

对于前端工程师来说,开发 GUI 界面极其耗费时间和精力。这种重复、繁琐的工作是否可以交给机器自动化完成,是目前 AI 领域研究人员积极探索的新方向。最近,西安交通大学的人工智能与机器人研究所提出了一种新的方法,可以帮助前端工程师将设计好的 GUI 图自动转换为代码,不仅在简单布局的 GUI 上可以生成非常好的代码,即使在图形元素复杂、样式复杂、空间布局复杂的情况下,生成效果也非常接近真实情况。本文是 AI 前线第 56 篇论文导读,我们将深入探讨这一方法背后的技术实现细节,揭开其神秘的面纱。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
介 绍

**目前,利用机器学习技术自动化生成用户界面的代码是 AI 领域比较热门的研究方向。**前端工程师在开发 GUI 时会耗费大量的时间和精力。如果有一套系统,可以根据图形界面自动生成代码,将会大大提高开发者的效率。
之前已经有研究者做过相关研究,其中一项工作是使用梯度下降的方法,通过可区分的解释性程序,从输入-输出的例子中归纳源代码。后来这种方法被证明性能上存在缺陷,不如编程语言社区使用的基于离散搜索的技术效果好。另外一项工作是 DeepCoder,该系统试图通过统计预测的手段来增强传统搜索技术生成代码的不足,但是它有一个问题是对复杂编程语言建模的能力会受到其对特定领域依赖的限制。
目前,从图形界面生成代码的任务中,pix2code 是相对而言做的比较好的一个,其利用反馈机制,在解码阶段,使用两个分层的 LSTM。但是,该方法存在一个缺陷在 LSTM 处理长距离依赖的过程中,需要限制输入序列的长度,这个影响到可扩展性和泛化能力;另外一个缺陷是没有考虑到图形界面的层次结构,这样就限制了它在生成精确图形方面的表现。
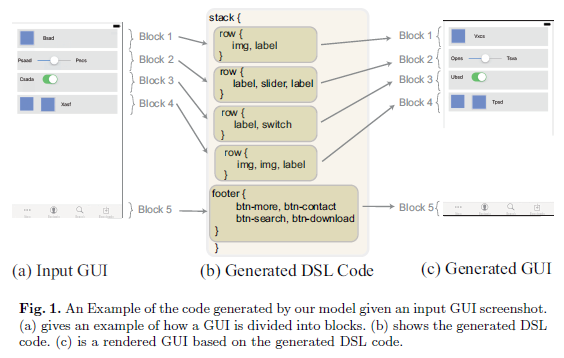
针对以上问题,本论文提出了一种全新的自动生成图形界面代码的方法。它不仅能很好地解决长距离依赖问题,而且还可以通过显式地表示分层的代码生成过程,来捕获代码的分层结构。该方法使用分层的解码器对代码序列进行推理,逐块生成图形界面的代码。这个方法已经在基准测试集上证明是有效的,并且效果非常好。其中,基准数据集涉及到 iOS、Android 和 Web 平台。此外,为了进一步证明该模型在处理复杂的图形界面生成代码问题上的优势,作者还创建了新的包含元素多样性、风格多样性、空间布局多样性的 GUI 屏幕截图数据集,测试结果表现大大优于以往的几种方法。下图 1 是使用本论文方法生成 GUI 代码的过程:
研究背景
自动生成 GUI 屏幕截图的代码任务和图像生成文字字幕的任务非常类似,都是首先理解图像的可视化内容,然后将它们解释为语言形式。这些任务都遵循 encoder-decoder 加 attention 机制的框架,由于 encoder 和 decoder 阶段会涉及到 RNN 神经网络结构,所以会存在长距离依赖问题,这个问题导致无法生成很长的图像描述。
在图像生成文字字幕的任务中,Jonathan 等人利用层次结构的 LSTM 解决长序列依赖问题,他们的模型可以生成段落级别的图像描述。在他们的工作中,使用了两个分层的基于 LSTM 网络的语言解码器:第一个阶段的 LSTM 网络捕获图像的一般信息,并将每个句子的上下文信息存储到隐含状态中;第二个阶段的 LSTM 网络结构用来解码第一个阶段 LSTM 存储在隐含状态的信息,在段落级别产生不同的句子。本文借鉴这一思想,并做了一些改进,提出了用于 GUI 代码自动生成任务的新方法。该方法第一阶段的 LSTM 网络的隐含状态仅仅用于 attention 网络中,主要是来帮助选择 CNN 网络提取特征,然后将结果输入第二个阶段的 LSTM 网络用来生成 GUI 代码。
本论文的主要贡献如下:
(1)首次提出利用层次化的方法从用户界面生成代码程序;
(2)提出了一种将注意力机制(attention mechanism)与层次的 LSTM 相结合的新方法,性能表现优于目前使用层次 LSTM 的其他方法。
(3)介绍了一种新的数据集 PixCo-e,其中包含了三个平台的 GUI 代码示例: iOS、Android 和 Web。
技术原理
1.整体架构
下面先整体介绍一下该模型自动生成图形界面代码的架构图,如下:
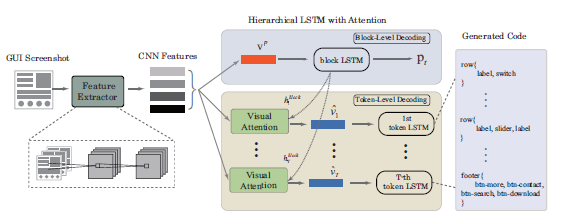
首先,输入的 GUI 截图给到卷积神经网络(CNN)中以便获取高级视觉特征。然后,将所有高级视觉特征投射到 D 维空间,合并到一起生成一个 v 向量,其中 v 向量表征图像的紧密特征;接着将其输入到 block LSTM 结构中生成 h 隐含状态向量和 p 分布,p 分布用于确定生成界面图形块的数目,h 隐含状态向量指导学习图形块结构中的代码逻辑。CNN 抽取的高级视觉特征结合 h 隐含状态向量,经过多层感知机网络和 softmax 函数等处理后,生成一个新的向量 v(^),然后输入 token LSTM 的结构中,token LSTM 解码生成图形界面的第 t 个块代码,最后将所有 token LSTM 生成的代码块拼接产生整个 GUI 的代码程序。
2.视觉编码器:卷积特征
利用卷积神经网络(CNN)作为图像的编码器,抽取图像特征向量 v 的集合 V,其中 v 是一个 D 维的向量,表征图像某部分的特征。
Region Pooling:将所有的图像特征 v,聚合到一个向量 v§中,以表示紧密的图像特征信息,并且作为上下文输入到 block LSTM 结构中。其中,聚合向量 v§是通过求每个 channel 的 v(p)和 v(i)逐元素求得最大值计算得来的。
3.基于注意力的分层解码器
将提取的视觉特征输入到层次视觉解码器模型中,该模型由两个模块组成:一个是 block LSTM,另外一个是 token LSTM。block LSTM 负责确定整个程序的总块数,并且为每个块生成一个 H 维的指导向量。token LSTM 利用指导向量结合 CNN 提取的基础图像特征,抽取每个块中最重要的图像特征,作为每一步输入的上下文信息,来指导生成每个块的代码结构。
Block LSTM
block LSTM 由一个 LSTM 构成,隐含状态的大小为 512,初始的 hidden 状态和 cell 状态都设置为 0,开始 block LSTM 会将聚合特征的向量 v§作为初始输入,然后会产生一系列的隐含状态,分别对应不同的代码块结构。隐含状态在整个过程中有两个作用:一个是决定代码块是否是整个程序的最后一块;另外一个是作为 attention 网络的输入,来指导 CNN 网络抽取跟块相关的更精确的特征。
Token LSTM
token LSTM 由两层 LSTM 构成,隐含状态的大小 512,图像特征 v 向量作为 token LSTM 的初始输入,然后来生成代码块。其中,图像特征 v 向量是由 CNN 产生高级特征,然后结合 block LSTM 输出的隐含状态,输入多层感知机网络,经过 softmax 函数处理输出 attention 网络的权重,再与 CNN 抽取的特征求和而得到。
第二个 LSTM 网络的隐含状态,用来预测 token 在词表中的分布,特殊的“END”字符是一个块解码结束的信号。经过 token LSTM 的处理,产生 GUI 相应的各个块的代码,然后拼接到一起就是整个 GUI 的代码程序了。
4.训练
训练数据集由(x,y)组成,其中 x 代表输入的 GUI 屏幕截屏,y 代表 GUI 的代码。之前研究者的方法是在每一次迭代训练中,利用固定大小的切片窗口获取一个切片代码块,然后输入到 LSTM 编码器中。而本论文新提出的方法是,一次性将全部的代码输入给模型。遵循 DSL 原则,在训练过程中,我们使用统一的规则来切分代码块,按 stack 模块来解析处理,“{”代表代码块的开始,“}”代表代码块的结束,并且手工插入一些代码块结束的标识符号。
代码程序经过切分处理后,假设程序包含 S 个块,第 i 个块有 N(i)个 tokens,y(i,j)是第 i 个块的第 j 个 token 的分布。p(i)是每一个块的状态,其中 0 代表继续,1 代表结束。q(i,j)是 block LSTM 产生的隐含状态输入 token LSTM 的一个副本后,为每个 token 产生的一个分布。g(i)是第 i 个块的隐含状态的分布,其中 0 代表继续,1 代表结束。训练的损失函数由 block LSTM 的损失函数和 token LSTM 的损失函数的交叉熵求和而得,下面是损失函数的公式:
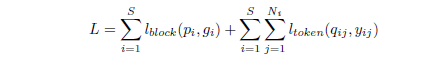
实验评测结果
在两个数据集上,都实现了本文提出的自动生成图形界面代码的模型。第一个是公开的数据集 PixCo,其中包含 iOS、Android 和 Web 三个子数据集,每个子数据集包含 1500 个 GUI-code 对的训练数据,250 个 GUI-code 对的测试集。第二个是我们自己收集的实际场景下的数据集 PixCo-e,创建第二个数据集的原因是,第一个数据集相对简单,而真实的 GUI 包含多个图形元素,视觉布局也相对复杂。类似第一个数据集,第二个数据集也分 iOS、Android 和 Web 三个子数据集。其中,训练数据有 3000 对,测试数据有 500 对,样本量也有扩大。
一些实现上的小细节:我们重新设置了输入图片的尺寸大小为 256*256 像素,再对像素值做归一化处理。编码阶段同样使用基于 CNN 网络结构的编码器,使用三个卷积层,宽度分别为:32,64,和 128,和两个全连接网络。解码阶段,block LSTM 和 token LSTM 的输入维度都设置为 512,并且使用 sigmoid 作为非线性激活函数。此外,因为 token 词表比较小,所以使用 one-hot 编码后的 token-level 的语言模型。在训练过程中,使用 Adam 优化算法进行优化,mini-batch 大小设置为 128,learning rate 大小设置为 0.001,dropout rate 大小设置为 0.5。
整个训练过程使用 NVIDIA TITAN X GPU,PixCo 数据集花费大约 3 个小时,我们自己的数据集 PixCo-e 大约花费 6 个小时。
定量的实验效果
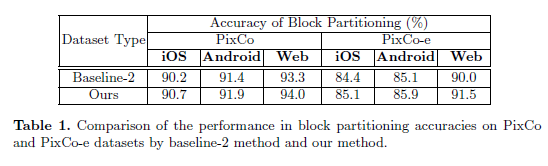
表 1 是基于分层的 LSTM 架构的基准测试结果。
Baseline-2 和本论文提出的模型不同的点是它的模型在第一阶段 LSTM 隐状态在每一步直接输入到第二阶段的 LSTM 作为上下文,而没有其他指导信息输入。
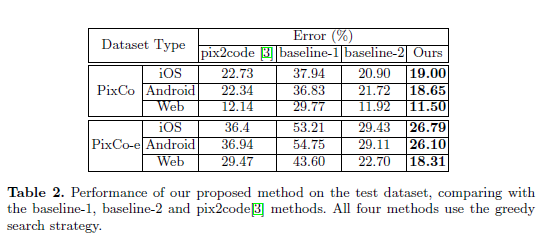
表 2 对比了在 PixCo 和 PixCo-e 数据集上 baseline-1、baseline-2、pix2code 和本论文提出的模型效果,生成代码的质量效果通过计算每个样本 token 的分类错误率来评估。
可以看到,在 PixCo 的三个子数据集上,本论文的模型明显优于 pix2code。从分类错误率看,在 iOS 和 Android 平台上,其拥有比 Web 平台长的代码长度,所以更能说明本论文的模型在处理复杂 GUI 布局和长序列依赖上表现要更好。baseline-2 也是基于分层的 LSTM 结构,但是跟本论文的模型比较,在两个数据集和三个平台上,效果都不如本论文的模型。这进一步说明,同样使用 CNN 网络,添加 attention 机制后,可以提升层次 LSTM 模型生成代码的质量。
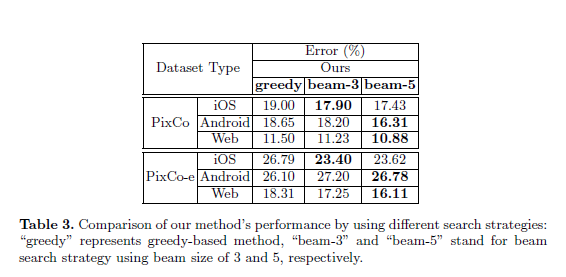
表 3 对比了本论文的模型使用不同搜索策略的效果。
从实验效果看,使用 beam 策略搜索效果会更好。实验分别对比了 beam 的大小设置为 3 和 5 的效果,当 beam 的大小为 5 时效果更佳。
定性的实验效果

图 4 展示了生成图形界面代码过程中的 attention 动态处理过程。模型能够学习 GUI 屏幕截图中的代码块和其对应的空间区域之间的正确对齐。


图 5 和图 6 展示了 iOS 和 Web 端的例子。在 PixCo 数据集上,尽管偶尔会出现一些图形元素错位和样式错误的情况,但是 pix2code 和本论文提出的模型输出的结果都非常接近真实情况。这证明了两个模型在学习简单的 GUI 布局上都是可行的。然而,在 GUI 变得更加复杂的 PixCo-e 数据集上,我们观察到,由 pix2code 生成的 GUI 质量急剧下降,并且明显低于本论文提出的模型。
未来展望
本文提出了一种新型的自动生成 GUI 代码的方法,该方法在基准数据集和自己创建的数据集上都表现出非常好的效果。本文提出的模型使用了层次结构的解码器,并且添加了 attention 机制,这样可以更好地捕获 GUI 和代码的分层布局。实验结果证明解决长距离依赖非常有效,能够为复杂的 GUI 布局精确地生成高质量代码。研究团队接下来计划尝试新的方法,用于识别和分开重叠的图形元素,并生成正确的代码描述。
论文原文链接:
https://arxiv.org/pdf/1810.11536.pdf
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


暂无签名

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论 6 条评论