

自然语言生成(Natural Language Generation,NLG)是自然语言处理的一部分,从知识库或逻辑形式等等机器表述系统去生成自然语言。实际上,自然语言生成出现已久,至今已有 71 年了。早在 1948 年,Shannon 就把离散马尔科夫过程的概率模型应用于描述语言的自动机。但商业自然语言生成技术知道最近才变得普及。但是,你了解自然语言生成的演变史吗?
自从科幻电影诞生以来,社会上就对人工智能十分着迷。每当我们听到“人工智能”这个词的时候,浮现在我们脑海的,往往是科幻电影中那样的未来机器人,比如《Terminator》(《终结者》)、《The Matrix》(《黑客帝国》)和《I, Robot》(《我,机器人》) 等。

尽管我们离能够独立思考的机器人尚有几年的时间,但在过去的几年里,机器学习和自然语言理解领域已经取得了重大进展。个人助理(Siri/Alexa)、聊天机器人和问答机器人等应用程序正在真正彻底改变我们与机器的交互方式,并开始渗透我们的日常生活。
自然语言理解(Natural Language Understanding,NLU)和自然语言生成(Natural Language Generation,NLG)是人工智能发展最快的应用之一,因为人们越来越需要从语言中理解并推导出意义,而语言的特点是,有许多歧义和多样的结构。据 Gartner 称,“到 2019 年,自然语言生成将成为 90% 的现代商业智能和分析平台的标准功能”。在本文中,我们将讨论自然语言生成成立之初的简史,以及它在未来几年的发展方向。
什么是自然语言生成?
语言生成的目标是通过预测句子中的下一个单词来传达信息。使用语言模型可以解决(在数百万种可能性中)哪个单词可能被预测的问题,语言模型是对单词序列的概率分布。语言模型可以在字符级别、n 元语法级别、句子级别甚至段落级别构建。例如,为了预测 I need to learn how to __ 之后的下一个单词,该模型为下一个可能的单词集分配了一个概率,可以是 write、drive 等等。神经网络(如递归神经网络和长短期记忆网络)的最新进展是的长句的处理成为可能,显著提高了语言模型的正确率。
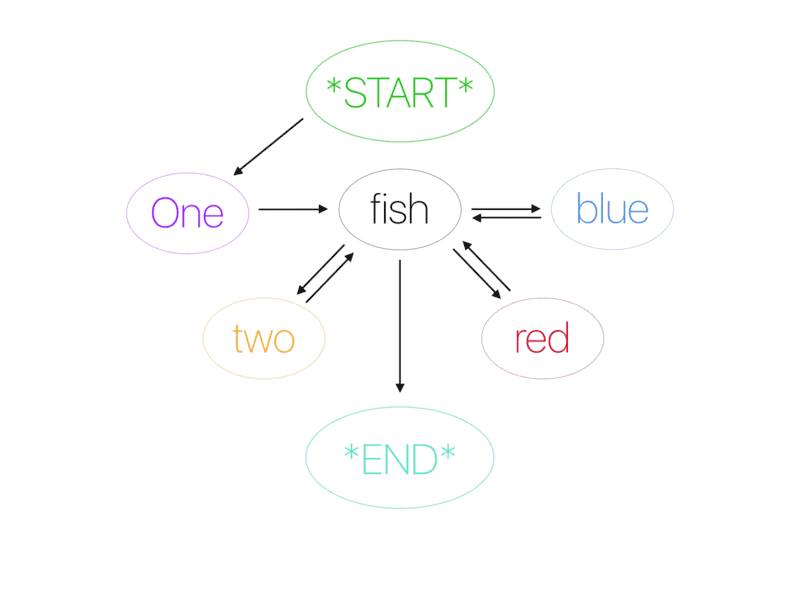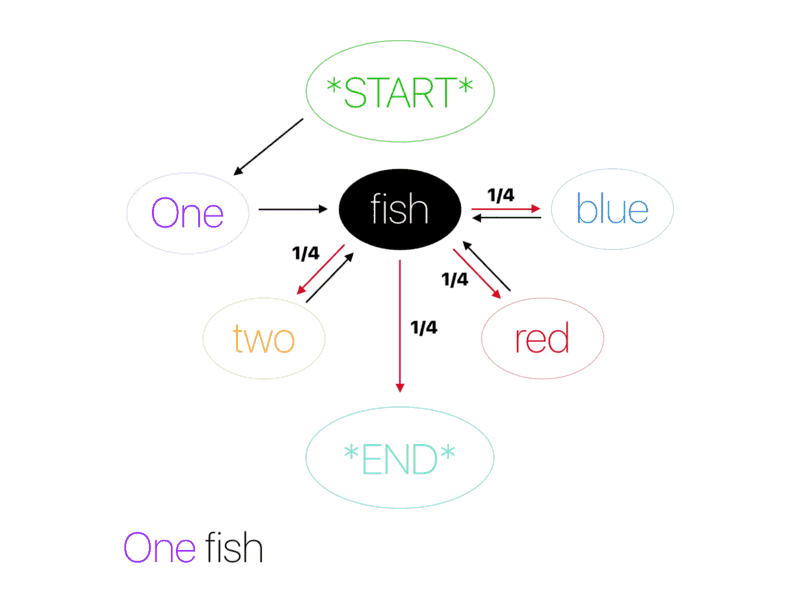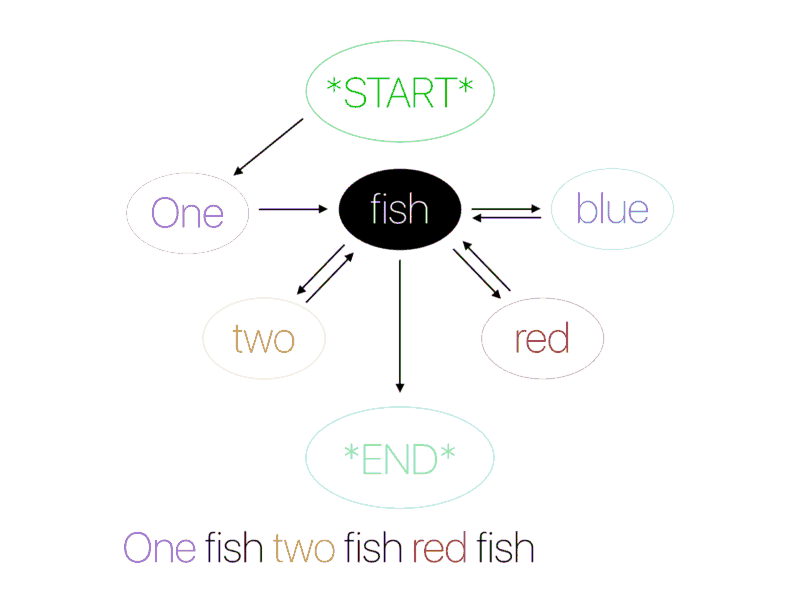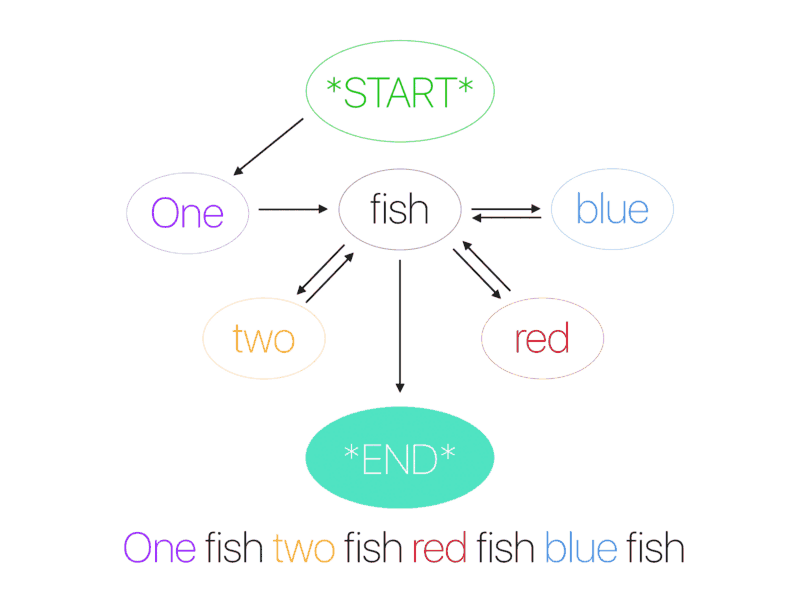
马尔科夫链
马尔科夫链是最早用于语言生成的算法之一。它们仅通过使用当前单词来预测句子中的下一个单词。例如,如果模型仅适用以下句子进行训练:I drink coffee in the morning 和 I eat sanwiches with tea,那么,它预测 coffee 会跟随 drink 的可能性是 100%,而 I 跟随 drink 的可能性是 50%,跟随 eat 的可能性也是 50%。马尔科夫链考虑到每一个唯一单词之间的关系来计算下一个单词的概率。在早期版本的智能手机输入法中,马尔科夫链用于为句子中的下一个单词生成建议。
然而,由于马尔科夫模型只关注当前单词,因此会失去句子中前面单词的所有上下文和结构,从而有可能会导致错误的预测,如此一来,就限制了它们在许多生成场景中的适用性。
递归神经网络(RNN)
神经网络是受人类大脑运作的启发而建立的模型,通过对输入和输出之间的非线性关系建模,为计算提供了另一种方法,它们在语言建模中的应用被称为神经语言建模。
递归神经网络是一种能够利用输入的顺序性质的神经网络。它通过前馈网络传递序列的每一项,并将模型的输出作为序列中下一项的输入,从而能够允许存储来自前面步骤的信息。递归神经网络所有用的“记忆”能力使得它们非常适合语言生成,因为他们可以随着时间的推移记住对话的上下文。递归神经网络和马尔科夫链不同之处在于,它们也会观察之前看到的单词(而马尔科夫链只观察前面的单词)来进行预测。
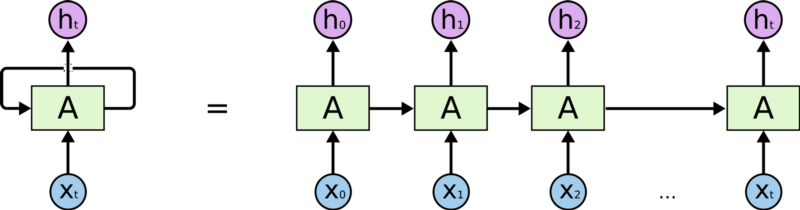
用于语言生成的递归神经网络
在递归神经网络的每次迭代中,模型都会将之前遇到的单词存储在内存中,并计算下一个单词的概率。例如,如果模型生成了文本 We need to rent a __,那么它现在就必须计算出这句子中的下一个单词。对于词典的每个单词,模型根据它所看到的前一个单词来分配概率。在我们的这个示例中,house 或 car 这两个词的概率要比 river 或 dinner 这样的单词高得多。然后选择概率最高的单词并将其存储在内存中,然后模型继续进行下一次迭代。
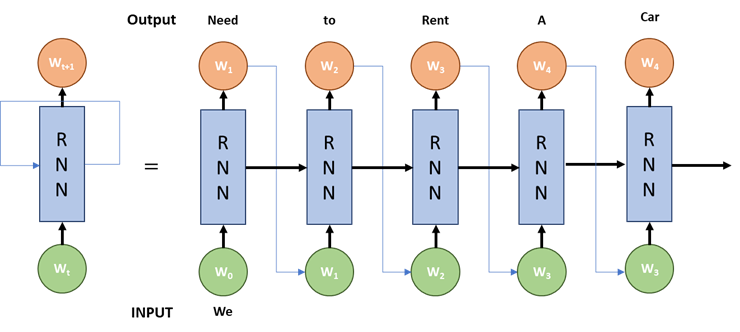
递归神经网络存在一个主要的限制:梯度消失问题。随着序列的长度增加,递归神经网络不能存储在句子后面很远的地方遇到的单词,且只能根据最近的单词进行预测。这就限制了递归神经网络在生成听起来连贯的长句的应用。
长短期记忆网络(LSTM)
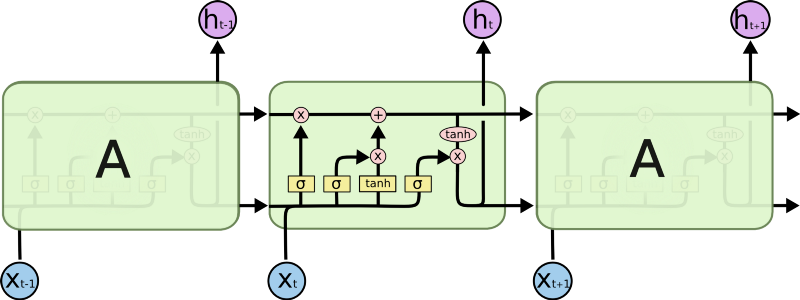
基于长短期记忆网络的神经网络是递归神经网络的一个变种,它比普通的递归神经网络能够更正确地处理输入序列中的长期依赖(long-range dependencies)问题。它们被用于各种各样的问题中。长短期记忆网络具有类似递归神经网络的链状结构;然而,它们是由四层神经网络组成,而不是递归神经网络那样的单层网络。长短期记忆网络由单元、输入门、输出门和遗忘门四部分组成。这样递归神经网络可以通过调节单元内外的信息流,在任意时间间隔内记住或忘记单词。
用于语言生成的长短期记忆网络

将下面这句话作为模型的输入:I am from Spain. I am fluent in __. 为了正确地预测下一个单词为 Spanish,该模型将重点放在前一句中的 Spain 一词上,并利用单元记忆来“记住”它。该信息在处理序列时由单元存储,然后用于预测下一个单词。当遇到句号时,遗忘门会意识到句子的上下文可能有所变化,当前单元状态信息就可以被忽略。这样网络就可以选择性地只跟踪相关信息,同时最小化梯度消失问题,模型就能够在更长的时间内记住信息。
长短期记忆网络及其变体似乎就是消除梯度来产生连贯句子问题的答案。但是,由于从以前的单元到当前单元仍然有一条复杂的顺序路径,因此可以保存多少信息还是有限制的。如此一来,长短期记忆网络能够记住的序列长度就限制在几百个单词以内。另外一个缺陷就是,由于计算要求很高,因此长短期网络很难训练。由于顺序性,它们很难并行化,这就限制了它们利用现代计算设备(如 GPU、TPU 之类)的能力。
Transformer
Transformer 最初是在 Google 论文《Attention Is All You Need》引入的,它提出了“自注意力机制”(self-attention mechanism)的新方法。Transformer 目前被广泛应用于各种自然语言处理任务,如语言建模、机器翻译和文本生成。Transformer 由一组编码器和一组解码器组成,前者处理任意长度的输入,后者输出生成的句子。

在上面的例子中,编码器处理输入句子并为其生成表示。解码器使用这种表示逐词创建输出句子。每个单词的出事表示 / 嵌入由未填充的圆圈表示。然后,模型使用自注意聚合来自所有其他单词的信息,以生成每个单词的新表示,由填充的圆圈表示,并由整个上下文通知。然后对所有单词并行重复该步骤多次,接连生成新的表示。类似地,解码器每次从左到右生成一个单词。它不仅关注先前创建的其他单词,还关注编码器开发的最终表示。
与长短期记忆网络不同的是,Transformer 只执行少量的、恒定数量的步骤,同时应用自注意力机制。这种机制直接模拟句子中所有单词之间的关系,而不考虑它们各自的位置。当模型处理输入序列中的每个单词时,自注意力机制允许模型查看输入序列的其他相关部分,以便更好地对单词进行编码。它使用多个注意力头(attention head),扩展了模型关注不同位置的能力,而无需考虑它们在序列中的距离。
近年来,对普通 Transformer 架构进行了一些改进,显著提高了它们的速度和正确度。2018 年,Google 发布了一篇关于 Transformer(BERT)双向编码器表示的论文,该论文为各种自然语言处理生成了最先进的结果。同样,2019 年,OpenAI 发布了一个基于 Transformer 的语言模型,它有大约 15 亿个参数,只需寥寥可数的几行输入文本即可生成长篇连贯的文章。
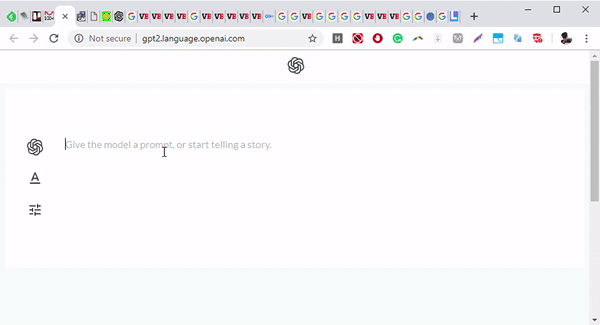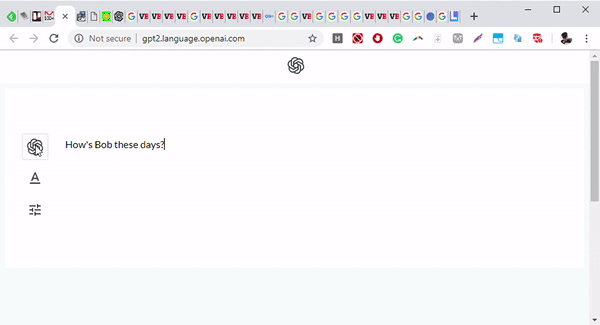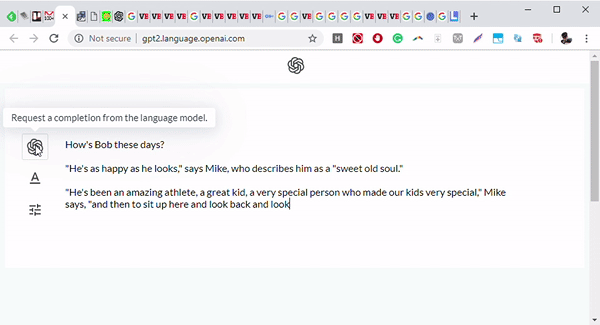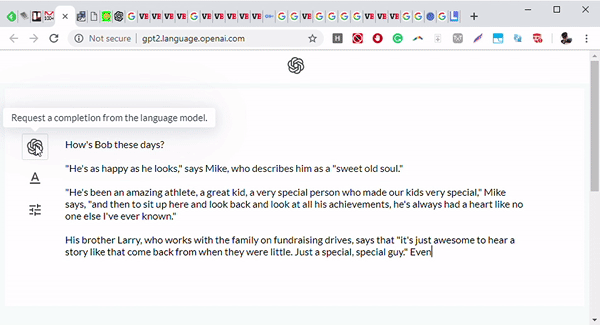
用于语言生成的 Transformer
最近,Transformer 也用于进行语言生成。其中最著名的例子之一是 OpenAI 的 GPT-2 语言模型。该模型学习预测句子中的下一个单词,是通过将注意力集中在于预测下一个单词相关的单词上进行学习的。

Transformer 生成文本是基于类似于机器翻译的结构。如果我们举一个例句: Her gown with the dots that are pink, white and __.模型将会预测下一个单词是 blue,因为它通过自注意力机制将列表中的前一个单词分析为颜色(white 和 pink),并理解预测的单词也应该是一种颜色。自注意力允许模型有选择地关注每个单词的句子的不同部分,而不是仅仅记住递归块(recurrent block)(在递归神经网络和长短期记忆网络中)的一些特征,这些特征大部分不会用于几个块中。这有助于模型能够回忆起前面句子的更多特征,并得到更准确和连贯的预测。与以前的模型不同,Transformer 可以在上下文中使用所有单词的标识,而无需将所有信息压缩为固定长度的表示。这种架构允许 Transformer 在更长的句子中保留信息,而不会显著增加计算需求。它们在不需要进行特定域修改的情况下,跨域的性能要比以前的模型表现得更好。
语言生成的未来
在本文中,我们看到了语言生成的演变过程,从使用简单的马尔科夫链生成句子,到使用自注意力机制的模型生成更长的连贯文本。然而,我们仍然处于生成语言建模的早期,而 Transformer 只是朝着真正自主文本生成方向迈出的一步。除此之外,生成模型也正在开发其他类型的内容,如图像、视频和音频等。这开启了将这些模型与生成文本模型集成的可能性,从而开发出具有音频 / 视频界面的高级个人助理。
然而,作为一个社会,我们需要谨慎地应用生成模型,因为它们为在网上生成虚假新闻、虚假评论和冒充他人开辟了多种可能性。OpenAI 决定不发布 GPT-2 模型,因为担心被滥用。这反映了这么一个事实:我们现在已进入一个语言模型强大到足以引起关注的时代。
生成模型有望改变我们的生活;然而,它们也是一把双刃剑。我们必须对这些模型进行适度的审查,无论是通过研究机构还是政府监管。在未来几年里,这一领域肯定还会取得更多进展。不管结果如何,展望未来,应该终会有激动人心的一刻!
原文链接:
https://medium.com/sfu-big-data/evolution-of-natural-language-generation-c5d7295d6517

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论