

本文为Robin.ly授权转载,文章版权归原作者所有,转载请联系原作者。
2019 年 3 月 9 日 Robin.ly 线上技术交流活动特邀 Alluxio 公司创始成员、开源项目 PMC 成员范斌博士,与 Robin.ly 社区成员分享数据架构在过去几十年的演变过程,以及他多年来从事分布式系统研究的经历和体会。
职业经历
今天很高兴来到这里。我叫范斌,是 Alluxio 公司的创始成员和 VP of Open Source。我之前曾经在 Mountain View 的 Google 总部工作并参与了下一代大规模分布式存储系统的开发。在加入 Google 之前,我在 CMU 攻读并获得了计算机科学博士学位,研究课题是分布式系统,网络系统以及相关的算法和性能优化。
Alluxio 最初是加州大学伯克利分校 AMPLab (The Algorithms, Machines and People Laboratory) 的研究项目,由李浩源博士创立。为了让全世界有更多的用户可以从这个开源项目中受益。我们得到了顶级的风险投资包括 Andreessen & Horowitz 的投资,帮助用户简单高效的开发数据驱动的应用程序,如大数据分析,机器学习和 AI 等。
今天我想简单回顾一下数据架构在过去的几十年中的演变,比如人们在不同时期所使用的技术和所面临的问题。
数据架构的演变
初代的大型主机中存储和计算能力是完全耦合在一起的,基本可以实现你需要的所有功能。最开始,人们只是使用大型机进行一些基本的计算。然而随着数据量不断增长,想把所有数据储存在一个地方已经基本不可能了,必须找到一种能够以类似可扩展的方式存储数据的方法。例如,人们提出了 RAID(Redundant Array of IndependentDisks)的概念,即使用多个不同的硬盘来存储数据,吞吐量更大,可靠性也更高。
Garth Gibson 是 RAID 系统的发明者,也是我的博士答辩委员会成员。在八十年代的初期,人们还对需要多个硬盘储存数据这个想法嗤之以鼻,而他们在试图解释这一概念的好处:这是一种用于分配存储的新算法,能够实现更大的数据吞吐量,更好的布局,更优的计算性能。
而当时一个磁盘就已经造价不菲,使得人们没有任何动力去追求更多的硬盘。而现在,它的体积已经变得很小,在任何一个台式机和笔记本电脑中都已经可以装得下多个不同的硬盘,还能连接一些外部存储器。
在上世纪 90 年代起,人们意识到这是大势所趋,于是开始尝试打造多硬盘驱动系统并将不同的应用程序连接到存储系统。那个时候,功能的构建包含两个部分:一部分重点关注如何低成本高效率的存储和提供字节;另一部分是如何构建更高效的 CPU 和服务器,已实现快速有效的处理其他部件所提供的字节。
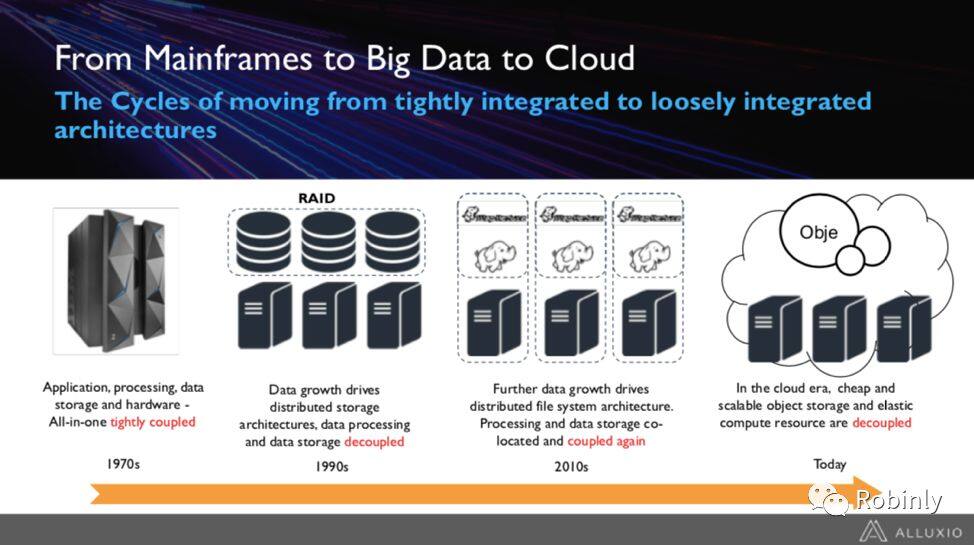
在本世纪头十年间,Google 发表了三篇关于 Google File System,Bigtable 和 MapReduce 的论文,它们被认为是分布式系统领域最经典的文章之一。当时 Google 面临的问题是,有太多的数据要存储,但专用硬件对他们来说太贵了。于是 Google 的工程师们想要找到一种不同的方式储存来自整个互联网的数据。于是他们打算构建一个不同于 Scale Up 模式,而是通过 Scale Out 来保证数据存储的可靠性,同事尽量将存储数据和计算共置。于是 Google 的 Google File System 将数十万台机器组合在一起以提升处理能力和数据吞吐量,用市面上能买到的比较廉价的硬件就能实现,这也就意味着制造成本相对低廉。这个想法在那个时期有着革命性的意义。
由于 Google 的解决方案并没有开源。开源社区的人在读了这些论文之后,认为这些都是很好的想法,于是想要找到一些方法来实现这个计算和存储的模型。Hadoop 协议栈以及开源社区就这样应运而生了。Hadoop 作为工业界广为接受的大数据的生态系统,忠实的再现了 Google 的这几篇论文里提出的将存储和计算再次进行耦合的模型。
那么发展到今天是什么样的状况呢?如果找刚成立一两年的创业公司谈一下,就会发现其中大部分公司不再需要构建自己的内部基础架构,而是直接在 Amazon AWS,Google Cloud,或者 Microsoft Azure 上构建基础架构。存储服务主要由对象存储系统提供。云服务供应商正是以这样更廉价,更具可扩展性和更灵活的方式,基于个性化的应用来提供多样的存储服务。这是一个极为重要的应用。如果想让不同的机器运行应用程序,只需要将应用程序连接到这些对象存储系统,这样一来就再次实现了可扩展对象存储系统和计算资源的去耦合。
以上就是数据架构的大致发展轨迹。我们可以从中看到一个循环:紧密耦合的架构 -> 去耦合的分布式存储架构 -> 大数据规模下具有水平可扩展性的分布式文件系统耦合模型 -> 云环境中的可扩展对象存储和计算资源的去耦合。这是个非常有趣的循环发展过程。
大数据生态系统面临的挑战

大数据生态系统正变得越来越复杂,也带来了很多挑战。在工作中能够拥有更多不同的选择对用户来说是件好事。然而,对于很多公司来说,后端基础设施会变得越来越复杂,因为他们必须同时支持各种处理数据的方法,于是只能在其系统中添加更多的新系统。
此外,对于用不同方法处理的常见数据,如何才能保证人们可以有效的共享不同框架呢?例如,在不同的 Spark 任务之间共享数据非常麻烦,因为每个 Spark 任务只会将自己的数据缓存到本身进程当中。所以必须找到一种巧妙的方法在像 Spark 这样的同一个框架内进行数据共享。如果你想在 Spark,Presto,Hadoop 和 TensorFlow 之间实现高级的数据共享,难度就更大了。
另一个挑战是,随着许多数据应用的数据规模变得越来越庞大,很多用户反映他们要用到数以万计,甚至更多的机器。在这个规模之上,要实现管理集群以及管理数据和获得更高的处理能力,都需要很高的成本。
计算和存储间的解决方案——数据编排层
如果想以更灵活、高效和低成本的方式搭建基础框架,比如实现数据驱动应用中计算和存储的独立扩展,还要考虑以下几个技术上的问题。

1)数据本地性。Hadoop MapReduce 将计算移动到接近数据所在节点位置,具有良好的本地性。云时代存储与计算分开,节约了存储空间的同时却造成了计算效率下降。那么如何能够延续 Hadoop 的数据本地性?
2)数据抽象。如果使用混合云解决方案,如何才能将多个不同类型的数据存储系统混合到一个统一的抽象中,让应用程序可以自如的处理数据而无需在意物理上的差异?
3)可访问性。构建可以访问一种类型的存储的应用程序非常容易,但是如果有多个不同的存储空间,如何保证开发人员依然能够方便的访问数据?
面对各种挑战,结合在伯克利 AMPLab 的经验,并与数据生态系统中的不同用户沟通之后,我们认为应该在计算和存储种插入一个新的“数据编排层(Data Orchestration Layer)”作为解决方案,相应的一个开源实现方案就是开源项目 Alluxio。我们认为,现在工业界已经正在引入这一解决方案来应对挑战了。这种架构的创新之处在于构建了一层统一的数据抽象,让不同的潜在后端存储系统都可以被访问,而且能够将数据转移到需要的地方。

案例研究
下面我想通过一些实际案例来说明为什么需要添加一个新的层,在面临这一新的挑战时会遇到哪些问题以及应该如何解决。
1. 弹性模型训练(Elastic Model Training)- Two Sigma
第一个实例是弹性模型训练。我们的一个用户是 Two Sigma,华尔街顶级对冲基金。时效性对他们至关重要。他们在训练机器学习模型时发现,弹性地利用云上的机器资源进行模型训练的效果非常好。因为这样一来,可以显着降低维护自有的计算机集群的成本,而且工作任务可以更好的在上百台机器中间进行分配。
但是这存在一个问题,对于这样一家华尔街公司,数据是重中之重。他们只愿意将数据存储在公司内部的基础设施中, 但将数据一次次移动到云端会导致高昂的成本,并且机器学习模型训练可能变得异常复杂。于是,他们将这个新的数据层与他们的机器学习工具,比如 Spark 部署在一起,一旦数据移动到 Alluxio 层,就可以进行缓存处理和数据管理,以避免机器学习训练的过程中反复从他们的数据源读取数据。这种方式可以让他们的开发机器学习模型的效率提高十倍,获得非常好的投资回报。

2. 准实时数据处理流水线(Near Real-time Data Pipeline) - 唯品会
还有一个很有意思的例子是电子商务公司唯品会的准实时数据流水线。这些关键的流水线可以提供推荐和分析销售原因等任务,能够帮助数据科学家们理解为什么有人会去他们的网站购买商品,比如是因为平台正在搞促销活动,还是因为他们刚好有优惠券,或者是在哪里看到了广告推介。因此,他们利用 Spark 将相关数据结合一些统计算法来推断当前的购买决定是否源于之前的某些特定行为。关键在于,人们不会一直在网上购物,多数人只会停留十几分钟到几十分钟。因此这些统计推断必须在用户离开前对行为数据进行实时分析以获得有意义的结果,并及时根据反馈进行调整。
在通常情况下, 常规的架构可能也可以满足要求。但是到了像“双 11”这样的热门购物促销日,网络流量就变得异常庞大。在这种情况下,应用程序与其数据之间的网络流量数据就不那么可靠了。于是,唯品会的工程师们为这些流水线提供了“另一层数据”,能够帮助他们获得非常稳定的数据访问量。例如,他们可以使用 Alluxio 并把内存(memory)作为数据存储设备,其提供的高带宽可以满足 Spark 的数据消费任务的需求。在这种情况下,数据处理流水线变得更加稳定,及时的推荐和销售归因可以提升网站的访问 - 购买转化率,数据科学家的工作也变得更加得心应手。

3. 提高数据科学家的工作效率 - 美国电信公司
我想分享的最后一个例子是如何让数据科学家的生活更轻松。机器学习应用程序可以通过一个新的智能数据层来访问数据。有一家历史悠久的美国顶级电信公司,拥有许多不同的传统基础设施,繁杂的部门也衍生出了非常分散的数据源。每当他们的数据科学家们想要用稍微高级一点的方式使用某些数据时都会觉得举步维艰。他们必须进行无数次的 ETL 操作(Extract, Transform and Load),这将直接影响他们完成机器学习模型的效率。
最后,他们发现可以在不同的分布式文件系统或不同数据源上使用一层数据将这种差异隐藏起来。只要他们能够理解一个统一的数据逻辑视图,就可以高枕无忧,等待数据层帮他们进行数据转移和管理。这样一来,他们就能够以很高的工作效率,非常轻松地进行模型开发。


硅谷AI科技、创业、领导力访谈

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论