
如今物联网的席卷之势正愈演愈烈,而个中原因其实不难说清:物联网的出现帮助企业通过将所有机械与设备接入网络而带来新的商业价值。不过新的挑战也由此产生,这就是实时数据处理与分析。云计算正是开启物联网财富大门的金钥匙,因为其具备显著的灵活性、可扩展能力以及弹性优势。
在今天的博文中,我们将了解如何开始自己的 Amazon Kinesis 之旅——这是一项基于云的全面托管服务,用于以实时方式处理并分发数据流,而且大家能够将其整合到几乎任何物联网用例当中。举例来说,News Distribution Network 就利用 Amazon Kinesis 对自己的流数据进行实时分析,并在负载性能糟糕或者出现异常用户操作时借此发出警报。要了解更多情况,请点击此处访问 News Distribution Network 的案例研究资料。数据科学家们在开发物联网在企业环境下的应用概念时,往往会选择Python 语言。Python 是目前人气最高的热门语言之一,特别是在数据科学领域的原型设计、可视化处理以及针对各类数据集进行数据分析等方面大放异彩。作为一套Python 库,Boto 旨在将AWS SDK 引入Python。Boto 通过将Python API 交付至多种AWS 服务的方式帮助用户免去了编程复杂性的烦恼,其中包括Amazon Simple Storage Service(简称Amazon S3)、Amazon Elastic Compute Cloud(简称Amazon EC2)以及Amazon Kinesis 等等。AWS 还提供一份易于阅读的指南文献,帮助大家轻松上手Boto。
Amazon Kinesis 基础介绍
以下示意图以直观方式展示了 Amazon Kinesis 中的各核心概念与模块:
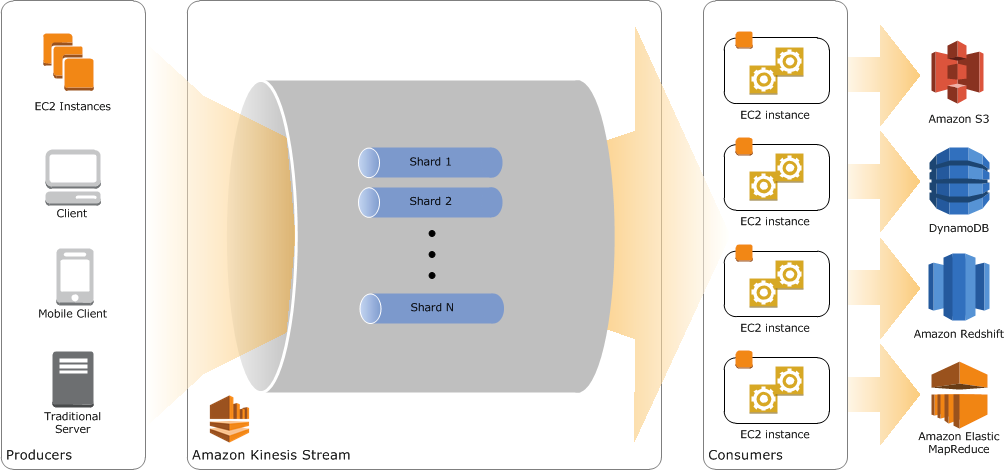
生产者生成数据并将该数据以记录形式添加到 Amazon Kinesis Stream 当中,后者相当于一系列有序数据记录的集合。一组数据流由多个片段组成,并作为多项数据记录的惟一标识组存在。消费者从 Amazon Kingesis Stream 中获取这些数据记录并加以处理。举例来说,消费者可以表现为一套实时仪表板或者一款需要将数据写入其它 AWS 服务的应用程序。要了解更多与 Amazon Kinesis 相关的信息,请点击此处查看其上手指南网页。
在示例代码当中,我假设大家已经完成了Boto 安装并具备了认证所需要的AWS 证书。Boto 还单独提供一份教程,帮助大家了解如何进行Boto 配置。
管理Amazon Kinesis 及创建数据
Boto 库提供高效易用的代码,用于管理 AWS 资源。首先,大家需要在 eu-west-1 当中创建一套包含一个片段且名为 BotoDemo 的 Amazon Kinesis Stream。我同时建议大家使用 describe_stream(‘BotoDemo’) 命令来了解与之相关的更多细节信息,并利用 andlist_streams() 命令列出当前 BotoDemo 与 IoTSensorDemo 实例中的全部现有数据流。
>>> from boto import kinesis >>> >>> kinesis = kinesis.connect_to_region("eu-west-1") >>> stream = kinesis.create_stream("BotoDemo", 1) >>> kinesis.describe_stream("BotoDemo") {u'StreamDescription': {u'HasMoreShards': False, u'StreamStatus': u'CREATING', u'StreamName': u'BotoDemo', u'StreamARN': u'arn:aws:kinesis:eu-west-1:374311255271:stream/BotoDemo', u'Shards': []}} >>> kinesis.list_streams() {u'StreamNames': [u'BotoDemo', u'IoTSensorDemo'], u'HasMoreStreams': False}
在本篇教程中,我们将使用模拟流数据并通过 Python 库“testdata”生成具备名、姓、年龄以及性别的个人信息数据。之所以选择这种简单的数据结构,是为了帮助大家集中精力理解各关键性 Kinesis 概念。如果大家希望接触更多更具挑战性的数据,请点击此处获取另一套 Python 包并将自己的 Amazon Kinesis Stream 与 Twitter 相对接。
>>> import testdata >>> import json >>> >>> class Users(testdata.DictFactory): ... firstname = testdata.FakeDataFactory('firstName') ... lastname = testdata.FakeDataFactory('lastName') ... age = testdata.RandomInteger(10, 30) ... gender = testdata.RandomSelection(['female', 'male'])
将数据导入 Amazon Kinesis
现在我们已经运行有一套 Amazon Kinesis 数据流,并在 Python 当中利用一个简单的 for 循环实现该流数据模拟。前面提到的 testdata 包会自动创建 JSON 数据,我们只需要添加一行代码即可将这部分数据直接发送至 Amazon Kinesis 当中。
>>> for user in Users().generate(50): ... print(user) ... kinesis.put_record("BotoDemo", json.dumps(user), "partitionkey") ... {u'ShardId': u'shardId-000000000000', u'SequenceNumber': u'49547280908463336004254488250210112303208011162475036674'} {u'ShardId': u'shardId-000000000000', u'SequenceNumber': u'49547280908463336004254488250211321229027625791649742850'}
在 put_record() 命令当中,大家必须设定流名称、将数据块放入记录外加一套用于进行数据拆分的分区键。在本次示例当中,我们只涉及单一片段,因此大家用不着在分区键方面费太多心思。在 put_record() 的输出结果中,大家会看到 Amazon Kinesis 针对我们放入 Amazon Kinesis 中的每个对象设定了序列数字,并将该对象保存在对应片段当中。
从 Amazon Kinesis 中读取数据
现在我们的 Amazon Kinesis Stream 已经拥有自己的数据,下一步要做的是完成数据读取。我们利用另一套 Python shell 打开新的终端窗口,只需要使用简单的 while 无限循环,我们就能够从数据流中读取到最新记录。
>>> from boto import kinesis >>> import time >>> >>> kinesis = kinesis.connect_to_region("eu-west-1") >>> shard_id = 'shardId-000000000000' #we only have one shard! >>> shard_it = kinesis.get_shard_iterator("BotoDemo", shard_id, "LATEST")["ShardIterator"] >>> while 1==1: ... out = kinesis.get_records(shard_it, limit=2) ... shard_it = out["NextShardIterator"] ... print out; ... time.sleep(0.2) ... {u'Records': [{u'PartitionKey': u'partitionkey', u'Data': u'{"lastname": "Rau", "age": 23, "firstname": "Peyton", "gender": "male"}', u'SequenceNumber': u'49547280908463336004254488250517179461390244620594577410'}, {u'PartitionKey': u'partitionkey', u'Data': u'{"lastname": "Mante", "age": 29, "firstname": "Betsy", "gender": "male"}', u'SequenceNumber': u'49547280908463336004254488250518388387209859249769283586'}], u'NextShardIterator': u'AAAAAAAAAAEvI7MPAuwLucWMwYtZnATetztUUTqgtQaTaihyV/ +buCmSqBdKnAwv2dMNeGlYo3fvYCcH6aI/A+DtG3uq +MnG8AlyrX7UrHnlX5OF0xG/IEhSJyyToPvwtJ8odDoWShib3bjuk +944QcsPrRRsUsBNx6xyKgnY+xi9lXvweiImL1ByK5Bdj0sLoRp/9nBWfw='}
首先,我们必须创建一个片段迭代器,用于指定应该在片段中的哪个位置开始顺序读取数据记录内容。在本次示例中(即‘LATEST’),我们将读取片段中的各条最新记录。AWS 提供一份参考指南,用于帮助大家了解各种不同可用片段迭代器类型。大家可以利用 theget_records() 命令获取大量记录信息。不过为了展示方便,我们在这里将记录的获取数量限定为两条。除此之外,每个片段只能支持每秒最高五次读取事务。因此,我们使用 sleep() 命令控制每秒中的读取操作次数。Amazon Kinesis 在说明文档中提供更多关于服务限制的信息,感兴趣的朋友请点击此处查看。最后一次 get_records() 命令的每项输出结果都将额外提供包含下一次 get_records 操作的片段迭代器。
现在大家已经可以对 Amazon Kinesis 当中的最新数据加以分析,并以可视化方式将数据结果显示在仪表板当中。以下代码用于计算 Amazon Kinesis 内模拟数据的平均年龄水平。
>>> from boto import kinesis >>> from boto import kinesis >>> from __future__ import division >>> import time >>> >>> kinesis = kinesis.connect_to_region("eu-west-1") >>> shard_id = 'shardId-000000000000' #we only have one shard! >>> shard_it = kinesis.get_shard_iterator("BotoDemo", shard_id, "LATEST")["ShardIterator"] >>> i=0 >>> sum=0 >>> while 1==1: ... out = kinesis.get_records(shard_it, limit=2) ... for o in out["Records"]: ... jdat = json.loads(o["Data"]) ... sum = sum + jdat["age"] ... i = i+1 ... shard_it = out["NextShardIterator"] ... if i <> 0: ... print "Average age:" + str(sum/i) ... time.sleep(0.2) ...
对 Amazon Kinesis Stream 的片段进行重新划分
而言,弹性与规模化能力已经成为其核心特性。到目前为止,我们所使用的范例在规模化方面还没什么作为。Amazon Kinesis 片段的大小受到每秒读取与写入操作设定以及资源容量的限制。为了对应用程序进行规模扩展,大家可以随时向其中添加及移除数据片段。因此,让我们将现有片段一分为二,并利用更为高效的分区键向 Amazon Kinesis 进行写入。
>>> sinfo = kinesis.describe_stream("BotoDemo") >>> hkey = int(sinfo["StreamDescription"]["Shards"][0]["HashKeyRange"]["EndingHashKey"]) >>> shard_id = 'shardId-000000000000' #we only have one shard! >>> kinesis.split_shard("BotoDemo", shard_id, str((hkey+0)/2)) >>> >>> for user in Users().generate(50): ... print user ... kinesis.put_record("BotoDemo", json.dumps(user), str(hash(user["gender"]))) ... {'lastname': 'Hilpert', 'age': 16, 'firstname': 'Mariah', 'gender': 'female'} {u'ShardId': u'shardId-000000000001', u'SequenceNumber': u'49547282457763007181772469762801693095350958144429752338'} {'lastname': 'Beer', 'age': 13, 'firstname': 'Ruthe', 'gender': 'male'} {u'ShardId': u'shardId-000000000002', u'SequenceNumber': u'49547282457785307926971000385136875291940648846406713378'} {'lastname': 'Boehm', 'age': 30, 'firstname': 'Lysanne', 'gender': 'female'} {u'ShardId': u'shardId-000000000001', u'SequenceNumber': u'49547282457763007181772469762802902021170572773604458514'} {'lastname': 'Bechtelar', 'age': 17, 'firstname': 'Darrick', 'gender': 'male'} {u'ShardId': u'shardId-000000000002', u'SequenceNumber': u'49547282457785307926971000385138084217760263475581419554'} ...
为了实现片段拆分,我们必须首先指定需要拆分的片段以及新的散列键,后者用于指定片段拆分时的起始位置。在大多数情况下,这个新的散列键往往仅是开头与结尾散列键的平均值,但大家也可以选择映射在该片段内的任意散列键值。
现在我们需要为 put_record() 命令提供一个更为高效的分区键。Amazon Kinesis 利用 MD5 散列函数将分区键映射至 128 位整数值,并利用片段中的散列键区间实现相关数据记录的映射。作为最佳实践,建议大家采用组数量高于片段的分区键。在本次示例中,性别字段正是最适合展示的分区键范例。在 put_record() 的输出结果中,大家会看到男性与女性数据对象被旋转在不同片段当中。在对这套方案进行规模扩展时,其同样受到两个片段的限制。就目前的数据样本来说,大家可以将年龄值作为可扩展性分区键。
除了向外扩展之外,大家还应该时刻考虑到规模削减的需要。我们可以利用 merge_shards() 命令将两个负载较低的片段加以合并。
优化 Put 操作
到目前为止,我们已经分别将每一条记录导入 Amazon Kinesis。随着生产者数量的增加以及数据规模的提升,这种处理方式有可能给 Amazon Kinesis 带来夸张的写入延迟水平。一旦出现这种状况,大家可以考虑将对象汇总成批,并一次性向 Amazon Kinesis 流内写入规模更大的对象集合。
>>> i=0; >>> records=[]; >>> for user in Users().generate(50): ... i=i+1 ... record = {'Data': json.dumps(user),'PartitionKey': str(hash(user["age"]))} ... records.append(record) ... if i%5==0: ... kinesis.put_records(records, "BotoDemo") ... records=[];
其中 put_records() 仅适用于 Boto v2.36.0 以及更高版本(发布于 2015 年 1 月 27 日)。对于此类批量操作,大家可以将多条记录(在我们的示例中为 5 条)汇总成一个数组。其中每个元素为一个配备一条 Data 字段与一条 PartitionKey 字段的对象。在该数组收集到五个元素之后,我们将其发送至 Amazon Kinesis 并转而创建新的数组。当大家完成了本篇教程的全部内容后,请删除这套 Amazon Kinesis 流
>>> kinesis.delete_stream("BotoDemo")
结论
Amazon Kinesis 是一项专门用于流数据管理的强大 AWS 服务。其在对来自设备日志、工业传感器、网站点击流、金融交易、社交媒体信息、IT 日志以及位置追踪事件等的数据进行存储及分析时极具实用性。整体而言,Amazon Kinesis 可谓新兴物联网技术的完美配伍方案。
作为 Python 库,Boto 提供了一套绝佳接口,帮助数据科学家充分发挥 Amazon Kinesis 以及其它 AWS 服务的固有优势。大家可以管理自己的数据流并利用不足十行 Python 代码将数据导入 Amazon Kinesis 并加以读取。如果大家更倾向于使用低级编程语言,那么请点击此处查看 AWS Java SDK ,其提供一款出色的 Amazon Kinesis 集成工具。如果大家有任何疑问、建议或者评论意见,请点击此处访问Amazon Kinesis 论坛或者在下方的评论栏中与我们分享。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论