

近年来,大数据和深度学习技术的发展极大地推动了人机对话系统的进步,使其成为少数能够大规模商业化应用的人工智能技术之一。从 2014 年开始,达摩院 Conversational AI 团队专注于人机对话的创新研究和大规模应用,打造了面向第三方开发者的智能对话开发平台 Dialog Studio,以及 KBQA、TableQA、FAQs 等智能问答技术,并在 ACL、EMNLP、AAAI、IJCAI 等顶会发表多篇论文。相关技术通过阿里云智能客服 ( 即云小蜜 ) 产品矩阵已广泛服务于政务、银行、保险、医疗、运营商等行业,如智能 IVR 机器人为中国移动 10086 自动接听电话量达到 1.5 亿通/年,更在 2020 年新冠疫情爆发初期,打造了全国最大的疫情外呼机器人平台,帮助 27 个省拨打了 1800 多万通电话,协助政府工作人员进行疫情的摸排防控,获得人民网“人民战疫”一等奖。
本文将对达摩院 Conversational AI 的研究进展及应用做系统介绍:
达摩院 Conversational AI 的研究进展
对话式 AI 在阿里云智能客服的大规模应用
达摩院 Conversational AI 的研究进展
达摩院 Conversational AI 的整体架构如下图所示:
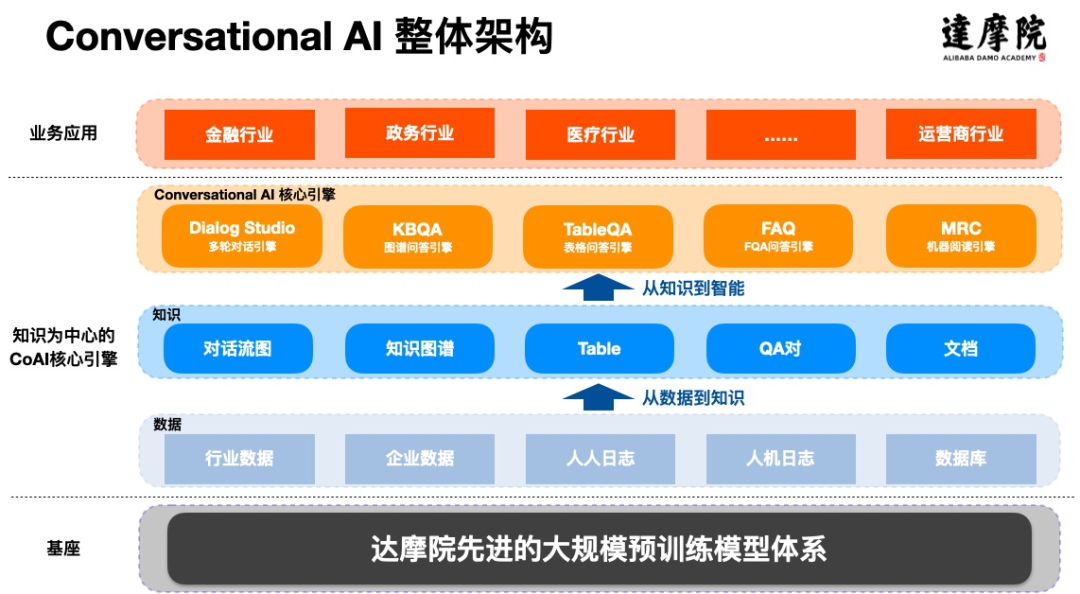
其中,以完成某个任务为目标的多轮对话是各行各业应用最广泛的对话形式,以二维表格 ( 含 SQL 数据库 ) 为载体的知识是各行各业最广泛存在的结构化知识形态,今天重点围绕任务型对话引擎 Dialog Studio 和表格型问答引擎 TableQA 的核心技术研究进行介绍:
语言理解:如何系统解决低资源问题
对话管理:如何从状态机到深度模型
TableQA:Conversational Semantic Parsing 的难点和进展
在将 Dialog Studio 大量落地应用于各个行业领域的过程中,从算法的角度来讲,主要面临着两个挑战:第一个是在涉及多行业、场景分散的 toB 业务中,怎么能解决低资源小样本下的语言理解问题;第二个是如何把多轮对话管理(Dialog Management)从业界普遍的状态机推进到深度学习模型,让多轮对话具备持续学习的能力。
1. 语言理解:系统解决低资源问题
① 低资源小样本问题
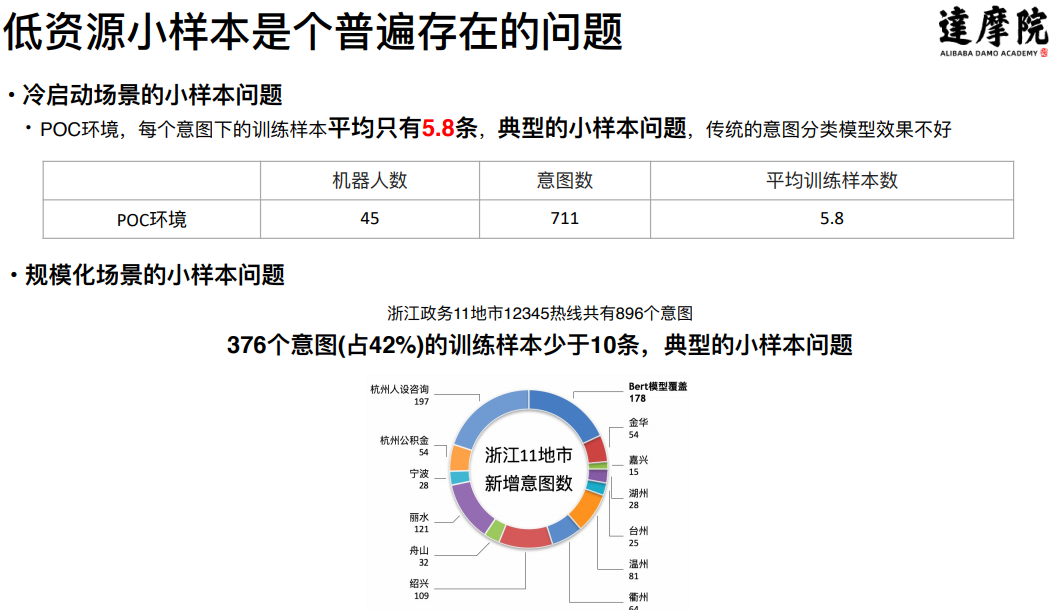
低资源小样本是普遍存在的问题,比如在冷启动的场景下,统计 45 个 POC 机器人的数据,平均每个意图下的训练样本不到 6 条,是一个典型的小样本学习问题。在脱离了冷启动阶段进入规模化阶段之后,小样本问题依然存在,比如对浙江省 11 个地市的 12345 热线机器人数据进行分析,在将近 900 个意图中,有 42%的中长尾意图的训练样本少于 10 条,这仍然是一个典型的小样本学习问题。
如何解决小样本问题,对学术研究以及业务上的大规模推广应用来讲都是重要的研究方向。
② 解决方案
引入 Few-shot Learning 系统解决小样本问题
在 2018 年初,达摩院 Conversational AI 团队就开始思考怎么解决这类问题,经过大量的调研,最终的选型是通过引入 Few-shot Learning(小样本学习)来解决小样本下的语言理解问题。Few-shot Learning 本质上是一种元学习(Meta Learning)或者说是迁移学习(Transfer Learning),希望模型能够学会如何去学习(Learning to learn)。
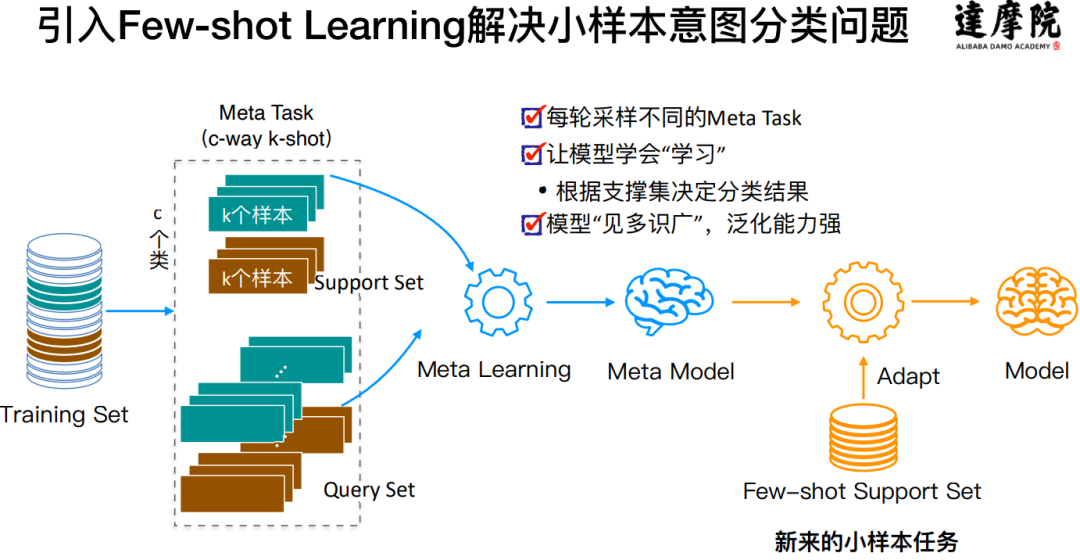
Few-shot Learning 的训练和应用大概如下:
从大规模的训练数据集中采样抽取一个子集来模拟真实的小样本数据:比如每轮从训练数据集中抽取 10(c-way, c=10)个意图,每个意图抽取 10(k-shot, k=10)个样本;
基于抽取的子数据集进行学习来训练 Meta Model;
重复前两步,这样经过多轮的训练之后,Meta Model 就“见多识广”,具备了一定的学习能力和泛化能力;
应用的时候用真实的小样本数据对 Meta Model 进行适配来得到当前业务的模型。
2018 年初,Few-shot Learning 的研究主要集中在图像领域,在 NLP 领域尤其是人机对话领域的研究还很少。经过调研,达摩院 Conversational AI 团队提出了一个 Encoder-Induction-Relation 的三层 Few-shot learning Framework:
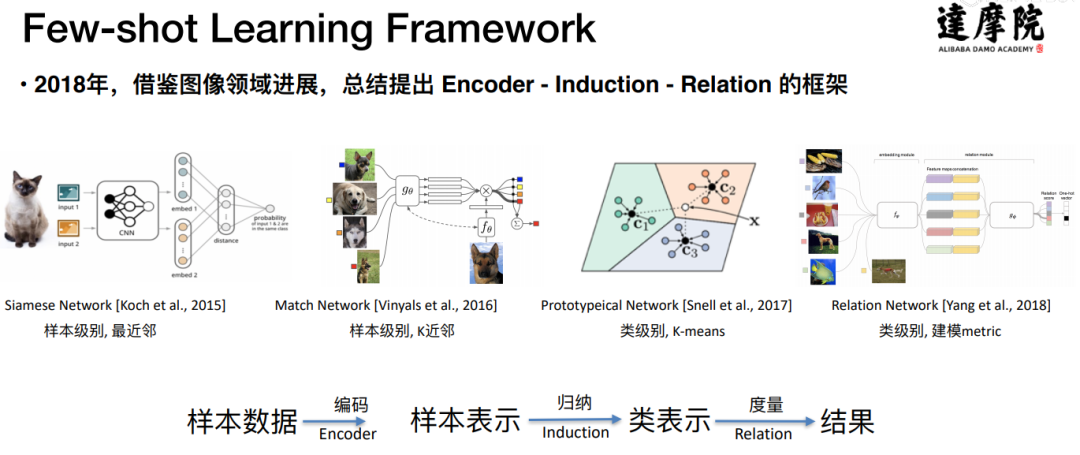
首先,小样本数据经过一个 Encoder 编码层来得到每一个样本的向量表示;然后第二层的归纳层再把样本表示归纳为类别表示;第三层的度量,或者叫关系层,就是在新来一个样本之后,通过计算新样本与每一个类别中心的距离来判断新的样本属于哪个类别。
基于这个框架,达摩院启动了自己的研究。无论是小孩子还是大人,从小样本中进行学习的时候,主要依靠的是两种强大的能力,归纳能力和记忆能力。归纳能力是指在学习一个问题的时候,只要见过几次,就可以根据几个样本归纳出公共的内容出来,以后再见到类似事情的时候,可以通过归纳出来的公共内容来进行处理;记忆能力就是把见过的东西都记下来,在遇到问题的时候就可以从记忆库里面搜索利用相关的记忆。人在解决问题时候的这两种典型思想,就是达摩院研究的出发点。
Induction Network (EMNLP2019)
首先是在归纳方面的研究探索:
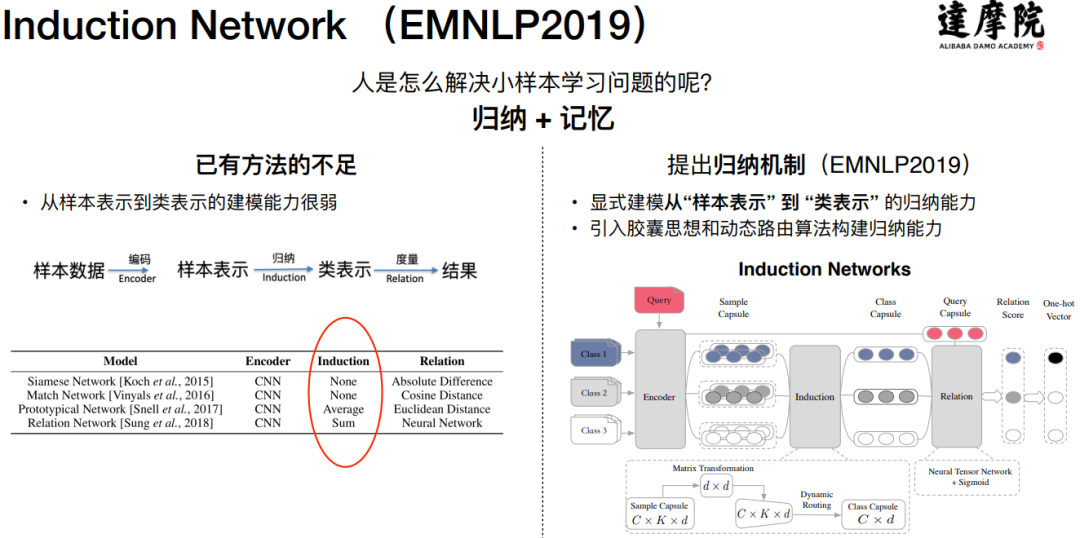
已有方法的不足:
要么是没有归纳这一层
要么是把 encoder 层得到的样本向量做简单的加和或者求平均
基于这个现状,达摩院在 2019 年提出了 Induction Network 的归纳机制,该工作发表于 EMNLP2019,主要有两个贡献点:
把从“样本表示”到“类表示”的归纳能力进行了显式的建模;
引入胶囊思想和动态路由算法来构建归纳能力;
下面重点解释一下动态路由是如何实现归纳能力的:
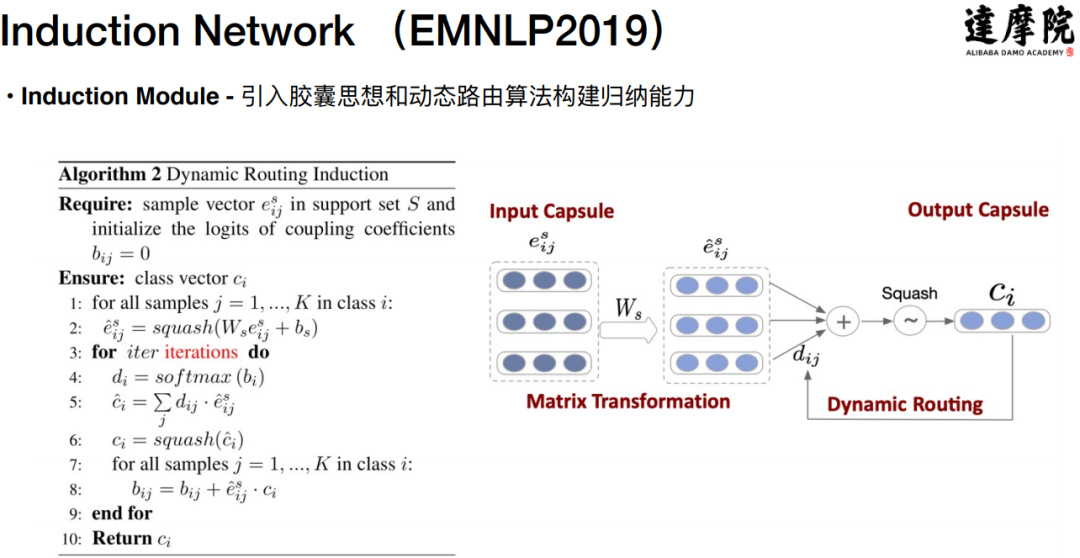
目标:根据样本向量,得到一个类别向量,即类中心。
动态路由思想:不是通过一次计算就得到类中心的表示向量,而是通过迭代的思想来进行学习。
步骤:先初始化参数,通过初始化的参数来计算得到一个初步的类别向量;再通过计算当前类别向量与样本向量的距离来更新整个参数;根据更新之后的参数可以重新计算得到新的类别向量;如此迭代即可得到最终的比较合理的类别向量。
优点:权重参数是通过迭代优化得到的,对样本向量有更好的感知(即更好的表达能力)。
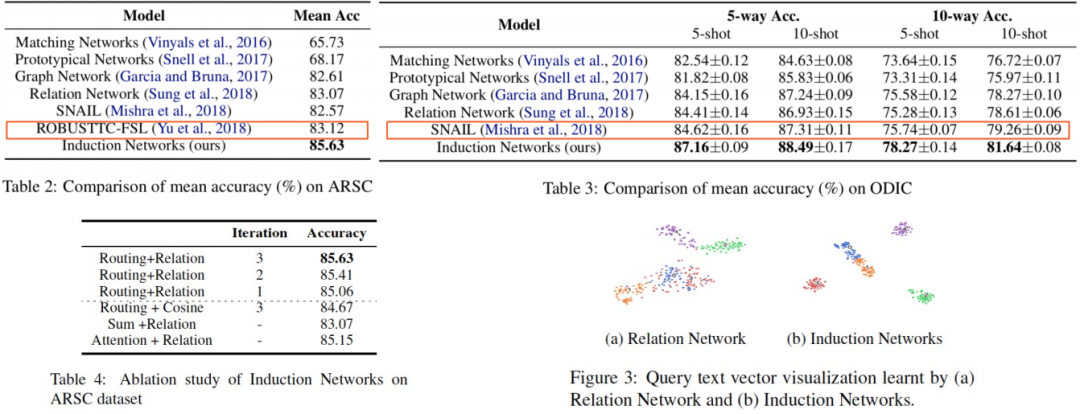
表现效果上,Induction Network 在英文公开数据集和中文意图分类数据集上都取得了 SOTA 的结果,超过了之前最好的模型(红框中是之前最好的模型):
Dynamic Memory Induction Networks (ACL2020)
其次是在记忆方面的研究:
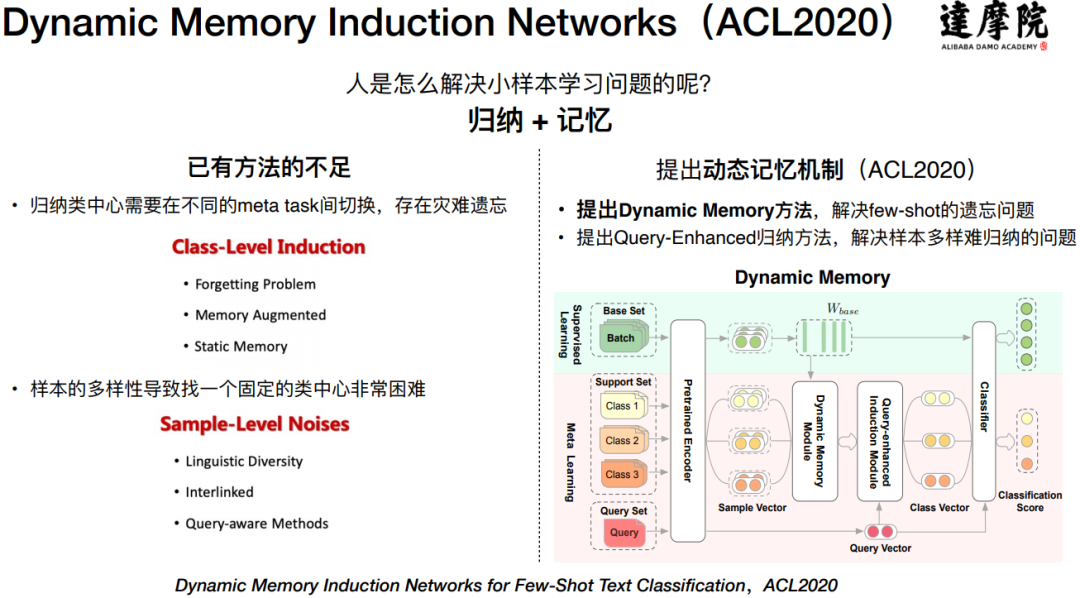
已有方法的不足:
Meta Learning 的学习机制本身存在问题:在进行多轮的抽样训练过程中,学习新的 Meta Task 会遗忘之前的 Meta Task 学习到的内容。
样本多样性的问题:样本的多样化导致同一个类别的样本难以只用一个类中心去表示。
基于以上不足,达摩院提出了 Dynamic Memory Induction Networks 的动态记忆机制(发表于 ACL2020):
提出 Dynamic Memory 方法,解决 Meta Learning 时的遗忘问题。
提出 Query-Enhanced 归纳方法,解决由于样本多样而难归纳的问题。
动态记忆机制将训练过程分为两个阶段:
第一阶段:利用监督学习的方法从大的训练集中学习出每一个类的代表性表示,将这种代表性表示放置在 memory 中;
第二阶段:进行 Meta Learning 的训练学习,每一个样本向量都会去读一次 memory,这样就把意识记忆融合进来了,而且读取的时候会引入动态路由的方法进行迭代计算;
同时,为了应对样本多样化问题,达摩院引入了 Query-Enhanced 的方法,将用户的 query 加入到训练过程中,希望找到数据集中哪些样本是与当前的用户 query 相关的,那么就只把这一簇样本拿出来与 query 一起进行处理。
效果方面,Dynamic Memory Induction Networks 也在英文数据集和中文意图数据集上取得了不错的表现:
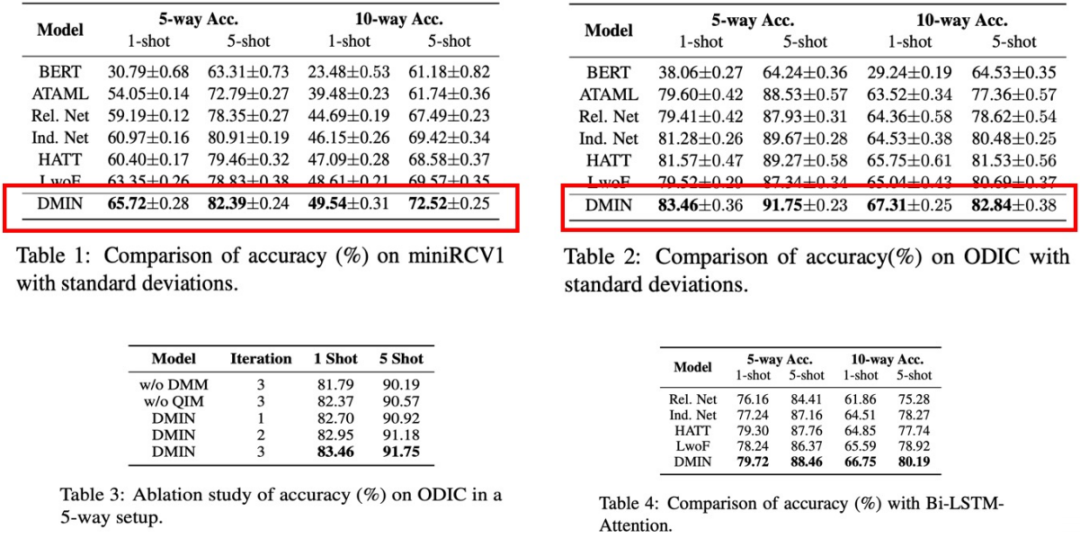
小结
Few-shot Learning 是达摩院整个 Conversational AI 中的一个基础算法,在所有的场景里面应用落地。这个方法有两个非常大的优势:
这是一个即插即用的算法:在应用的时候不需要训练,可以灵活地增添新的数据,这对 toB 场景非常友好;
本质是一个迁移学习:迁移学习的方式能够最大化平台方积累数据的优势。
2. 对话管理:从状态机到深度模型
在这一部分达摩院要解决的问题是,把对话管理从状态机推到深度模型,让对话管理具备学习能力。
① 基于状态机的对话管理面临的问题

基于状态机的对话管理主要面临两个问题:
第一个问题是,通过配置的方法,永远无法把整个对话流配置完备,总会有漏掉的配置;
第二个问题是,基于状态机的对话管理,本质上仍是一个规则化的对话引擎,即使积累再多的日志和数据,也没有办法具备学习能力。
基于以上两点,把对话管理从状态机推到深度模型,就是一条必然的路径,但是目前学术界尤其是工业界还没有解决这个问题,这个问题的核心难点是多轮对话数据获取难、标注难。
② 解决方案
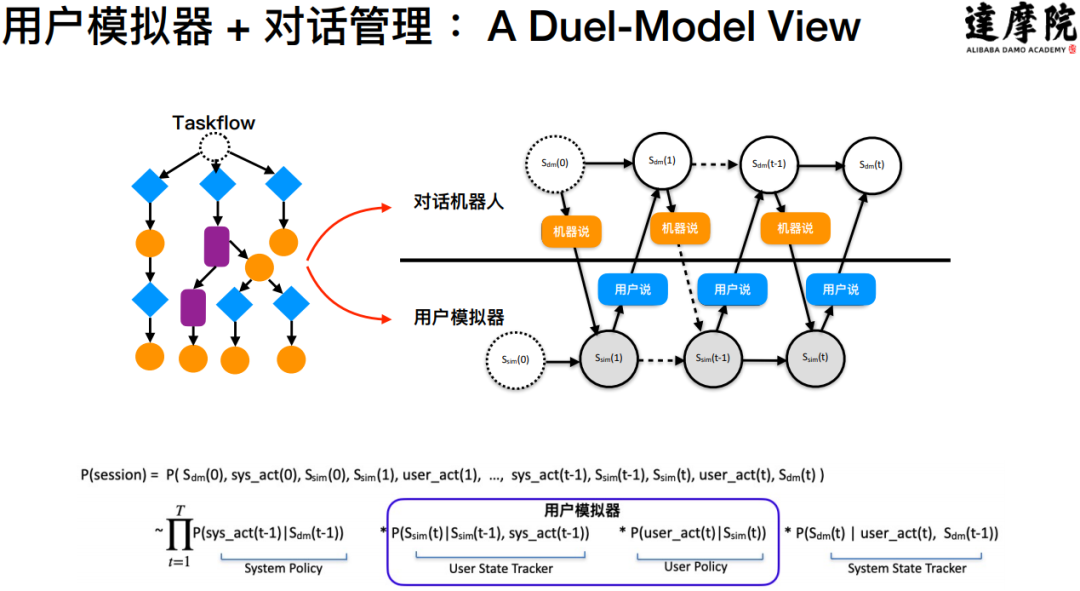
达摩院引入了用户模拟器,把用户模拟器和对话系统结合在一起,通过两者之间的 Self-Play 产生海量的标注数据来解决数据难题。在用户模拟器和对话系统的对偶模型中有两个模块:
对话机器人:每一轮中说机器应该说的那句话
用户模拟器:模拟用户这个角色应该说的话
这样就形成了机器和用户之间的对话过程,产生大量的对话数据,而这些数据最大的优势就是:这些数据是带有标签的。
基于以上的基础建模,达摩院实现了对话管理的深度学习模型化,并且在业务场景中进行了大规模的落地应用:
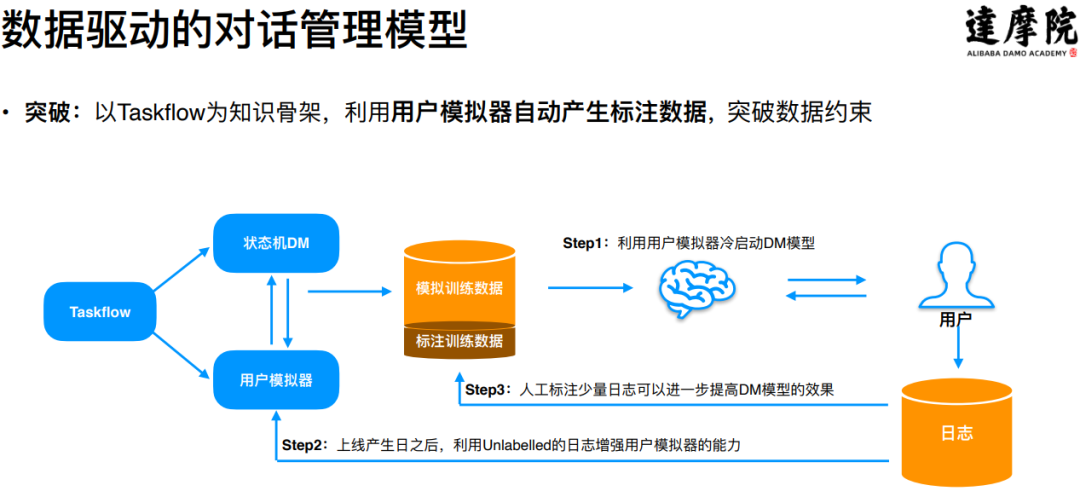
整个过程分为以下三部分:
Step1:利用用户模拟器冷启动对话管理模型,产生大量的模拟训练数据,通过模拟训练数据即可对模型进行训练,得到可直接上线的模型;
Step2:模型上线之后会产生日志数据,可以利用这些日志数据来进行数据增强,通过模拟器的迭代来提升模型的效果;
Step3:对于产生的日志数据,也可以通过人力适量标注一部分来进一步提升模型的效果;
通过引入用户模拟机器,解决了对话管理的深度学习模型化问题。
③ 对话管理模型的迁移学习
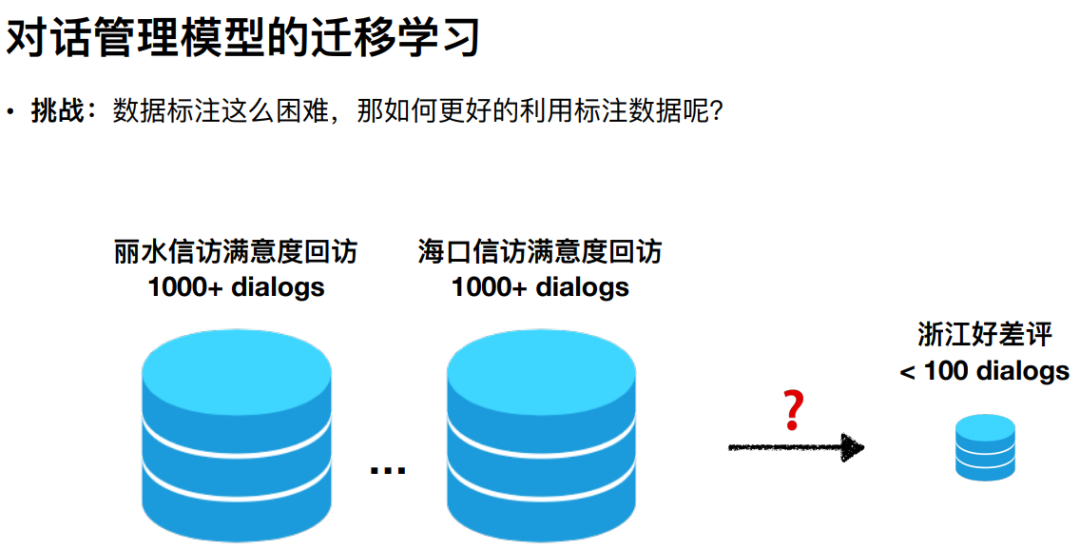
在实际应用的时候还遇到了新的问题:当我们有了一些场景的标注数据以及训练好的模型之后,在面对新的应用场景时,如何将已有的数据和模型复用起来。
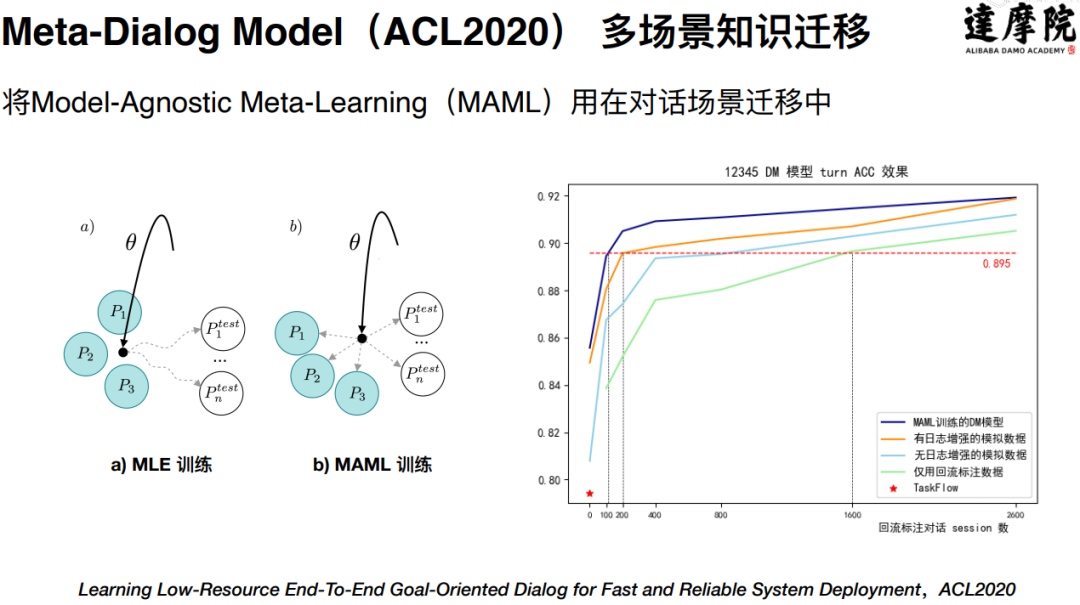
针对这一新的问题,达摩院考虑使用迁移学习的方法来进行解决。为此对迁移学习在这方面的应用做了一定的研究,最终提出了一个 Meta-Dialog Model,对应的工作发表在 ACL2020 上。主要思想是将 MAML(Model-Agnostic Meta-Learning)这种迁移学习的思路引入进来:在已有数据的前提下,利用 MAML 迁移学习的方法训练出一个比较好的元模型(Meta Model), 当有新的场景时,可以用元模型的参数来进行初始化,这可以使得新场景下的模型有更好的初始化参数和训练起点。基于这种方法,在政务 12345 热线上进行了实验,得到了 4 个点的提升。
3. TableQA:Conversational Semantic Parsing 的难点和进展
① TableQA 介绍

这里通过一个例子来介绍 TableQA。首先有一个理财产品的 Table,围绕这个 Table, 用户可能会问:“收益率大于 3.5%且保本型的理财产品最低起投金额是多少?”,要想解决这个问题,需要先把自然语言转换成一个 SQL 语句,然后用 SQL 语句去查询表格,最终就可以回答这个问题。所以整个 TableQA 的核心问题就是如何解析自然语言:把 TEXT 文本转变为一个 SQL 语句。
TableQA 的优势主要有以下三点:
表格容易获取:企业中存在大量现成的表格,无需加工即可自然获取;
使用门槛低:针对 TableQA 达摩院已经研究了多种算法,大大降低了企业应用的成本和门槛;
功能强大:支持复杂语言的理解、支持多表查询、支持多轮问答。
② TableQA 发展
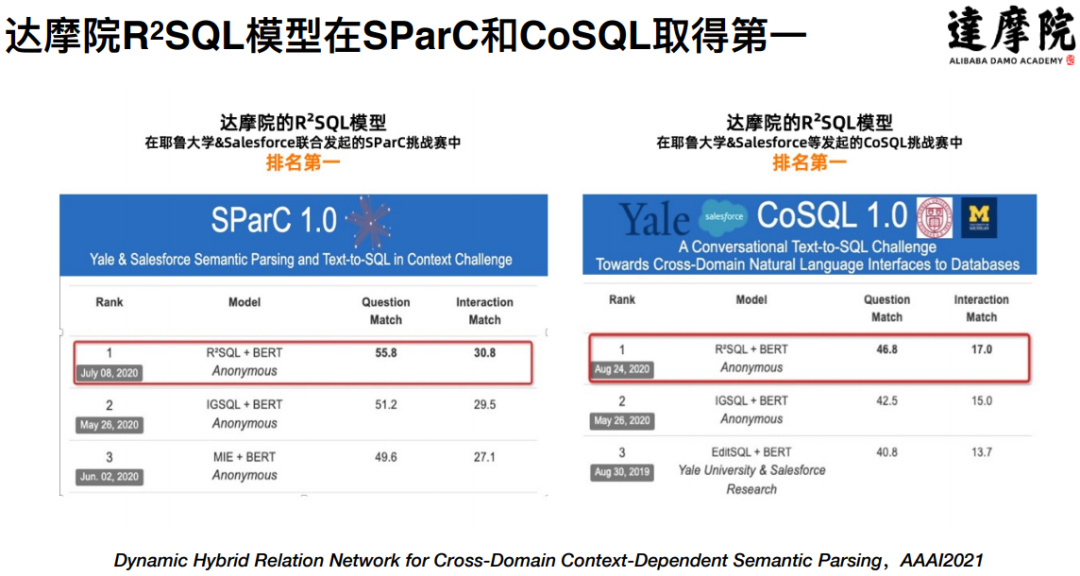
TableQA 是最近两年里发展最快的一种问答方式。从 2017 年开始重新被发掘出来,2019 年的时候这个方向的研究开始加速,达摩院也是在 2019 年启动了对 TableQA 的研究。2020 年加速趋势更加明显,达摩院提出的 SDSQL 模型在 WikiSQL 上取得了第一名,提出的 R2SQL 模型在国际公开挑战赛 SParC 和 CoSQL 上都取得了第一名的好成绩。
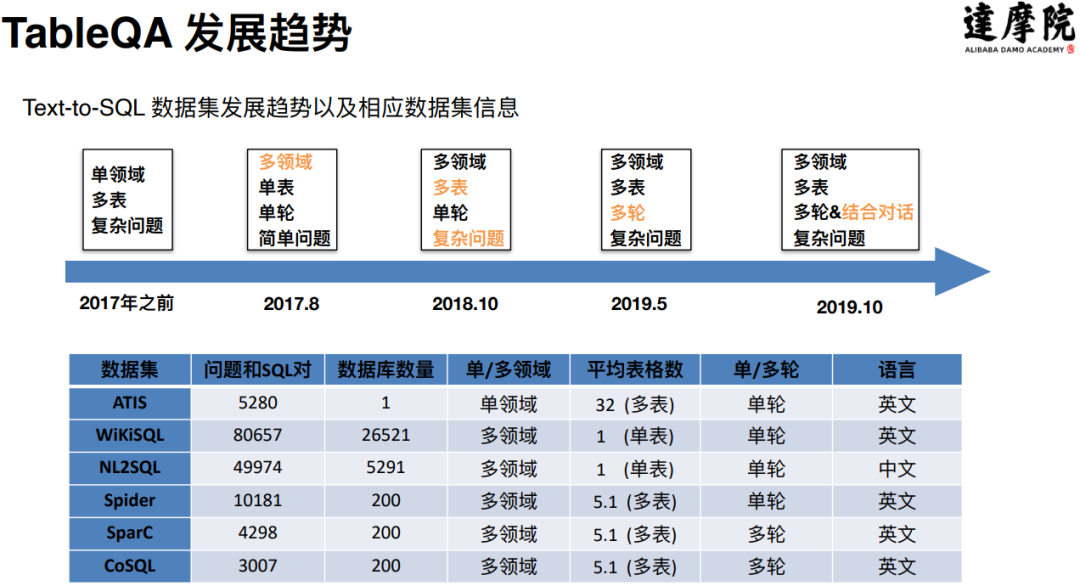
上图是 TableQA 整个方向上的发展脉络,图中列出了一些比较典型的数据集,这里面有四个数据集是值得大家去关注的:一个是 WikiSQL 数据集,这是一个单表单轮的数据集;第二个是多表单轮的 Spider 数据集;第三个是多表多轮的 SparC 数据集;第四个是 CoSQL 数据集,这是一个融合了多轮对话特点的多表多轮数据集。
接下来介绍达摩院在 SParC 以及 CoSQL 数据集上的研究进展。
③ 达摩院在 TableQA 上的研究
达摩院在 TableQA 上的研究主要是基于多表多轮的数据集(SparC 和 CoSQL), 多表指的是寻找答案的时候需要在多个表中进行查询,而不是仅仅靠一张表就能得到答案;多轮指的是用户通常会连续不断的提问。
其中,在 SparC 数据集上主要有两个挑战:

第一个挑战是用户表达的自然语言和 SQL 语言之间的 linking 问题,也即用户的问题和表格的 Schema 之间的 link 问题。以“对于那种有四缸的汽车,哪一款车拥有最大的马力?”这个问题为例:
需要将问题链接到相应的表(table):知道去哪些表中去寻找答案,在例子的问题中就是需要把与“车”相关的表找出来。
需要找出表中与问题对应的列(column):例子中需要找出与“缸数”以及“马力”相对应的列。
将用户的自然语言与表格的 Schema 之间进行 link 是非常困难的事情,通过对 SparC 数据集中 BadCase 数据的统计发现,有 84%的错误情况都是由 link 的错误引起的。

第二个挑战就是对上下文进行建模。这个问题主要是出现在多轮的情况下,一方面多轮的时候会出现指代、省略等问题,需要通过对上下文建模来解决;另一方面多轮的情况下上下文的意图切换比较困难,所以就存在如何动态建模 linking 的问题。
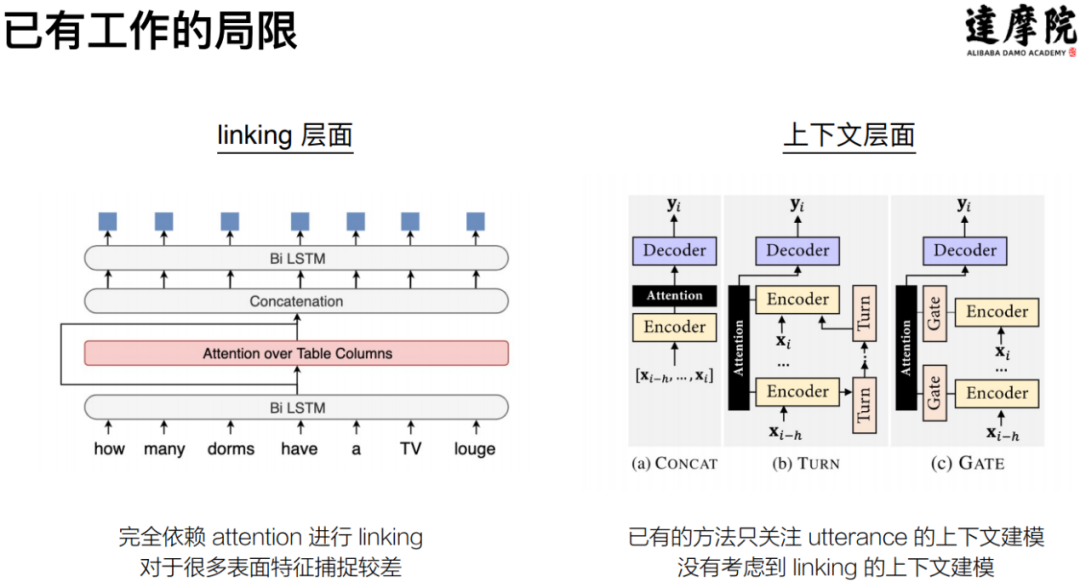
对于以上的两个挑战,已有的研究存在的不足主要是:
linking 层面:依赖隐式 attention 对 linking 建模,对于显式的特征捕捉较差;
上下文层面:针对句子文本层面进行了建模,没有对 linking 进行上下文建模。
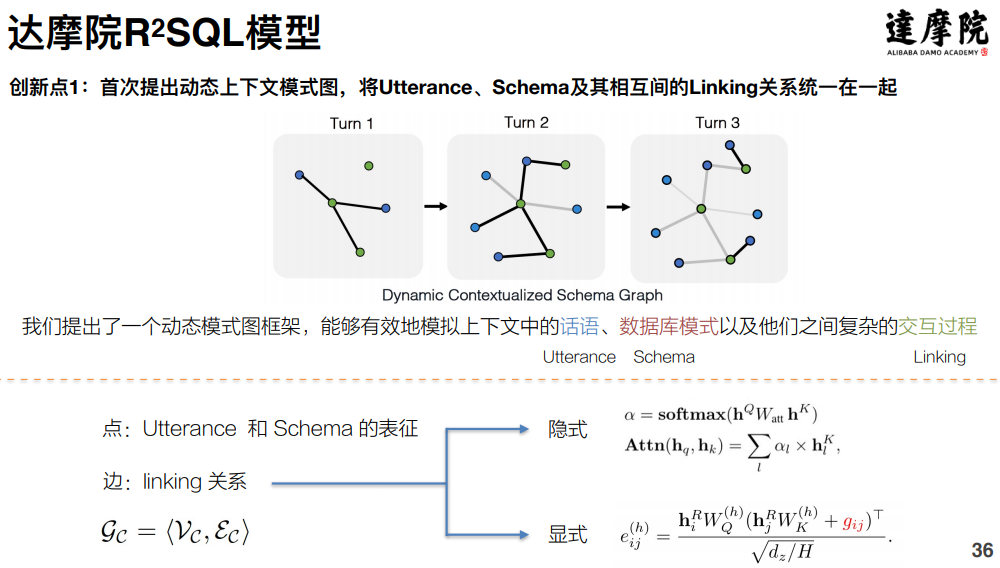
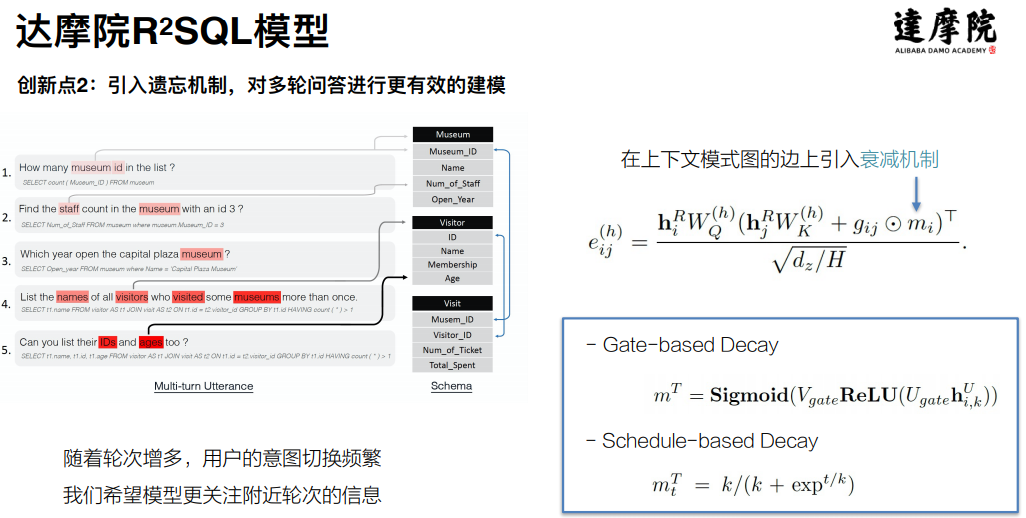
针对面临的挑战以及已有研究的不足,达摩院提出了 R2SQL 模型,该模型的创新点主要有:
首次提出动态上下文模式图的概念:将用户的话语、table 的 Schema 以及两者之间的 linking 关系统一地在一张图中进行建模,让 linking 学习地更加充分;
其次是引入了遗忘机制:在多轮的对话中,在用户的意图进行切换的过程中,使用衰减机制来降低之前 schema 的权重,从而更关注当前的 schema。
在效果层面上,R2SQL 在 SparC 以及 CoSQL 两个榜单上都取得了第一名,相关文章已经被 AAAI2021 录用:
对话式 AI 在阿里云智能客服的大规模应用
阿里云智能客服,隶属于达摩院,小蜜家族系列产品重要一员,专注于“服务”和“人工智能”,已经在多个领域进行了落地应用。下面会介绍在三个领域的落地应用:政务领域、金融领域、疫情场景。
1. 政务领域:政务 12345 热线
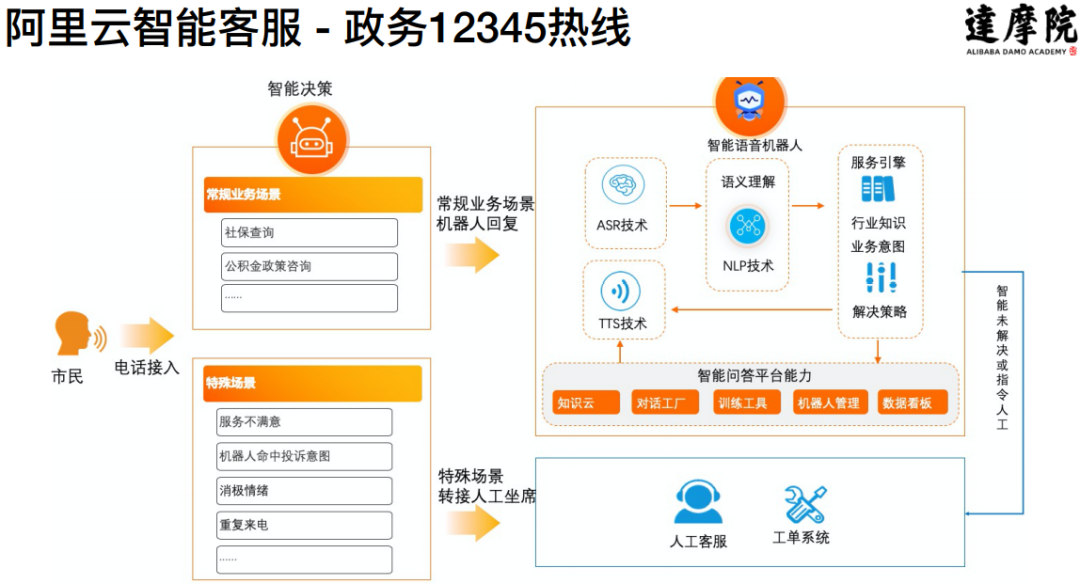
在政务领域,主要是政府的 12345 热线。首先是在浙江省 11 个地市的 12345 热线上进行实践,把背后的人工部分逐步替换成为人工智能的对话机器人。
覆盖场景广泛:覆盖了热线中包括社保查询、ETC、公安(户籍、出入境)、住房保障、公积金全语音门户等 9 大场景;
落地需求多:除了在浙江省树立标杆意外,还在陆续应用于全国的其他城市。
2. 金融领域:在银行和保险上的应用

在银行方面,以催收这样一个典型的场景来讲,客户的信用卡在欠款了之后,银行需询问客户不能还款的原因、什么时候还款等问题,而这一系列流程可以通过智能外呼机器人去完成,实践显示,使用智能外呼之后整个回款率提升了 25%,端到端的准确率达到了 88%。目前几乎整个催收部门背后的客服全部都用智能机器人,节省了大量的人力。

在保险方面,针对中国人寿的业务,做了一整套的客服体系,这套客服体系应用于 APP、官方微信等多个渠道,整个端到端的准确率达到了 93%左右。在这个过程中,对保险业务的知识体系进行了梳理和升级,将原有的几万甚至数十万的知识点进行分门别类处理,对不同的类别采用不同的处理方式,大大降低了整个知识系统的运营和维护成本。
3. 疫情场景
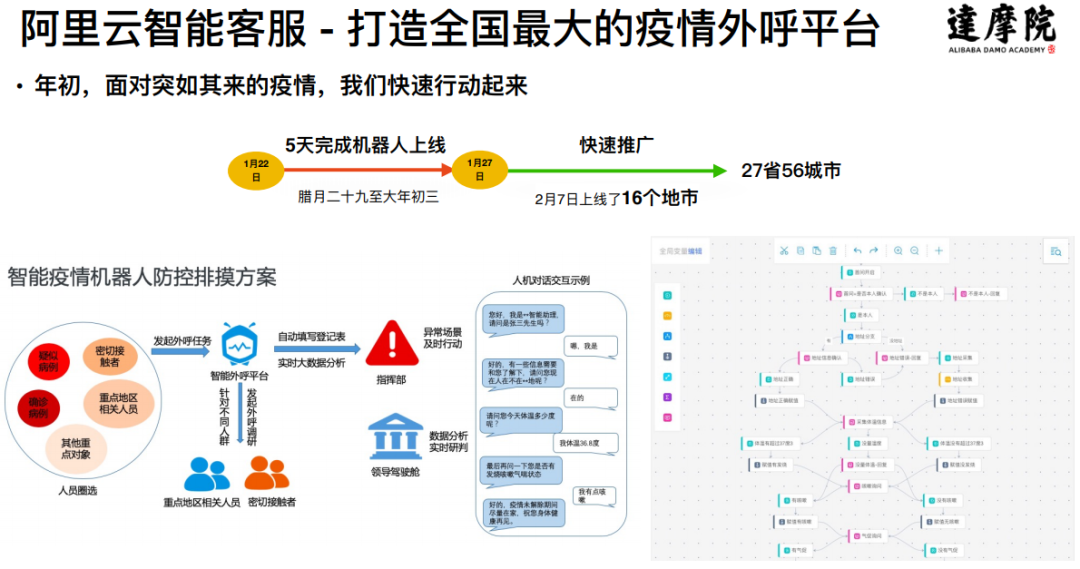
在疫情刚刚爆发的时候,达摩院团队就行动起来,致力于打造一个全国最大的疫情外呼平台,希望通过外呼平台来帮助政府解决一些问题,该平台在五天的内打造完成并开始在全国推广。截止到 2020 年 3 月 31 日,这个平台用在了中国的 27 个省,帮政府拨打了 1800 万的外呼电话,对话完成率超过 90%,获得了人民网的“人民战疫”一等奖。

总结
整个达摩院的 Conversational AI, 凭借过去多年的研究和积累,已经在语言理解,对话管理,小样本学习,迁移学习,以及 TableQA、KBQA 等多个研究领域里面取得了很好的前沿进展。达摩院同时更注重把研究成果应用于阿里云智能客服里面,在政务行业、金融行业、运营商行业等多个行业里进行了大量客户的应用落地,成为中国智能客服市场的领导者。
今天的分享就到这里,谢谢大家。
嘉宾介绍:
李永彬,阿里巴巴达摩院 | 资深算法专家。清华大学自动化系毕业,达摩院 Conversational AI 方向资深算法专家。2014 年研发了阿里巴巴第一个智能助理对话系统,应用于手机、电视、汽车等智能设备;2017 年从 To C 转到 To B,进入智能客服对话领域,打造了面向第三方开发者的智能对话开发平台 Dialog Studio(对话工厂),目前该平台为云小蜜的核心对话引擎,服务于政务(如多省的 12345 热线)、运营商(如移动 10086 热线)、金融(如中国人寿)和大通用(如交通、电力、热力等)等所有行业;此外还为钉钉官方智能工作助理和阿里内部数十个 BU 提供数千个场景的人机对话服务。今年疫情期间基于该平台搭建了全国最大的疫情外呼机器人平台,为全国 24 个省提供 1800 万+通外呼电话服务,荣获人民网“人民战疫”一等奖。近年来带领团队在 ACL、EMNLP、AAAI 等发表多篇论文。
本文转载自:DataFunTalk(ID:dataFunTalk)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论