

作为人工智能领域中热度最高、挑战最大的子领域之一,自然语言处理(NLP)在最近几年得到了飞速的发展。2020 年我们又迎来了 GPT-3,1750 亿参数让其自诞生就引起了开发者们的激烈讨论。短短一年时间,知识图谱的成熟度由萌芽期一跃达到预期膨胀高峰且非常接近最高点…本期大咖说,京东科技算法科学家、高级技术总监吴友政博士将与我们分享 NLP 领域的 2020 年大事记,以及未来一年最值得期待的变化。
InfoQ:吴老师,您好,非常高兴有机会和您对话。先请您简单总结下 NLP 领域在 2020 年的进展。
吴友政:NLP 技术 2020 年仍然在快速发展的车道上。内容生成方向,以 GPT-3 为代表的预训练技术不仅在 NLP、甚至在整个 AI 领域都受到了广泛关注。GPT-3 生成的文章连人类也难辨真假。生成式 AI 也首次进入 Gartner 技术成熟度曲线,跟踪其成熟度和未来潜力。人机对话方向,谷歌去年初发布了 Meena、Facebook 后续发布了 Blenderbot、以及 Blenderbot 和 Pandora Kuki 两个聊天机器人的“约会”遭全网围观,都极大地推动了人机对话技术的发展。此外,多模态智能、数字内容生成、图神经网络等技术都有非常大的进展。影响力上,NLP 领域中的 Transformer、预训练等技术在计算机视觉、语音等 AI 领域都得到了广泛的应用。落地应用上,人机对话相比于 2019 年有了非常显著的进步。在 2020 年的 Gartner 报告中,人机对话的位置相比 2019 更加靠前。该报告同时预测人机对话技术将在 2~5 年后进入平台期或者说成熟期。
综上,我认为过去一年 NLP 技术仍然行驶在快车道上。
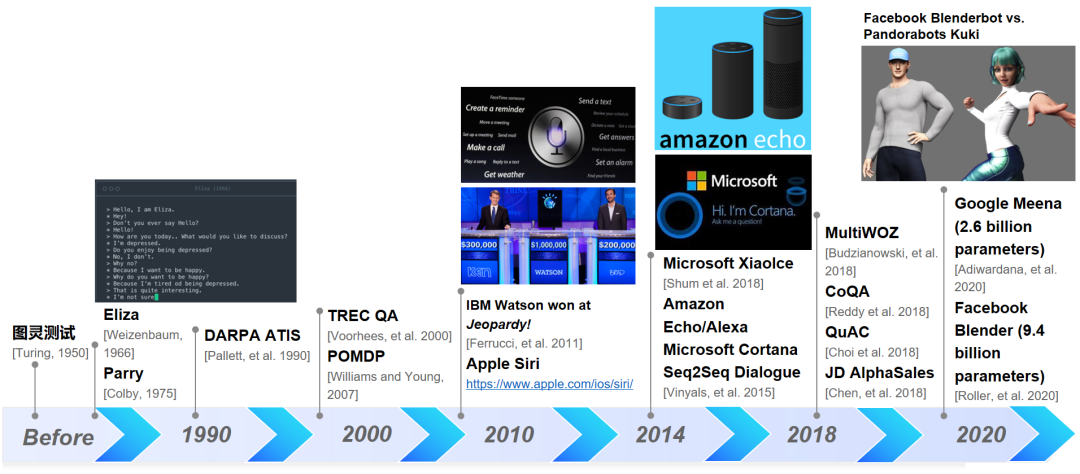
图 1:人机对话技术发展回顾
InfoQ:如果回顾自然语言处理过去几年的发展特点,您认为可以从哪几个纬度展开?
吴友政:我觉得可以从学科发展、技术趋势、人才情况、落地应用等多个维度展开。我先简单回顾一下 NLP 的发展历程。2000 年之前,NLP 是一个小众的学科方向,而且 NLP 领域的很多算法也是从其他领域借鉴过来的,比如分词、词性标注用的马尔可夫模型借鉴自语音领域。2000 年之后,Google 等搜索公司的成功带动了 NLP 学科的发展。NLP 在 Query 理解、Doc 理解、Query-Doc 相关度计算等可以显著提高搜索的相关性,进而改善搜索质量。由于 NLP 涉及面广的特点,除搜索之外,推荐、广告、舆情、社交等等对 NLP 技术都有大量的需求。2010 年左右,随着语音、计算机视觉等感知技术相对成熟,以 NLP 为代表的认知智能受到了 AI 学者的广泛关注。比尔盖茨曾说过:自然语言处理是人工智能皇冠上的明珠。2013 年左右,我认为 NLP 技术开始进入快速发展的通道,标志性事件是谷歌提出的词嵌入技术。词嵌入是一种词的表示方法,是将词汇映射到实数向量的方法,让我们可方便地计算 2 个词的相似度,进而可实现句子嵌入/表示等。在这之后一系列新的有影响力的技术陆续提出:2015 年的 Attention, 2017 年的 Transformer, 2018 年的 ELMo、GPT-1、BERT, 2019 年的 GPT-2, 2020 年的 GPT-3(1750 亿参数), T5, 2021 年的 Switch Transformer(1.6 万亿参数)。落地应用上,以 NLP 为核心引擎的智能音箱、智能服务机器人、机器翻译已经走进了我们的日常生活。
具体到 2020 年,我们统计了 2020 年 NLP 顶会论文,总结了一些观察。
从 NLP 任务看
(1)多模态人机对话是最 HOT 的研究方向:研究课题涉及任务型对话、开放域聊天、对话式推荐、对话式机器阅读理解等。我们去年在斯坦福大学的对话式机器阅读理解数据集 QuAC 上获得了冠军。
(2)文本生成热度不减:文本生成与自动文摘、机器翻译、人机对话等任务关系紧密。基于 Seq2Seq 框架、预训练语言模型、融合多模态和知识的可控文本生成一直是自然语言处理的热门研究领域。
(3)机器翻译:虽然仍位居研究热点头部位置,但相对人机对话来说关注度有所下降。
(4)其他的如自动文摘、Syntactic Parsing、关系抽取、命名体识别等传统自然语言处理任务逐渐式微。
从 NLP 模型看
(1)以 BERT/GPT 为代表的自编码/自回归/对比学习的预训练模型在自然语言理解、自然语言生成任务上不断刷榜,预训练-精调形成 NLP 新范式。
(2)融合知识成为提升模型能力的万金油。全国知识图谱大会 CCKS 的参会人数逐年创记录也反应了 KG 的热度。
(3)图神经网络强势崛起:图神经网络在文本分类、关系抽取、多跳阅读、数值计算等多个自然语言处理任务上的得到了广泛的应用。
(4)多模态:多模态信息处理已渗透到多个领域,如内容生成、人机对话等。
InfoQ:2018 年诞生的 BERT 在 2019 年引发了一波落地浪潮,成为 NLP 领域去年最受关注的技术,您方便介绍下,BERT 或者说预训练模型在 2020 年有哪些值得注意的变化吗?京东在这方面有哪些实践和经验可以分享?
吴友政:预训练技术确实是受到关注最多的技术之一,我今年也看到很多研究者对预训练技术都做了非常好的总结。那我简单总结一下预训练技术的发展趋势,不局限于 2020 年发生的。
趋势一:从上下文无关的词嵌入(word embedding)走向上下文有关的预训练,比如 2018 年的 ELMo。
趋势二:预训练模型和下游 Fine-tuning 模型走向统一。ELMo 预训练模型和下游诸如文本分类、序列标注等的精调模型是不一致的。我们一般仅提取 ELMo 隐藏层信息,放到下游的 CNN/LSTM 等模型中。而 GPT 和 BERT 的出现则把预训练模型和下游模型统一了,这是预训练技术发展的一个重要变化。
趋势三:预训练模型从或用于理解或用于生成任务走向同时适用于理解和生成任务的统一。自编码的 BERT 最早提出是做文本理解,自回归的 GPT 则是做生成。2020 年,预训练模型将理解和生成统一到 Encoder - Decoder 框架,谷歌今年提出的 T5 就是典型的代表。
趋势四:基于文本-图像对、文本-视频对的多模态预训练。比如只在 Encode 框架上面做理解的 VL-BERT,基于 Encoder-Decoder 框架的 Unicoder-VL。
趋势五:知识增强的预训练。代表模型有知识嵌入的语言模型 ERINE、模块化且解释性更强的知识嵌入方法 REALM、将知识图谱的信息引入到 BERT 中的 K-BERT、可插拔式的知识融入模型 K-Adapter,用于解决连续学习在 pre-training 的时候遗忘之前学到的知识的问题。
趋势六:预训练模型越来越大。2020 年发布的 GPT-3 有 1750 亿个参数,今年 1 月份发布的 Switch Transformer 有 1.6 万亿的参数。北京智源人工智能研究院和清华大学 2020 年发布的中文预训练有 217 亿参数。2021 年可能会有更大的预训练模型发布。
趋势七:更小巧的预训练模型。预训练模型在应用到实际的产品或者商业化系统需要满足线上推理、延时的要求。以 TinyBERT、ALBERT 为代表的模型是更小、更高效模型的代表。
以上是我观察到的预训练技术的几个趋势。具体到实践层面,以京东为例,预训练技术在产品上有非常多的应用。
一是领域迁移。其实数据也不是越多越好,而是需要更多高质量的数据,而且需要和应用场景相匹配。比如京东要做零售领域的很多 NLP 任务,我们肯定是要在通用的预训练模型的基础上,再结合零售数据做领域适配。
二是上文提到的知识增强的预训练。京东在这上面做了很多工作,提出了很多知识增强的预训练目标,将知识融入到预训练模型里面,采用 Encode-Decode 架构,可以完成商品要素的编辑检测、商品类目分类、商品要素的摘要生成等,都是希望将领域知识或者特品任务的知识,融入到预训练里面,从而提高目标任务的效果。
三是解决延时和成本问题。GPU 资源相对比较宝贵,很多企业都没办法提供大规模的 GPU 机器供推理服务使用。知识蒸馏技术因此得到广泛应用。其主要包含两种方式:一是将大模型变成小模型,比如 12 层的 Transformer 变成六层或者三层。二是不同模型之间的蒸馏,比如 Transformer 里面的知识蒸馏到 TextCNN,其可以做到毫秒级响应。
InfoQ:我们刚刚提到预训练模型的参数越来越大,您认为这在 2021 年会继续延续下去吗?
吴友政:我觉得这肯定是其中一个方向,未来会有研究机构或者企业推出更大的模型。大力确实出奇迹。就像我们的一句老话:熟读唐诗三百首,不会吟诗也会吟。模型到底会变成多大是 2021 年非常值得关注的一个点。
InfoQ:2020 年,GPT-3 的发布引发了业内的广泛关注,开发者对其褒贬不一,您对 GPT-3 有哪些评价?目前,GPT-3 已经被应用来做大量内容自动生成方面的事情,您方便介绍下目前自动生成内容的效果和难度分别如何?具体可应用在哪些场景?
吴友政:正如大家从媒体上了解的一样,GPT-3 通过少量的提示就可以生成一篇完整的文章。但是 GPT-3 生成的内容在常识、语言逻辑、前后照应等方面还有很多问题。但 GPT-3 在技术上的进步是毋庸置疑的:一、GTP3 验证了大规模自监督预训练模型可以达到很好的效果,就像 GTP-3 文章中提出的一样:人们很难区分文章到底是由机器生成的还是人类完成的,人类判断的准确率只有 12%。二、GTP-3 强调自己是少样本或者零样本,这对实际应用是非常重要的。因为做产品的过程中遇到的最棘手的问题就是样本不足,研究快速达到好的冷启动效果是非常重要的课题。在这方面,GTP-3 是非常有应用价值的。
在内容生成的实践层面,京东也做了很多非常有意思的探索:基于图像生成技术的虚拟试衣、AI 音乐生成、商品营销文案生成、AI 写诗、风格化 AI 书法字体生成、文本与图像的相互生成等等。其中,AI 商品营销文案生成的挑战是不仅要求机器生成语句通顺,符合语法规则和语义逻辑的文章,还需要是用户愿意阅读的商品文案,从而提高用户的点击转化。我们在 AI 商品文案生成上取得的效果还是非常不错的,人工审核的通过率在 90%以上,AI 生成的素材平均点击率显著高于达人平均。目前已经覆盖了京东的 3000+个三级品类,在京东发现好货频道、社交电商京粉、搭配购、AI 直播带货等多个场景都有广泛的应用。具体技术细节可参考:《"多模态数字内容生成"的技术探索与应用实践》
InfoQ:我们在前面的对话中也多次提到多模态,我们也看到业界有一些对多模态方面的讨论,您可以介绍一下多模态在 2020 年的进展吗?
吴友政:多模态在 2020 年的确受到学术界和产业界的关注。2020 年有很多场关于多模态信息处理的研讨会。我们去年 10 月份在 CCF-NLPCC 会议期间举办了线下的多模态自然语言处理研讨会,邀请了来自 CV、NLP 以及艺术领域的专家,介绍他们在多模态摘要、多模态对话、多模态与艺术的结合等方向上的最近研究进展。去年我们也举办了第三届京东多模态人机对话挑战赛(当AI客服遇上「图文混排」提问,京东给电商AI来了场摸底考试),并发布了首个真实场景的多模态对话数据集 JDDC Corpus2.0。大赛吸引了来自高校、研究所、企业的 700 多名选手和 400 多支队伍参加。我们希望通过大赛和开放数据集共同推动多模态多轮人机对话技术的进展。
在多模态应用上面,京东将多模态人机对话应用到了导购机器人。线上客服导购对话中有超过 16%含有多模态信息,就是含有图片信息,所以导购客服需要有多模态语义理解的能力,然后更好的服务客户,因为如果有 16%的会话都回答不了,是很遗憾的。
InfoQ:在 NLP 领域,知识图谱也是发展比较好的一个分支,您方便从技术和应用落地两方面简单总结知识图谱 2020 年的发展情况以及未来趋势吗?
吴友政:融合知识在大多数情况下都能显著提高模型效果。基于知识图谱改进预训练模型,无论是通过知识指导 Mask,或是将知识编码进预训练模型,都是近期的研究热点。二、用知识图谱解决低资源的问题,比如解决推荐的冷启动问题就非常依赖知识图谱。三、知识图谱在文本生成方面有广泛的应用,我们提出利用知识图谱提高文本生成的忠实度,利用知识图谱指导解码器进行受限解码,从而提高文本输出的冗余性,提高可读性等。
在实践层面,我们正在建设 2 个知识图谱:第一个是以商品为中心的商品知识图谱,包括商品、用户、场景等实体的知识图谱。第二个是药学知识图谱、是以药品为中心的构建药品与药品、药品与疾病、药品与人群等关系。知识图谱在京东有丰富的落地场景,我这里举几个例子:
(1)第一个应用场景是商品图谱问答:在售前场景,用户咨询中有 2%左右的问题(不同品类比例不同)涉及商品属性(这款洗衣机是否有杀菌清洁功能)。我们的解决方法是 KBQA 技术。
(2)第二个场景是使用知识图谱提高商品文案写作的忠实度。一个合格的商品营销文案的基本要求是生成的文案不能出现事实性错误,比如对于一款“变频冰箱”,模型生成的文案不能描述成“定频”。我们从两个方面提升文本的忠实度。一是对商品知识图谱中的商品属性信息进行建模;二是我们提出了一个属性信息 Only-copy 机制,在解码属性词时,仅允许从输入文本中复制。
(3)第三个场景是企业采购场景:我们构建了采购知识图谱,图谱中包括商品、供应商、制造商、品牌商、行业、场景等实体的关系。基于采购图谱,我们提供一系列的智能选品、智能比价、供应商智能匹配等多个智能化采购服务工具与应用。
(4)第四个场景是基于药学知识图谱的处方审核引擎。药学知识图谱是从药品说明书中通过规则、模型抽取的。这个功能已经在京东的互联网医院上线,每天审核大量的的处方,可帮助药剂师提高处方审核的效率。
InfoQ:在落地方面,您认为当下 NLP 领域比较成熟的是什么?正在飞速发展中的是什么?为什么?
吴友政:比较成熟的 NLP 技术方向是文本理解与数据挖掘,包括搜索的 Query 理解、推荐的内容理解等、机器翻译、人机对话等。这些已经走进我们的日常生活。
飞速发展的 NLP 技术包括数字内容生成、知识图谱、多模态、虚拟数字人等。这些技术得以快速发展我觉得有两方面的原因:一是深度学习等技术的快速很快,让这些 NLP 应用的实现变成了可能,而且在某些特定场景还能达到不错的效果。另一方面,巨大的需求促进了技术进步,是技术进步的驱动力。
InfoQ:根据您的了解,目前 NLP 领域面临的比较大的挑战是什么?有一些不错的解决思路了吗?
吴友政:NLP 主要有三大挑战:歧义性、多样性、知识表示/构建/融合。除此之外,还有符号化的知识跟神经网络之间的联合建模、推理能力、可解释 NLP 等都存在很大的挑战。
我觉得有些挑战,目前还没有特别成熟的方案。不过研究人员都在做很多探索和尝试,也取得了很好的进展。比如低资源 NLP 正在通过预训练、无监督学习、半监督学习、迁移学习、少样本学习(Few-shot Learning)、零样本学习(Zero-shot Learning)不断取得进步。
语言的歧义性/多样性的挑战也可通过多模态输入弥补单模态信息的缺失,进而提高文本单模态模型的效果。
InfoQ:未来一年,自然语言处理领域的哪些进展可能是值得关注的?京东在这方面有哪些规划?
吴友政:预测是很难的事情,我可以简单说下个人比较关注的方向吧。
第一个还是预训练技术:基于自回归、自编码、对比学习的预训练是非常值得关注的方向。预训练会向更大、更小巧、更高效的方向发展。
第二个是知识与数据结合驱动:模型加入知识指导,通过知识和数据两者联合实现深度语义理解,支撑上层 NLP 任务。未来知识图谱将朝着数据规模更大、模态和关系更丰富、建模方法更加自动和智能的方向去发展。
第三个是多模态拟人化人机交互。复杂交互场景下的多模态人机交互服务是人工智能的重要技术需求。人机交互从命令式交互、图形交互、自然交互、开始走向多模态多轮对话的交互。多模态多轮对话的人机交互要求机器具备人类听觉、视觉、情感交流能力、场景知识储备、语义理解和多轮交互能力。而且多模态多轮对话人机交互也有巨大的应用需求。
京东在上述几个方向都已开展了一些工作。在多模态拟人化人机交互上,我们申请了国家级的重大项目,希望在这个领域实现一些技术突破。在应用上,多模态拟人化交互技术会应用到智能情感客服,智能营销导购和智能消费媒体三个典型的场景。
NLP 技术还有很大的发展空间,非常值得期待。

DIVE大会主编

中国卓越技术团队访谈录(2022 年第二季)
本迷你书精选了微软 Edge、蚂蚁可信原生、明源云、文因互联、Babylon.js 等技术团队在技术落地、团队建...











评论