

1. 导读
高德既有上半身(导航服务、交通服务、步导服务、渲染服务、离线包等),为亿级用户提供基础的地图展示、搜索、导航、路况服务;又有下半身(数据采集、制作),源源不断地采集最新的数据,为用户提供最新最准的数据。
下半身采集的数据,需要经过处理,序列化为二进制数据,输送给上半身的各个应用。同时,上半身的各个服务间也需要数据传输,这些都需要将地图数据序列化为二进制数据。
地图数据包括道路、POI、水系、绿地、建筑等,可抽象为三类:点、线、面数据。再进一步抽象,可分为两类:几何数据和属性数据。
本文将分享高德技术团队在地图数据序列化领域的探索和实践。
2. 序列化的关键因素
序列化主要考虑以下几个因素:
数据量:
针对客户端 App,流量消耗情况非常重要。高德地图对数据的新鲜度要求非常高,如京港澳高速开通,需要实时上线,让用户第一时间用最新的数据进行导航。数据更新快,会导致客户端缓存很快失效,需要实时从服务端请求最新数据。这就要求地图数据要尽量小,以减少服务带宽占用、用户流量消耗。
针对离线数据,离线包的大小也非常重要。地图数据全国离线包动辄上 G,对用户流量、下载速度和手机存储空间占用都是不小的消耗。
扩展性:
客户端 App 一方面无法控制用户软件更新,一方面又需要不停迭代为用户提供新功能。这就要求数据需要做到向前兼容和向后兼容。
各服务间的数据传递最好也做到数据兼容。如无法兼容,则需要各服务同步修改、同时上线,二者强耦合。强耦合就带来开发以及沟通的复杂性。
编解码效率:
毋庸置疑,二进制数据的解码效率,对服务和客户端来说,都是很重要的指标。
3. 序列化方案选择
3.1 开源序列化库的优势与弊端
序列化成本最低的选择是使用开源的序列化库。目前流行的开源序列化库有 protobuf,flatbuffers 等。它们的共同特点是都提供一种数据描述语言,只需定义好协议,即可自动生成编解码器,编码器负责将内存数据序列化为二进制数据,解码器负责将二进制数据反序列化到内存。
使用第三方库的好处是无需自己设计数据规格,自己实现编解码器,将这些工作交给第三方库,自己专注于业务逻辑即可。缺点是无法根据业务特点,充分定制化,设计出最适合地图业务的数据编码规格。
开源序列化库在扩展性方面都做的很好,支持协议的升级,并且在升级的同时保证向前兼容和向后兼容。flatbuffers 通过其特有的数据结构 table 实现,protobuf 通过 optional 关键字来实现。
数据量和编解码效率是相互矛盾的两个方面。protobuf 更倾向于降低数据量,针对数值类型的存储进行优化,使用 varint 存储整形,使用 zigzag 编码存储负数;可节省整形数据所占存储空间。
图 1 展示了使用 varint 表示整数 300 的原理,zigzag 原理如图 2 所示。flatbuffers 更倾向于使解码效率最优。它通过 mmap,zero-copy,random-access 等手段使得使用方解码、以及读取解码后的属性值都效率极高。
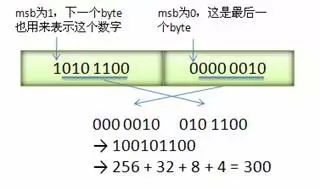
图 1 varint 表示
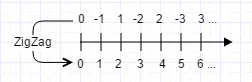
图 2 zigzag 编码
3.2 自定义序列化规格
由于地图数据有其独有特点,且全国数据量巨大,开源库序列化后的数据量大小都无法满足数据传输的要求。
所以,我们需要在保留开源库优点的前提下,设计自己的序列化规格。保证扩展性的同时,做到数据量最小,同时尽量优化解码效率。
地图数据功能扩展有两类:扩展一种新的要素,或者针对现有要素扩展其属性。如果仅考虑扩展性,flatbuffers 和 protobuf 都可满足要求。但地图数据使用方在不同场景下,希望可以只解析部分数据即可工作,即需要支持随机读取功能。
所以综合扩展性和随机读取这两类需求,我们针对性地设计了两种支持协议扩展的模式:章节式存储、可变属性。通过这两种模式,可支持任意的数据扩展,并且保证向前兼容和向后兼容。同时,这两种模式还可以带来解码效率的优化,使用方对其不关心的章节或者可变属性,可直接跳过,提高解码效率。
针对地图数据序列化后数据量的优化,我们无须拘泥于一种压缩形式,多种压缩方法综合使用,才能达到最好的压缩效果。shannon 的信息论告诉我们,对信息的先验知识越多,我们就可以把信息压缩的越小。
换句话说,如果压缩算法的设计目标不是任意的数据源,而是基本属性已知的特种数据,压缩的效果会进一步提高。这提醒我们,在使用通用压缩算法之余,还可以针对地图数据开发其特有的数据压缩算法。
我们使用的压缩手段有:
针对整形使用 varint 编码;
针对负数使用 zigzag 编码;
将 double 转为整形存储;
针对几何数据在不同比例尺做简化,经典的算法有 Douglas-Peucker,Li-Openshaw 等;
针对几何数据做曲线拟合,如贝塞尔曲线拟合,CLOTHOID 曲线拟合等。(如图 3 所示);
针对连续几何数据进行差值存储,减少每个坐标点所需 bit 数;
使用指定 bit 位存储数值类型,而非整数个字节。

图 3 贝塞尔曲线拟合
除了上述针对地图数据特有的压缩算法外,我们还可使用通用的无损压缩算法。目前通用的压缩库使用的算法基本分为两类:基于字典的压缩算法,基于统计的压缩算法。基于字典的压缩算法代表是 lz 系列算法(lz77, lz78, lzw,lzss),基于统计的压缩算法代表是 haffman 编码和算术编码等。
二者的基本原理都是找到输入串中冗余的信息,用更少的字节来表示冗余信息,以达到压缩的效果。基于字典的压缩算法以类似查字典的方法进行编码,它的基本原理是使用索引来表示字典中出现过的字符串。基于统计的压缩算法实质是统计字符的出现频率来对字符本身进行重新编码,属于熵编码类,与原始数据的排列次序无关而与其出现频率有关。
地图数据中的几何信息经过我们针对地图数据特有的压缩算法处理后,冗余信息已经很少了,所以使用通用压缩算法的效果不明显。针对属性信息,通用压缩算法有一定效果。所以我们的序列化协议支持对不同类型数据选择性地使用通用无损压缩算法。
综上,我们设计的序列化规格和 protobuf,flatbuffers 综合对比如下:
4. 小结
可以看出,各种序列化方法各有优缺点。扩展性方面,三者都做的很好。如果注重解码效率,则 flatbuffers 最优;如果注重数据量,则我们自定义的序列化规格最优。
当然,没有最好,只有最适合。选择时,需要根据业务特点来选择适合自己的序列化规格。
本文转载自公众号高德技术(ID:amap_tech)。
原文链接:

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论