

DT 时代,银行业务趋向敏态化,数据量呈现出爆炸式增长态势,这些蕴涵无限价值的大数据给整个银行体系带来了创新动能,成为银行提升竞争力的关键因素。从业界数据管理和数据利用的趋势来看,数据平台进化已成为各银行急需解决的问题。
如何选择进化路径?本期,我们邀请了 Kyligence 资深解决方案架构师李明江分享他对银行业数据平台进化的洞察。
银行业是最早进行电子化、信息化建设的行业之一,也是最早发掘数据价值的行业之一。自 2000 年起,国内银行企业开始构建数据仓库利用数据进行经营分析和业务决策,目前银行行业在数据管理和利用方面处于领先行列。
银行行业数据仓库架构基本按照“数据集成-面向主题整合-应用支持”设计数据层次架构,其中面向主题整合的数据模型是数据仓库的核心,数据模型通常采用 ER 模型设计方法,国内银行普遍应用的是 Teradata FS-LDM 模型,通过定义业务主题,抽象业务的实体-关系,涵盖金融企业主要的业务元素及相互关系,明确相对稳定的数据结构,为决策支持提供稳定的数据资源。
随着数据积累和数据化运营的发展,在数据平台技术架构层面,部分银行采用了针对数据仓库的 MPP 架构数据库和一体机,如 Teradata、Greenplum 等,通过专用硬件+横向扩展并行计算的方式提高数据仓库的性能。
2012 年后互联网的发展使得银行行业纷纷拥抱互联网进行数字化转型,业务模式从传统线上转为线上线下结合,业务处理方式更加多样,数据来源大大扩展,数据量爆炸式增长,此时传统数据仓库已很难满足海量数据下的性能要求。
01 银行数据平台化探索
在初期,银行企业采取扩展 MPP 基础设施的方式进行应对,但随着新型业务的不断增加(普惠银行、生活服务、网上支付等)、数据海量涌入、业务运营数据分析需求增多,单纯扩展 MPP 架构带来扩容和运维成本的急剧增加,同时 MPP 架构并非线性增长的扩展能力亦愈来愈难满足数据量和业务需求的增长。
随着可部署在低廉硬件上的 Hadoop 技术体系的发展和成熟,银行机构纷纷引入 Hadoop 技术体系,与 MPP 数据仓库一起搭建了混合式数据平台。新型业务数据直接采集入 Hadoop 平台,利用 Hadoop 平台的低廉基础架构、可扩展的高性能并行计算能力对数据进行存储和计算。由于 Hadoop 平台中,数据仓库一般使用 Hive 实现, Hive 能够满足表关联以满足 3NF 数据关系,但是 Hive 更适合大数据量批量计算,对于即席交互支持能力较弱。因此银行在混搭架构数据平台中,Hadoop 平台更多作为历史数据存储平台和计算平台使用,计算好的数据导入传统 MPP 数仓中,通过 BI 工 具进行业务分析。

目前大多银行企业都搭建了如上图所示的混搭架构数据平台,虽然在一定程度上降低了 MPP 数仓的存储和计算压力,但是仍旧存在一些问题。
一方面部分海量业务数据仍然进入传统数仓,如互联网支付导致账户交易流水数据量暴增。
另一方面由于 Hadoop 平台数据交互的短板,应用数据在 Hadoop 计算完成后,仍导入到 MPP 数仓的集市层,导致 MPP 数仓仍然面临扩容压力。
另外混搭架构导致数据处理路径变长,存在跨物理集群数据搬迁的过程,导致了 ETL 时长增加,同时增加了管理和运维的复杂度。
由于混搭架构存在的问题,很多银行开始思考将整个传统数仓整体迁移到 Hadoop 平台,其中某银行采取了比较直接的方法,将原来的数仓架构和模型原样搬迁到 Hadoop 上,如下图所示:
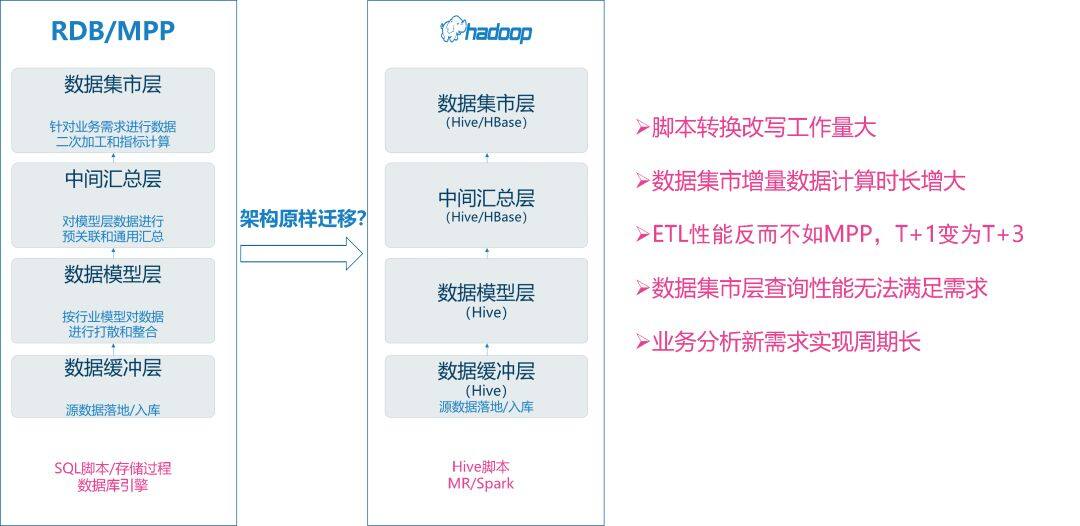
(MPP 迁移存在的问题)
整体迁移完成后,这种简单复制过来的新数仓暴露出现了一些问题,主要表现在:
原样搬迁数据模型层,FS-LDM 为保障结构稳定性建立的大量关系表在迁移到 Hive 后,集市层数据统计计算需要关联大量的表进行数据计算,ETL 时长由原来 T+1,变成 T+3 乃至更长,不能满足业务分析需求。
由于集市层数据用 Hive 存储,在多表关联查询时性能很差,大部分查询需要数分钟到数十分钟。
新兴业务(如 APP 用户行为分析)的需求实现需要扩展模型并逐层数据加工,导致新需求开发周期很长。
对于上述问题,目前应急的解决方法是增加基础设施(DataNode 数量),从而使 ETL 时长满足业务的需要,但这种方式仍然存在问题:
硬件投资大大增加,降本增效的效果大打折扣
由于 Hive 多表关联的性能问题依然存在,查询响应时间变长,数据交互访问的性能降低
数字化转型使得利用数据进行运营的业务人员大大增加,数据访问的并发应对面临挑战
02 数据平台进化的路径有哪些?
面对传统数仓迁移到 Hadoop 平台的风险和挑战,各银行不约而同采取了审慎的态度,大多将 Hadoop 平台用于历史数据存储和大数据计算,而一些规模较大的银行和数字化转型较快的银行面对数据量的海量增长,积极探索可行方案,实现数据平台的改进和优化。
从目前来看,银行数据平台进化大致有如下几个路径:
数仓架构整体搬迁,即将传统数据从数据层次到数据模型整体搬迁到 Hadoop 平台,通过增加算力方式或对数据模型和 ETL 脚本进行优化方式满足业务需求。
在 Hadoop 平台构建全新数仓,即在 Hadoop 平台上利用其技术特性结合银行业务数据重新构建数仓模型。
保持混搭架构,新业务如普惠银行、移动服务、客户画像等在 Hadoop 平台实现,传统业务数据仍在 MPP 数仓,部分应用数据在技术支持的前提下有序迁移到 Hadoop 平台。
第一种方案业界已有所尝试,目前只能通过增加硬件的方式达到在一体机或专用硬件的性能,而针对数据模型和 ETL 脚本优化技术难度也比较高,总体来看,整体搬迁的方式风险较高,效果较难把握,容易造成业务部门的质疑,当前不是一种稳妥方案。
第二种方案中,构建满足 Inmon 思想的相对稳定特性的 ER 数据模型,这一方案在当前 Hadoop 技术体系下很难完成。借鉴阿里数据仓库进化实践,以 Kimball 思想的维度建模方式更适合 Haoop 平台技术体系特点。但以审慎为原则的银行重新构建一套数仓平台并非易事,银行需要大量对业务数据和 Hadoop 技术都比较精通的人才队伍,同时也需要很强的高层决断力才能推进,对于稳定优先的银行业,目前尚无实践。
在当前数据量增长较快和业务数据化运营不断增强的形势下,部分银行选择了第三种方案,即在用传统数仓继续满足业务统计和分析需求的前提下,将新业务的数据直接采集入 Hadoop 平台采用维度建模,结合 Hadoop 平台的 OLAP 组件进行数据加工并提供数据服务,以控制 MPP 数仓的过快增长,同时满足新业务分析的需要。
03 从实践中寻找最佳路径
近日,在 Kyligence 在厦门举办了主题为数据平台演进技术沙龙,某大型国有银行介绍了其在数据平台进化过程中从传统数仓向 Hadoop 迁移的路线选择,以及和 Kyligence 共同合作过程中打造的实践心得和方法论。
随着数字化转型的发展,该行 Greenplum 数据仓库集群规模不断扩大,集群资源始终处于紧张状态,扩容和维护成本越来越高,因此该行逐步将部分数据加工、存储和服务的功能迁移到 Hadoop 平台。
在数据仓库迁移的过程中,针对 Hadoop 平台各组件的技术特点,结合银行业务数据情况,按照先易后难的方针,对各类业务应用数据进行迁移,并在迁移过程中对旧的数据分析方法进行了改进,提升多维数据自助分析的灵活度和效率,一方面利用了 Hadoop 平台上高性能多维分析组件(如 Apache Kylin)的技术特点,另一方面也提高了数据分析的灵活性。
不同技术体系的加工逻辑迁移是一个非常复杂的工程,在数仓迁移的过程中,该行引入 Kyligence 研发的自动化迁移工具,辅助将 Greenplum ETL 脚本进行自动化转换,迁移工具可完成 90% 的脚本转换工作,大大提高了迁移的效率和质量。

(自动化迁移工具使用效果)
可维护性提高-在数仓迁移实践中, ETL 脚本代码量减少了一半以上,提高了可维护性。同时利用 Hadoop 平台优异的分布式计算能力,ETL 加工的效率亦得到了很大的改善。如普惠银行应用数据迁移后,ETL 效率平均提升了 4 倍以上,减少了 ETL 时间窗口。
查询性能提高-在充分利用 Kylin 企业版进行数据预计算后,前端报表查询性能亦从原来的数分钟提升到了秒级甚至亚秒级。
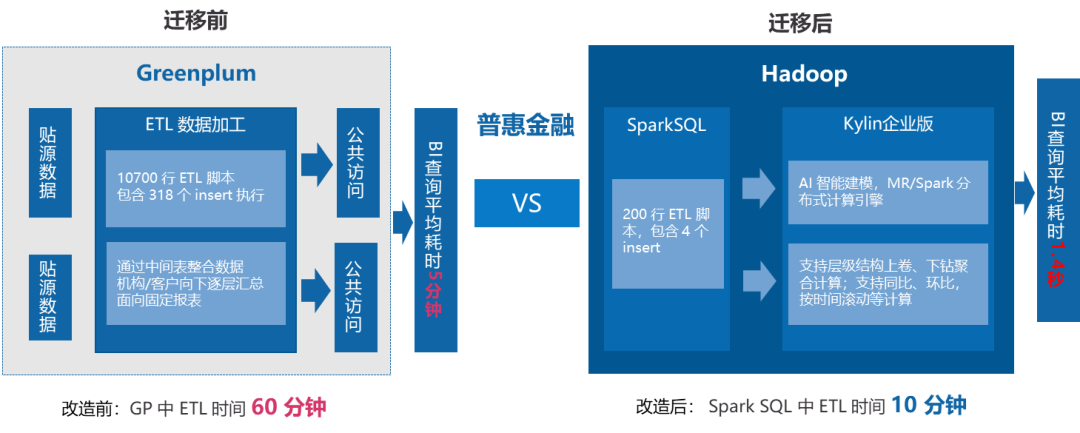
(数仓迁移后,查询性能提升)
在优化数据平台架构,应用数据迁移的实践中,我们与该行共同总结了一套数仓迁移方法论,为后续数据平台持续进化提供了支持,希望为银行业进行数据平台进化提供参考。

(数仓迁移方法论)
我们将持续为大家带来银行数仓迁移过程中遇到的具体挑战和最佳实践,敬请期待。
原文链接:
https://mp.weixin.qq.com/s/3q4Xrd6lnm20EGupPAUiBA
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论