

今天带来的是一个篇长文,主要讲解高并发系统架构指标及调优测试经验,希望能对您的研究有所帮助。本文最先发布于 OpsDev,转载已获取作者授权。
高并发系统的优化一直以来都是一个很重要的问题,下面基于笔者的实践,和大家聊聊高并发系统的一些调优和优化策略。
1 系统性能的关键指标
吞吐量(Throughput)系统单位时间内处理任务的数量
延迟(Latency)系统对单个任务的平均响应时间
一般来说,考量一个系统的性能主要看这两个指标。而这两个指标之间又存在着一些联系:对于指定的系统来说,系统的吞吐量越大,处理的请求越多,服务器就越繁忙,响应速度就会慢下来;而延迟越低的系统,能够承载的吞吐量也相应的更高一些。
一方面,我们需要提高系统的吞吐量,以便服务更多的用户,另一方面我们需要将延迟控制在合理的范围内,以保证服务质量。
2 系统性能测试
业务场景
对于不同的业务系统,可以接受的延迟(Latency)也有所不同,例如邮件服务可以忍受的延迟显然要比 Web 服务高得多,所以首先我们需要根据业务场景的不同来定义理想的 Latency 值。
测试工具
我们需要一个能够制造高吞吐的工具来测试系统的性能,本文中使用的 Tsung,它是一个开源的支持分布式的压力测试工具,它功能丰富,性能强大,配置简单,并支持多种协议(HTTP、MySQL、LDAP、MQTT、XMPP 等)。
测试流程
测试的过程中需要不断加大吞吐量,同时注意观察服务端的负载,如果负载没有问题,那就观察延迟。一般这个过程需要反复很多次才能测出系统的极限值,而每次测试消耗的时间也比较长,需要耐心一些。
3 通用的系统参数调优
Linux 内核默认的参数考虑的是最通用的场景,不能够满足高并发系统的需求。
4 服务器参数调优
编辑文件/etc/sysctl.conf,添加以下内容:
关于这两项配置的含义可以查看系统手册:
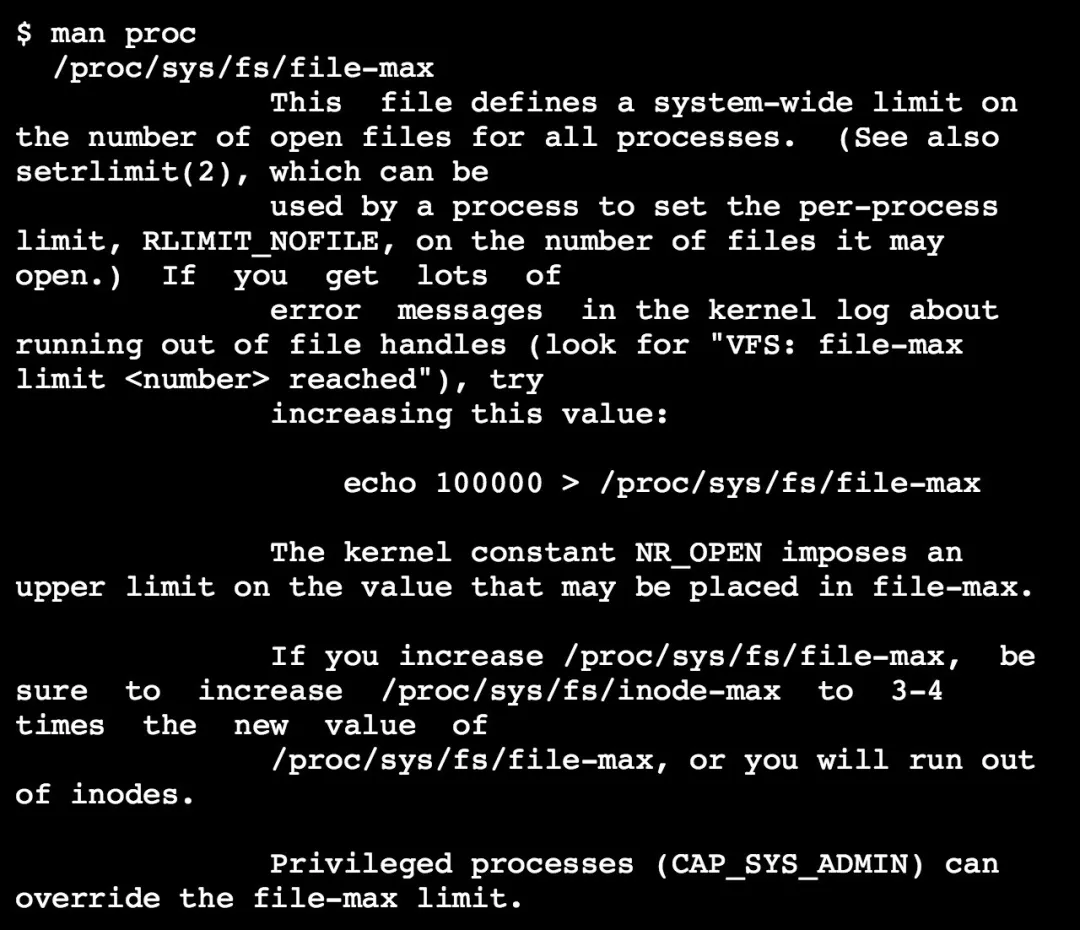
可以看到 file-max 的含义:它是系统所有进程一共可以打开的文件数量,它是系统级别的,因此应该尽量将它调的大一些,这里将它修改为一亿。 这里说到需要增大/proc/sys/fs/inode-max 的值,但是执行如下命令时发现没有该配置项:
再看 inode-max 说明:

可以看到有的系统中没有这个参数,所以先不管了。
对于 nr_open,系统手册里没有找到关于它的定义,不过我们可以参考kernel文档。
可以看到 nr_open 的描述与 file-max 十分相近,不仔细看几乎分辨不出区别。重点在于,file-max 是对所有进程(all processes)的限制,而 nr_open 是对单个进程(a process)的限制。这里给出了 nr_open 的默认值:
1024*1024 = 1048576
编辑文件/etc/security/limits.conf,添加如下内容:
编辑文件/etc/sysctl.conf,添加以下内容:
关于这两项配置的含义可以查看系统手册:
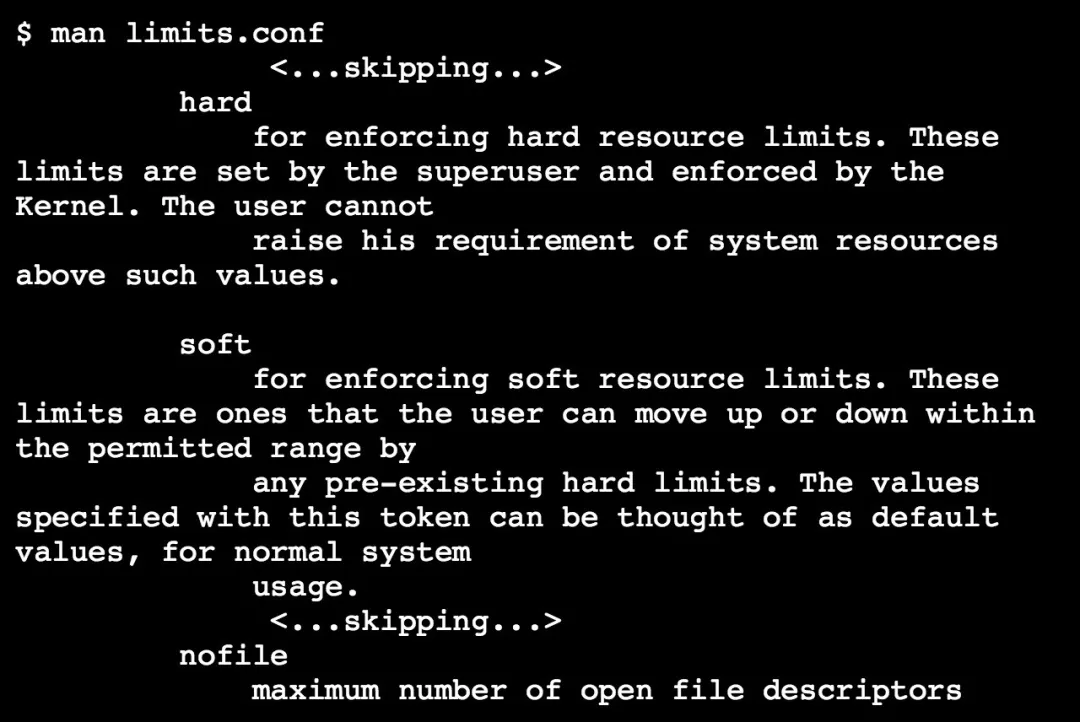
这里的意思很明确:hard 意为硬资源限制:一旦被 superuser 设置后不能增加;soft 为软资源设置:设置后在程序运行期间可以增加,但不能超过 hard 的限制。程序读取的是 soft,它是一个告警值。 nofile 意为用户打开最大文件描述符数量,在 Linux 下运行的网络服务器程序,每个 tcp 连接都要占用一个文件描述符,一旦文件描述符耗尽,新的连接到来就会返回"Too many open files"这样的错误,为了提高并发数,需要提高这项配置的数值。
这里有一点需要特别注意,而手册里面也没有细说:在 CentOS7 下(其他系统还未测试过),nofile 的值一定不能高于 nr_open,否则用户 ssh 登录不了系统,所以操作时务必小心:可以保留一个已登录的 root 会话,然后换个终端再次尝试 ssh 登录,万一操作失败,还可以用之前保留的 root 会话抢救一下。
修改完毕执行:
通过以上,我们修改了/etc/security/limits.conf 和/etc/sysctl.conf 两个配置文件,它们的区别在于 limits.conf 是用户层面的限制,而 sysctl.conf 是针对整个系统层面的限制。
5 压测客户机参数调优
对于压测机器来说,为了模拟大量的客户端,除了需要修改文件描述符限制外,还需要配置可用端口范围,可用端口数量决定了单台压测机器能够同时模拟的最大用户数量。
文件描述符数量:修改过程同服务器
可用端口数量:1024 以下的端口是操作系统保留的,我们可用的端口范围是 1024-65535,由于每个 TCP 连接都要用一个端口,这样单个 IP 可以模拟的用户数大概在 64000 左右 修改/etc/sysctl.conf 文件,添加如下内容:
修改完毕执行:
需要注意的是,服务器最好不要这样做,这是为了避免服务监听的端口被占用而无法启动。如果迫于现实(例如手头可用的机器实在太少),服务器必须同时用作压测机器的话,可以将服务监听端口添加到 ip_local_reserved_ports 中。下面举例说明:
修改/etc/sysctl.conf 文件,添加如下内容:
修改完毕执行:
TCP/IP 协议栈从 ip_local_port_range 中选取端口时,会排除 ip_local_reserved_ports 中定义的保留端口,因此就不会出现服务端口被占用而无法启动的情况。
6 程序调优
对于不同的业务系统,需要有针对性的对其进行调优,本文中测试的目标服务使用 Erlang/OTP 写就,Erlang/OTP 本身带有许多的限制,对于一般场景来说这些默认的设置是足够的;但是为了支持高并发,需要对 Erlang 虚拟机进行一些必要的参数调优,具体可以参考官方性能指南。
7 服务程序参数调优
进程(process)数量
Erlang 虚拟机默认的进程数量限制为 2^18=262144 个,这个值显然是不够的,我们可以在 erl 启动时添加参数+P 来突破这个限制
需要注意的是:这样启动,erlang 虚拟机的可用进程数量可能会比 10000000 大,这是因为 erlang 通常(但不总是)选择 2 的 N 次方的值作为进程数量上限。
原子(atom)数量
Erlang 虚拟机默认的原子数量上限为 1048576,假如每个会话使用一个原子,那么这个默认值就不够用了,我们可以在 erl 启动时添加参数+t:
从另一个角度来说,我们在编写 Erlang 程序时,使用原子需要特别小心:因为它消耗内存,而且不参与 GC,一旦创建就不会被移除掉;一旦超出原子的数量上限,Erlang 虚拟机就会 Crash,参见 How to Crash Erlang。
端口(port)数量 端口提供了与外部世界通讯的基本机制(这里的端口与 TCP/IP 端口的概念不同,需要注意区别),每个 Socket 连接需要消耗 1 个端口,官方文档里面说默认端口上限通常是 16384,但根据实测,Linux 系统默认为 65536,Windows 系统默认为 8192,无论多少,在这里都是需要调整的:在 erl 启动时添加参数+Q Number,其中 Number 取值范围是[1024-134217727]:
8 压测脚本调优
压测工具使用 Tsung。Tsung 支持多种协议,有着丰富的功能,并且配置简单灵活。下面是几点需要注意的地方:
内存
对于单个 Socket 连接来说消耗内存不多,但是几万甚至几十万个连接叠加起来就非常可观了,配置不当会导致压测端内存成为瓶颈。
TCP 发送、接收缓存 Tsung 默认的 TCP/UDP 缓存大小为 32KB,本例中我们测试的服务采用 MQTT 协议,它是一种非常轻量级的协议,32KB 还是显得过大了,我们将它设置为 4KB 大小就足够了:
Tsung 能够让模拟用户的进程在空闲时间(thinktime)进入休眠,用以降低内存消耗,默认空闲 10 秒触发,我们可以将它降低到 5 秒:
IO
不要启用 dumptraffic,除非用于调试,因为它需要将客户机和服务器往来的协议写入磁盘日志中,是一个 IO 开销非常大的行为。笔者曾经遇到过一次这样的问题,测试部门的同事使用 JMeter,压测过程中,服务端一直处于较低的负载,但 JMeter 最终得出的压测报告却包含很多超时错误。经过仔细排查,才定位到原来是压测端默认开启了 debug 日志,海量的 debug 日志生生拖垮了压测机器。所以遇到这种情况时,可以先检查一下压测端配置是否正确。
日志等级要调高一些,日志等级过低会打印很多无用信息:一方面会加大 IO 开销,另一方面会让有用的 ERROR 信息淹没在海量的调试日志中。
如果 Tsung 从 CSV 文件读取用户名密码,那么该 CSV 文件不能过大,否则读取该 CSV 将会变成一个极其耗时的操作,特别是当压测程序需要每秒产生大量用户时。
网络
有时候为了避免网络拥塞,需要限制压测客户机的带宽,使流量以比较平滑的速率发送和接收。
其采用令牌桶算法(token bucket),单位 KB/s,目前只对流入流量有效。
9 定位系统性能瓶颈
当系统吞吐和延迟上不去时,首先需要定位问题,而不是急于修改代码。
常见的性能瓶颈包括 CPU/内存/磁盘 IO/网络带宽等,其中每一项都有一到多个简单实用的工具: 对于 CPU 和内存,我们只要使用 top 就可以了;对于磁盘 IO,可以用 iotop 或 iostat;对于网络带宽,可以使用 iftop。
如果依然没能定位到问题,可能系统配置不当,参考通用的系统参数调优。
最后检查代码是否有单点瓶颈,例如程序被阻塞了:在笔者实测过程中,发现每个用户创建会话进程都需要对同一个 supervisor 发起同步请求,同时登录的用户数量很大时,这些同步请求会排队,甚至引发超时。
10 结束语
以上就是笔者做压力测试时遇到的一些问题以及应对办法,鉴于笔者水平有限,错漏难免。抛砖引玉,欢迎交流指正。
本文转载自公众号 360 云计算(ID:hulktalk)。
原文链接:
https://mp.weixin.qq.com/s/4LclaIGDBj4y6xZQRFiDeg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论