
本文从 SQL on Hadoop 介绍、快手 SQL on Hadoop 平台概述、SQL on Hadoop 在快手的使用经验和改进分析、快手 SQL on Hadoop 的未来计划四方面介绍了 SQL on Hadoop 架构。整理自快手大数据架构工程师钟靓近日在 A2M 人工智能与机器学习创新峰会的演讲分享《SQL on Hadoop 在快手大数据平台的实践与优化》。

SQL on Hadoop 介绍
SQL on Hadoop,顾名思义它是基于 Hadoop 生态的一个 SQL 引擎架构,我们其实常常听到 Hive、SparkSQL、Presto、Impala 架构,接下来,我会简单描述一下常用的架构情况。
Hive
Hive,一个数据仓库系统。它将数据结构映射到存储的数据中,通过 SQL 对大规模的分布式存储数据进行读、写、管理。
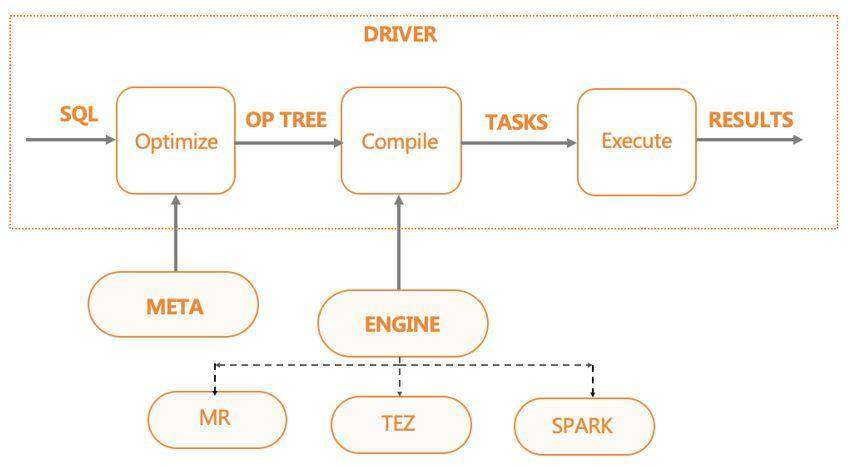
根据定义的数据模式,以及输出 Storage,它会对输入的 SQL 经过编译、优化,生成对应引擎的任务,然后调度执行生成的任务。
Hive 当前支持的引擎类型有:MR、Spark、TEZ。
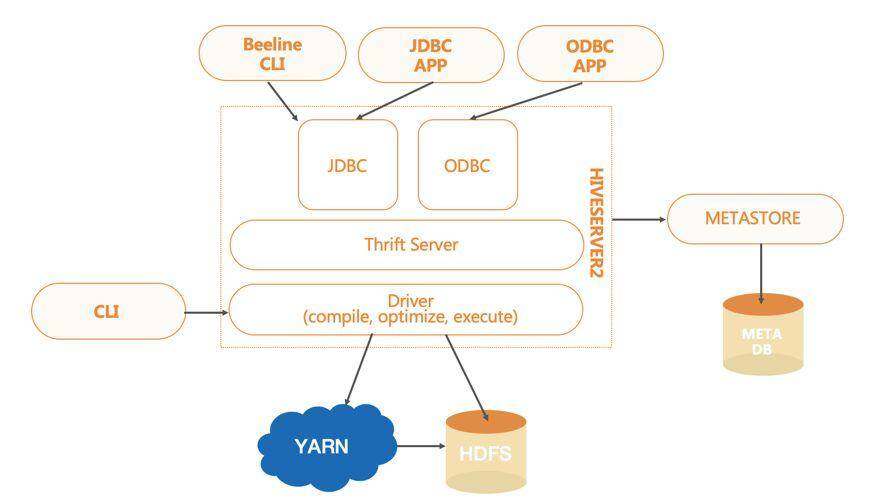
基于 Hive 本身的架构,还有一些额外的服务提供方式,比如 HiveServer2 与 MetaStoreServer 都是 Thrift 架构。
此外,HiveServer2 提供远程客户端提交 SQL 任务的功能,MetaStoreServer 则提供远程客户端操作元数据的功能。
Spark
Spark,一个快速、易用,以 DAG 作为执行模式的大规模数据处理的统一分析引擎,主要模块分为 SQL 引擎、流式处理 、机器学习、图处理。
SparkSQL
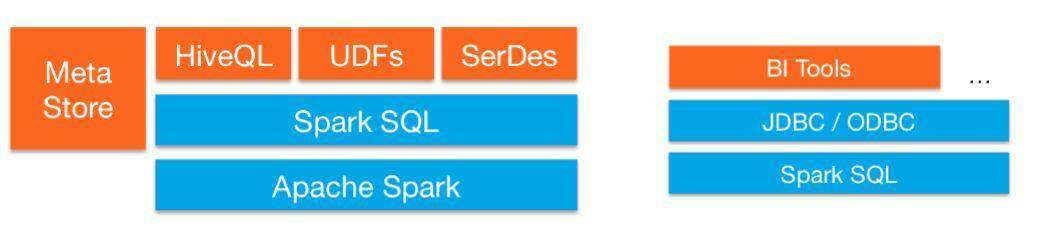
SparkSQL 基于 Spark 的计算引擎,做到了统一数据访问,集成 Hive,支持标准 JDBC 连接。SparkSQL 常用于数据交互分析的场景。
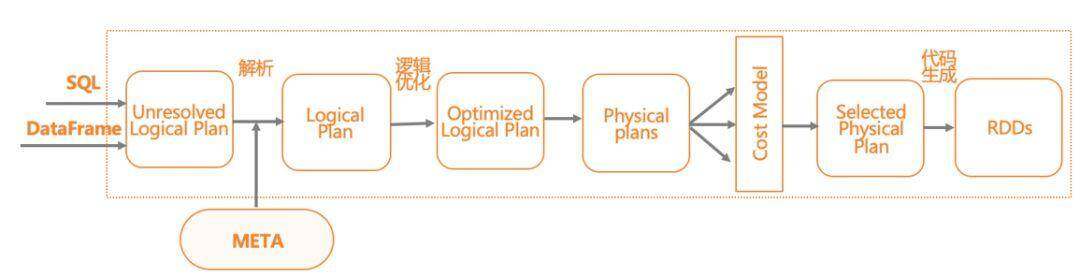
SparkSQL 的主要执行逻辑,首先是将 SQL 解析为语法树,然后语义分析生成逻辑执行计划,接着与元数据交互,进行逻辑执行计划的优化,最后,将逻辑执行翻译为物理执行计划,即 RDD lineage,并执行任务。
Presto
Presto,一个交互式分析查询的开源分布式 SQL 查询引擎。
因为基于内存计算,Presto 的计算性能大于有大量 IO 操作的 MR 和 Spark 引擎。它有易于弹性扩展,支持可插拔连接的特点。
业内的使用案例很多,包括 FaceBook、AirBnb、美团等都有大规模的使用。

其它业内方案

我们看到这么多的 SQL on Hadoop 架构,它侧面地说明了这种架构比较实用且成熟。利用 SQL on Hadoop 架构,我们可以实现支持海量数据处理的需求。
快手 SQL on Hadoop 平台概述
平台规模
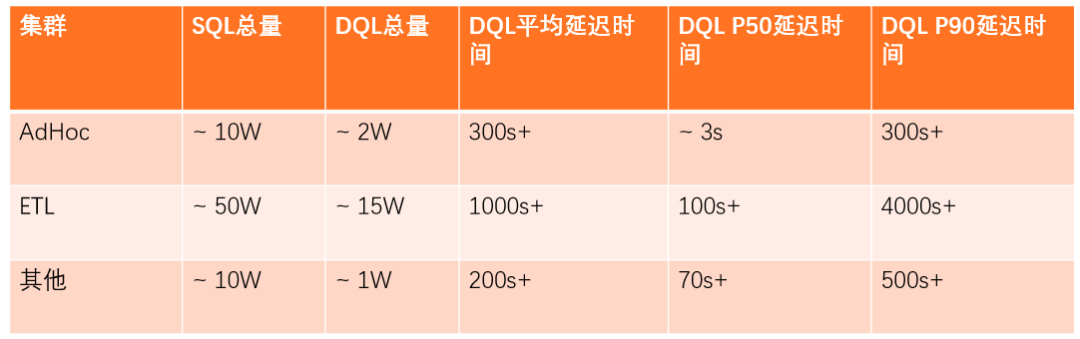
查询平台每日 SQL 总量在 70 万左右,DQL 的总量在 18 万左右。AdHoc 集群主要用于交互分析及机器查询,DQL 平均耗时为 300s;AdHoc 在内部有 Loacl 任务及加速引擎应用,所以查询要求耗时较低。
ETL 集群主要用于 ETL 处理以及报表的生成。DQL 平均耗时为 1000s,DQL P50 耗时为 100s,DQL P90 耗时为 4000s,除上述两大集群外,其它小的集群主要用于提供给单独的业务来使用。
服务层次
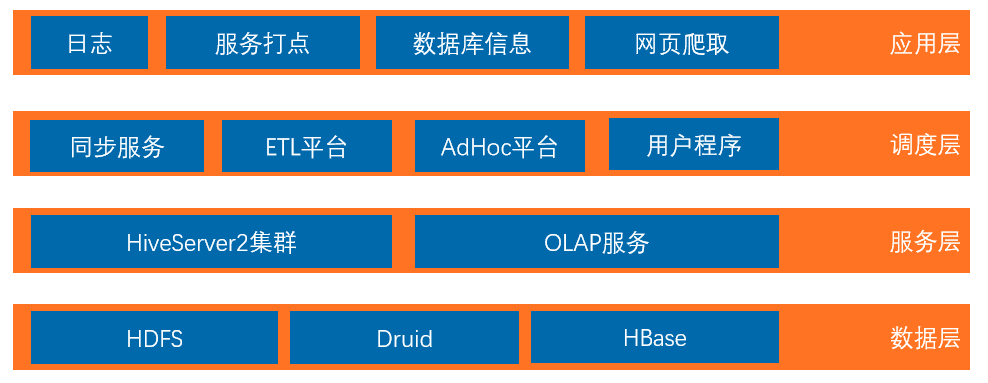
服务层是对上层进行应用的。在上层有四个模块,这其中包括同步服务、ETL 平台、AdHoc 平台以及用户程序。在调度上层,同样也有四方面的数据,例如服务端日志,对它进行处理后,它会直接接入到 HDFS 里,我们后续会再对它进行清洗处理;服务打点的数据以及数据库信息,则会通过同步服务入到对应的数据源里,且我们会将元数据信息存在后端元数据系统中。
网页爬取的数据会存入 hbase,后续也会进行清洗与处理。
平台组件说明
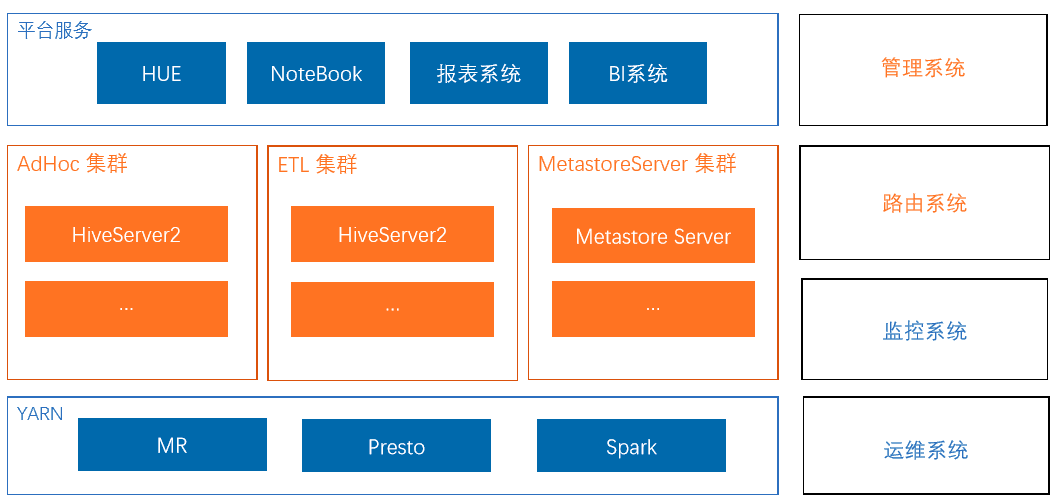
HUE、NoteBook 主要提供的是交互式查询的系统。报表系统、BI 系统主要是 ETL 处理以及常见的报表生成,额外的元数据系统是对外进行服务的。快手现在的引擎支持 MR、Presto 及 Spark。
管理系统主要用于管理我们当前的集群。HiveServer2 集群路由系统,主要用于引擎的选择。监控系统以及运维系统,主要是对于 HiveServer2 引擎进行运维。
我们在使用 HiveServer2 过程中,遇到过很多问题。接下来,我会详细的为大家阐述快手是如何进行优化及实践的。
SQL on Hadoop 在快手的使用经验和改进分析
HiveServer2 多集群架构
当前有多个 HiveServer2 集群,分别是 AdHoc 与 ETL 两大集群,以及其他小集群。不同集群有对应的连接 ZK,客户端可通过 ZK 连接 HiveServer2 集群。
为了保证核心任务的稳定性,将 ETL 集群进行了分级,分为核心集群和一般集群。在客户端连接 HS2 的时候,我们会对任务优先级判定,高优先级的任务会被路由到核心集群,低优先级的任务会被路由到一般集群。
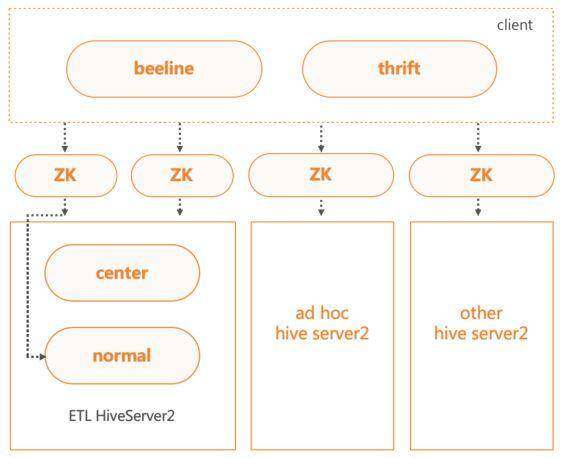
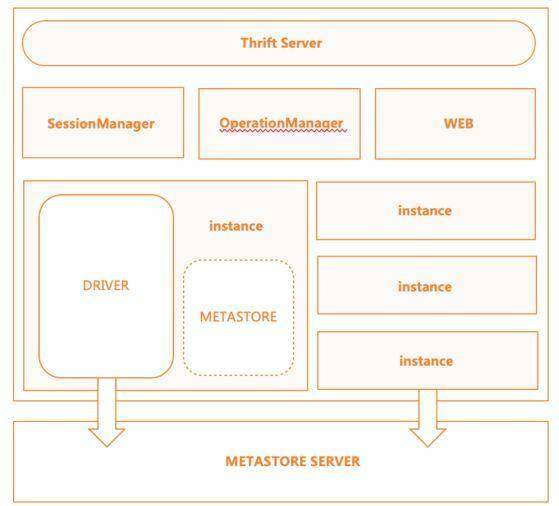
HiveServer2 服务内部流程图
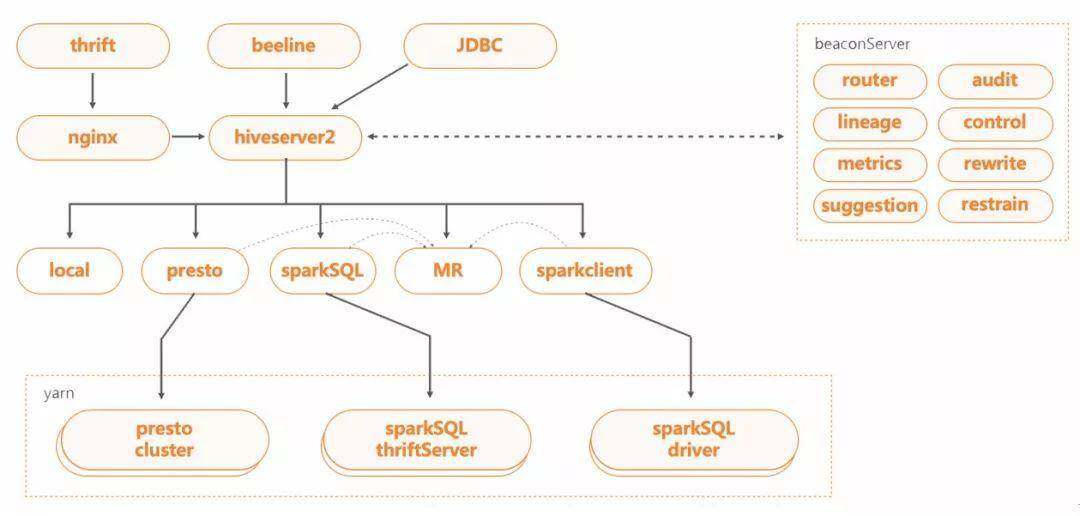
BeaconServer 服务
BeaconServer 服务为后端 Hook Server 服务,配合 HS2 中的 Hook,在 HS2 服务之外实现了所需的功能。当前支持的模块包括路由、审计、SQL 重写、任务控制、错误分析、优化建议等。
无状态,BeaconServer 服务支持水平扩展。基于请求量的大小,可弹性调整服务的规模。
配置动态加载,BeaconServer 服务支持动态配置加载。各个模块支持开关,服务可动态加载配置实现上下线。比如路由模块,可根据后端加速引擎集群资源情况 ,进行路由比率调整甚至熔断。
无缝升级,BeaconServer 服务的后端模块可单独进行下线升级操作,不会影响 Hook 端 HS2 服务。
高性能问题
使用新引擎进行加速面临的问题
Hive 支持 Spark 与 TEZ 引擎,但不适用于生产环境。
SQL on Hadoop 的 SQL 引擎各有优缺点,用户学习和使用的门槛较高。
不同 SQL 引擎之间的语法和功能支持上存在差异,需要大量的测试和兼容工作,完全兼容的成本较高。
不同 SQL 引擎各自提供服务会给数仓的血缘管理、权限控制、运维管理、资源利用都带来不便。
智能引擎的解决方案
在 Hive 中,自定义实现引擎。
自动路由功能,不需要设置引擎,自动选择适合的加速引擎。
根绝规则匹配 SQL,只将兼容的 SQL 推给加速引擎。
复用 HiveServer2 集群架构。
智能引擎:主流引擎方案对比
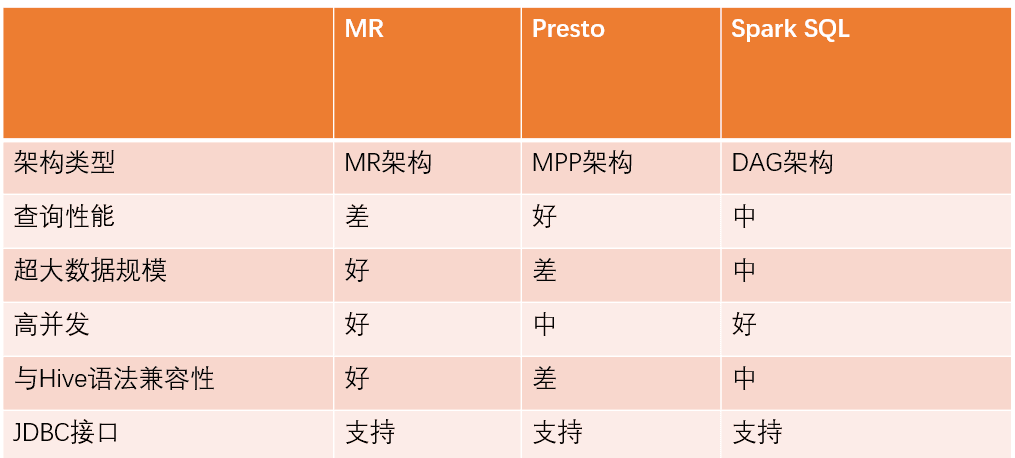
智能引擎:HiveServer2 自定义执行引擎的模块设计
基于 HiveServer2,有两种实现方式。JDBC 方式是通过 JDBC 接口,将 SQL 发送至后端加速引擎启动的集群上。PROXY 方式是将 SQL 下推给本地的加速引擎启动的 Client。
JDBC 方式启动的后端集群,均是基于 YARN,可以实现资源的分时复用。比如 AdHoc 集群的资源在夜间会自动回收,作为报表系统的资源进行复用。
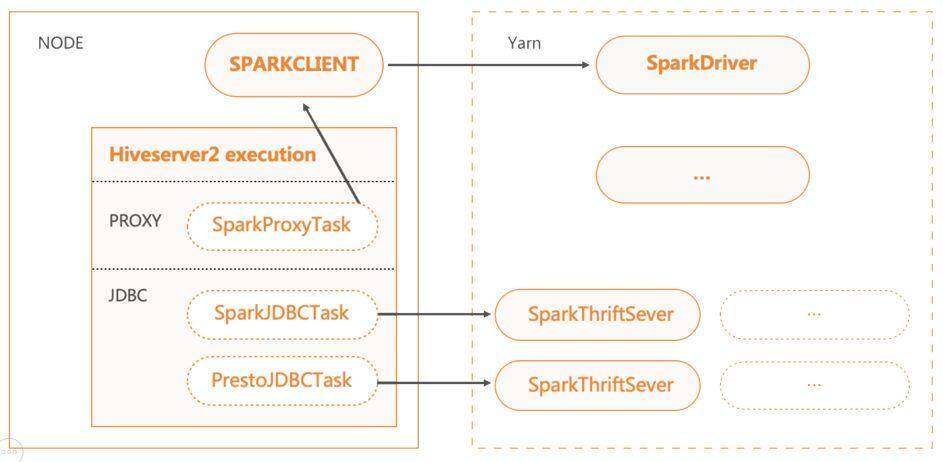
智能引擎:SQL 路由方案设计架构
路由方案基于 HS2 的 Hook 架构,在 HS2 端实现对应 Hook,用于引擎切换;后端 BeaconServer 服务中实现路由 服务,用于 SQL 的路由规则的匹配处理。不同集群可配置不同的路由规则。
为了保证后算路由服务的稳定性,团队还设计了 Rewrite Hook,用于重写 AdHoc 集群中的 SQL,自动添加 LIMIT 上限,防止大数据量的 SCAN。
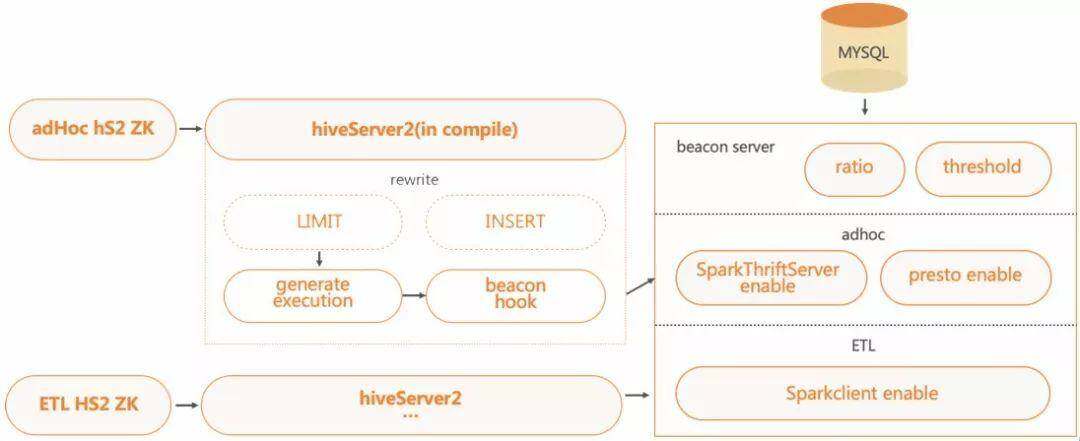
智能引擎:SQL 路由规则一览

智能引擎:方案优势
易于集成,当前主流的 SQL 引擎都可以方便的实现 JDBC 与 PROXY 方式。再通过配置,能简单的集成新的查询引擎,比如 impala、drill 等。
自动选择引擎,减少了用户的引擎使用成本,同时也让迁移变得更简单。并且在加速引擎过载 的情况下,可以动态调整比例,防止因过载 对加速性能的影响。
自动降级,保证了运行的可靠性。SQL 路由支持 failback 模块,可以根据配置选择是否再路由引擎执行失败后,回滚到 MR 运行。
模块复用,对于新增的引擎,都可以复用 HiveServer2 定制的血缘采集、权限认证、并发锁控制等方案,大大降低了使用成本。
资源复用,对于 adhoc 查询占用资源可以分时动态调整,有效保证集群资源的利用率。
智能引擎 DQL 应用效果
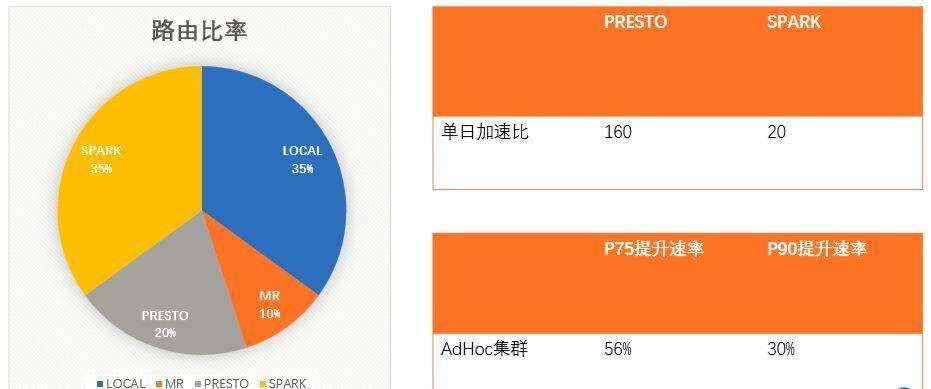
HiveServer2 中存在的性能问题

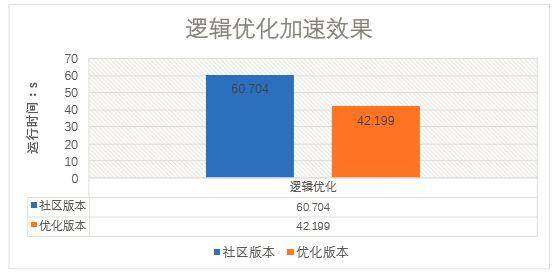
FetchTask 加速:预排序与逻辑优化
当查询完成后,本地会轮询结果文件,一直获取到 LIMIT 大小,然后返回。这种情况下,当有大量的小文件存在,而大文件在后端的时候,会导致 Bad Case,不停与 HDFS 交互,获取文件信息以及文件数据,大大拉长运行时间。
在 Fetch 之前,对结果文件的大小进行预排序,可以有数百倍的性能提升。
示例:当前有 200 个文件。199 个小文件一条记录 a,1 个大文件混合记录 a 与 test 共 200 条,大文件名 index 在小文件之后。
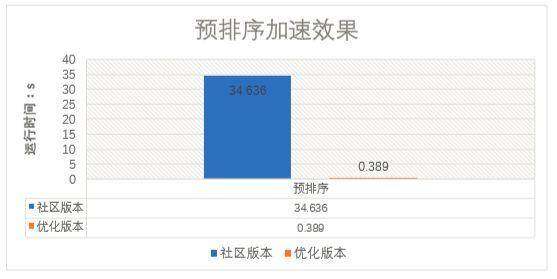
FetchTask 加速:预排序与逻辑优化
Hive 中有一个 SimpleFetchOptimizer 优化器,会直接生成 FetchTask,减小资源申请时间与调度时间。但这个优化会出现瓶颈。如果数据量小,但是文件数多,需要返回的条数多, 存在能大量筛掉结果数据的 Filter 条件。这时候串行读取输入文件,导致查询延迟大,反而没起到加速效果。
在 SimpleFetchOptimizer 优化器中,新增文件数的判断条件,最后将任务提交到集群环境, 通过提高并发来实现加速。
示例:读取当前 500 个文件的分区。优化后的文件数阈值为 100。
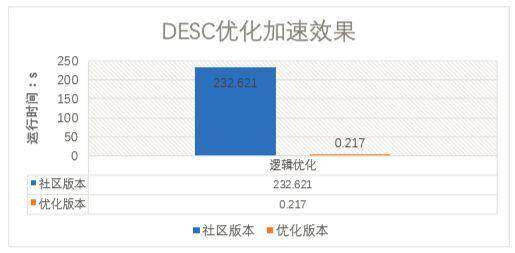
大表 Desc Table 优化
一个表有大量的子分区,它的 DESC 过程会与元数据交互,获取所有的分区。但最后返回的结果,只有跟表相关的信息。
与元数据交互的时候,延迟了整个 DESC 的查询,当元数据压力大的时候甚至无法返回结果。
针对于 TABLE 的 DESC 过程,直接去掉了跟元数据交互获取分区的过程,加速时间跟子分区数量成正比。
示例:desc 十万分区的大表。
其它改进
复用 split 计算的数据,跳过 reduce 估算重复统计输入过程。输入数据量大的任务,调度速率提升 50%。
parquetSerde init 加速,跳过同一表的重复列剪枝优化,防止 map task op init 时间超时。
新增 LazyOutputFormat,有 record 输出再创建文件,避免空文件的产生,导致下游读取大量空文件消耗时间。
statsTask 支持多线程聚合统计信息,防止中间文件过多导致聚合过慢,增大运行时间。
AdHoc 需要打开并行编译,防止 SQL 串行编译导致整体延迟时间增大的问题。
高可用性问题

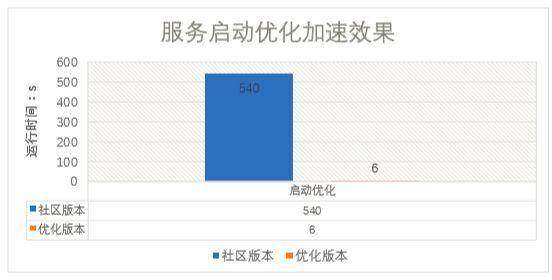
HiveServer2 服务启动优化
HS2 启动时会对物化视图功能进行初始化,轮询整个元数据库,导致 HS2 的启动时间非常长,从下线状态到重新上线间隔过大,可用性很差。
将物化视图功能修改为延迟懒加载,单独线程加载,不影响 HS2 的服务启动。物化视图支持加载中获取已缓存信息,保证功能的可用性。
HS2 启动时间从 5min+提升至<5s。
HiveServer2 配置热加载
HS2 本身上下线成本较高,需要保证服务上的任务全部执行完成才能进行操作。配置的修改可作为较高频率的操作,且需要做到热加载。
在 HS2 的 ThriftServer 层我们增加了接口,与运维系统打通后,配置下推更新的时候自动调用,可实现配置的热加载生效。
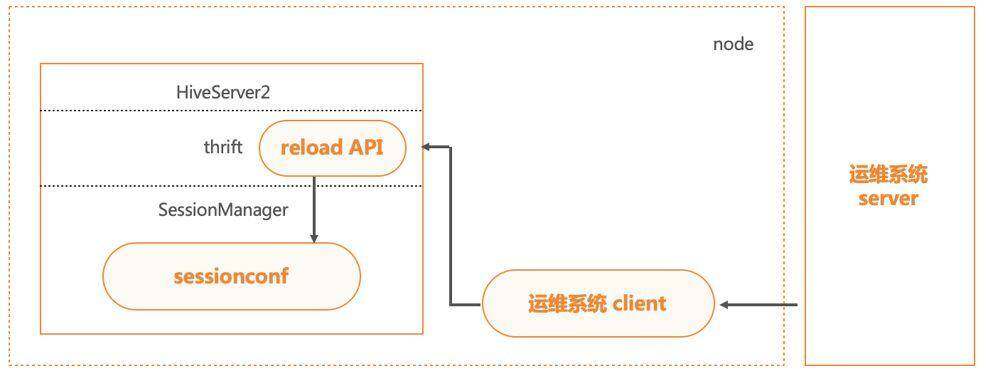
HiveServer2 的 Scratchdir 优化
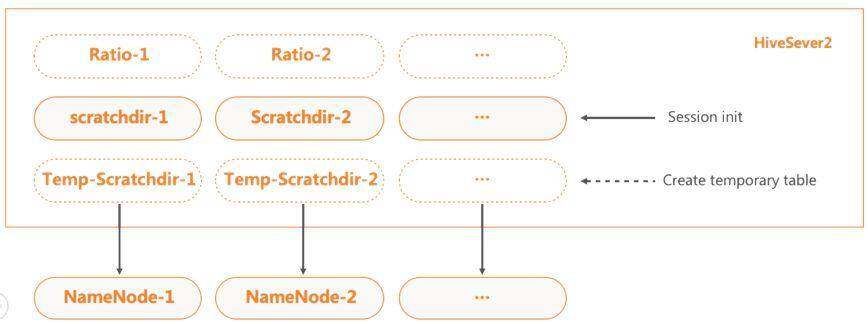
HiveServer2 的 scratchdir 主要用于运行过程中的临时文件存储。当 HS2 中的会话创建时,便会创建 scratchdir。 在 HDFS 压力大的时候,大量的会话会阻塞在创建 scratchdir 过程,导致连接数堆积至上限,最终 HS2 服务无法再连入新连接,影响服务可用性。
对此,我们先分离了一般查询与 create temporay table 查询的 scratch 目录,并支持 create temporay table 查询的 scratch 的懒创建。 当 create temporay table 大量创建临时文件,便会影响 HDFS NameNode 延迟时间的时候,一般查询的 scratchdir HDFS NameNode 可以正常响应。
此外,HS2 还支持配置多 scratch,不同的 scratch 能设置加载比率,从而实现 HDFS 的均衡负载。
Hive Stage 并发调度异常修复
Hive 调度其中存在两个问题。
一、子 Task 非执行状态为完成情况的时候,若有多轮父 Task 包含子 Task,导致子 Task 被重复加入调度队列。这种 Case,需要将非执行状态修改成初始化状态。
二、当判断子 Task 是否可执行的过程中,会因为状态检测异常,无法正常加入需要调度的子 Task,从而致使查询丢失 Stage。而这种 Case,我们的做法是在执行完成后,加入一轮 Stage 的执行结果状态检查,一旦发现有下游 Stage 没有完成,直接抛出错误,实现查询结果状态的完备性检查。

其它改进
HS2 实现了接口终止查询 SQL。利用这个功能,可以及时终止异常 SQL。
metastore JDOQuery 查询优化,关键字异常跳过,防止元数据长时间卡顿或者部分异常查询影响元数据。
增加开关控制,强制覆盖外表目录,解决 insert overwrite 外表,文件 rename 报错的问题。
hive parquet 下推增加关闭配置,避免 parquet 异常地下推 OR 条件,导致结果不正确。
executeForArray 函数 join 超大字符串导致 OOM,增加限制优化。
增加根据 table 的 schema 读取分区数据的功能,避免未级联修改分区 schema 导致读取数据异常。
易用性问题
为什么要开发 SQL 专家系统
部分用户并没有开发经验,无法处理处理引擎返回的报错。
有些错误的报错信息不明确,用户无法正确了解错误原因。
失败的任务排查成本高,需要对 Hadoop 整套系统非常熟悉。
用户的错误 SQL、以及需要优化的 SQL,大量具有共通性。人力维护成本高,但系统分析成本低。
SQL 专家系统
SQL 专家系统基于 HS2 的 Hook 架构,在 BeaconServer 后端实现了三个主要的模块,分别是 SQL 规则控制模块、SQL 错误分析模块,与 SQL 优化建议模块。SQL 专家系统的知识库,包含关键字、原因说明、处理方案等几项主要信息,存于后端数据库中,并一直积累。
通过 SQL 专家系统,后端可以进行查询 SQL 的异常控制,避免异常 SQL 的资源浪费或者影响集群稳定。用户在遇到问题时,能直接获取问题的处理方案,减少了使用成本。
示例:空分区查询控制。

作业诊断系统
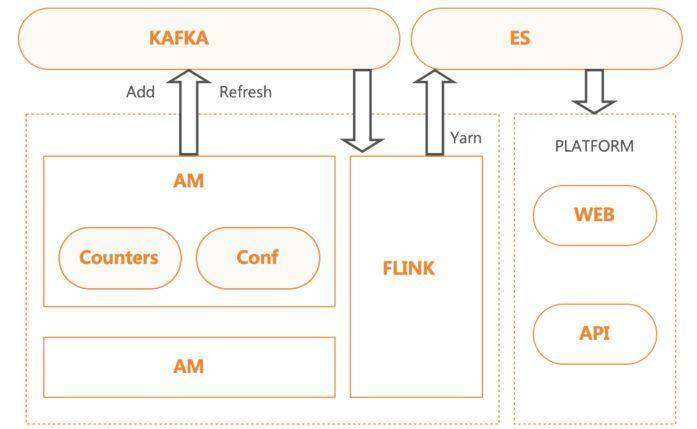
SQL 专家系统能解决一部分 HS2 的任务执行的错误诊断需求,但是比如作业健康度、任务执行异常等问题原因的判断,需要专门的系统来解决,为此我们设计了作业诊断系统。
作业诊断系统在 YARN 的层面,针对不同的执行引擎,对搜集的 Counter 和配置进行分析。在执行层面,提出相关的优化建议。
作业诊断系统的数据也能通过 API 提供给 SQL 专家系统,补充用于分析的问题原因。
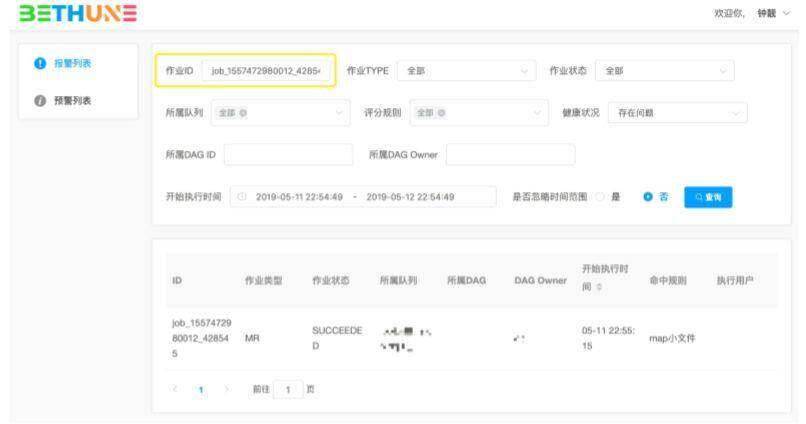
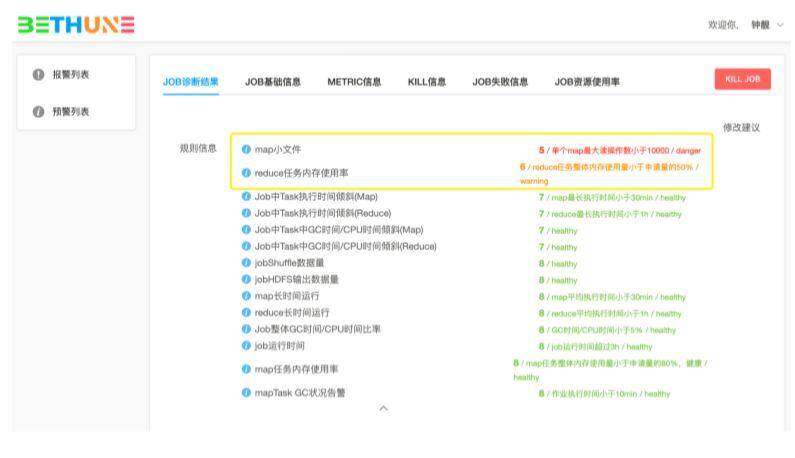
作业诊断系统提供了查询页面来查询运行的任务。以下是命中 map 输入过多规则的任务查询过程:
在作业界面,还可以查看更多的作业诊断信息,以及作业的修改建议。
运维性问题

审计分析 - 架构图
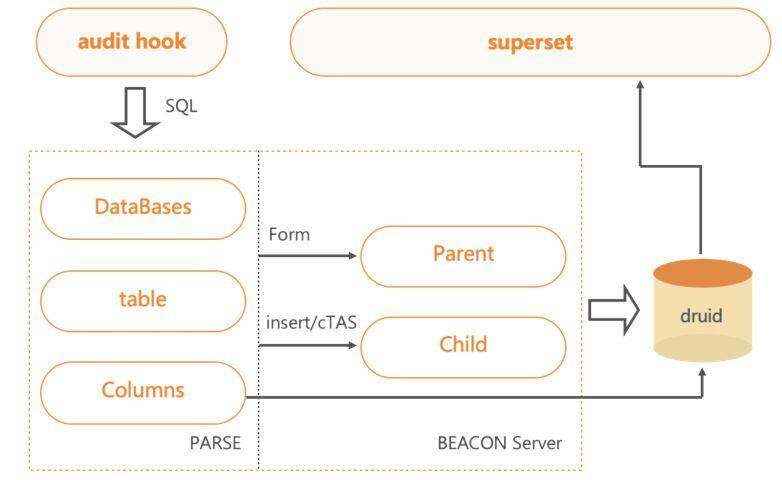
审计功能也是 BeaconServer 服务的一个模块。
通过 HS2 中配置的 Hook,发送需要的 SQL、IP、User 等信息至后端,进行语法分析,便可提取出 DataBase、Table、Columns 与操作信息,将其分析后再存入 Druid 系统。用户可通过可视化平台查询部分开放的数据。
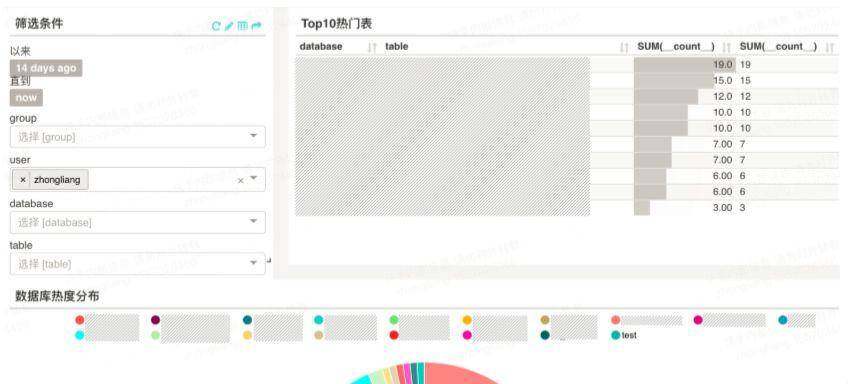
审计分析 - 热点信息查询
热点信息查询即将热点信息展示了一段时间以内,用户的热点操作,这其中包括访问过哪些库,哪些表,以及哪些类型的操作。
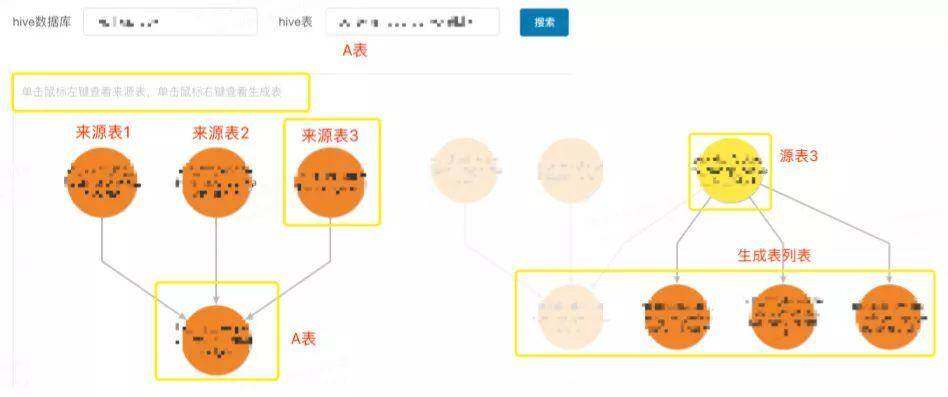
审计分析 - 血缘信息查询
下图可看出,血缘信息展示了一张表创建的上游依赖,一般用于统计表的影响范围。
审计分析 - 历史操作查询
历史操作可以溯源到一段时间内,对于某张表的操作。能获取到操作的用户、客户端、平台、以及时间等信息。一般用于跟踪表的增删改情况。
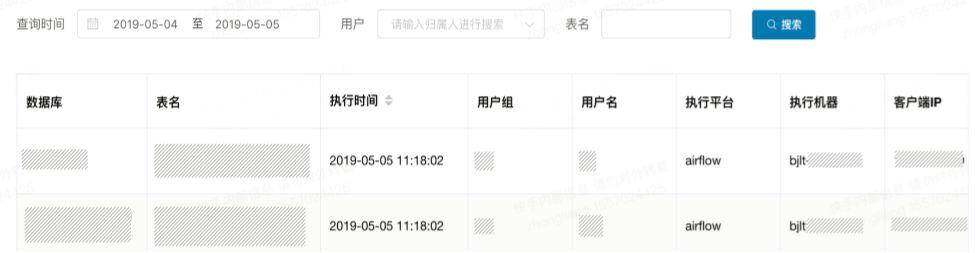
HiveServer2 集群 AB 切换方案
因为 HiveServer2 服务本身的上下线成本较高,如果要执行一次升级操作,往往耗时较长且影响可用性。HiveServer2 集群的 AB 切换方案,主要依靠 A 集群在线,B 集群备用的方式,通过切换 ZK 上的在线集群机器,来实现无缝的升级操作。
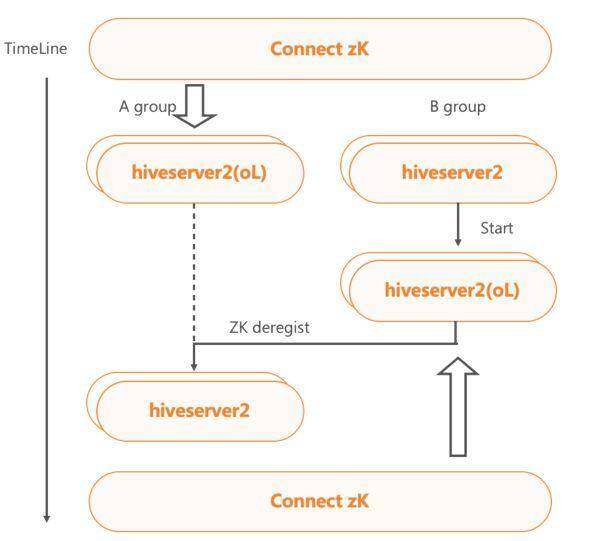
HiveServer2 集群动态上下线
HiveServer2 集群部署了 Metrics 监控,能够实时地跟踪集群服务的使用情况。此外,我们对 HS2 服务进行了改造,实现了 HS2 ZK 下线和请求 Cancel 的接口。
当外部 Monitor 监控感知到连续内存过高,会自动触发 HS2 服务进程的 FGC 操作,如果内存依然连续过高,则通过 ZK 直接下线服务,并根据查询提交的时间顺序,依次停止查询,直到内存恢复,保证服务中剩余任务的正常运行。
HiveServer2 集群管理平台
HiveServer2 在多集群状态下,需要掌握每个集群、以及每个 HS2 服务的状态。通过管理平台,可以查看版本情况、启动时间、资源使用情况以及上下线状态。
后续跟运维平台打通,可以更方便地进行一键式灰度以及升级。
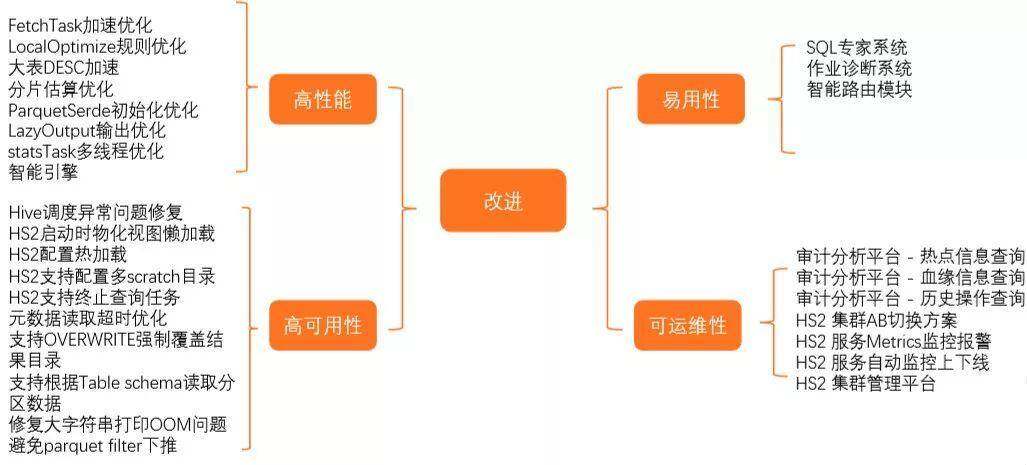
快手查询平台的改进总结
快手 SQL on Hadoop 的未来计划
专家系统的升级,实现自动化参数调优和 SQL 优化
AdHoc 查询的缓存加速
新引擎的调研与应用

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 1 条评论