

场景概述
在医学报告整理和内容提取的场景中,从业人员往往需要花费大量的时间进行内容阅读和关键字的提炼;Amazon Textract 结合 Amazon Comprehend Medical 的解决方案整体采用无服务器化架构,全自动化也提高整体效率。采用该解决方案,可以以秒级的效率提取出需要的内容;除此之外,该架构也大大降低了整体成本,架构中包含的所有服务都以实际使用计费。
Amazon Textract 是一个托管的 OCR(Optical Character Recognition) 服务,Amazon Comprehend Medical 是一个医疗语义分析的托管人工智能服务。通过 Amazon Textract 将医学报告和诊断报告的表单表格转化成序列化文档,通过 Amazon Comprehend Medical 对这些序列化文档进行分析并快速获取不同分类的信息。在 CRO(Clinical Research Organization) 等行业场景中,可以通过这个解决方案对医学研究、药物分析及诊断报告提供有效的帮助和补充。
服务架构
在这个架构中,我们需要创建:
一个 Amazon S3 存储桶用来存放输入的文档资料和输出的结果文件
一个用来调用 Amazon Textract API 的 AWS Lambda 函数
一个用来调用 Amazon Comprehend Medical API 的 AWS Lambda 函数
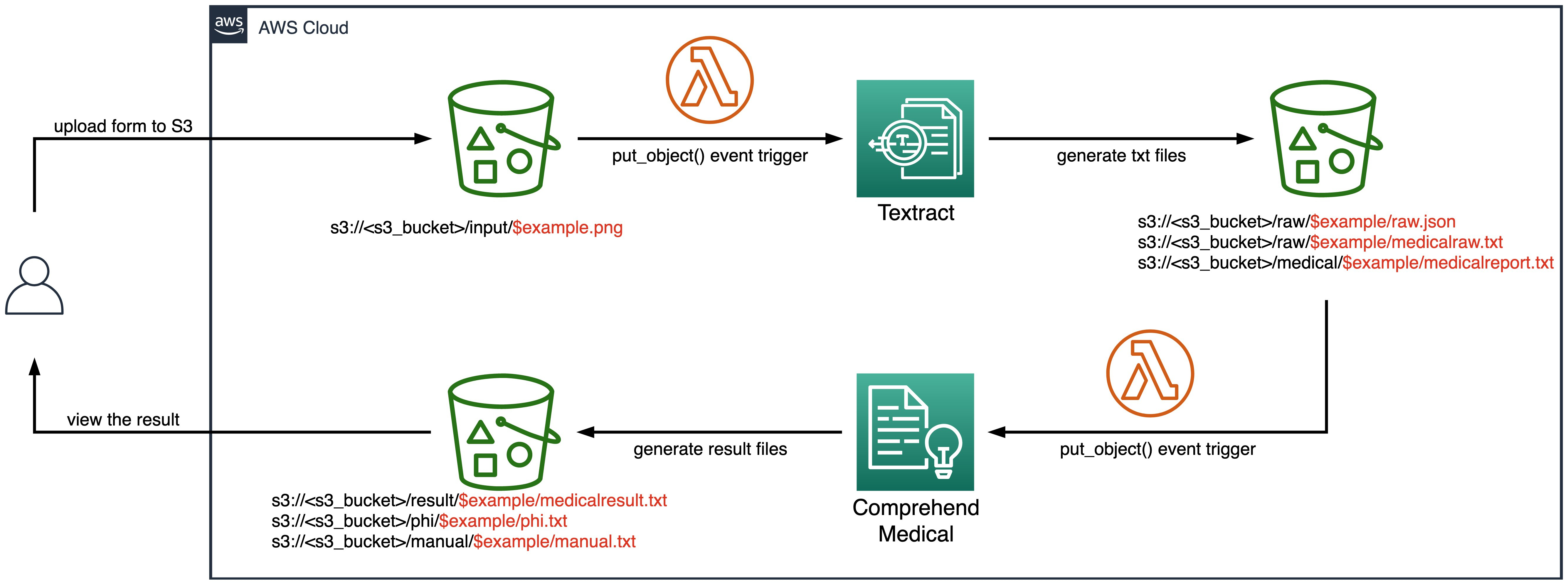
架构逻辑如下:
以用户向 Amazon S3 传入一个文档为例,上传成功后 AWS Lambda 函数会以该事件作为触发并调用 Amazon Textract API,将该文档内容提取成序列化的文档以及待分析的文本,并存入 Amazon S3 的相应路径
上述待分析文本传入 Amazon S3 后,又会触发下一个 AWS Lambda 函数,调用 Amazon Comprehend Medical API,对内容进行语义分析,并将分析后的结果写入 Amazon S3
完成以上自动化的操作后,用户即可查询读取提炼后的内容进行进一步的工作
具体实现
Amazon S3 存储桶配置
创建用于输入和输出医学分析报告的存储桶和桶下面相应目录,例如:
存储桶:s3://medical-report-analysis-<unique_identifier>
这里的<unique_identifier> 用以和其他用户的 S3 存储桶区分,因为 Amazon S3 存储桶的名称具有全球唯一性
文档输入目录:s3://medical-report-analysis-<unique_identifier>/input
手动检查目录:s3://medical-report-analysis-<unique_identifier>/manual
分析输入目录:s3://medical-report-analysis-<unique_identifier>/medical
保护数据目录:s3://medical-report-analysis-<unique_identifier>/phi
原始文档目录:s3://medical-report-analysis-<unique_identifier>/raw
分析结果目录:s3://medical-report-analysis-<unique_identifier>/result

启用 Amazon S3 的版本控制
AWS IAM 权限配置
由于整体技术实现会通过 AWS Lambda 作为粘合剂将几个服务串联起来,所以需要创建相应的 AWS IAM 角色以确保服务之间有权限进行相互调用;以下会创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role,以及用于串接 Amazon S3 和 Amazon Comprehend Medical 的 AWS IAM Role:
创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Policy:
策略名称:LAMBDA_TEXTRACT_S3_RW
策略文档:
Python
创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role:
受信任实体:Lambda
绑定策略:LAMBDA_TEXTRACT_S3_RW
角色名称:LAMBDA_TEXTRACT_S3_RW_ALL
创建用于串接 Amazon S3 和 Amazon Comprehend Medical 的 AWS IAM Policy:
策略名称:LAMBDA_COMPREHENDMEDICAL_S3_RW
策略文档:
Python
创建用于串接 Amazon S3 和 Amazon Textract 的 AWS IAM Role:
受信任实体:Lambda
绑定策略:LAMBDA_COMPREHENDMEDICAL_S3_RW
角色名称:LAMBDA_COMPREHENDMEDICAL_S3_RW_ALL
AWS Lambda 函数 – textract_content_ingest
函数名称:textract_content_ingest
运行时:Python 3.8
执行角色:LAMBDA_TEXTRACT_S3_RW_ALL
内存分配:1024 MB
超时:1 分钟
代码如下:
Python
AWS Lambda 函数 – comprehendmedical_analysis
函数名称:comprehendmedical_analysis
运行时:Python 3.8
执行角色:LAMBDA_COMPREHENDMEDICAL_S3_RW_ALL
内存分配:1024 MB
超时:1 分钟
代码如下:
Python
Amazon S3 事件与 AWS Lambda 集成
使用拥有 Amazon S3 管理权限的用户登录 AWS 管理控制台
进入到相应的 Amazon S3 存储桶 (medical-report-analysis-<unique_identifier>)
切换到“属性”选项卡,点开“事件”
点击“添加通知”,输入名称“upload_report”,事件勾选 “PUT”,前缀处输入 “input/”,发送到选择 AWS Lambda,选择函数 textract_content_ingest,然后选择保存
点击“添加通知”,输入名称“comprehendmedical_analysis”,事件勾选 “PUT”,前缀处输入 “medical/”,发送到选择 AWS Lambda,选择函数 comprehendmedical_analysis,然后选择保存
本文转载自 AWS 技术博客。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论