

背景和介绍
如何从用户历史行为数据中建模他们动态、不断变化的兴趣特征已经成为 CTR 预估的一个关键问题,比如上一篇文章我们介绍了 DIEN 来建模用户的兴趣特征。但是大都数工作还是忽略了用户行为序列内在的结构:用户的行为 sequences 其实是由多个 sessions 组成,其中多个 sessions 是通过用户的点击时间来区分。
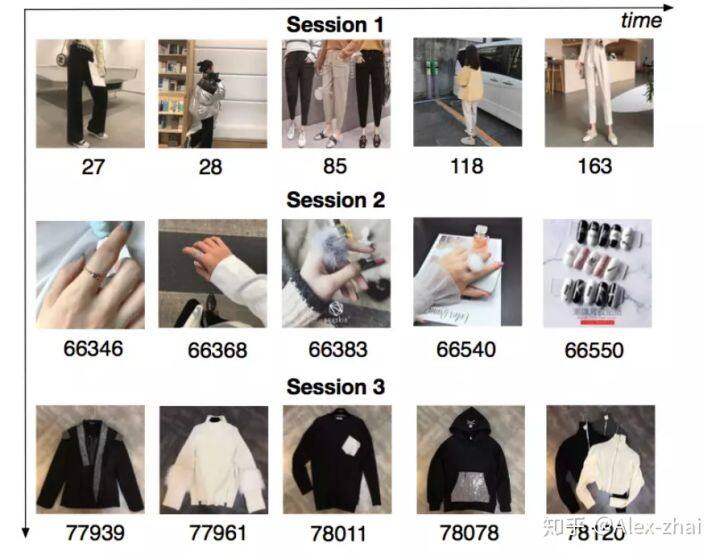
如下图,将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于 30min,就进行切分。可以看上图,第一个 session 中,用户查看的都是跟裤子相关的物品,第二个 session 中,查看的是戒指相关的物品,第三个则是上衣相关。我们发现在同个 session 中的行为是相近的,而在不同 session 之间差别是很大的。这说明用户在同一个 session 下对购买商品有一个明确的、单独的需求,但是一旦开启一个新的 session,他的兴趣将会发生很大的变化。基于该观察,我们提出了一个 CTR 预估模型,被称作 Deep Session Interest Network(DSIN)。该模型充分利用了用户的多个历史行为 sessions。
创新点:
首先,根据点击时间将用户的行为序列区分成多个 sessions,并使用带有 bias 编码的自注意力模块来抽取用户每个 session 的兴趣特征。
使用双向 LSTM 建模用户在多个 sessions 间兴趣的演变过程。
使用 local activation 单元自适应学习不同 session 的兴趣对 target item 的影响。
模型
1.Base Model
Base Model 是一个 MLP 网络,在 basemodel 中输入特征分为三部分:User Profile, Item Profile 和 User Behavior。User Profile 包括性别、城市、用户 ID 等等,Item Profile 特征包含商家 ID、品牌 ID 等等,User Behavior 历史行为序列特征主要是用户最近点击的物品 ID 序列。当然一些 item 的 side information 也可以加到输入特征中。
这些特征分别通过 Embedding 层转换为对应的 embedding 向量,拼接后输入到多层全连接中,并使用 logloss 指导模型的训练。
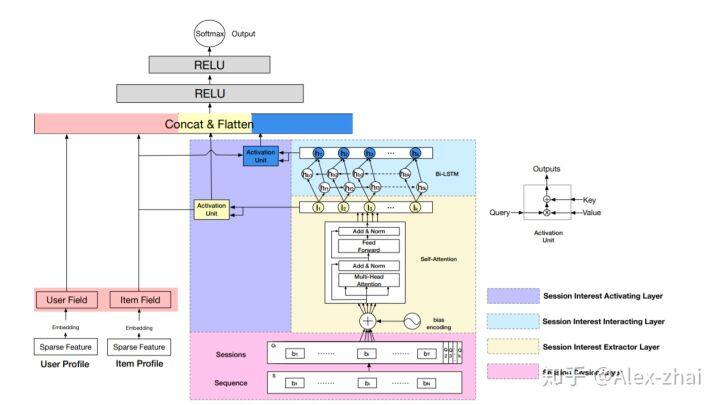
DSIN 模型
如下图,在 MLP 之前 DSIN 包含两大部分,其中一部分是 User Profile 和 Item Profile 通过 embedding 层然后 concat 的向量;另一部分 User Behavior 主要是对用户行为序列进行建模,从下到上分为四层:
session division layer:主要是将用户的历史行为序列划分为多个 sessions
将用户的历史点击行为序列进行切分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,如果前后的时间间隔大于 30min,就进行切分。切分后,我们可以将用户的行为序列 S 转换成会话序列 Q。第 k 个会话 Qk=[b1;b2;…;bi;…;bT], 其中,T 是会话的长度,bi 是会话中第 i 个行为。
session interest extractor layer:抽取用户 session 的兴趣
因为同个 session 中的行为是高度相关的,并且用户在当前 session 下的随意的一些行为会使得 session 的兴趣表示变得不准确。为了建模在同一 session 中多个行为的关系和减轻那些不大相关行为的影响。DSIN 对每个 session 都使用 Transformer 中的 multi-head self-attention 模块来抽取用户 session 的兴趣特征。具体过程是:对用户行为序列中的每个 session 添加一个 Positional Encoding,该模块被称为 Bias Encoding,BE 中的每个元素都分为三块:
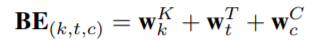
其中 BE 是 K * T * d 的。BE(k,t,c)是第 k 个 session 中,第 t 个物品的 embedding 向量的第 c 个位置的偏置项。也就是说,对每个 session 中的每个物品对应的 embedding 的每个位置,都加入了偏置项。加入偏置项后 Q 变为,Q 是用户行为 session 的表示:
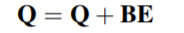
在推荐系统中,用户的点击行为会受各种因素影响,比如颜色、款式和价格。Mulit-head self attention 模块可以在不同的表示子空间层面上建模这种关系。这里让 QK 表示为:
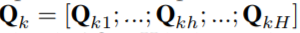
其中 Qkh 是 T*dh 的,是 Qk 的第 h 个 head,H 是 head 的数量。其中第 h 个 head 的输出为:
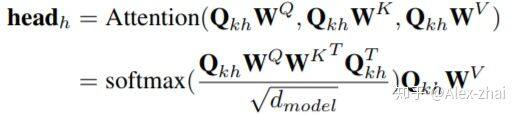
然后将不同 head 的输出 concat 后输入到一个全连接网络中:

经过 Mulit-head self attention 处理之后,每个 Session 得到的结果仍然是 T * d 大小的,随后,经过一个 avg pooling 操作,将每个 session 兴趣转换成一个 d 维向量。
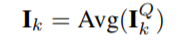
session interest interacting layer:建模用户多个 sessions 之间的联系。每个时刻的 hidden state 计算如下:
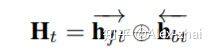
相加的两项分别是前向传播和反向传播对应的 t 时刻的 hidden state。这里得到的隐藏层状态 Ht,混合了上下文信息的会话兴趣。
session interest activating layer:建模不同 session 和 target item 的关联度。也就是说用户的会话兴趣与目标物品越相近,越应该赋予更大的权重。使用注意力机制来刻画这种相关性:
同样,混合了上下文信息的会话兴趣,也进行同样的处理。最后将 User profile 向量、Item profile 向量、会话兴趣加权向量 UI、带上下文信息的会话兴趣加权向量 UH 进行横向拼接,输入到全连接层中,得到最终的输出。
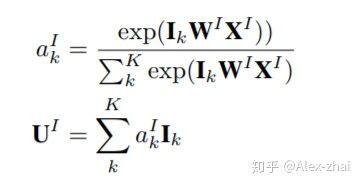
实验
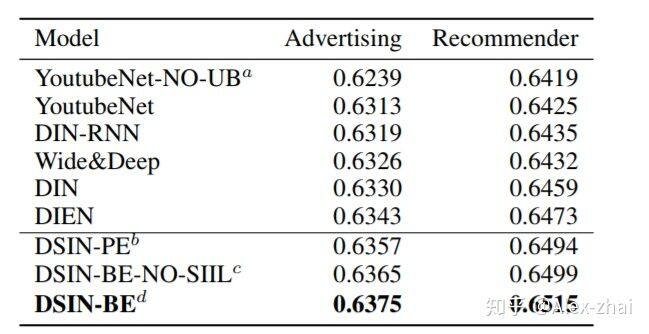
使用了两个数据集进行了实验,分别是阿里妈妈的广告数据集和阿里巴巴的电商推荐数据集。对比模型有 YoutubeNet、Wide & Deep、DIN 、DIN-RNN、DIEN,评价指标为 AUC。结果:
参考文献:
https://arxiv.org/pdf/1905.06482.pdf
https://www.jianshu.com/p/82ccb10f9ede
本文转载自 Alex-zhai 知乎账号。
原文链接:https://zhuanlan.zhihu.com/p/71695849

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论