特征路径中,利用更多辅助的全局信息。这样,全分辨率的低层特征可以有效地与高层信息融合在一起,并经过多次非线性转换学习更复杂的预测函数。最终网络在第一层运行 5×5 稀疏不变卷积;生成的特征经过 3-尺度块,然后做稀疏不变最大池化,再进行三次上采样生成全分辨率特征图。最终特征图通过一个 1×1 卷积层转换生成最终的逐像素预测结果。
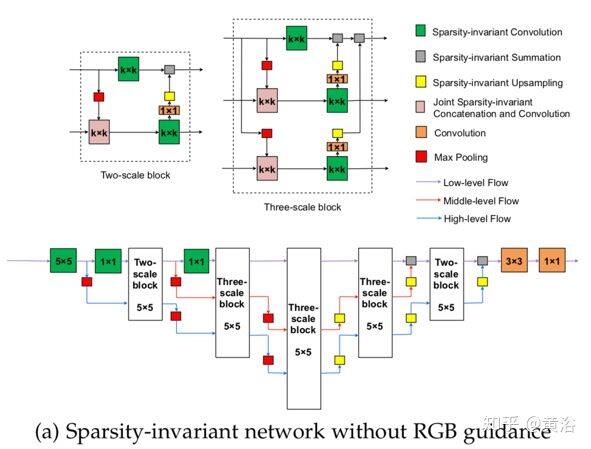
图(b)输入图像首先由 RGB 子网络处理得到中层 RGB 特征。子网的结构遵循 ERFNet 的前六个模块,由两个下采样模块和四个残差模块组成。下采样块有 2×2 卷积层(步幅为 2)和 2×2 最大池化层。输入特征同时馈入到两层,其结果沿着通道维联结在一起,获得 1/2 大小的特征图。残差块的主路径有两组:1×3 conv → BN → ReLU → 3×1 conv → BN → ReLU。由于中层 RGB 特征下采样至原始大小的 1/4,因此它们会被放大到输入图像的原始大小。通过一系列卷积对上采样 RGB 特征进行转换,充当附加的引导信号,并与不同多尺度块的低层稀疏深度特征图相连。
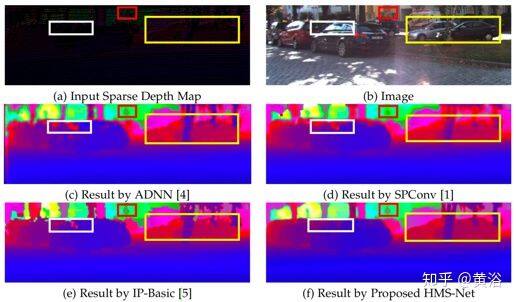
如图是 HMS-Net 和其他方法的实验结果比较:(a)输入稀疏深度图示例,(b)相应的 RGB 图像,(c)ADNN(基于压缩感知)的结果,(d)稀疏不变卷积的结果,(e)手工制作的传统(形态)图像处理方法得出的结果,以及(f)HMS-Net 的结果。
“Sparse and noisy LiDAR completion with RGB guidance and uncertainty”2019.2
这项工作提出了一种新方法,可以精确地完整化 RGB 图像引导的稀疏激光雷达深度图。对于自动驾驶车辆和机器人,必须使用激光雷达才能实现精确的深度预测。大量的应用程序取决于对周围环境的了解,并使用深度线索进行推理并做出相应的反应。一方面,单目深度预测方法无法生成绝对且精确的深度图。另一方面,基于激光雷达的方法仍然明显优于立体视觉方法。
深度完整(depth completion)任务的目标是从稀疏、不规则、映射到 2D 平面的点云生成密集的深度预测。这里提出了一个框架,同时提取全局和局部信息生成适当的深度图。简单的深度完整并不需要深度网络。但是,该文提出一种融合方法,由单目相机提供 RGB 指导,利用目标信息并纠正稀疏输入数据的错误,这样大大提高了准确性。此外,利用置信度掩码考虑来自每种模态深度预测的不确定性。
注:原代码在https://github.com/wvangansbeke/Sparse-Depth-Completion。
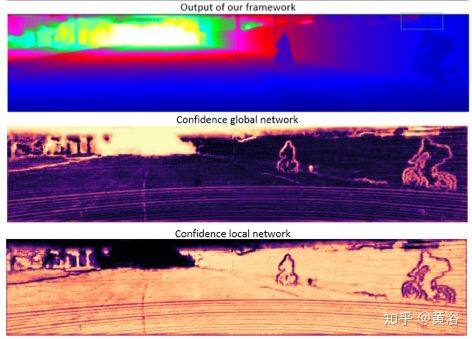
如图所示,该框架由两部分组成:位于顶部的全局分支和位于下方的局部分支。 全局路径输出三个图:引导图,全局深度图和置信度图(guidance map, global depth map,confidence map)。 局部图通过全局网络的引导图预测置信度图)和局部深度图(local depth map)。 该框架在后期融合方法中基于置信度图融合了全局和局部信息。
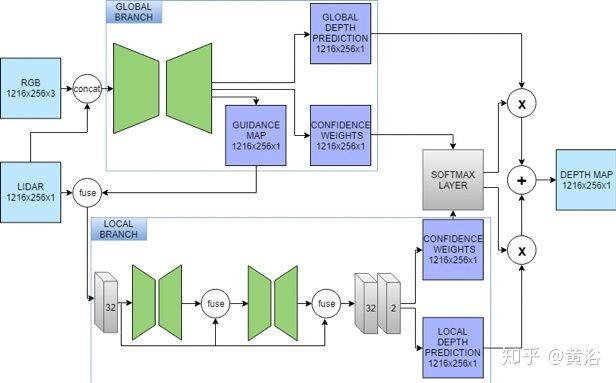
全局网络是基于 ERFNet(实时分割网络模型)的编解码器网络,而局部网络是堆叠的沙漏网络(hourglass network)。后者由两个沙漏模块组成,获得原始深度预测的残差,总共只有 350k 参数。每个模块由六层组成,小感受野,通过跨步卷积(strided convolutions)做两次下采样。在第一个卷积层和第一个沙漏模块的编码器中,没有批次归一化(BN),因为零的数量会使该层的参数产生偏差,尤其是在输入稀疏度变化的情况下。
以利用全局信息,全局引导图与稀疏的激光雷达框架融合在一起,类似于前融合对局部网络的引导。将置信度图与其深度图相乘并添加来自两个网络的预测,可以生成最终预测。置信度图的概率用 softmax 函数计算。该选择过程,从全局深度图选择像素,或者从堆叠的沙漏模块中选择调整的深度值。因此,最终的深度预测 dˆ开发置信度图 X 和 Y。
如图看结果。

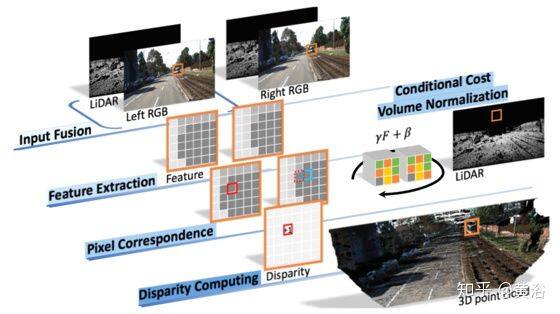
“3D LiDAR and Stereo Fusion using Stereo Matching Network with Conditional Cost Volume Normalization”2019.4
主动和被动深度测量技术的互补特性促使激光雷达传感器和立体双目相机融合,以改善深度感知。作者不直接融合激光雷达和立体视觉模块来估计深度,而是利用带两种增强技术的立体匹配网络:激光雷达信息的输入融合和条件成本容积归一化(Conditional Cost Volume Normalization,CCVNorm)。 所提出的框架是通用的,并且紧密地与立体匹配神经网络中成本容积组件集成。
如图是 3D 激光雷达和立体视觉融合方法的插图。立体匹配流水线的概念包括立体图像对 2D 特征提取、像素对应以及最终视差计算。与立体匹配网络紧密集成的(1)输入融合和(2)条件成本容积归一化(CCVNorm)。 通过利用激光雷达和立体视觉模块的互补性,该模型可以生成高精度的视差估计。
3D LiDAR 和立体融合框架的概述如图所示:(1)输入融合,将稀疏的激光雷达深度的几何信息与 RGB 图像结合起来,作为成本计算阶段的输入,学习联合的特征表示;以及(2)CCVNorm 代替批量归一化 (BN)层,在立体匹配网络的成本正则化(Regularization)阶段以激光雷达数据为条件调制成本容积特征 F。
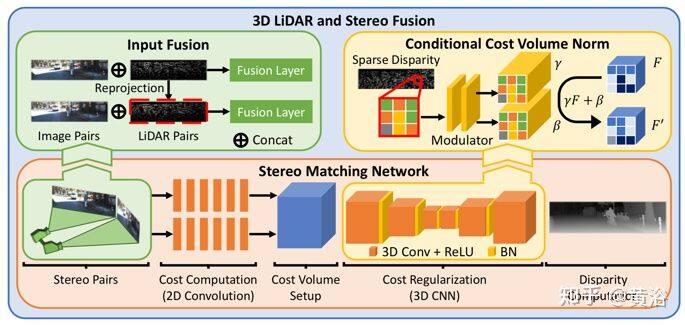
在立体匹配网络的成本计算阶段,立体双目对的左图像和右图像都经过卷积层以提取特征。在输入融合(Input Fusion),通过深度变成视差的三角化原理,将激光雷达扫描重新投影到左右图像坐标转换为深度,从而形成与立体图像相对应的两个稀疏激光雷达深度图。
而将稀疏的激光雷达深度点信息纳入立体匹配网络的成本正则化阶段(即 3D-CNN),学习去减少匹配的搜索空间并解决多义性问题。
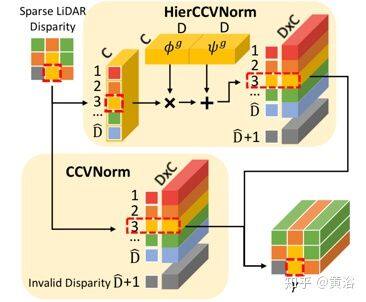
受条件批量归一化(Conditional Batch Normalization,CBN)的启发,这里条件成本容积归一化(CCVNorm)将稀疏的激光雷达信息编码为 4-D 成本容积的 C×H×W×D 特征。由于以下三点考虑,在立体匹配网络中直接将 CBN 直接应用于 3D-CNN 可能会引起问题:(1)设置的条件输入是一个稀疏图,其像素间的值一直变化 ,这意味着归一化参数按像素进行; (2)需要一种替代策略来解决稀疏图中包含的无效信息; (3)稀疏图中的有效值对成本容积的每个视差级有不同的贡献。因此,CCVNorm 根据成本特性更好地协调 3D 激光雷达信息,以解决上述问题。
这里采用两种不同的方法构造 CCVNorm:
1) 分类 CCVNorm(categorical CCVNorm):构造一个 Dˆ-条目查找表,每个元素作为 D×C 向量,将激光雷达值映射到不同特征通道和视差级别的归一化参数{γ,β},其中激光雷达深度值离散化为 Dˆ 级的条目索引。
2) 连续 CCVNorm(Continuous CCVNorm):用 CNN 将稀疏激光雷达数据与 D×C 通道的归一化参数之间连续映射建模。这里用 ResNet34 的第一个块编码激光雷达数据,然后分别在不同层对 CCVNorm 进行一次 1×1 卷积。
为了减小模型大小,文中提出 CCVNorm 的分层扩展,即 HierCCVNorm。如图是 CCVNorm 的示意图。每个像素(红色虚线框),基于相应激光雷达数据的离散视差,分类 CCVNorm 从 Dˆ条目查找表中选择调制参数γ,而无效值的激光雷达点采用附加参数集单独处理(灰色表示)。 另一方面,HierCCVNorm 通过 2 步分级调制生成γ。
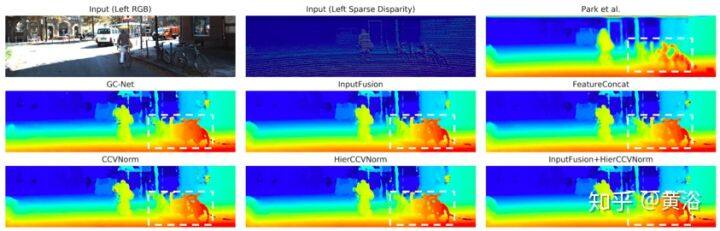
如图显示的是,该方法与其他基准方法及其变型相比,通过利用激光雷达和立体视觉模块的互补特性来捕获复杂结构区域(白色虚线框)中的细节。
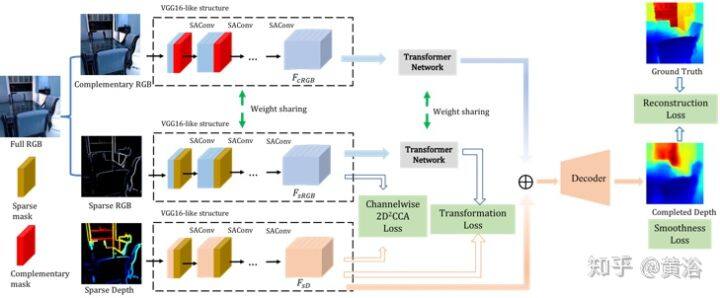
“Deep RGB-D Canonical Correlation Analysis For Sparse Depth Completion”2019.6
完整关联网络(Correlation For Completion Network,CFCNet)是一种端到端的深度模型,用 RGB 信息做稀疏深度完整化。2D 深度规范相关性分析(2D deep canonical correlation analysis,2D2CCA),作为网络约束条件,可确保 RGB 和深度的编码器捕获最相似语义信息。
该网络将 RGB 特征转换到深度域,并且互补的 RGB 信息用于完整丢失的深度信息。完整的密集深度图被视为由两部分组成。一个是可观察并用作输入的稀疏深度,另一个是无法观察和恢复的深度。
同样,相应深度图的整个 RGB 图像可以分解为两部分,一个称为稀疏 RGB,在稀疏深度可观察位置保留相应的 RGB 值,另一部分是互补 RGB(complementary RGB),即从整个 RGB 图像中减去稀疏 RGB 的部分。在训练期间,CFCNet 会学习稀疏深度和稀疏 RGB 之间的关系,并用所学知识从互补 RGB 中恢复不可观察的深度。
如图所示,输入的 0-1 稀疏掩码表示深度图的稀疏模式。 互补掩码(complementary mask)与稀疏掩码互补。通过掩码将整个图像分为稀疏 RGB 和互补 RGB,然后将它们与掩码一起馈入网络。CFCNet 接受稀疏深度图,稀疏 RGB 和互补 RGB。在类似 VGG16 的编码器中使用稀疏-觉察注意卷积(Sparsity-aware Attentional Convolutions,SAConv)。
SAConv 受到局部注意掩码(local attention mask,LAM)的启发,LAM 引入了分割-觉察掩码(segmentation-aware mask),使卷积“聚焦”在与分割掩码一致的信号上。如图是 SAConv 架构图。 ⊙Hadamard 积,⊗卷积, +逐元加法。 对于卷积和最大池化,其内核大小 3×3,步幅(stride)1。
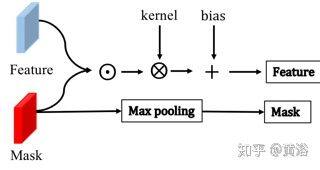
为了传播来自可靠来源的信息,用稀疏性掩码(sparsity masks)使卷积操作参与来自可靠位置的信号。与局部注意掩码 LAM 的区别在于,SAConv 不应用掩码归一化,它会影响之后 2D2CCA 的计算稳定性,原因是多次归一化后它产生的数值较小的提取特征。此外,在 SAConv 之后对掩码使用最大池化操作以跟踪其可见性。如果卷积核可见至少一个非零值,则最大池化将在该位置处计算得到值为 1。
规范相关性分析(canonical correlation analysis ,CCA)是一种标准的统计技术,学习跨多个原始数据空间的共享子空间。对于两种模态,从共享子空间来看,每个表示形式对另一个的预测最强,而另一个的可预测性也最高。在小样本高维空间(high-dimensional space with small sample size,SSS)情况下,单向 CCA(one-directional CCA)方法会遇到协方差矩阵的奇异性问题。所以,现在的方法已将 CCA 扩展为双向(two-directional)方式,以避免 SSS 问题。
大多数多模态深度学习方法只是联结或逐元添加瓶颈特征。但是,当元素之间提取的语义和特征数值范围不同时,多模态数据源的直接联结接和添加不会比单模态数据源产生更好的性能。为避免此问题,这里用编码器从两个分支提取更高级别的语义,2D2CCA 确保从两个分支提取的特征具有最大的相关性。
直觉告诉我们,从 RGB 和深度域要捕获相同的语义。接下来,用变换器网络(transformer network)将提取的特征从 RGB 域转换为深度域,使不同来源提取的特征共享相同的数值范围。在训练阶段,用稀疏深度和相应的稀疏 RGB 图像特征来计算 2D2CCA 损失和转换器损失。
双向 CCA 的协方差矩阵为:
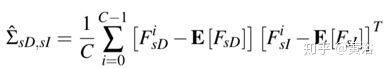
其中
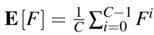
而正则化常数 r1 和单位矩阵 I 的协方差矩阵为
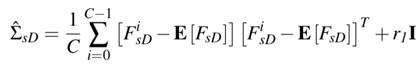
这样,图像和深度特征之间的相关性,为
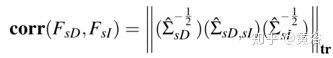
2D2CCA 的损失即为−corr(FsD , *FsI *) 。而整个损失函数是:
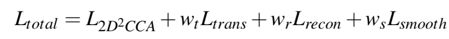
如图是一些结果例子:(a)RGB 图像,(b)500 点稀疏深度作为输入,(c)完整深度图。 (d)MIT 方法的结果。
“Confidence Propagation through CNNs for Guided Sparse Depth Regression“ 2019.8
通常,卷积神经网络(CNN)可在规则网格(例如网格)上处理数据,即普通相机生成的数据。设计用于稀疏和不规则间隔输入数据的 CNN 仍然是一个开放的研究问题。
本文有几个特点:
1) 提出的代数约束归一化卷积层,针对稀疏输入数据的 CNN,相对来说网络参数量较少。
2) 提出从卷积运算确定置信度并将其传播到后继层的策略。
3) 定义一个目标函数,可同时最小化数据误差最大化输出置信度。
4)为了集成结构信息,提出融合策略,可以在标准化卷积网络框架中结合深度和 RGB 信息。5)使用输出置信度作为辅助信息来改善结果。
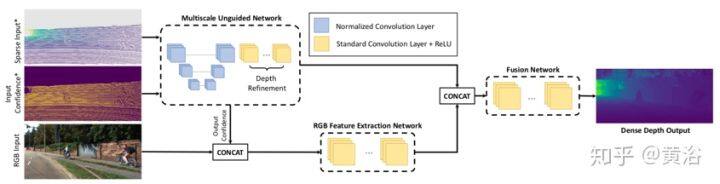
如图是示例图像的场景深度完整化的流水线。流水线的输入是一个非常稀疏的投影激光雷达点云、一个输入置信度图(在缺失像素处为 0,否则为 1)以及一个 RGB 图像。 输入稀疏点云和置信度被馈送到多尺度无引导(unguided)网络,其作为数据的通用估计器。 然后,将连续输出置信度图与 RGB 图像连接起来,并馈入特征提取网络。来自非引导网络和 RGB 特征提取网络的输出联结在一起馈送到融合网络,生成最终的密集深度图。
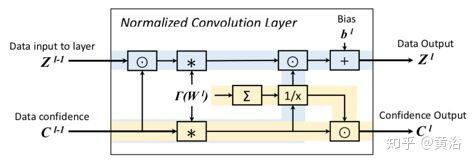
CNN 框架的标准卷积层可用少量修改的归一化卷积层代替。 首先,该层同时接受两个输入,即数据及其置信度。 然后修改前向传递(forward pass),并修改后向传播(back-propagation)加入非负强制函数(enforcement function)的导数项。 为了将置信度传播到后继层,已经计算的分母项被滤波器元素之和归一化。如图所示,归一化卷积层接受两个输入即数据和置信度,并输出一个数据项和一个置信度项。
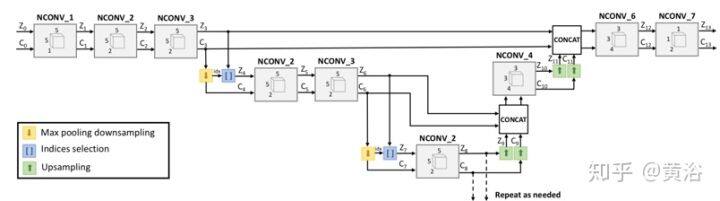
下图是非引导场景深度完整任务中采用归一化卷积层的多尺度体系结构。 用最大池化对置信度图下采样,池化像素的索引用于今后从特征图中选择置信度最高像素。 上采样较粗尺度特征并将其与较细尺度特征连接起来,可以融合不同尺特征。 然后,基于置信度信息归一化卷积层融合特征图。 最后,1×1 归一化卷积层将不同通道合并为一个通道,并生成密集深度图和输出置信度图。
对于引导场景深度完整任务,和两个常用的架构进行比较。如图所示:(a)一种多流体系结构(multi-stream architecture),其中包含一个深度流和一个 RGB +输出置信度特征提取流。 之后,融合网络将两个流合并产生最终的密集输出。(d)一种多尺度编码器-解码器体系结构,其中将深度馈入非引导网络,然后是编码器,随后将输出置信度和 RGB 图像连接起来,馈入相似编码器。两个流在对应尺度之间的解码器设置跳连接。 (c)与(a)类似,不过算早期融合,(b)与(d)类似,但是早期融合。
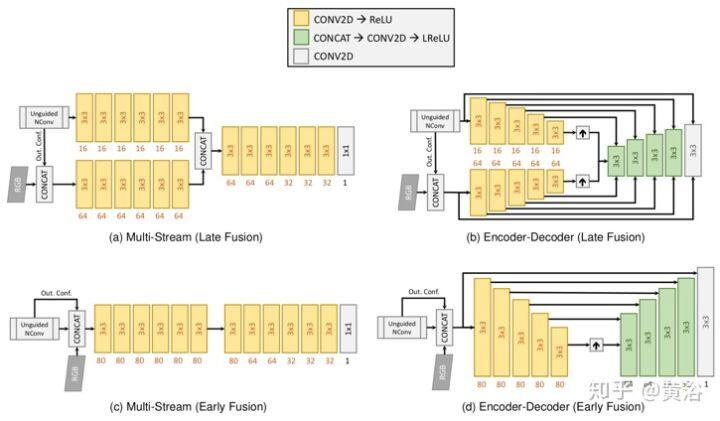
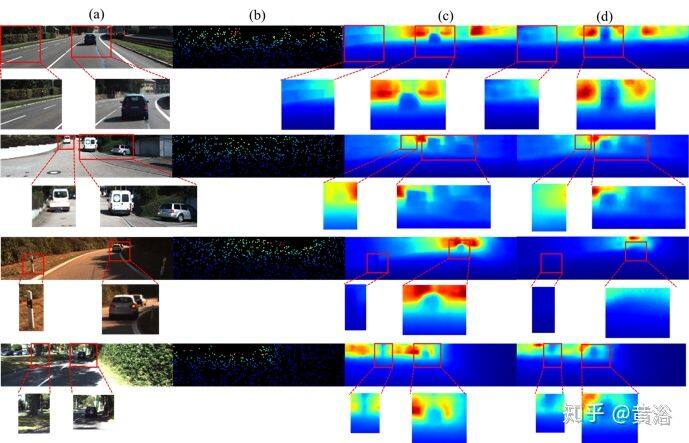
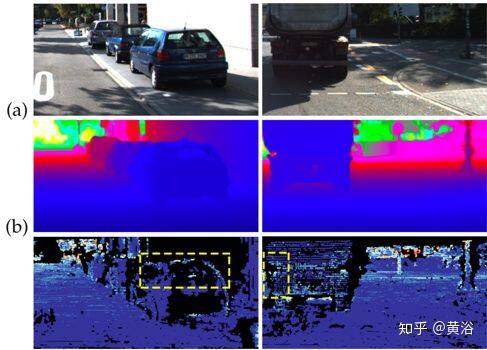
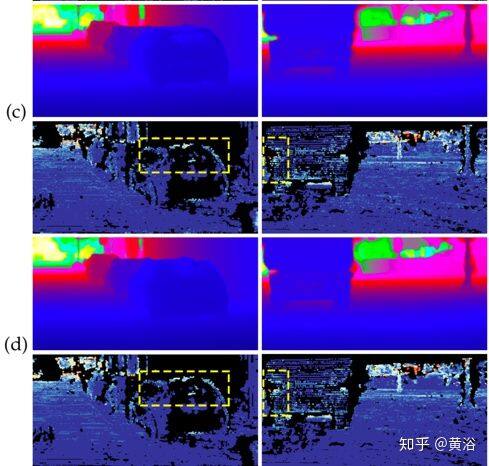
第一个体系结构是早期融合(EF)的多流(MS)网络,称为 MS-Net [EF],其变型为 MS-Net [LF](后期融合)。 第二种架构是编码器-解码器架构,其早期融合表示为 EncDec-Net [EF],其变体是后期融合的 EncDec-Net [LF]。如图是实验结果:(a)RGB 输入,(b)MS-Net [LF] -L2 方法(gd),(c)Sparse-to-Dense(gd)方法,和(d)HMS-Net(gd)方法。对每个预测,方法 MS-Net [LF] -L2(gd)的性能略好,而“Sparse-to-Dense”由于使用平滑度损失而产生了更平滑的边缘。
“Learning Guided Convolutional Network for Depth Completion”2019.8
密集深度感知对于自动驾驶和其他机器人应用至关重要。因此,有必要完整稀疏激光雷达数据,通常同步的引导 RGB 图像促进此完整化。受著名的引导图像滤波(guided image filtering)方法启发,引导网络(guided network)可以从引导图像(guidance image)中预测内核权重。然后将这些预测核用于提取深度图像特征。
以这种方式,一个网络生成内容相关和空间变化的内核,用于多模态的特征融合。此外,动态生成的空间变量内核可能导致 GPU 内存消耗过大和计算开销,而卷积分解可减少计算和内存消耗,这样 GPU 内存的减少使特征融合可以在多步方案中运行。
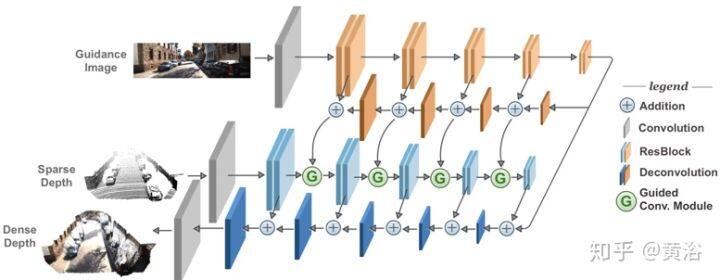
如图所示,该网络体系结构包括两个子网:橙色 GuideNet 和蓝色 DepthNet。 在 GuideNet 和 DepthNet 的开头以及 DepthNet 的末尾添加卷积层。浅橙色和浅蓝色分别是 GuideNet 和 DepthNet 的编码器步,而对应的深橙色和深蓝色是 GuideNet 和 DepthNet 的解码器步。 ResBlock 是两个连续 3×3 卷积层的基本残差块结构。
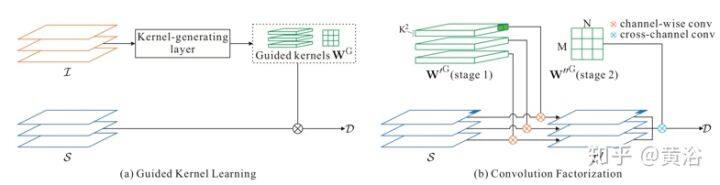
下图是引导卷积模块架构图:(a)引导卷积模块的整体流水线,在给定图像特征输入的情况下,滤波器生成层动态地生成引导核(guided kernels),将其用于输入深度特征并输出新的深度特征;(b)引导核与输入深度特征之间卷积的细节,其分解为两步卷积,即逐通道卷积和跨通道卷积。
内容相关和空间变化内核的优点是双重的。 首先,这种内核允许网络将不同的滤波器用于不同的目标(和不同的图像区域)。因此,根据图像内容和空间位置动态生成内核将很有帮助。 其次,在训练期间,空间不变核的梯度计算为下一层所有图像像素的平均值。这样的均值更可能导致梯度接近于零,甚至觉得学习的内核对于每个位置而言不是最优,这可能会产生次优结果。相比之下,空间变化的内核可以缓解此问题,并使训练表现得更好,从而获得更好的结果。
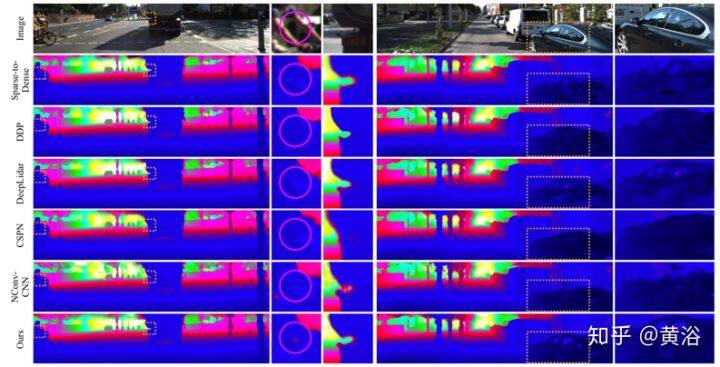
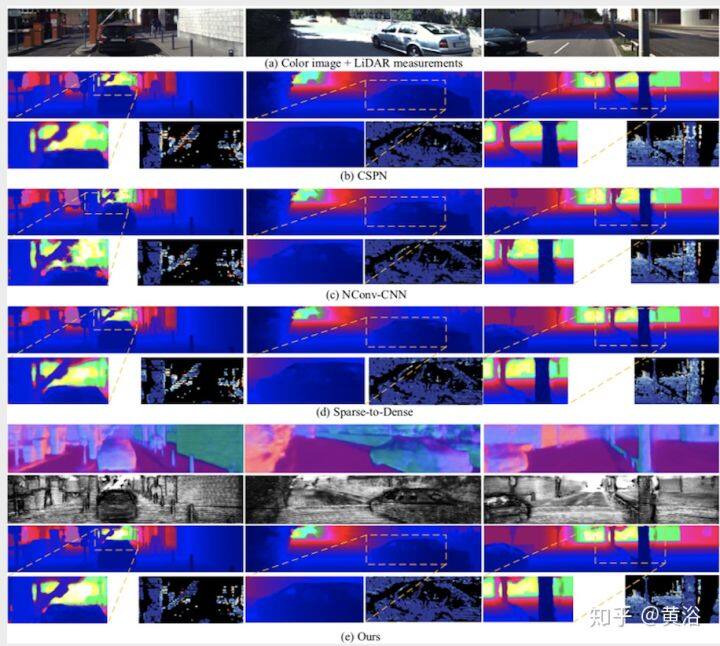
最后是 KITTI 测试集上最新方法的结果定性比较,如图所示:选择的方法有‘Sparse-to-Dense’, ‘DDP’ , ‘DeepLiDAR’, ‘CSPN’和‘NConv-CNN’,以及本文的方法。
“DFineNet: Ego-Motion Estimation and Depth Refinement from Sparse, Noisy Depth Input with RGB Guidance”2019.8
深度估计是自动驾驶汽车了解和重建 3D 环境以及避免障碍的一项重要功能。精确的深度传感器(例如机械式激光雷达)通常很笨重和昂贵,并且只能提供稀疏深度,而较轻的深度传感器(例如,立体双目相机)则相对含噪。
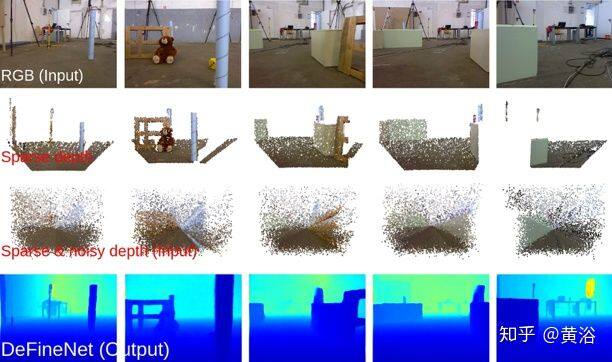
DFineNet 是一种端到端的学习算法,能够用稀疏、含噪的输入深度进行细化和深度填充。该模型输出摄影机姿势作为副产品。如图所示,稀疏、含噪的深度输入(第一行),真实深度的 3D 可视化(第二行)和模型输出的 3D 可视化(底部)示例。 为了可视化,RGB 图像(第 1 张)和有稀疏、含噪的深度输入叠在一起。

再看一个 DFineNet 实例,如图所示:它细化稀疏含噪的深度输入(第三行),并输出高质量的密集深度(下一行)。
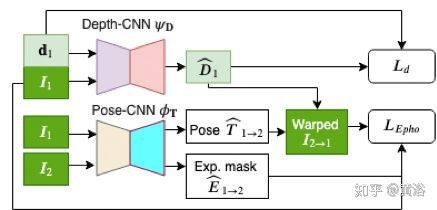
下图是 DFineNet 的架构图。该网络由两个分支组成:一个 CNN 学习估计深度(ψd)的函数,另一个 CNN 学习估计姿势(θp)的函数。其将图像序列和相应的稀疏深度图作为输入,并输出变换以及密集深度图。在训练过程中,训练信号会同时更新两组参数。它是 MIT 深度网络的修正,称为 Depth-CNN,而 Pose-CNN 改编自 Sfmlearner。
训练中整个损失函数表示为
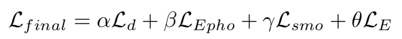
其中平滑损失记为 Lsmo,而监督损失定义为:
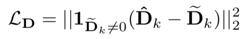
光度损失定义为:
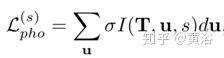
掩码光度损失定义为:
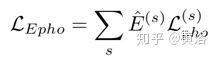
最后是结果:左边是本文方法结果,中间是关于 RGB 引导(第二行)及其不确定性(第三行)的方法结果,最右边是 MIT 方法的结果。

“PLIN: A Network for Pseudo-LiDAR Point Cloud Interpolation”2019.9
激光雷达可以在低频(约 10Hz)下提供可靠的 3D 空间信息,并已广泛应用于自动驾驶和无人机领域。但是,实际应用中具有较高频率(约 20-30Hz)的摄像机必须降低,以便与多传感器系统中的激光雷达匹配。
伪激光雷达内插网络(Pseudo-LiDAR interpolation network,PLIN),用于增加激光雷达传感器的频率。PLIN 旨在解决相机和激光雷达之间的频率不匹配问题,同时生成时空高质量的点云序列。为此,它采用连续稀疏深度图和运动引导的粗内插阶段,以及由真实场景引导的精细内插阶段。这种从粗到细的级联结构,可以逐步感知多模态信息。
如图是 PLIN 的总体流程图。该方法将三个连续彩色图像和两个稀疏深度图作为输入,内插一个中间密集深度图,然后根据相机内参将其进一步转换 Pseudo-LiDAR 点云。
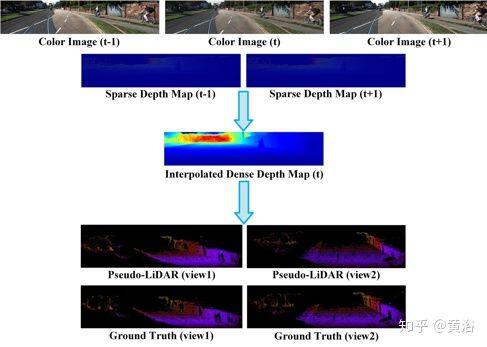
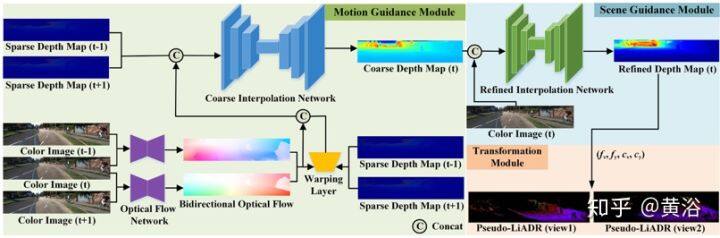
伪激光雷达内插网络(PLIN)概述图如下:整个架构由三个模块组成,即运动引导(motion guidance)模块、场景引导(scene guidance)模块和变换(transformation)模块。首先有一个基准网络(一个编码器-解码器架构)从两个连续稀疏深度图来生成内插图。 然后,为了构造更合理的慢动作结果,用双向光流包含的运动信息来指导内插过程(基于 LiteFlowNet 网络)。此外,对输入的深度图进行扭曲(warping)操作得到中间的粗略深度图,其中包含了显式运动关系。最后中间彩色图像在场景引导下细化粗略的深度图(基于一个轻型 U-Net 网络),从而获得更准确、更密集的中间深度图。
下面是实验展示。如图所示是 PLIN 获得的内插深度图结果:对每个示例,显示彩色图像、稀疏深度图、密集深度图和 PLIN 结果。该方法可以恢复原始深度信息并生成更密集分布。

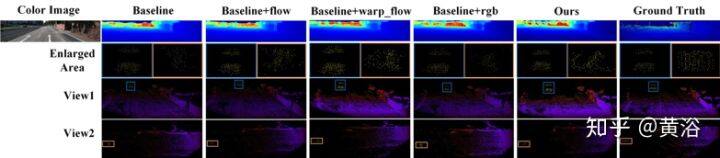
如图显示的结果:从上到下是内插的密集深度图、生成 Pseudo-LiDAR 的两个视图以及放大的区域。完整网络生成更准确的深度图,并且 Pseudo-LiDAR 的分布和形状与真实点云的分布和形状更相似。
“Depth Completion from Sparse LiDAR Data with Depth-Normal Constraints”2019.10
深度完整旨在从稀疏深度测量中恢复密集的深度图。它对自动驾驶的重要性日益增加,并引起了视觉界的越来越多的关注。大多数现有方法直接训练网络学习从稀疏深度输入到密集深度图的映射,这比较难利用 3D 几何约束,以及处理实际传感器噪声。
为了规范化深度完整解法并提高抗噪能力,作者提出一个统一的 CNN 框架:1)在发散模块(diffusion module)中模拟深度和表面法线之间的几何约束,2)预测稀疏激光雷达测量的置信度以减轻噪声的影响。 具体而言,编码器-解码器主干网同时预测激光雷达输入的表面法线、粗深度和置信度,然后将其输入到扩散细化模块(diffusion refinement module)获得最终深度完整的结果。
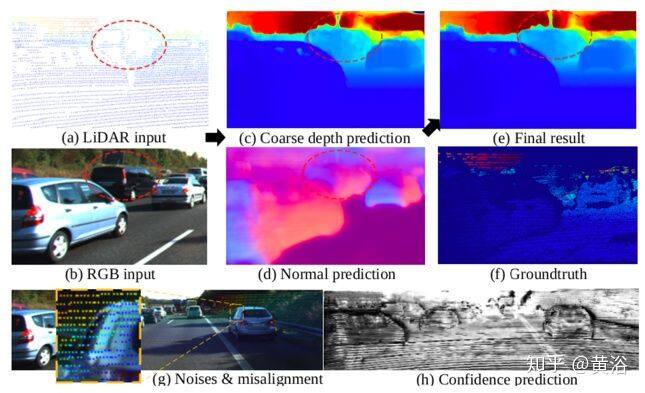
如图所示:从稀疏的激光雷达测量和彩色图像(a-b),该模型首先推断出粗深度和法线图(c-d),然后强制深度和法线之间约束反复细化初始深度估计。 此外,为了解决实际激光雷达测量的噪声(g),用解码器分支预测稀疏输入深度的置信度(h),实现更好的正则化。
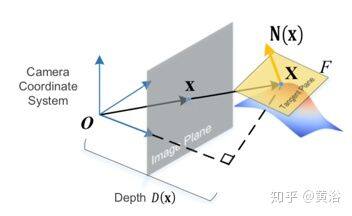
在介绍该统一框架之前,需要简单提一下定义的平面原点距离空间(plane-origin distance space)。X 为 3D 空间点,x 为其在像平面的 2D 投影点。在 3D 点 X 处的表面法线 N(x) 定义为垂直于切平面 F 的向量,其法平面方程为 N(x)·X−P =0。如图所示,切平面方程建立了深度和法线之间关系。P=N(x)·X,称为平面原点距离。
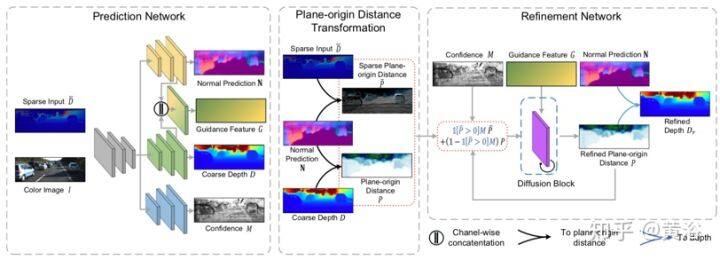
下图是整个框架的概览:预测网络是共享权重编码器和独立解码器,其预测表面法线图 N、粗深度图 D 和稀疏深度输入的置信度图 M。 然后,将稀疏深度输入 D̄和粗略深度 D 转换为平面原点距离空间,分别为 P̄和 P。接下来,细化网络,一个各向异性发散(anisotropic diffusion)模块,在平面原点距离子空间中细化粗略深度图 D 来强制深度和法线之间的约束,并合并置信稀疏深度输入的信息。在细化期间,发散引导度(diffusion conductance)取决于引导特征图 G 的相似性。最后,当发散结束,细化距离 P 逆变换获得细化深度图 Dr。
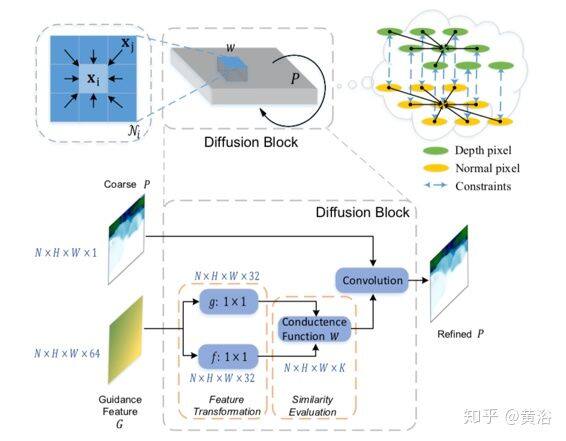
如图是可微分扩散块(Differentiable diffusion bloc)架构图。 在每个细化迭代中,引导特征图(guidance feature map)G 中的高维特征向量(例如,维数为 64),通过两个不同的函数 f 和 g(建模为两个卷积层,然后进行归一化)独立地进行变换。 然后,计算从每个位置 xi(在平面原点距离图 P 中)到其相邻的 K 个像素(xj∈Ni)的引导度。最后,发散经一个卷积运算操作,其内核由先前计算的引导度所定义。通过这种发散,深度完整的结果由深度和法线之间约束而规范化。
这里训练的损失函数定义为:
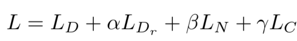
其中重建损失定义为
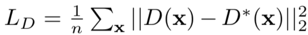
细化重建损失定义为
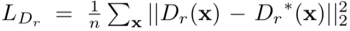
法线预测的损失定义为
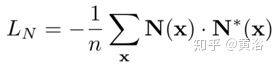
深度损失定义为
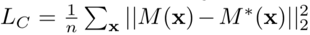
如图是结果展示例子。实际上是与其他三个方法的定量比较:对每种方法,深度完整的结果以及细节和误差的放大图,还有法线预测和置信度预测的结果。
作者介绍
黄浴,奇点汽车美研中心总裁和自动驾驶首席科学家,上海大学兼职教授。曾在百度美研自动驾驶组、英特尔公司总部、三星美研数字媒体研究中心、华为美研媒体网络实验室,和法国汤姆逊多媒体公司普林斯顿研究所等工作。发表国际期刊和会议论文 30 余篇,申请 30 余个专利,其中 13 个获批准。
原文链接
注:本文源自黄浴的知乎:https://zhuanlan.zhihu.com/p/90773462

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论