

背景
2018 年初,知乎 Android 客户端处于组件化中期阶段,组件的拆分和建立正在如火如荼的进行。得益于组件化, java 文件可以提前编译为 class 文件, app 整体的编译时间也得到了一定程度上的提升。然而有一天,主工程的的编译时间突然从 4 分钟猛增到了 10 分钟,对于仍在主工程进行开发的同学来说,这严重影响了开发效率,同时也使得 CI 资源耗费几乎翻番,因此需要排查一下问题到底出在哪里。
定位问题
首先,在编译时添加 --profile 参数,发现增长的部分都在 javac 阶段,对应的 gradle task 为 compile{flavor}{buildType}JavaWithJavac ,而其他编译阶段的耗时基本没有变化,很明显编译 java 文件到 class 的时候出了问题。
由于并不是立即发现问题,并且提交的 MR 众多,不知道立即确定到底是哪里的改动导致的问题,于是祭出二分查找大法,最终找到了编译变慢的那个 commit,然后看代码并没有什么可疑之处,只是简单的将一个组件拆分成了三个组件 —— 组件化拆分时账号组件是第一个拆出来的组件,拆得比较粗糙,连带着不少其他业务代码和基础代码,所以这个 commit 将账号组件拆成了三个组件:页面框架、账号和一个 Common 组件。难道这次拆分的某些改动触发了编译的 bug ?
同时又对比了一下其他各个业务组件的编译时长,发现各个业务组件 javac 的时间也均有不同程度的增长,其中依赖层级越多的组件,编译时间增长越大,时长的增长与依赖层级基本成指数关系。
举例来说,假设有四个组件 ABCD,A 依赖 B、B 依赖 C、C 依赖 D,那么 D 组件编译时长增长了 1 分钟的话,C 组件编译时间增长大约 2 分钟,B 组件大约增长 4 分钟,而 A 则会增长大约 8 分钟了。
对比组件拆分前后的代码,绝大部分都只是文件的简单移动,其他改动的地方也非常的简单,很难想像这种情况会触发什么编译器的问题,毕竟几乎 100% 的情况下,怀疑编译器只会打自己的脸。
那问题可能出在哪里呢?我们知道,Android 编译并不仅仅有 javac 阶段,还会有其他编译过程,而 aar 文件中除了 jar 文件之外,还有一堆其他的 Android 相关的产物,这是如果代码看不出问题的话,难道是其他编译产物导致了的问题吗?
找一个最上层的业务组件对比了一下编译产物 aar 文件:
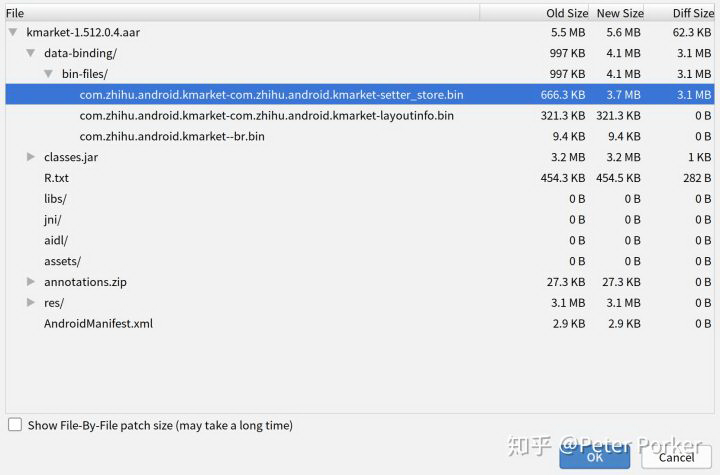
如上图,发现很明显有一个 setter_stores.bin 文件的体积有了巨幅的增长,不出意外的话,打包时间应该跟这个文件有关系。
然后再分析了其他组件的 aar,发现此文件的体积增幅与 javac 编译时间的增幅基本一致,而 体积与编译时间的增幅与依赖树的所有分支中包含 databinding 组件数量最多的那条分支的 databinding 数量大致呈指数关系。也就是说:
原本编译 Java 只要 2 分钟,依赖层级中多了一层普通的库,编译时间不会发生变化,而如果多了一层启用了 DataBinding 的库,可能会增长 1 分钟,如果再多两层 DataBinding ,则会增长 4 分钟。
得出这个猜测之后,解决方案就比较明确了:去除一些组件的 DataBinding 属性。由于页面框架和 Common 组件并没有多少 DataBinding 的代码,所以直接将这两个组件的 DataBinding 去掉,打包时间恢复。
虽然暂时解决了眼前的问题,但是并没有真正解决问题,说不定那一天 DataBinding 依赖层级会再次变多,问题会再次出现。果然,在组件化最后一次拆分完毕之后,编译时间再次暴涨。当时是将最后的社区业务全部从主工程中拆走,由于主工程业务复杂,拆走后变成了多个业务组件,这些业务组件由于历史原因是有耦合关系的,所以导致最终多了几个 DataBinding 依赖层级,而这些组件都使用了很多的 DataBinding 代码,使得去除 DataBinding 依赖变得有些不现实:首先是改造这些代码的开发成本,更重要的是 QA 的回归成本很高,还有就是这样不能真正解决问题,谁也不能确定日后会不会再有依赖层级出现,除非我们禁止再使用 DataBinding。是时候深究一下 DataBinding 导致编译变慢的根本原因了。
具体慢在哪里
要看到底慢在哪里的,我们就要知道,打包的这一段时间,它都在干什么,我们使用工具 visual vm 看一下( jstack 也可以):
1 ) 打开 Visual VM
2 ) 执行主工程编译命令,定位编译的进程 id (例子中为 7689)
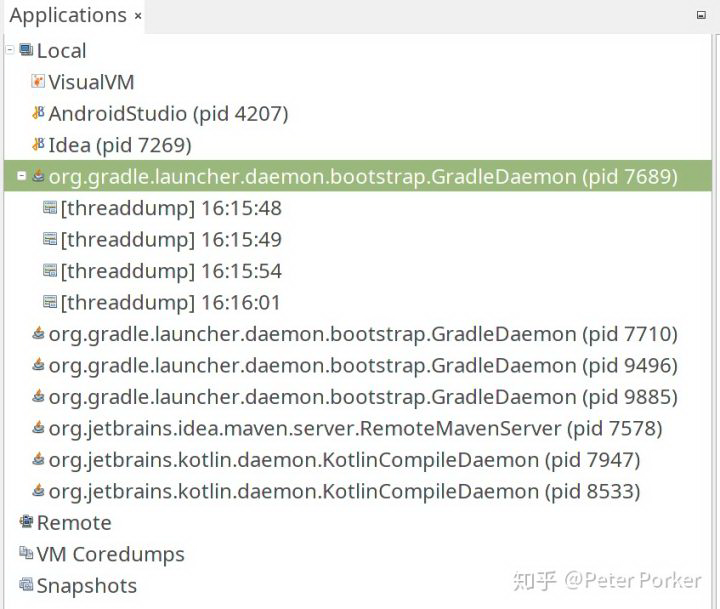
3 ) 在编译执行到 javac 阶段的时候 ( 比如 compileDebugJavaWithJavac ),在进程名上点击右键 → Thread Dump,将线程 dump 下来,可以多执行几次
4 ) 由于我们已经猜测是 DataBinding 导致的问题,所以直接在 dump 出的信息中搜索 databinding,发现每次都卡在了同一个地方:
所有 dump 的信息都卡在了 android.databinding.tool.store.SetterStore.merge(SetterStore.java:1173) 这一行上,很明显,直接原因就是这里了:SetterStore#merge 方法有鬼。
SetterStore 是做什么的
在 Android DataBinding 中,可以在 xml 中将数据与 view 的属性绑定,比如要把一个 String 绑定到 TextView 的 text 属性上去,那只需要在 xml 中声明
然后给 TextView 的 text 属性定义如何绑定数据
编译时 databinding-compiler 会找到 xml 属性对应的 BindingAdapter,并将 xml 中的绑定语法转换成 BindingAdapter 注解的方法,这样就实现了数据绑定。
但是,databinding-compiler 是通过 annotationProcessor 处理源码来生成代码的,一般来说 annotationProcessor 不会处理本模块以外的注解,比如说其他 aar 文件中的注解,那么如果在 Base 库中定义了 BindingAdapter 的话,如何让依赖 Base 库的工程也能使用 Base 库的 BindingAdapter 呢?
研究 databinding-compiler 的源码后发现答案就在 setter_stores.bin 中:databinding-compiler 会把得到的 BindingAdapter 及其他一些元素都存储一个 SetterStore.Intermediate 类实例中,而 setter_stores.bin 是这个对象被序列化后的结果,它最终被打包到 aar 中供引用者使用。引用者在编译时会把它依赖的所有的库的 setter_store.bin 都反序列化得到若干个 Intermediate 类实例,然后生成一个合并的 SetterStore 供 annotationProcessor 使用,这样 annotationProcessor 就可以使用其他工程定义的 BindingAdapter 了,而合并的数据最终又会被序列化成 setter_stores.bin 文件。
所以 SetterStore 主要做的就是序列化、反序列化与合并其他的 setter_stores.bin 文件。
为什么会变慢
我们先看一下 merge 的过程:
首先是拿到所有的 setter_store.bin 文件并反序列化然后合并,每一个循环都是在将一个 library 的 setter_store 合并到新的 store 中,看起来没毛病
再看合并单个 setter_store 的方法,看起来很正常,依次合并各个类型的数据
看一下合并单项的 merge 方法,Map 合并,好像也没有什么问题
setter_store 的内部是一个个的 Map(见 SetterStore.java#IntermediateV1 ),所以如果不出意外,最终会得到一个小的去重后的 setter_store 。但是我们打开这些生成的 setter_store.bin 文件,会发现里面有巨量的重复,同一个 BindindAdapter 在同一个 Map 中出现了多次,而 BindingAdapter 是存储 IntermediateV1#adapterMethods 这个字段中的,类型是 HashMap<String, HashMap<AccessorKey, MethodDescription>> ,这个 Map 难道有什么问题么?
猜测大量的重复应该是跟 key 的 hashcode 和 equals 设计不当有关,adapterMethods 是一个双重 Map,第一层 key 为 String,显然没有问题,pass,第二层的 key 是一个类 AccessorKey,看一下这个类的源码:
仔细审查一下 equals 那一行

viewType.equals(that.valueType) 肯定是恒为 false。
根据上面的分析,原本 merge 做的工作是将所有依赖的库的 setter_store 去重合并,现在因为 equals 写法错误,导致每个 Key 必然不一样,完全没有达到去重的效果
我们假设最简单的情况,我们有库 D 依赖 C、C 依赖 B,B 依赖 A,均开启了 databinding 且都没有定义任何的 adapterMethods,假设 databinding 库本身已经包含了 50 个 adapterMethods,那么:
A 依赖了 databinding 库,A 最终的 setter_store 中包含了 50 个 adapterMethods
B 依赖了 A 和 databinding 库,B 最终的 setter_store 中包含了 50 + 50 = 100 个 adapterMethods
C 依赖了 A、B 和 databinding 库,C 最终的 setter_store 中包含了 100 + 50 + 50 = 200 个 adapterMethods
D 依赖了 A、B、C 和 databinding 库,D 最终的 setter_store 中包含了 200 + 100 + 50 + 50 = 400 个 adapterMethods
与上面结论「体积的增幅与依赖树中包含 databinding 组件最长的那条链的长度大致呈指数关系」一致
而我们的主工程的依赖层级已经达到了 8 层,所以算起来重复率为 1/2^7 ,实际的使用环境中,依赖关系不仅仅是单链的依赖,每一个依赖层级可能会有多个库,所以事实上最终依赖会再翻几番,最终我们自定义 BindingMethod 的哈希冲突率接近 99.9% (862/863),而 databinding 自带的 BindingMethod 又翻了两番,哈希冲突率达到了 99.97% (3497/3498),整个 setter_store.bin 文件已经达到了 33M ,而事实上去重之后只有大约 100 个 BindingMethod。
解决方案
一、修改 databinding-compiler。
知道问题在哪里后,修改也就很简单了,修改出问题的那一行
重新打包 databinding-compiler,使用后速度果然快了
二、禁止不合理的依赖
虽然 DataBinding 导致的打包变慢的问题已经得到了解决,但是工程依赖层级过多也是一个问题,造成依赖问题的情况很多:一是某个大型业务拆分的时候,一次拆成了几个互相依赖的组件,导致层级变多,二是有些同学有开发的时候贪图方便,在发生组件间交互的时候,采用了直接引用其他组件(而不是引用组件接口)的方式,导致依赖关系变得复杂。所以我们的解决方案是对组件进行分级:
明确业务组件、业务中间件与基础组件的划分
业务组件间禁止发生直接依赖,下层组件禁止依赖上层组件,禁止循环依赖
对现存的不合理依赖按定级进行重新梳理和解决
对组件的定级落实到一个集中的配置文件,并使用 gradle 插件禁止错误的依赖
后续
这个 bug 已经存在了一年,2018 年初 Android Gradle Plugin 还是 3.0 版本的时候就遇到过,当初只是发现了是 DataBinding 的问题,但是并没有想到可能是一个 bug,所以只是简单的去掉了几个组件的 DataBinding 代码了事,后来再次探索这个问题的时候已经是 3.2.1 版本,一直没有被修复。而在写这篇文章之前几天,官方又出了 3.3 版本,这个问题已经修复了:SetterStore.java#1357
不仅如此,还悄悄的加了一个 compareTo 方法:
不了解 compareTo 的可以看这个 廖雪峰 # Java Map的正确使用方式

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论