

编者按
ClickHouse自从2016年开源以来,在数据分析(OLAP)领域火热,各个大厂纷纷跟进大规模使用。百分点在某国家级项目中的完成了多数据中心的ClickHouse集群建设,目前存储总量超10PB,日增数据100TB左右,预计流量今年会扩大3倍。本文是结合百分点在前期设计中的经验对ClickHouse做的整理,其中,第二章节最佳实践部分是基于我们的业务场景以及数据规模,经过大量的测试及总结后得到的结论,并且充分保证了整个系统日后的稳定运行,极具参考意义。
目录
ClickHouse 介绍
特点
适用场景
核心概念
百分点最佳实践
部署安装
服务器的选择
分布式集群
表的创建
数据的写入
业务查询
跨中心访问
最佳参数实践
集群监控
版本升级
附常用引擎
MergeTree
ReplacingMergeTree
SummingMergeTree
Replicated*MergeTree
Distributed
ClickHouse 是“战斗民族”俄罗斯搜索巨头 Yandex 公司开源的一个极具"战斗力"的实时数据分析数据库,是面向 OLAP 的分布式列式 DBMS,圈内人戏称为“喀秋莎数据库”。ClickHouse 简称"CH",但在中文社区里大家更偏爱“CK”,反馈是因为有“AK”的感觉!与 Hadoop、Spark 这些巨无霸组件相比,ClickHouse 很轻量级,其特点:列式存储数据库,数据压缩;关系型、支持 SQL;分布式并行计算,把单机性能压榨到极限;高可用;数据量级在 PB 级别。
适用场景从社区分享的案例看主要有以下 3 类:日志数据的行为分析,标签画像的分析,数据集市层分析。百分点除了以上应用场景应用外,还作为存储引擎集成在了产品内部,应用于知识图谱作为本体数据存储,及标签数据的存储引擎等。
绝大多数请求都是用于读访问
表很“宽”,即表中包含大量的列
在处理单个查询时需要高吞吐量
每次查询中大多数场景查询一个大表
查询结果显著小于数据源,即数据有过滤或聚合
在使用 ClickHouse 之前我们需要明确一些核心概念,在此我们梳理了五个概念进行分享:
(1)表引擎(Engine)
表引擎决定了数据在文件系统中的存储方式,常用的也是官方推荐的存储引擎是 MergeTree 系列,如果需要数据副本的话可以使用 ReplicatedMergeTree 系列,相当于 MergeTree 的副本版本,读取集群数据需要使用分布式表引擎 Distribute。常用的引擎见【附常用引擎】的内容。
(2)表分区(Partition)
表中的数据可以按照指定的字段分区存储,每个分区在文件系统中都是都以目录的形式存在。常用时间字段作为分区字段,数据量大的表可以按照小时分区,数据量小的表可以在按照天分区或者月分区,查询时,使用分区字段作为 Where 条件,可以有效的过滤掉大量非结果集数据。
(3)分片(Shard)
一个分片本身就是 ClickHouse 一个实例节点,分片的本质就是为了提高查询效率,将一份全量的数据分成多份(片),从而降低单节点的数据扫描数量,提高查询性能。这里先埋一个问题,当其中一个分片查询出现异常情况,我们如何处理呢?选择 1 返回异常;选择 2 跳过异常节点;详情见【参数实践】的内容。
(4)复制集(Replication)
简单理解就是相同的数据备份,在 ClickHouse 中通过复制集,我们实现了保障数据可靠性外,也通过多副本的方式,增加了 ClickHouse 查询的并发能力。这里一般有 2 种方式:1.基于 ZooKeeper 的表复制方式;2.基于 Cluster 的复制方式。由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑 ZooKeeper 的表复制方案。
(5)集群(Cluster)
可以使用多个 ClickHouse 实例组成一个集群,并统一对外提供服务。
百分点最佳实践
部署安装
(1)部署包的获取
ClickHouse 官方并没有提供 RPM 安装包,这里就为大家提供一个标准渠道。资源地址:https://packagecloud.io/Altinity。页面提供 2 个目录:

ClickHouse 目录下多为测试版更新,更新速度快;clickhouse-altinity-stable 目录为稳定版发布目录。
(2)部署包说明
ClickHouse 安装部署需要四个安装包:
clickhouse-client.rpm
clickhouse-common-static.rpm
clickhouse-server.rpm
clickhouse-server-common4.rpm
(3)部署方式
下载安装包时要对应版本下载四个安装包,将四个安装包拷贝到统一目录下,执行 rpm -ivh * 即可完成安装。
安装完成后的主要目录以及文件说明:
/etc/clickhouse-server:配置文件目录,包括:config.xml 和 users.xml
/etc/clickhouse-client:客户端配置文件目录
/var/lib/clickhouse:默认数据目录
/var/log/clickhouse-server:默认日志目录
/etc/init.d/clickhouse-server:启动 shell 脚本
/etc/security/limits.d/clickhouse.conf:最大文件打开数的配置
/etc/cron.d/clickhouse-server:定时任务配置,默认没有任务
/usr/bin/clickhouse-client:clickhouse 客户端
服务器的选择
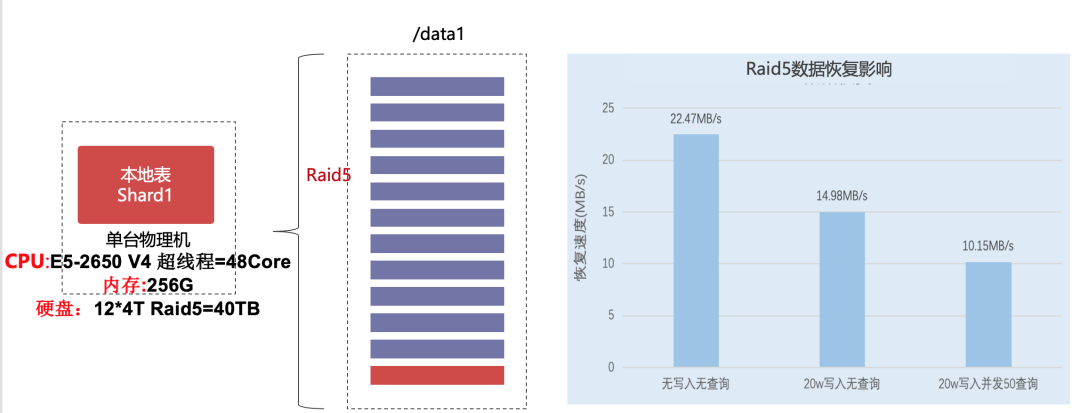
如上图,是我们的线上服务器情况,ClickHouse 查询使用并行处理机制,对 CPU 和内存的要求还是比较高的。不建议单台机器上部署多个节点,同时也要求 ClickHouse 节点与集群中 ZooKeeper 节点分开。防止高负载下相互影响。
由于当时使用的 ClickHouse 版本不支持多数据盘,所以选择一个合适的 Raid 方式也是很多人关心的问题,这里我们直接建议 Raid5,注意配置热备盘,这样无论从磁盘 IO,数据可靠性,数据恢复,及运维复杂度来说都提供了很好的保障。这里也给出了 Raid5 情况下的磁盘恢复的影响,供大家参考。
此外, 19.15 版本开始,ClickHouse 开始实现多卷存储的功能。它具有多种用途,其中最重要的用途是将热数据和冷数据存储在不同类型的存储中。这种配置被称为分层存储,如何很好的利用多卷存储能力,实现结合业务实现分层存储,也期待大家能分享自己的经验。
分布式集群
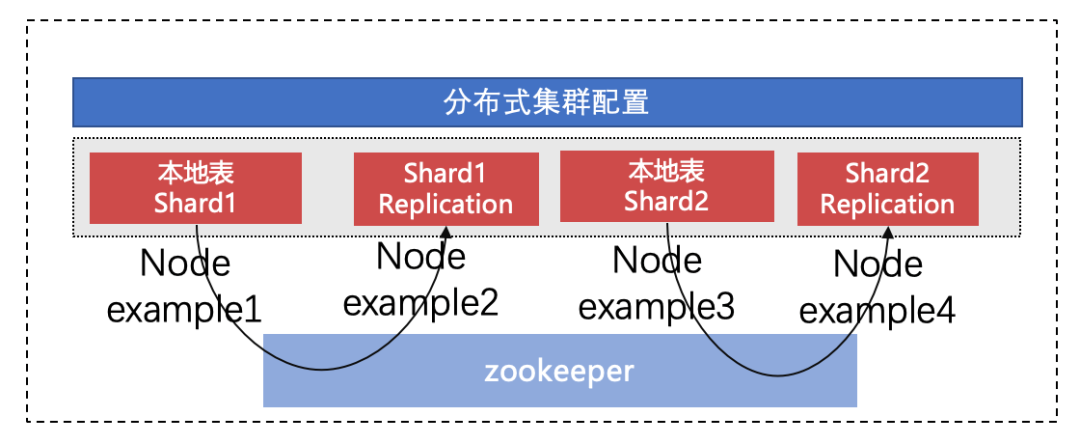
图 1 分布式集群示例

图 2 分片和副本关系示例
如【图 1、图 2】,ClickHouse 分布式集群有 4 个节点,2 个 Shard,副本数为 2。其中节点 example1,example2 属于同一 Shard,互为副本,他们的数据一致。example3,example4 属于同一 Shard。查询时,分布从 2 个 Shard 中随机取一个节点进行访问。其中任何单节点异常时,写入和查询都能保障数据完整性,高可用,业务无感知。
ClickHouse 的分布式也是一个有意思的设计方式,多个节点部署完成后,节点与节点之间并没有联系。通过 ClickHouse 集群的配置文件来实现,即节点与节点之间通过配置文件来形成成集群,配置中包含集群的节点信息,复制节点,分片节点,同构成一个 Cluster。
这样就形成了一个有意思的现象。我们可以抽象为:“集群定义节点,和节点关系,节点不知道集群”。这样一个引用关系,表现为 ClickHouse 的分布式在使用上就很灵活。
举个例子,一个集群里有 30 节点,我可以挑选其中 2 个配置整个集群的分布式关系,这样你会发现每个节点都是独立的,并不知道整个集群的全貌,集群的调整我只要关注 2 个节点的配置就行。包括基于之上的,数据安全,外部访问控制等等。
如上,从高可用的角度,我们默认都是采用分布式集群方式,数据做分片,保证数据写入不中断。数据副本提供可靠性,同时提升并发查询能力。
集群配置
有四个节点,example1、example2、example3、example4,可以在 config.xml 中配置,配置文件中搜索 remote_servers,在 remote_servers 内即可配置字集群,也可以提出来配置到扩展文件中。incl 属性表示可从外部文件中获取节点名为 clickhouse_remote_servers 的配置内容。
通常,我们采用扩展文件的方式来配置集群,首先,在 config.xml 文件中添加外部扩展配置文件 metrika.xml 的配置信息,在 config.xml 文件中加入以下内容允许使用扩展文件 metrika.xml 来配置信息。
然后,在/etc/clickhouse-server 下新建 metrika.xml 文件,并且插入以下内容。
说明:
clickhouse_remote_servers 与 config.xml 中的 incl 属性值对应;
cluster_with_replica 是集群名,可以自定义;
Shard 即为数据分片;
internal_replication=true 这个参数和数据的写入,自动复制相关。从生产环境角度考虑,我们都是复制表,通过本地表写入,这里配置 true 就好。 不推荐也不需要考虑其他情况 ;
macros 是使用复制引擎时指定的 ZooKeeper 路径中占位符替换的信息。(注意这里的配置在创建 Distribute 表时会用到,见【表的创建】,注意这里不同的 shard 和 replica 需要区分开来,通常集群中的每个节点都不一样的;
ZooKeeper-servers 来同步数据,指定当前集群的 ZooKeeper 信息即可;
clickhouse_compression 数据的压缩。
表的创建
我们这里以有副本模式的数据写入为例,首先在每一个节点创建本地表,可以到每个实例上运行一次建表语句。
(1) 创建本地表
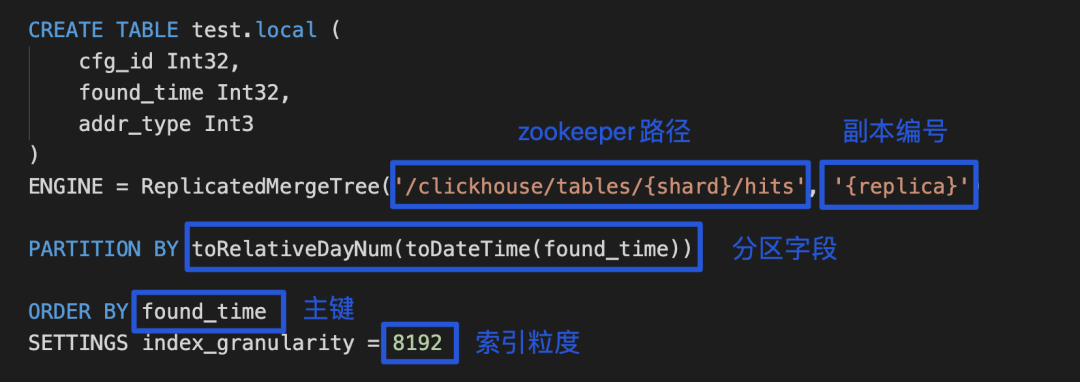
/clickhouse/tables/{shard}/test:代表的是这张表在 ZooKeeper 上的路径。即配置在相同 Shard 里面的不同 replica 的机器需要配置相同的路径,不同 Shard 的路径不同;
{replica}:分片的名称,可以理解是机器名,即需要每台机器都不同;
集群的配置,{shard}{replica}配置在配置文件 metrika.xml 中。
此时,将 internal_replication 设置为 true,这种配置下,写入不需要通过分布式表,而是将数据直接写入到每个 Shard 内任意的一个本地表中,如图所示。
(2)创建分布式表
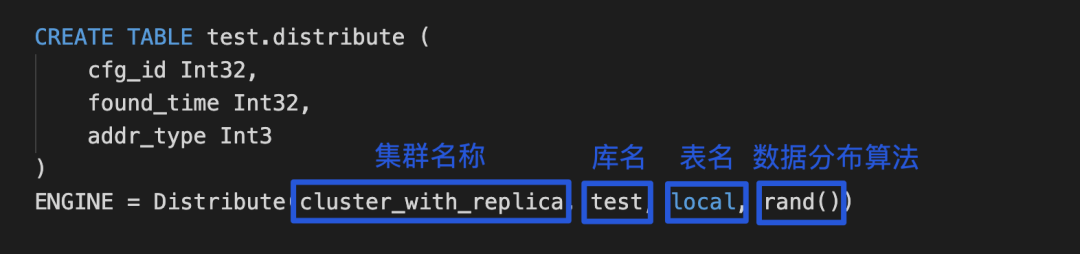
我们只借助于分布式表提供分布式查询能力,与数据写入无关,类似创建 DB 的 View 命令,所以这里只需要在提供查询入口的机器上创建,并不一定在所有机器上创建。
(3)借助集群的指令
oncluster {cluster_name} 这个指令使得操作能在集群范围内的节点上都生效。这里使用类似 create table xxx oncluster cluster_name ENGINE = ReplicatedMergeTree()。
在任意一个节点上运行,ClickHouse 会根据集群里面配置的分片信息在每一个节点上将表格创建好。有些日常批量维护的命令可以通过类似方式执行。
如果需要通过此方式进行维护,需要注意维护一个专门用户发送集群指令的节点列表。
实际生产运维中,我们并不推荐集群指令的方式,建议通过运维的方式,从管理规范上,准备日常维护的批量脚本,配置文件的分发和命令的执行,从操作机上,使用脚本批量远程登陆执行。
数据的写入
禁止分布式写入,采用本地表写入。
社区很多伙伴在分享时,也都提到了禁止使用分布式表写入,我们也一样。
禁止使用的原因是需要设计及减少 Part 的生成频率,这对整个集群的稳定性和整体性能有着决定的作用,这个在之前我司的分享中曾经介绍过,我们控制批次的上线和批次的时间窗口,保障写入操作对每个节点的稳定压力。
这里也分享下我们在做评估写入稳定性测试的结果,作为大家可借鉴的评估思路,其本质是平衡好合并速度和 Part 数量的关系,一定是需要相对均衡的。
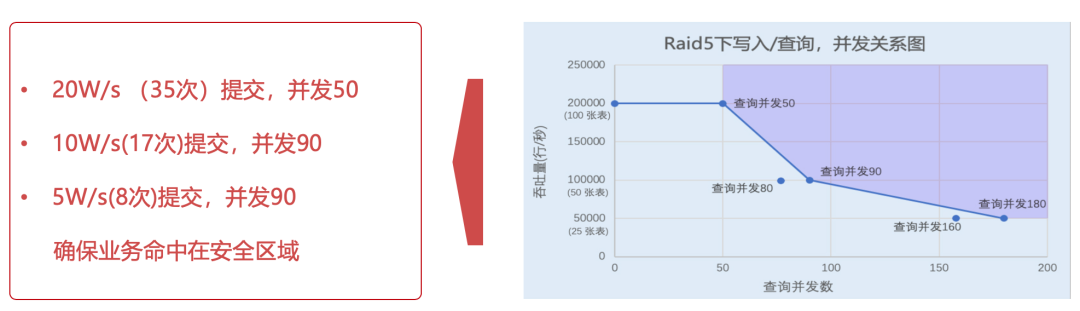
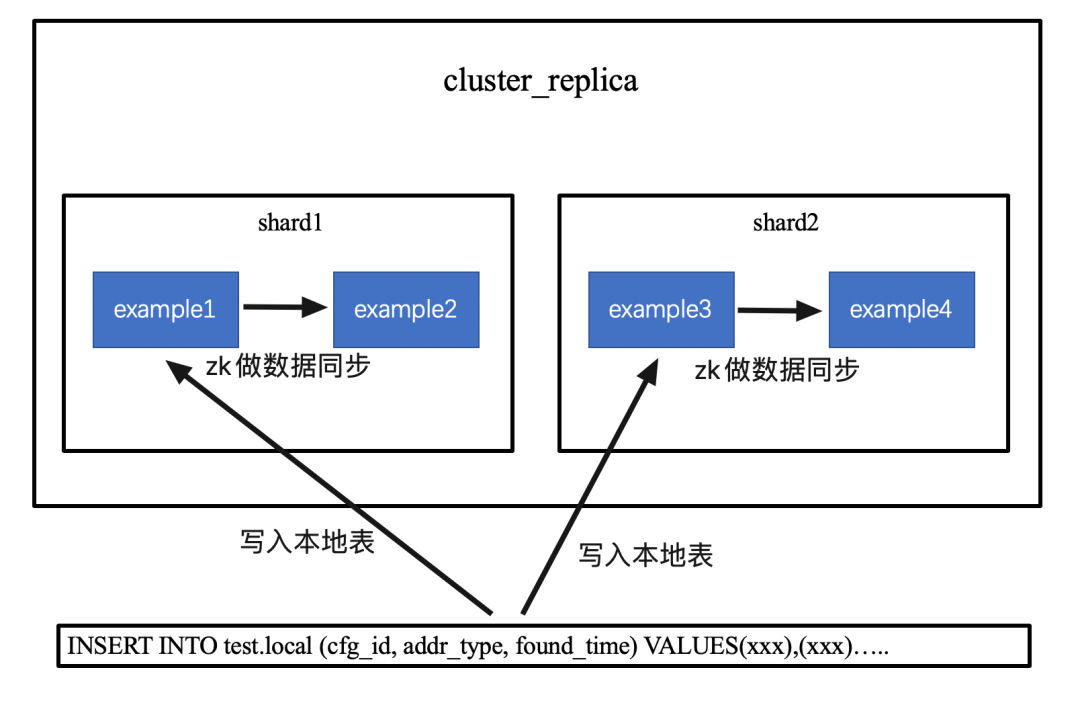
(1)写本地表
数据写入时,可以由客户端控制数据分布,直接写入集群中 ClickHouse 实例的本地表,也可以通过 LB 组件(如 LVS,Nginx)进行控制。
(2)写分布式表
数据写入时,先写入集群中的分布式表下的节点临时目录,再由分布式表将 Insert 语句分发到集群各个节点上执行,分布式表不存储实际数据。
ClickHouse 在分布式写入时,会根据节点数量在接收请求的节点的下创建集群节点的临时目录,数据(Insert 语句)会优先提交的本地目录下,之后同步数据到对应的节点。此过程好处是提交后,数据不会丢失。我们模拟同步过程中节点异常,重启后数据也会自动恢复,如果你的数据量及集群压力并不大,分布式也可以认为是一种简单的实现方式。
(3)写入副本同步
在集群配置中,Shard 标签里面配置的 replica 互为副本,将 internal_replication 设置成 true,此时写入同一个 Shard 内的任意一个节点的本地表,ZooKeeper 会自动异步的将数据同步到互为副本的另一个节点。
业务查询
业务查询入口要保障查询高可用,需要提供负载均衡和路由的能力。一些大厂都会有自己的 LB 基础设施。其实大家可以能够观察 ClickHouse 提供两个网络端口分别是:
HTTP 默认 8123;
TCP 默认 9000;
ClickHouse 的 JDBC 客户端是通过 HTTP 的方式与 ClickHouse 进行交互的,我们可以判断场景的可以基于 HTTP 协议做负载均衡,路由的中间件是可以满足需求的,这样我们的选择其实就有很多了。基于传统运维常见中间件的如:LVS,Nginx,HAProxy 都有相关的能力,这里我们选用了 Nginx。
我们基于它实现 2 个目的:(1)负载均衡能力(2)采集请求响应日志。
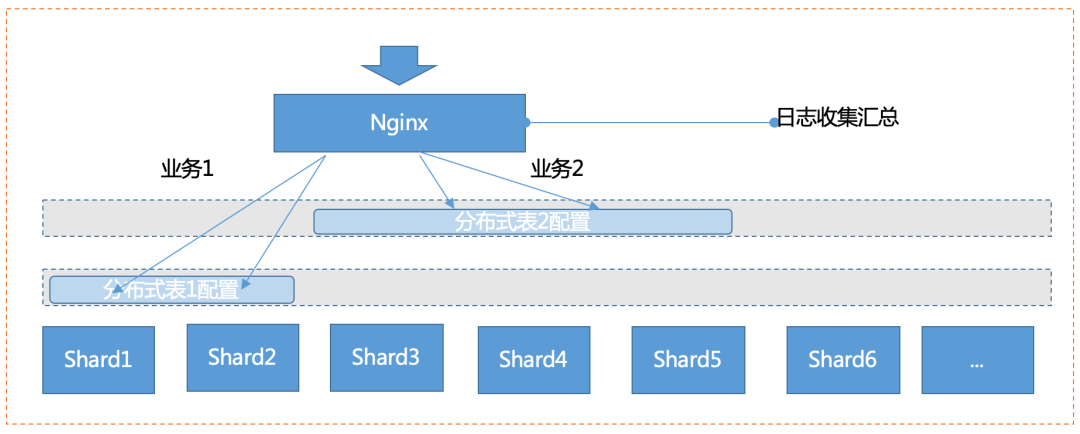
大家可能奇怪第 2 个目的,ClickHouse 本身有自己的查询响应日志,为啥还要单独采集。原因很简单,我们把 ClickHouse 本身的日志定位为做具体问题,排查与分析的日志,日志分散在了集群内部,并且分布式的查询转换为本地 SQL 后作为集群的系统行监测,我们认为并不合适。我们通过 Nginx 日志分析线上业务的请求情况,并进行可视化展现包括业务使用情况,慢查询,并发能力等等,如果确实有需要追溯的场景时候,才会使用到 ClickHouse 的自身日志。
同时我们发现社区目前也提供了 CHProxy 作为负载均衡和 HTTP 代理,从我们角度更愿意选择一个简单,熟悉的。
需要注意的是,我们只针对提供查询入口的实例配置分布式表,然后通过 Nginx 进行代理。由 Nginx 将请求路由到代理的 ClickHouse 实例,这样既将请求分摊开,又避免了单点故障,同时实现了负载均衡和高可用。并且我们在生产环境中也根据不同的业务配置路由入口,实现访问的业务和负载隔离。
Nginx 转发后的节点(根据负载配置多个),使用 Distribute 表引擎作为集群的统一访问入口 ,当客户端查询分布式表时,ClickHouse 会将查询分发到集群中各个节点上执行,并将各个节点的返回结果在分布式表所在节点上进行汇聚,将汇聚结果作为最终结果返回给客户端。
跨中心访问
在我们的业务中,需要实现跨数据中心的分析,可以利用 ClickHouse 的灵活配置化分布式特性,将多数据中心的所有集群的分片都添加到一个 ClickHouse 实例中,并在该 ClickHouse 实例上创建分布式表,作为客户端查询的统一入口。如下图所示。
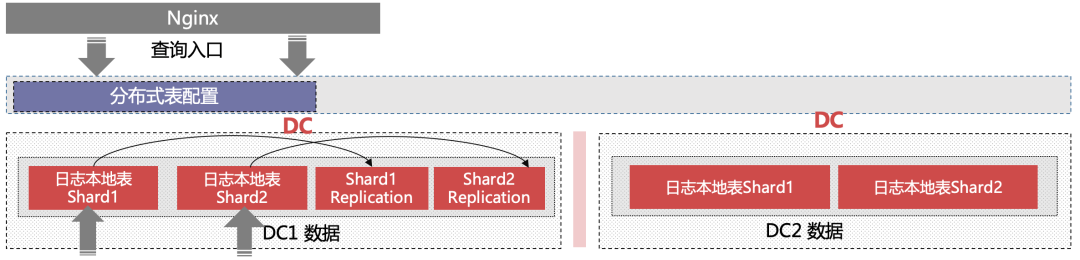
当客户端查询该分布式表时,ClickHouse 会将查询分发到各个数据中心的所有分片上,并将各个分片的返回结果在分布式表所在配置的节点上进行汇聚,汇聚结果作为最终结果返回给客户端,需要注意的是如果数据量巨大会给汇聚节点造成巨大的压力,所以要平衡好数据量与服务器硬件资源之间的关系,才可以保证系统的稳定性,从业务的安全来说,也只有对外的入口节点知道整个集群的信息。
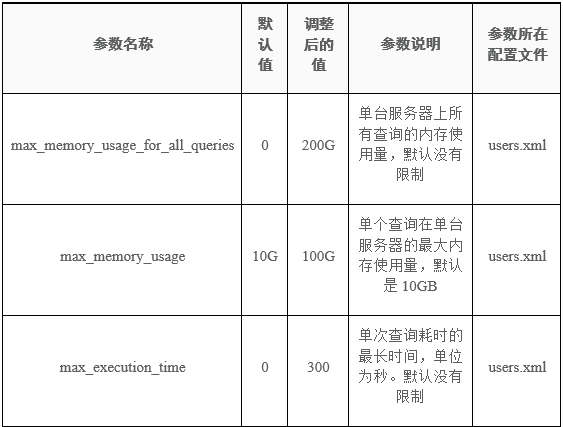
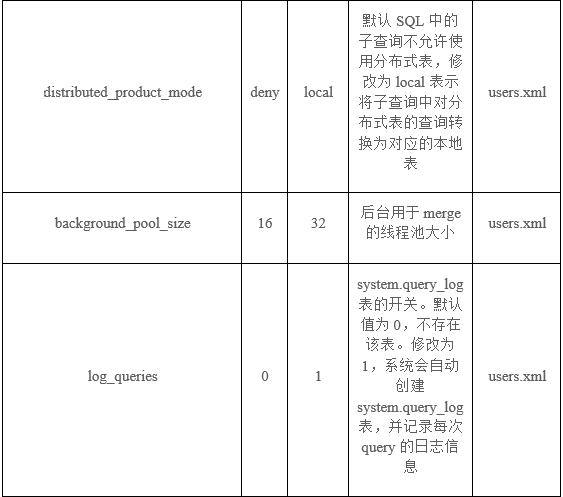
最佳参数实践
在实际项目中,无论是写入、查询以及保证集群稳定运行,需要配置一些参数来维护集群的状态,下属表格中的参数是我们根据依据线上业务总结出来的最佳实践参数。如果大家基于 ClickHouse 的生产使用,我们希望使用者理解其中每一个参数的含义,和配置的目的,社区的交流过程发现很多同行中经常遇到一些问题,实际都可以从表格中得到答案。
请注意, 其中很多参数配置是对集群的稳定性有着决定性的作用 。在理解的基础上,大家才能结合自己的硬件和业务设置自己的最佳参数实践。

集群监控
ClickHouse 集群监控通常使用 ClickHouse Exporter + Prometheus +Grafana 方式, Exporter 负责信息采集,时序数据库 Prometheus 存储相关日志,并用 Grafana 进行展现, Grafana 基于 ClickHouse 的监控主题可以查询社区贡献的插件。
我们定义监控有 2 个维度:
(1)集群信息监控
这里主要是 ClickHouse 服务的指标,我们除了通过 Exporter 采集的数据进行展现外,大家可以选择合适的 Grafana 的主题同时自己也可以扩展通过 ClickHouse 直接访问系统的配置信息进行展示。
(2) 业务信息监控
这里我更想介绍的是业务信息的监控,详情见【业务查询】。我们通过 Nginx 额外收集所有访问日志,这些日志我们也同样存储到了 ClickHouse,基于这个我们进行了并发、响应时间、长尾查询相关的统计分析。
同时也针对业务表,进行配置了相关统计任务,统计信息存储与 ClickHouse 的统计表。
基于 Grafana 我们将这些业务信息进行了可视化展现。
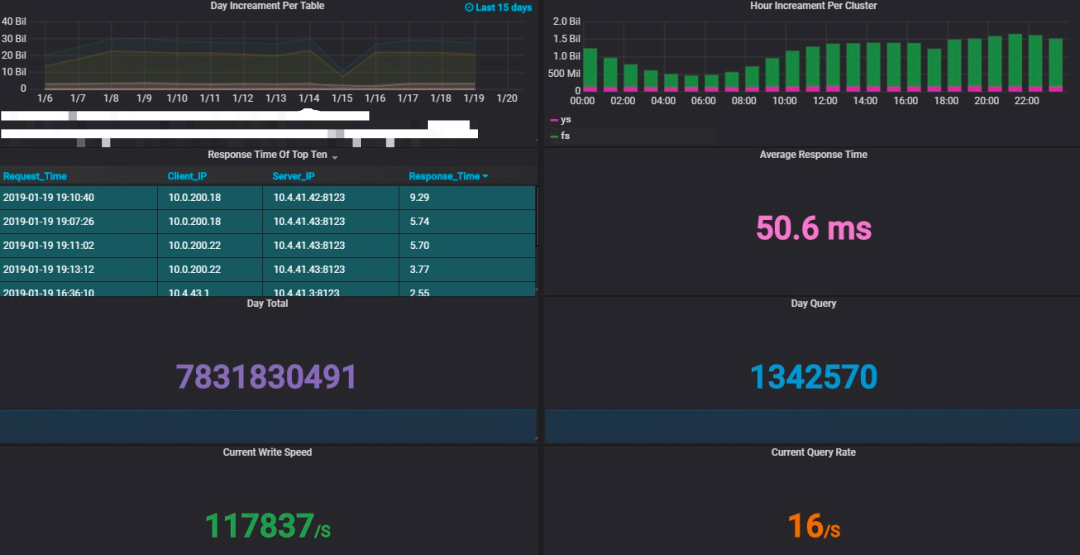
这里主要是 ClickHouse 服务的指标,我们除了通过 Exporter 采集的数据进行展现外,大家可以选择合适的 Grafana 的主题同时自己也可以扩展通过 ClickHouse 直接访问系统的配置信息进行展示,如图所示,为我们的一个监控页面,展示着集群的数据量变化以及其他业务信息。
版本升级
在数据模型版本兼容的情况下,可以使用如下方式升级版本
总体流程:
停止当前进程
然后卸载已安装的 ClickHouse 相关安装包
备份当前集群的配置文件 config.xml、metrika.xml、users.xml
安装新的安装包
使用备份的配置文件覆盖自动生成的文件
注意:
ClickHouse 正常部署完成有三个配置文件,分别是:
config.xml (基本配置)
metrika.xml (集群配置)
users.xml (用户以及限额相关配置)
卸载原版本后会将 users.xml 删除,并且将 config.xml 重命名为 config.rpmsave,所以 users.xml 要注意备份,可以先将 users.xml 重命名,这样就不会被删除。

升级过程:
(1)停止进程 ,查看已安装的 ClickHouse:rpm -qa | grep clickhouse
clickhouse-client-19.15.3.6-1.el7.x86_64
clickhouse-server-common-19.15.3.6-1.el7.x86_64
clickhouse-server-19.15.3.6-1.el7.x86_64
clickhouse-common-static-19.15.3.6-1.el7.x86_64
(2)卸载以上安装包
注意按照顺序卸载:
rpm -e clickhouse-client-19.15.3.6-1.el7.x86_64
rpm -e clickhouse-server-19.15.3.6-1.el7.x86_64
rpm -e clickhouse-common-static-19.15.3.6-1.el7.x86_64
rpm-e clickhouse-server-common-19.15.3.6-1.el7.x86_64
卸载完成后提示:
warning:/etc/clickhouse-server/config.xml saved as/etc/clickhouse-server/config.xml.rpmsave
此时/etc/clickhouse-server/下只剩两个配置文件,并且 config.xml 被重命名为 config.rpmsave,users.xml 被删除。(若 users.xml 有更改要,卸载前要注意备份)

(3)安装新版本
rpm -ivh *
此时/etc/clickhouse-server/下重新生成了新的 config.xml 与 users.xml

使用原来的 config.xml 替换新生成的 config.xml
rm -rf config.xml
mv config.xml.rpmsaveconfig.xml
使用用原来的 users.xml 替换新生成的 users.xml
rm -rf users.xml
mv users.xml.bakusers.xml
(4)启动 ClickHouse
serviceclickhouse-server start
附常用引擎
MergeTree
MergeTree 是 ClickHouse 中最强大的表引擎。在大量数据写入时数据,数据高效的以批次的形式写入,写入完成后在后台会按照一定的规则就行数据合并,并且 MergeTree 引擎家族还有很多扩展引擎*MergeTree,注意,Merge 引擎不属于*MergeTree 系列。
建表:
ENGINE—引擎名和参数。ENGINE = MergeTree(). MergeTree 引擎没有参数
PARTITION BY—分区键
ORDER BY—表的排序键
PRIMARY KEY—主键【默认情况下主键跟排序键(由
ORDER BY子句指定)相同】SAMPLE BY—用于抽样的表达式
SETTINGS—影响 MergeTree 性能的额外参数:
index_granularity—索引粒度。即索引中相邻『标记』间的数据行数。默认值,8192。
index_granularity_bytes—索引粒度,以字节为单位,默认值: 10Mb。
enable_mixed_granularity_parts—启用或禁用通过 index_granularity_bytes 控制索引粒度的大小。
use_minimalistic_part_header_in_zookeeper—数据片段头在 ZooKeeper 中的存储方式。如果设置了 use_minimalistic_part_header_in_zookeeper=1 ,ZooKeeper 会存储更少的数据。
min_merge_bytes_to_use_direct_io—使用直接 I/O 来操作磁盘的合并操作时要求的最小数据量。
merge_with_ttl_timeout—TTL 合并频率的最小间隔时间。默认值: 86400 (1 天)。
write_final_mark—启用或禁用在数据片段尾部写入最终索引标记。默认值:1(不建议更改)。
storage_policy—存储策略。
ReplacingMergeTree
该引擎和 MergeTree 的不同之处在于它会删除具有相同主键的重复项。数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。因此,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。同时 ReplacingMergeTree 在一定程度上可以弥补 ClickHouse 不能对数据做更新的操作。
建表:
合并的时候,ReplacingMergeTree 从所有具有相同主键的行中选择一行留下:
如果 ver 列未指定,选择最后一条。
如果 ver 列已指定,选择 ver 值最大的版本。
SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果主键的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度。
建表:
columns - 包含了将要被汇总的列的列名的元组。可选参数。
如果没有指定 columns,ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
Replicated*MergeTree
ReplicatedMergeTree
ReplicatedSummingMergeTree
ReplicatedReplacingMergeTree
ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree
ReplicatedVersionedCollapsingMergeTree
ReplicatedGraphiteMergeTree
副本是表级别的,不是整个服务器级的。所以,服务器里可以同时有复制表和非复制表。副本不依赖分片。每个分片有它自己的独立副本。要使用副本,需在配置文件中设置 ZooKeeper 集群的地址。需要 ZooKeeper 3.4.5 或更高版本。
例如:
Distributed
以上引擎都是数据存储引擎,但是该引擎-分布式引擎本身不存储数据,但可以在多个服务器上进行分布式查询。读是自动并行的。读取时,远程服务器表的索引会被使用。
建表:
分布式引擎参数:服务器配置文件中的集群名,远程数据库名,远程表名,数据分布策略。
致谢
在 ClickHouse 的学习、评测、应用及对集群的维护过程中,得到了来自同行以及 ClickHouse 中文社区,还有 ClickHouse 研发团队的巨大帮助,尤其感谢新浪高鹏的帮助,为我们解决使用过程中的难题提供了思路,同时还为我们的集群架构提出了很多非常有建设性的指导建议。
本文转载自公众号百分点(ID:baifendian_com)。
原文链接:
https://mp.weixin.qq.com/s/9S6DhDhv7lFbMaFScf137Q

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论