

在数据仓库建模中,未经任何加工处理的原始业务层数据,称之为 ODS(Operational Data Store)数据。作为 DBA 来说,关心的肯定是如何把关系型数据库的业务数据同步到数据仓库中去…
一、领导的需求
我从一份领导的需求开始:
1.实现业务系统 7*24 小时不间断运行。
2.保证业务系统数据安全性。
3.降低生产系统压力,将部分查询和报表分析业务负载分离出去。
看似简单的几行字,实际上并不简单,对我们公司而言,至少走过了几年,痛苦的几年…
二、系统架构
我先介绍一下公司某业务数据库选型和架构,业务库采用了 Oracle 11G RAC+DataGuard (3+2),数据仓库是 2 套单实例的 ORACLE 12C。
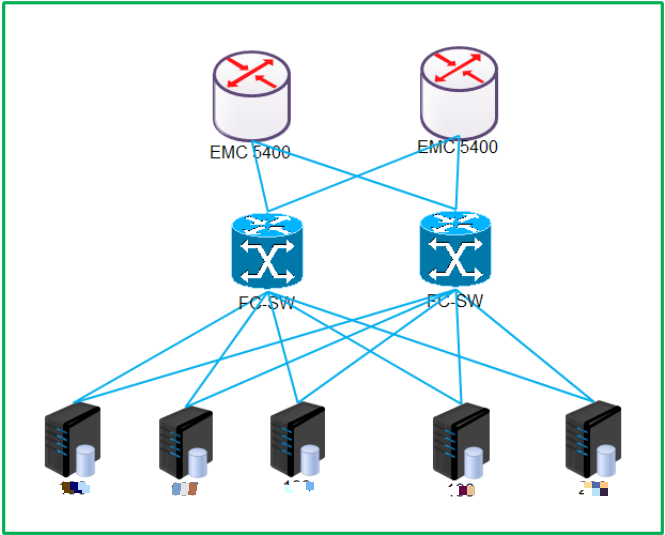
1. 主备节点之间采用光纤直连。
2. 正常情况下,主节点的数据(REDO)传递到备节点 APPLY。
3. 切换至备库节点步骤:
当生产数据库发生灾难时,备库角色从 standby 变为 primary,可以进行业务负载。
将 DNS 中主库域名解析地址由主库 scan ip 切换至备库 scan ip。
应用配置无需更改,最大限度的提高业务恢复速度。
DataGuard 有 switch over、fail over 两种切换方式。
switch over 功能,在容灾演练、生产环境服务器或存储硬件升级、服务器非存储类硬件故障或其它计划内的切换动作时,可以采用 switch over 方式进行切换。switch over 切换过程是可逆的,即主备数据库可以反复相互切换。*
fail over 功能,当生产环境服务器发生存储类故障且无法修复,可以采用 failover 方式强制切换。failover 切换过程是不可逆的,备数据库变为主数据库后,是不能再回切回来的,即使原来的主数据库修好后,需要重建 DataGuard,才能保持容灾同步关系。
2016 年的某一个晚上,我们拉研发、测试人员等十几号人,埋头奋战了一夜,通过 SWITCH OVER 切换演练,做到了大部分应用程序无缝接管,保证了核心业务连续性。当然,也发现了一些问题,也及时进行经验总结。
在业务应用服务梳理中,遗漏了少部分外围的系统,事后才发现。
在 DNS 进行域名切换时,少部分服务出现访问异常,由于长事务等原因,后手动重启服务才解决的。
在我们引进 ORACLE RAC+DataGuard 架构后,带来的效果是明显的,解决我们数据库的单点故障,备库承担了大部分读的角色,同时也释放了主库的一部分读写压力。加上每天 RMAN LEVEL0-LEVEL2 的备份机制,保证了核心业务系统数据安全性,也朝着实现核心业务系统 7*24 小时不间断运行迈进了很重要的一步。
故事还没结束,才刚刚开始,呵呵!我的中心思想是业务报表数据同步,如何实现数据同步?如何给数据中心那边提供一个单纯,而又干净的数据仓库呢?
看到这,大部分读者首先想到是 DBLINK 最方便,在备库上用 DBLINK 同步。作为 DBA 来言,不能否认用 DBLINK 在某些方面确实能带来方便,如临时迁移数据、少部分基础表的数据同步等,但作为数据仓库建模,做大数据分析、报表,可想而知,数据量的规模,DBLINK 太小家子气了,而且用 DBLINK 存在隐患。
不支持断点续传功能,如果源端数据库出问题(UNDO 不足、TEMP 不足等)、网络问题,需要重新同步数据,牵扯到效率问题。
不支持 DDL,如果通过大量的自定义触发器来实现,在效率和准确性方面需要长时间验证,得不偿失。
几年前爆发的 dblink 导致 SCN Headroom 过低问题,有血的教训。
具体可以参考:
System Change Number (SCN), Headroom, Security and Patch Information (文档 ID 1376995.1)
Installing, Executing and Interpreting output from the “scnhealthcheck.sql” script (文档 ID 1393363.1)
三、利剑之一 Kettle+Azkaban
我们首先想到了 ETL 工具,想到了 Kettle,也想到了 Azkaban。
ETL 是 EXTRACT(抽取)、TRANSFORM(转换)、LOAD(加载)的简称,实现数据从多个异构数据源加载到数据库或其他目标地址,是数据仓库建设和维护中的重要一环,也是工作量较大的一块。
Azkaban 是一个任务调度系统,用于负责任务的调度运行(如数据仓库调度),用以替代 linux 中的 crontab。
Kettle 是一款国外开源的 ETL 工具,JAVA 开发的,数据抽取高效稳定。Kettle 中文名称叫水壶,该项目的主程序员 MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Azkaban 是一个 Linkedin 开源的,JAVA 开发的,批量工作流任务调度器, 用于在一个工作流内以一个特定的顺序运行一组工作和流程,定义了一种 KV 文件格式来建立任务之间的依赖关系,友好 WEB 界面,便于维护和跟踪工作流。
kettle 和 Azkaban 的引入,也验证了一句话,“好东西永远不愁卖,何况还不要钱”。
关键工作流程:
如图所示,首先在 Spoon 上编排数据抽取任务(任务中包含多个转换,多任务并行执行),其次将源表的数据经过处理输出到目标端数据库中,更新原有记录,再次在 Spoon 上完成任务编排,通过组件 kitchen 来调用编排好任务,最后将调用的内容编写成 shell 脚本,由 azkaban 进行任务调度。
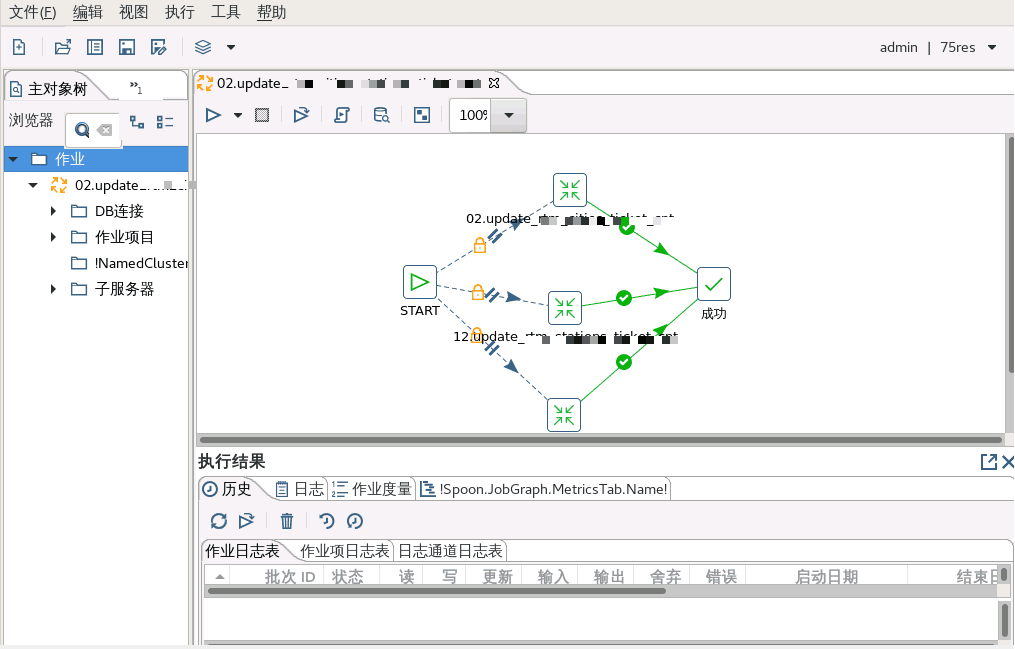
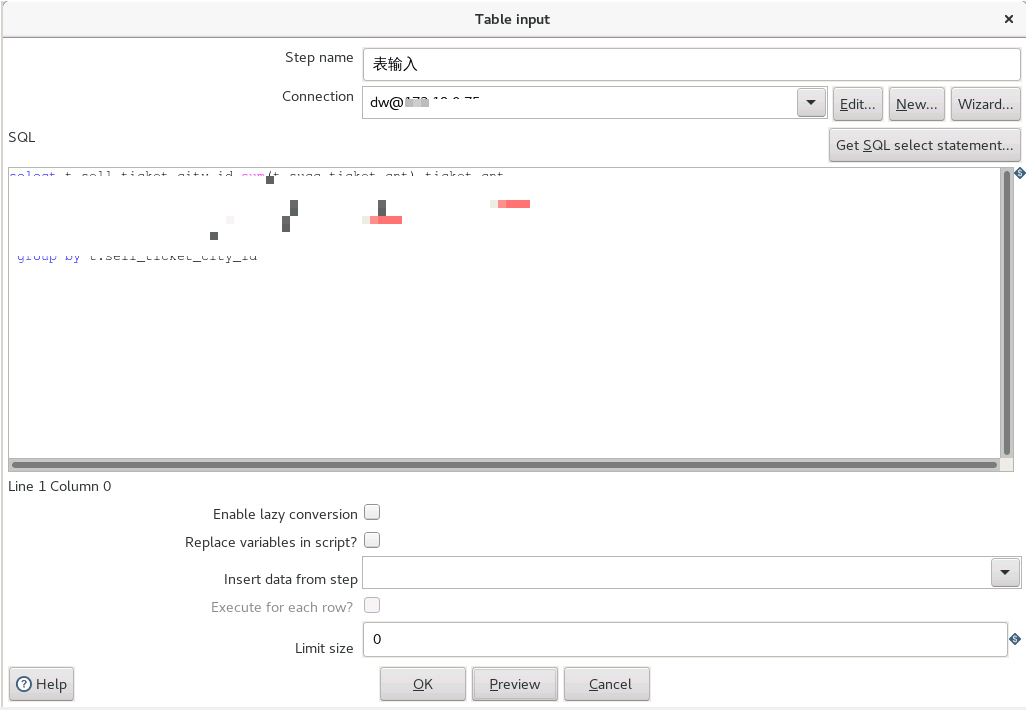
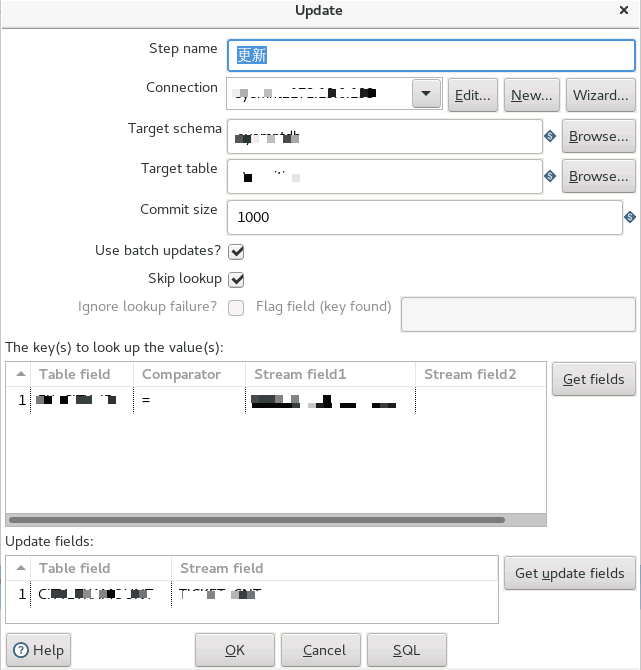
Azkaban 友好的 WEB 界面,运维人员能方便的查看任务执行情况,以及任务执行日志。
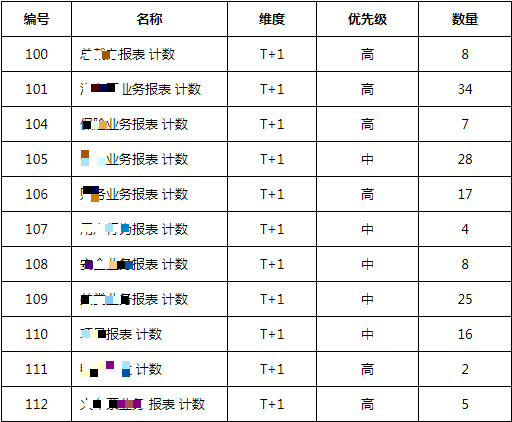
目前公司业务报表情况统计如下:
四、利剑之二 GOLDENGATE
随着公司业务数据的不断增长,业务数据种类越来越多,领导对各类数据整合的要求也越来越高,数据中心能否及时对实时数据深层次的挖掘、分析?已成为重要一环,目前面临的刺手问题是数据的实时性。
基于数据的可靠性、实时性等要求,我们开始尝试 Oracle 下 GoldenGate 产品,先简单介绍 GoldenGate 产品。
2009 年被 Oracle 收购,成为 Oracle 在实时数据集成,数据复制和数据高可用性领域的战略性产品。
跨异构环境,对系统负载影响很低,对交易型数据做实时抓取、路由、转换和传递。
和其他产品关键差异点 :
性能:非侵入式、低影响和亚秒级的延迟
弹性、可扩展:开放和模块化的架构,支持异构数据源和目标
可靠:保持交易事务的完整性 ,对中断和失败容忍度高
从官方找了二张 goldengate 的工作流程图:
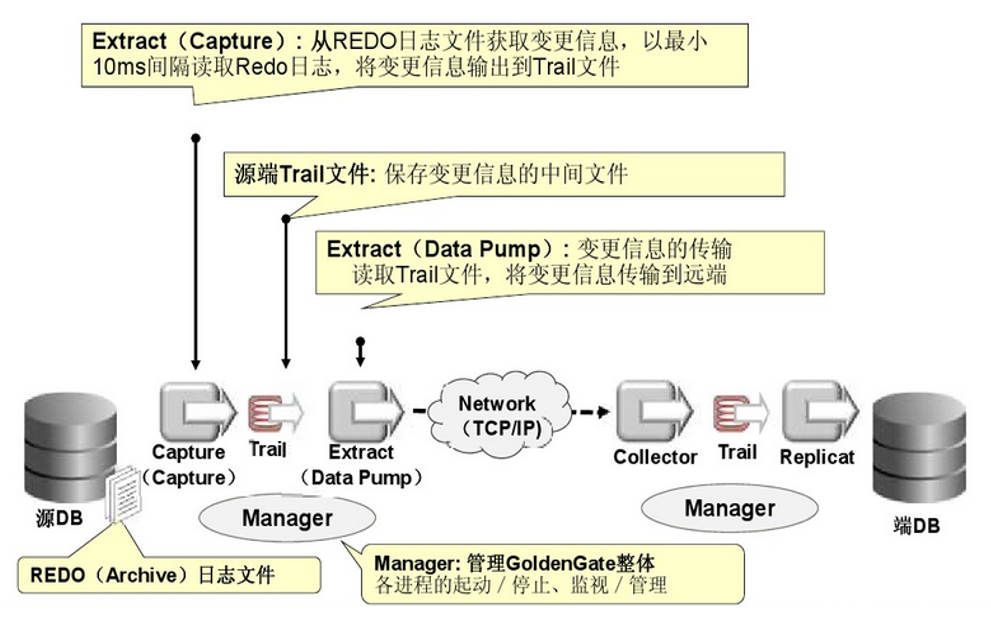
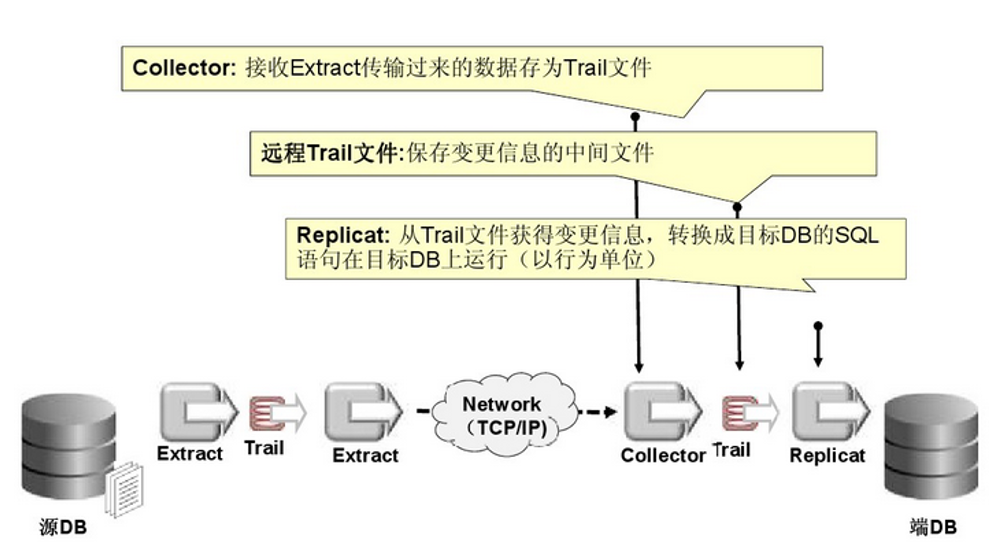
作为 ORACLE 铁粉的我,我相信它的实力。
曾经有过这么一段故事,有点久了,希望不会影响您的判断,有一丁点参考价值,我都开心。在 2014 年 5 月左右,跟 ORACLE 工程师 James 经过 2 周的时间,共同完成了对 oracle goldengate 同步工具(产品)的测试工作,文档《江苏某支撑平台 oracle goldengate 同步工具测试用例_v1.3》。

在测过过程中发现一些性能瓶颈,如下:
Analyz 操作分析表不能同步,需要在目标端手动执行。
没有主键和唯一索引的大表的 update、delete 操作,目标端执行时间较长,对某业务表(表大小 53G)进行 130 万条记录删除,目标端执行 8 小时以上(速度相差近 300 倍)。
在数据校验测试中,有主键和唯一建的表与无主键和唯一建的表,在数据量基本相同情况下,速度相差 6 倍以上。
业务高峰期 OGG 软件后台进程消耗 CPU 资源情况如下:
一个复制进程要消耗 4%CPU;一个抽取进程要消耗 3%CPU;
目标端开启 8 个复制进程时,cpu 消耗 36%左右,开启 4 个复制进程时,cpu 消耗 20%左右。
废话少说,开始我们的介绍,首先了解一下数据库基础环境。

主要的实施步骤
源端/OGG 为共享文件目录。
源端在 dataguard 中备库某一节点上部署 Manager、Extract、DataPump 进程。
在目标端节点上部署 Manager、Replicat 进程。
说明:源端使用 ASM 存放数据文件或日志文件,必须使用 SYS 用户登录 ASM 实例,在源端 extract 参数文件中要配置:
经过 1~2 个月的反复测试和验证过程中,在 DDL/DML 同步、断点续传、实时性、数据安全性等取得了很好的效果,尤其是在备库节点承担了 OGG 抽取进程的所有消耗,对主库基本无影响下进行的,也满足了数据中心对数据的实时性的要求。花了将近半年的时间,在数据中心的大力协助下,我们成功的把 Kettle 上 300 多张核心业务的表迁移到 OGG 上,丰富了多维度的报表开发,实时报表也上线了,管理后台的财务报表也计划从业务库迁移至数据仓库。这下,大家都开心了,是不是可以“假装友好的”拥抱一下,开个玩笑,哈哈!
如下图所示,分别部署了 6 个抽取进程、投递进程和复制进程。

对于百万级以下新增表同步,基本做到在线实施。当然,期间 replicat 进程会出现大量 Error ORA-01403: no data found 的错误,导致 replicat 进程 ABENDING,一般选择业务低峰期,通过 skiptransaction 后,手动补齐差异数据来实现。
不知不觉中,dataguard 已经上线了 1 年多,一直高效、稳定的执行他的职责。因此,我们还上了异构平台的数据同步(Oracle->mysql),如天眼系统数据同步、对账系统数据同步、火车票项目数据同步等。
五、小插曲
当然也出现过小插曲,2019 年 6 月左右上线的新增城市站点项目,给我们带来了不少困惑,项目上线后,replicat 出现数据延时,从 1 小时积压到 10 多小时,突然感觉 replicat 进程 HANG 了,而且是所有的 replicat 进程都不工作了。 通过目标端 info repyw2、send repyw2,status,源端 send extyw2, showtrans 等命令,发现 RBA 刷新非常慢, 存在长事务。于是组织相关的研发人员讨论,战火开始了,您懂得。
通过对代码的排查,发现新增站点处理流程中加入事务管理,而且在调度中通过 city_id 字段采用并发机制,反复对某城市站点表中 SYNC_FLAG 字段更新(业务逻辑有点复杂,此处省略了),导致了处理未提交事务。我们内部初步认为是长事务导致 replicat 进程 HANG ,造成数据延时。通过 mos 找到蛛丝马迹,Goldengate 12.1.2 Integrated Replicat Appears To Hang when Applying a transaction against an 11.2.0.4 database (Doc ID 1609690.1)。
经过多次跟研发沟通,研发同意在新增站点处理流程取消事务管理,引进了中间表进行改造,等业务逻辑测通后,且降低和控制并发(从 300 降到 50,30,10)的情况下,再次上线,发现问题依旧,但是数据延时由 10 多小时降到 1 小时 30 分钟左右,期间加入提升 replicat 进程性能的批处理进程模式 BATCHSQL。期间通过业务日志系统发现部分城市站点出现了 ORA-08103 对象不存在错误。
此时,我多想在 ORACLE support 上开个 SR,寻求 ORACLE 的帮助啊!无奈,只能打消这念想,继续前行…
关键的一步,分两种思路走
第一,继续优化业务逻辑,结合 ORA-8103 触发场景,我们暂且用 DELETE 代替了 TRUNCATE,优先避免错误发生,先不考虑 DELETE 效率低下,以及带来高水位问题。
第二,我们对新增站点处理流程进行存储过程的改写,采用事务类型的临时表来代替中间表。此处,应该有掌声,这是同事张春蕾的杰作,当然,也少不了研发同事的大力协作。有兴趣的可以提供该过程的代码。
等再次上线后,成功的解决了 replicat 进程 HANG,数据延时等问题,不想再赘述枯燥地细节,当然有兴趣者,我们可以一起探讨,谢谢!
六、总结
结束了吗?
结束了,我反问,是不是快了点(尴尬了)…
严肃一点,再来一次,真的结束了吗?
没有。从理论上说,文章结束了,但从实践上说,还没有,我们才刚开始…
这不是废话嘛!
…
…
…
好了,言归正传,我来总结和展望一下吧。
公司数据平台基于 Kettle+Azkaban 和 GOLDENGATE 两大利器,基本覆盖了公司内部各个业务线,目前能够满足绝大部分业务的数据同步需求,实现业务 DB 数据准确、高效地入仓。
而对业务服务类的日志数据(Log)入仓的部分又是另一个课题,卖个关子,公司有一套稳定的 HADOOP 集群平台,通过 flume、kafka、spark 等技术解决了公司大部分用户行为的分析需求, 但是,重点来了,对于两者的数据整合、后续构建高可用容灾等,我们不得不又面临的重要难题,也许分布式架构的 NEWSQL(TIDB,小强 DB 等)是我们下一站,加油!我们才真正的开始…

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论 2 条评论