

无论怎样大肆宣传 NoSQL 数据库的出现,关系数据库都还将继续存在。原因很简单,关系数据库强制执行基本的结构和约束,并提供了很好的声明式语言来查询数据(我们都喜欢它):SQL!
但是,规模一直是关系数据库的问题。21 世纪的大多数企业都拥有丰富的数据存储和仓库,并希望最大限度地利用大数据来获得可操作的洞见。关系数据库可能很受欢迎,但除非我们投资了适当的大数据管理策略,否则不能很好地对它们进行扩展。这包括考虑潜在的数据源,数据量,约束,模式,ETL(提取 - 转换 - 加载),访问和查询模式等等!

本文将介绍在关系数据库的强大功能方面取得的一些优秀进展,而对于“大规模”,会介绍 Apache Spark – Spark SQL和DataFrames 中的一些新组件。最值得注意的是,将涵盖以下主题:
关系数据库扩展的动机和挑战
了解Spark SQL和DataFrames
目标
架构和功能
性能
人们努力地工作并投入时间在 ApacheShark 中构建新组件,我们关注他们的主要挑战和动机,以便能够大规模执行 SQL。我们还将研究 Spark SQL 和 DataFrames 的主要体系结构、接口、功能和性能基准。在本文最后,最重要的一点,我们将介绍一个分析入侵攻击的真实案例研究,基于KDD 99 CUP数据,利用 Spark SQL 和 DataFrames,通过Databricks云平台来平衡从而实现 Spark。
为大数据而扩展关系数据库的动机和挑战
关系数据存储易于构建和查询。此外,用户和开发人员通常更喜欢用类似人类的可读语言(如 SQL)编写易于解释的声明式查询。然而,随着数据的数量和多样性的增加,关系方法的伸缩性不足以构建大数据应用程序和分析系统。以下是一些主要挑战:
处理不同类型数据源,可以是结构化、半结构化和非结构化的;
建立各种数据源之间的ETL管道,这可能导致要开发大量特定的自定义代码,随着时间的推移会增加技术债务
能够执行基于传统商业智能(BI)的分析和高级分析(机器学习、统计建模等),后者在关系系统中执行肯定具有挑战性
大数据分析并不是昨天才发明的!我们在 Hadoop 和 MapReduce 范式方面取得了成功,这很厉害但进展太慢,它为用户提供了一个低级的、程序化的编程接口,需要人们编写大量代码来进行非常简单的数据转换。然而,自从 Spark 的发布,它真正改变了大数据分析的方式,不需要再把重点放在内存计算、容错、高级抽象和易用性上。
从那时起,一些框架和系统,如 Hive、Pig 和 Shark(演变成 Spark SQL),为大数据存储提供了丰富的关系接口和声明式查询机制。挑战在于,这些工具要么是基于关系的,要么是基于过程的,但是鱼和熊掌无法两者兼得。
然而,在现实世界中,大多数数据分析管道可能涉及到关系代码和过程代码的组合。如果强迫用户选择其中一个会最终让事情变得复杂,并增加用户在开发、构建和维护不同应用程序和系统方面的工作量。Apache Spark SQL 建立在前面提到的 SQL on Spark(称为 Shark)的基础上,它不强制要求用户在关系 API 或过程 API 之间进行选择,而是试图让用户无缝地混合使用它们,来对大数据进行大规模的数据查询、检索和分析。
了解 Spark SQL 和 DataFrame
Spark SQL 本质上试图用两个主要组件弥合我们之前提到的两个模型(关系模型和过程模型)之间的差距。
Spark SQL提供了一个DataFrame API,可以对外部数据源和Spark的内置分布式集合进行大规模的关系操作!
为了支持大数据中各种各样的数据源和算法,Spark SQL引入了一种名为Catalyst的新型可扩展优化器,可以轻松地为机器学习等高级分析添加数据源、优化规则和数据类型。
从本质上讲,Spark SQL 利用 Spark 的强大功能在大数据上大规模地执行分布式的、健壮的内存计算。Spark SQL 提供了最先进的 SQL 性能,并且兼容 Apache Hive(一种流行的大数据仓库框架)支持的所有现有结构和组件,包括数据格式、用户定义函数(UDF)和 Metastore。除此之外,它还有助于从大数据源和企业数据仓库(如 JSON,Hive,Parquet 等)中提取各种数据格式,并执行关系和过程操作的组合,以实现更复杂的高级分析。
目标
让我们看一下有关 Spark SQL 的一些有趣的事实,包括它的使用、采用和目标,其中一些我将再次从“ Spark中的关系数据处理 ”的优秀原始论文中复制过来。Spark SQL 于 2014 年 5 月首次发布,现在可能是 Spark 中最活跃的组件之一。Apache Spark 绝对是大数据处理最活跃的开源项目,有数百个贡献者。
除了作为一个开源项目,Spark SQL 已经开始得到主流行业的采用,并部署在了非常大规模的环境中。Facebook 有一个关于“ Apache Spark @Scale:一个 60TB+ 的生产用例 ” 的优秀案例研究,他们正在为实体排名做数据准备,其 Hive 的工作过去需要几天时间并面临许多挑战,但 Facebook 成功地使用 Spark 进行扩展并提高了性能。接下来让我们看看他们在这次旅程中遇到的有趣挑战!
另一个有趣的事实是,三分之二的 Databricks 云(运行 Spark 的托管服务)客户在其他编程语言中使用了 Spark SQL。在本系列的第二部分中,我们还将展示使用 Spark SQL on Databricks 的实际案例研究。
Spark SQL 的主要目标是由它的创建者所定义的:
无论是在Spark程序(在本机RDD上)还是在外部数据源上,都使用对程序员友好的API来支持关系处理
使用已建立的DBMS技术提供高性能
轻松支持新的数据源,包括半结构化数据和易于查询联合的外部数据库
使用高级分析算法(如图形处理和机器学习)进行扩展
架构和功能
现在我们来看看 Spark SQL 和 DataFrames 的主要功能和架构。这里需要牢记围绕着 Spark 生态系统的一些关键概念,随着时间的推移这个生态一直在不断发展。
RDD(弹性分布式数据集)可能是 Spark 所有成功案例背后的最大贡献者。它基本上是一种数据结构,或者更确切地说是分布式存储器的抽象,它允许程序员在大型分布式集群上执行内存计算,同时保留容错等方面的特性。还可以并行化大量计算和转换,并跟踪转换的整个过程,这有助于有效地重新计算丢失的数据。此外,Spark 使用驱动程序和执行程序的概念,如下图所示。
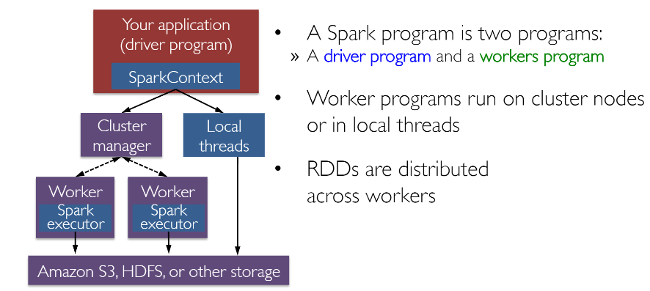
通常可以从文件、数据库读取数据,并行化现有集合甚至转换来创建 RDD。通常,转换是将数据转换为不同方面和维度的操作,具体取决于我们想要整理和处理数据的方式。它们也会被延迟地评估,这意味着即使定义了转换,在执行动作之前也不会计算结果,通常需要将结果返回到驱动程序(然后它会计算所有应用的转换!)。
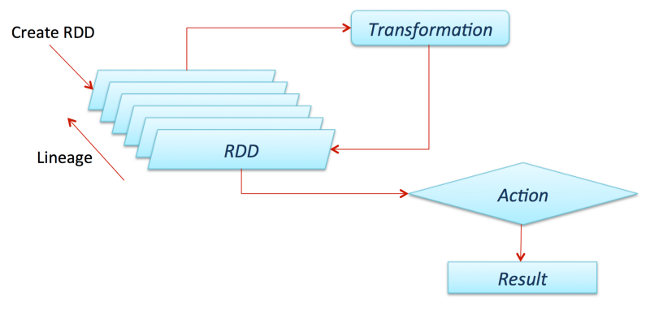
既然已经了解了 Spark 工作原理的架构,那么让我们更深入地了解 Spark SQL。通常,Spark SQL 在 Spark 之上作为库运行,正如我们在图中看到的那样,它覆盖了 Spark 生态系统。下图详细介绍了 Spark SQL 的典型体系结构和接口。
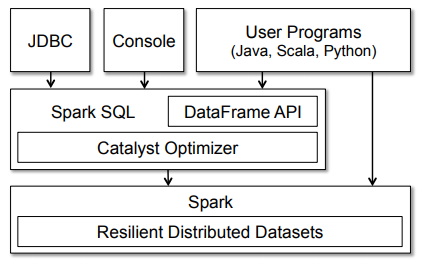
该图清楚地显示了各种 SQL 接口,通过 JDBC/ODBC 或命令行控制台来访问,集成到 Spark 支持的编程语言中的 DataFrame API(我们将使用 Python)。DataFrame API 非常强大,允许用户最终混合程序代码和关系代码!诸如 UDF(用户定义函数)之类的高级函数可以在 SQL 中使用,BI 工具也可以使用它。
Spark DataFrames 非常有趣,可以帮助我们利用 Spark SQL 的强大功能,并根据需要结合其过程式范例。Spark DataFrame 基本上是具有相同模式的行(行类型)的分布式集合,它基本上是被组织成一些命名列的Spark数据集。这里需要注意的是,数据集是 DataFrame API 的扩展,它提供了一种*类型安全的、面向对象的编程接口。*它们仅在 Java 和 Scala 中可用,因此我们将专注于 DataFrame。
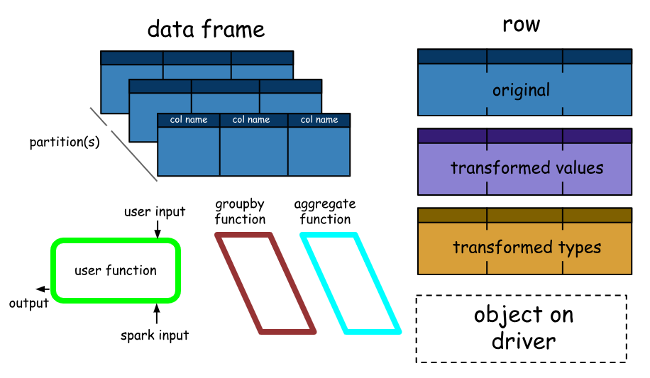
DataFrame 等同于关系数据库中的表(但在引擎盖下具有更多优化),并且还可以以类似于 Spark(RDD)中的“本机”分布式集合的方式进行操作。Spark DataFrames 有一些有趣的属性,例如:
与RDD不同,DataFrame通常会跟踪schema并支持各种关系操作,从而实现更优化的执行。
DataFrame可以通过表来构建,就像大数据基础结构中现有的Hive表一样,甚至可以从现有的RDD来构建。
DataFrames可以使用直接SQL查询操作,也可以使用DataFrame DSL(特定领域语言),以及使用各种关系运算符和变换器,例如where和groupBy。
此外,每个DataFrame也可以被视为行对象的RDD,允许用户调用过程化的Spark API,例如map。
最后,与传统的Dataframe API(Pandas)不同,Spark DataFrames具有延迟性,因为每个DataFrame对象都代表一个逻辑计划来计算数据集,但在用户调用特殊的“输出操作”(如save)之前,不会执行任何操作。
这应该让您对 Spark SQL、数据框架、基本特性、概念、体系结构和接口有了足够的了解。下面让我们看一下性能基准来完成这一部分。
性能
在没有正确优化的情况下发布一个新特性是致命的,构建 Spark 的人做了大量的性能测试和基准测试!让我们看看一些有趣的结果,下面描述了展示一些结果的第一个图。
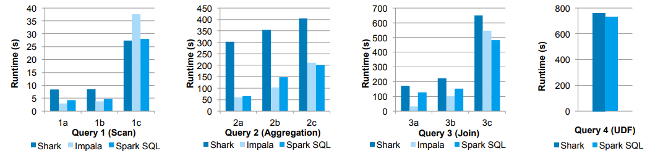
在这些实验中,他们使用 AMPLab 的大数据基准测试比较了 Spark SQL 与 Shark 和 Impala 的性能,后者使用了 Pavlo 等人开发的网络分析工作负载。基准测试包含带不同参数的四种类型查询,这些查询具有执行扫描、聚合、连接和基于 UDF 的 MapReduce 作业。使用列式 Parquet 格式压缩后,数据集包含了 110GB 的数据。我们看到,在所有查询中,Spark SQL 比 Shark 快得多,通常与 Impala 竞争。Catalyst 优化器负责这个压缩,降低了 CPU 开销(后面会简要介绍这一点)。此功能使 Spark SQL 在许多查询中与基于 C ++和 LLVM 的 Impala 引擎竞争,与 Impala 的最大差距在于 Query 3a 中 Impala 选择更好的 join 计划,查询的选择性使得其中一个表非常小。
下面的图表显示了 DataFrames 和常规 Spark API 以及 Spark + SQL 的一些性能基准。

Spark DataFrames vs. RDD 和 SQL
最后,下图显示了不同语言中 DataFrames 与 RDD 的一个很好的基准测试结果,从而为优化的 DataFrames 提供了一个有趣的视角。
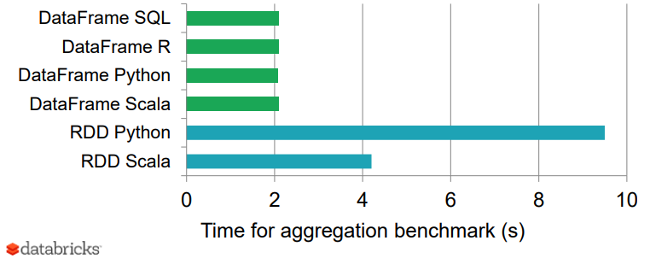
比较 Spark DataFrames 和 RDD
性能秘诀:Catalyst 优化器
为什么 Spark SQL 如此快速和优化?原因是因为新的可扩展优化器 Catalyst,基于 scala 中的函数式编程结构。虽然不会在这里详细介绍 Catalyst,但值得一提的是,它有助于优化 DataFrames 的操作和查询。
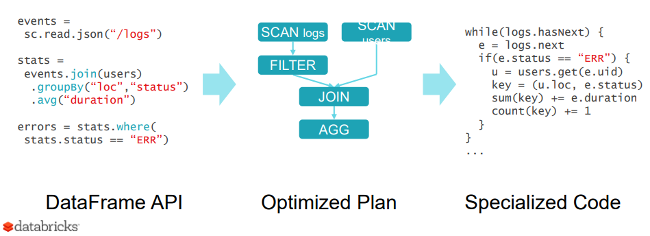
Catalyst 的可扩展设计有两个目的:
可以轻松地为Spark SQL添加新的优化技术和功能,尤其是解决大数据、半结构化数据和高级分析方面的各种问题
易于优化器的扩展 – 例如,通过添加定制于数据源的规则,可以将过滤或聚合推送到外部存储系统,或支持新的数据类型
Catalyst 支持基于规则和基于成本的优化。虽然可扩展优化器在过去已经被提出,但它们通常需要一种复杂的特定于域的语言来指定规则。通常,这会导致显著的学习曲线和维护负担。相比之下,Catalyst 使用 Scala 编程语言的标准特性,例如模式匹配,让开发人员使用完整的编程语言,同时仍然使规则易于指定。
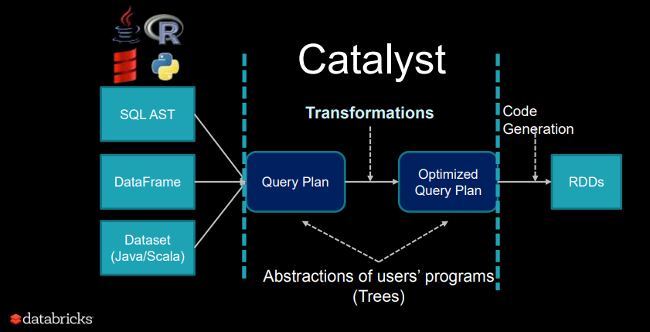
Catalyst 的核心包含了一个通用库,用于表示树状结构并应用规则来操作它们。在这个框架的顶部,包含关系查询处理(例如,表达式、逻辑查询计划)的库,以及处理查询执行的不同阶段的若干规则:分析、逻辑优化、物理规划和代码生成,以将查询的部分编译成 Java 字节码。
关于作者
Dipanjan(DJ)Sarkar – Dipanjan(DJ)Sarkar 是 RedHat 的数据科学家、出版作家、顾问和培训师。他曾在多家创业公司以及英特尔等财富 500 强公司做过顾问和合作。他主要致力于利用数据科学、机器学习和深度学习来构建大规模智能系统。他拥有数据科学和软件工程专业的技术硕士学位。他也是自学者和大规模开放在线课程的狂热支持者。
查看英文原文:Scaling relational databases with Apache Spark SQL and DataFrames

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论