

一、背景
地图 App 的功能可以简单概括为定位,搜索,导航三部分,分别解决在哪里,去哪里,和怎么去的问题。高德地图的搜索场景下,输入的是,地理相关的检索 query,用户位置,App 图面等信息,输出的是,用户想要的 POI。如何能够更加精准地找到用户想要的 POI,提高满意度,是评价搜索效果的最关键指标。
一个搜索引擎通常可以拆分成 query 分析、召回、排序三个部分,query 分析主要是尝试理解 query 表达的含义,为召回和排序给予指导。
地图搜索的 query 分析不仅包括通用搜索下的分词,成分分析,同义词,纠错等通用 NLP 技术,还包括城市分析,wherewhat 分析,路径规划分析等特定的意图理解方式。
常见的一些地图场景下的 query 意图表达如下:
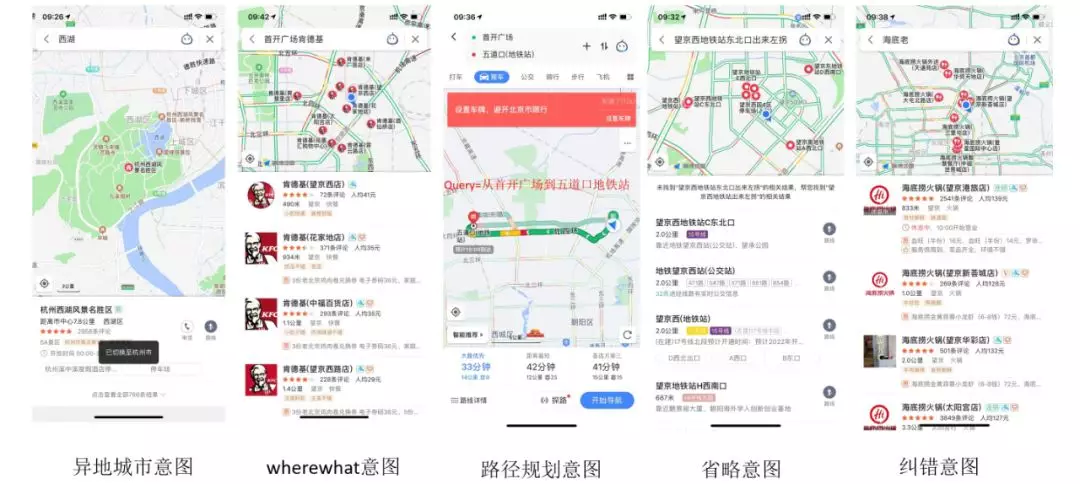
query 分析是搜索引擎中策略密集的场景,通常会应用 NLP 领域的各种技术。地图场景下的 query 分析,只需要处理地理相关的文本,多样性不如网页搜索,看起来会简单一些。但是,地理文本通常比较短,并且用户大部分的需求是唯一少量结果,要求精准度非常高,如何能够做好地图场景下的文本分析,并提升搜索结果的质量,是充满挑战的。
二、整体技术架构
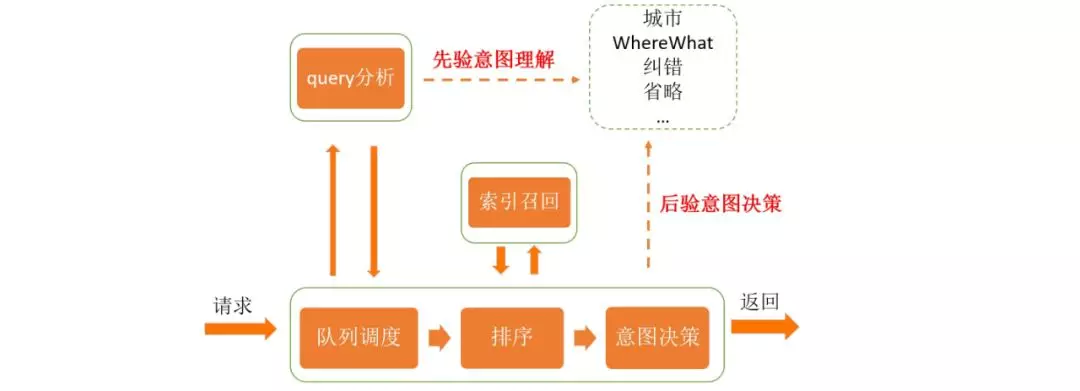
搜索架构
类似于通用检索的架构,地图的检索架构包括 query 分析,召回,排序三个主要部分。先验的,用户的输入信息可以理解为多种意图的表达,同时下发请求尝试获取检索结果。后验的,拿到每种意图的检索结果时,进行综合判断,选择效果最好的那个。
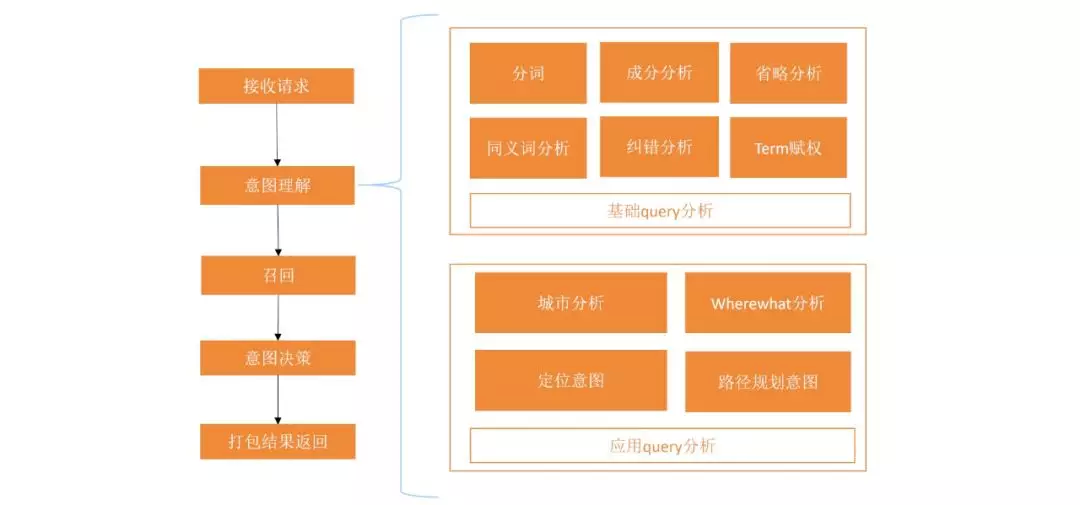
query 分析流程
具体的意图理解可分为基础 query 分析和应用 query 分析两部分,基础 query 分析主要是使用一些通用的 NLP 技术对 query 进行理解,包括分析,成分分析,省略,同义词,纠错等。应用 query 分析主要是针对地图场景里的特定问题,包括分析用户目标城市,是否是 where+what 表达,是否是从 A 到 B 的路径规划需求表达等。

整体技术演进
在地里文本处理上整体的技术演进经历了规则为主,到逐步引入机器学习,到机器学习全面应用的过程。由于搜索模块是一个高并发的线上服务,对于深度模型的引入有比较苛刻的条件,但随着性能问题逐渐被解决,我们从各个子方向逐步引入深度学习的技术,进行新一轮的效果提升。
NLP 领域技术在最近几年取得了日新月异的发展,bert,XLNet 等模型相继霸榜,我们逐步统一化各个 query 分析子任务,使用统一的向量表示对进行用户需求进行表达,同时进行 seq2seq 的多任务学习,在效果进一步提升的基础上,也能够保证系统不会过于臃肿。
本文就高德地图搜索的地理文本处理,介绍相关的技术在过去几年的演进。我们将选取一些点分上下两篇进行介绍,上篇主要介绍搜索引擎中一些通用的 query 分析技术,包括纠错,改写和省略。下篇着重介绍地图场景中特有 query 分析技术,包括城市分析,wherewhat 分析,路径规划。
三、通用 query 分析技术演进
3.1 纠错
在搜索引擎中,用户输入的检索词(query)经常会出现拼写错误。如果直接对错误的 query 进行检索,往往不会得到用户想要的结果。因此不管是通用搜索引擎还是垂直搜索引擎,都会对用户的 query 进行纠错,最大概率获得用户想搜的 query。
在目前的地图搜索中,约有 6%-10%的用户请求会输入错误,所以 query 纠错在地图搜索中是一个很重要的模块,能够极大的提升用户搜索体验。
在搜索引擎中,低频和中长尾问题往往比较难解决,也是纠错模块面临的主要问题。另外,地图搜索和通用搜索,存在一个明显的差异,地图搜索 query 结构化比较突出,query 中的片段往往包含一定的位置信息,如何利用好 query 中的结构化信息,更好地识别用户意图,是地图纠错独有的挑战。
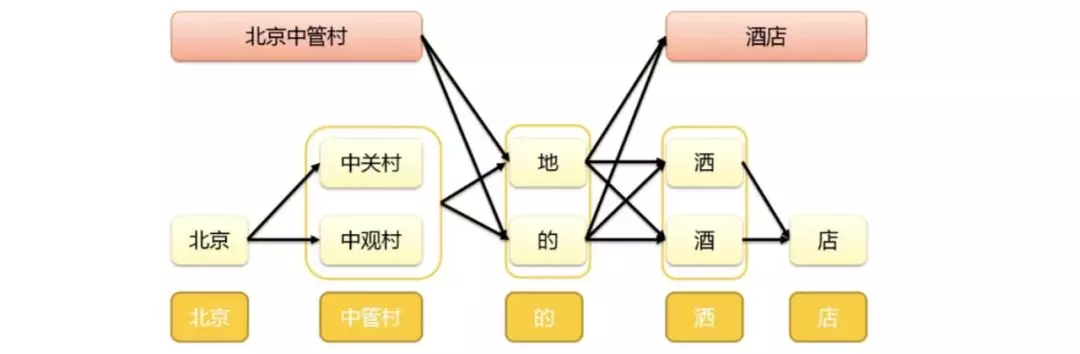
常见错误分类
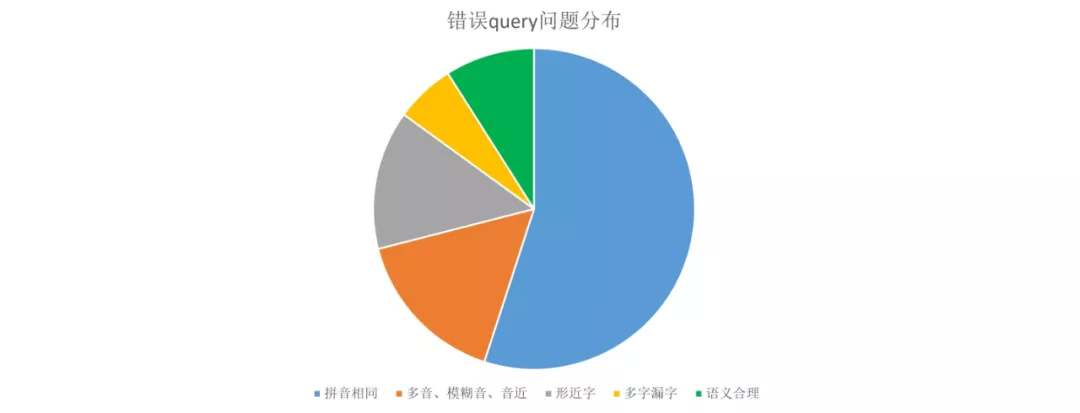
(1) 拼音相同或者相近,例如: 盘桥物流园-潘桥物流园
(2) 字形相近,例如: 河北冒黎-河北昌黎
(3) 多字或者漏字,例如: 泉州州顶街-泉州顶街
纠错现状
原始纠错模块包括多种召回方式,如:
拼音纠错:主要解决短 query 的拼音纠错问题,拼音完全相同或者模糊音作为纠错候选。
拼写纠错:也叫形近字纠错,通过遍历替换形近字,用 query 热度过滤,加入候选。
组合纠错:通过翻译模型进行纠错替换,资源主要是通过 query 对齐挖掘的各种替换资源。
组合纠错翻译模型计算公式:
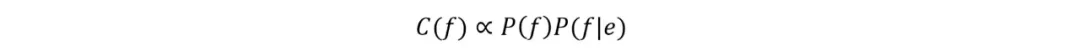
其中 p(f)是语言模型,p(f|e)是替换模型。
问题 1:召回方式存在缺陷。目前 query 纠错模块主要召回策略包括拼音召回、形近字召回,以及替换资源召回。对于低频 case,解决能力有限。
问题 2:排序方式不合理。纠错按照召回方式分为几个独立的模块,分别完成相应的召回和排序,不合理。
技术改造
改造 1:基于空间关系的实体纠错
原始的纠错主要是基于用户 session 挖掘片段替换资源,所以对于低频问题解决能力有限。但是长尾问题往往集中在低频,所以低频问题是当前的痛点。
地图搜索与通用搜索引擎有个很大的区别在于,地图搜索 query 比较结构化,例如北京市朝阳区阜荣街 10 号首开广场。我们可以对 query 进行结构化切分(也就是地图中成分分析的工作),得到这样一种带有类别的结构化描述,北京市【城市】朝阳区【区县】阜荣街【道路】10 号【门址后缀】首开广场【通用实体】。
同时,我们拥有权威的地理知识数据,利用权威化的地理实体库进行前缀树+后缀树的索引建库,提取疑似纠错的部分在索引库中进行拉链召回,同时利用实体库中的逻辑隶属关系对纠错结果进行过滤。实践表明,这种方式对低频的区划或者实体的错误有着明显的作用。
基于字根的字形相似度计算
上文提到的排序策略里面通过字形的编辑距离作为排序的重要特征,这里我们开发了一个基于字根的字形相似度计算策略,对于编辑距离的计算更为细化和准确。汉字信息有汉字的字根拆分词表和汉字的笔画数。

将一个汉字拆分成多个字根,寻找两个字的公共字根,根据公共字根笔画数来计算连个字的相似度。
改造 2:排序策略重构
原始的策略召回和排序策略耦合,导致不同的召回链路,存在顾此失彼的情况。为了能够充分发挥各种召回方式的优势,急需要对召回和排序进行解耦并进行全局排序优化。为此我们增加了排序模块,将流程分为召回和排序两阶段。
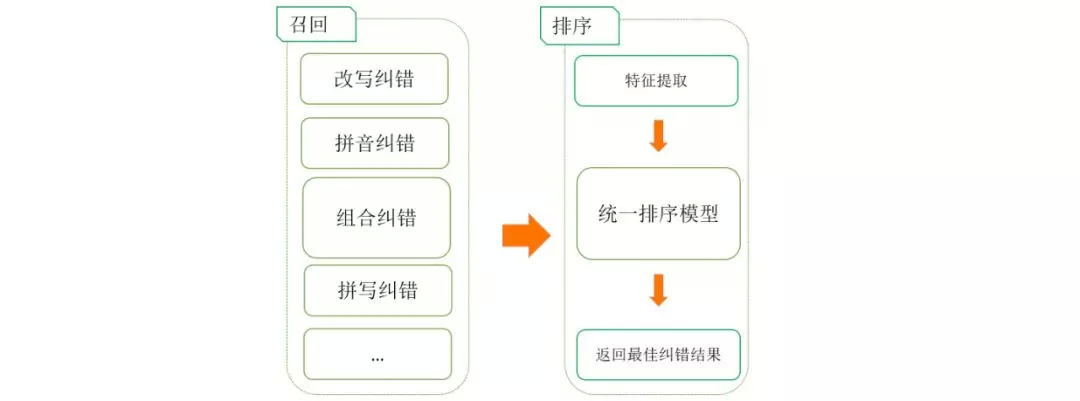
模型选择
对于这个排序问题,这里我们参考业界的实践,使用了基于 pair-wise 的 gbrank 进行模型训练。
样本建设
通过线上输出结合人工 review 的方式构造样本。
特征建设
(1) 语义特征。如统计语言模型。
(2) 热度特征。pv,点击等。
(3) 基础特征。编辑距离,切词和成分特征,累积分布特征等。
这里解决了纠错模块两个痛点问题,一个是在地图场景下的大部分低频纠错问题。另一个是重构了模块流程,将召回和排序解耦,充分发挥各个召回链路的作用,召回方式更新后只需要重训排序模型即可,使得模块更加合理,为后面的深度模型升级打下良好的基础。后面在这个框架下,我们通过深度模型进行 seq2seq 的纠错召回,取得了进一步的收益。
3.2 改写
纠错作为 query 变换的一种方式的召回策略存在诸多限制,对于一些非典型的 query 变换表达,存在策略的空白。比如 query=永城市新农合办,目标 POI 是永城市新农合服务大厅。用户的低频 query,往往得不到较好搜索效果,但其实用户描述的语义与主 poi 的高频 query 是相似的。
这里我们提出一种 query 改写的思路,可以将低频 query 改写成语义相似的高频 query,以更好地满足用户需求多样性的表达。
这是一个从无到有的实现。用户表达的 query 是多样的,使用规则表达显然是难以穷尽的,直观的思路是通过向量的方式召回,但是向量召回的方式很可能出现泛化过多,不适应地图场景的检索的问题,这些都是要在实践过程中需要考虑的问题。
方案
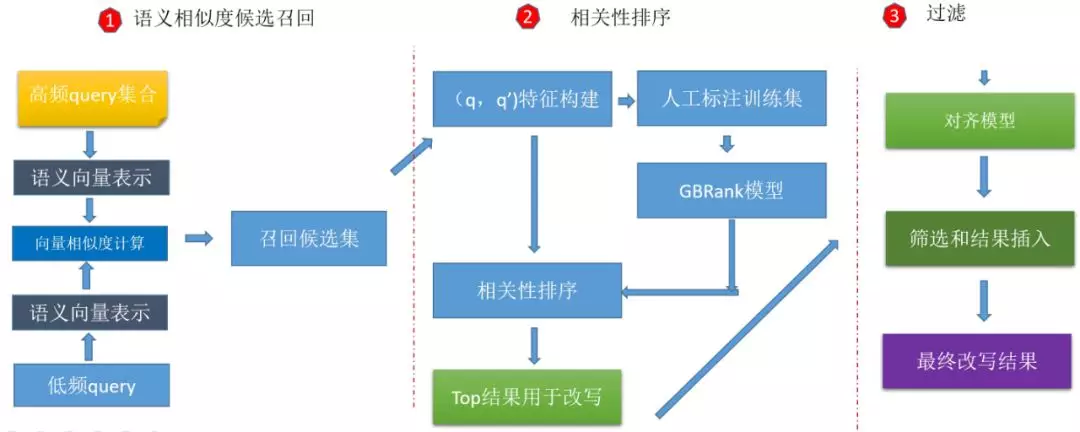
整体看,方案包括召回,排序,过滤,三个阶段。
召回阶段
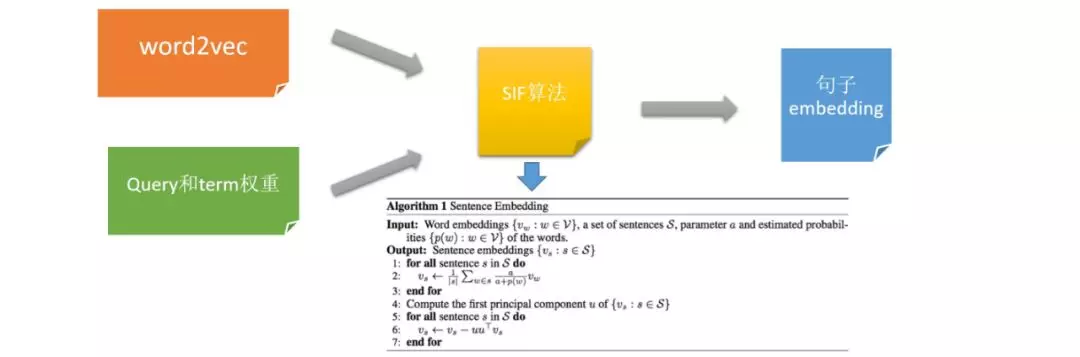
我们调研了句子向量表示的几种方法,选择了算法简单,效果和性能可以和 CNN,RNN 媲美的 SIF(Smooth Inverse Frequency)。向量召回可以使用开源的 Faiss 向量搜索引擎,这里我们使用了阿里内部的性能更好的的向量检索引擎。
排序阶段
样本构建
原 query 与高频 query 候选集合,计算语义相似度,选取语义相似度的 TOPK,人工标注的训练样本。
特征建设
基础文本特征
编辑距离
组合特征
模型选择
使用 xgboost 进行分数回归
过滤阶段
通过向量召回的 query 过度泛化非常严重,为了能够在地图场景下进行应用,增加了对齐模型。使用了两种统计对齐模型 giza 和 fastalign,实验证明二者效果几乎一致,但 fastalign 在性能上好于 giza,所以选择 fastalign。

通过对齐概率和非对齐概率,对召回的结果进行进一步过滤,得到精度比较高的结果。
query 改写填补了原始 query 分析模块中一些低频表达无法满足的空白,区别于同义词或者纠错的显式 query 变换表达,句子的向量表示是相似 query 的一种隐式的表达,有其相应的优势。
向量表示和召回也是深度学习模型逐步开始应用的尝试。同义词,改写,纠错,作为地图中 query 变换主要的三种方式,以往在地图模块里比较分散,各司其职,也会有互相重叠的部分。在后续的迭代升级中,我们引入了统一的 query 变换模型进行改造,在取得收益的同时,也摆脱掉了过去很多规则以及模型耦合造成的历史包袱。
3.2 省略
在地图搜索场景里,有很多 query 包含无效词,如果用全部 query 尝试去召回很可能不能召回有效结果。如厦门市搜"湖里区县后高新技术园新捷创运营中心 11 楼 1101 室 县后 brt 站"。这就需要一种检索意图,在不明显转义下,使用核心 term 进行召回目标 poi 候选集合,当搜索结果无果或者召回较差时起到补充召回的作用。
在省略判断的过程中存在先验后验平衡的问题。省略意图是一个先验的判断,但是期望的结果是能够进行 POI 有效召回,和 POI 的召回字段的现状密切相关。如何能够在策略设计的过程中保持先验的一致性,同时能够在后验 POI 中拿到相对好的效果,是做好省略模块比较困难的地方。
原始的省略模块主要是基于规则进行的,规则依赖的主要特征是上游的成分分析特征。由于基于规则拟合,模型效果存在比较大的优化空间。另外,由于强依赖成分分析,模型的鲁棒性并不好。
技术改造
省略模块的改造主要完成了规则到 crf 模型的升级,其中也离线应用了深度学习模型辅助样本生成。
模型选择
识别出来 query 哪些部分是核心哪些部分是可以省略的,是一个序列标注问题。在浅层模型的选型中,显而易见地,我们使用了 crf 模型。
特征建设
term 特征。使用了赋权特征,词性,先验词典特征等。
成分特征。仍然使用成分分析的特征。
统计特征。统计片段的左右边界熵,城市分布熵等,通过分箱进行离散化。
样本建设
项目一期我们使用了使用线上策略粗标,外包细标的方式,构造了万级的样本供 crf 模型训练。
但是省略 query 的多样性很高,使用万级的样本是不够的,在线上模型无法快速应用深度模型的情况下,我们使用了 boostraping 的方式,借助深度模型的泛化能力,离线构造了大量样本。
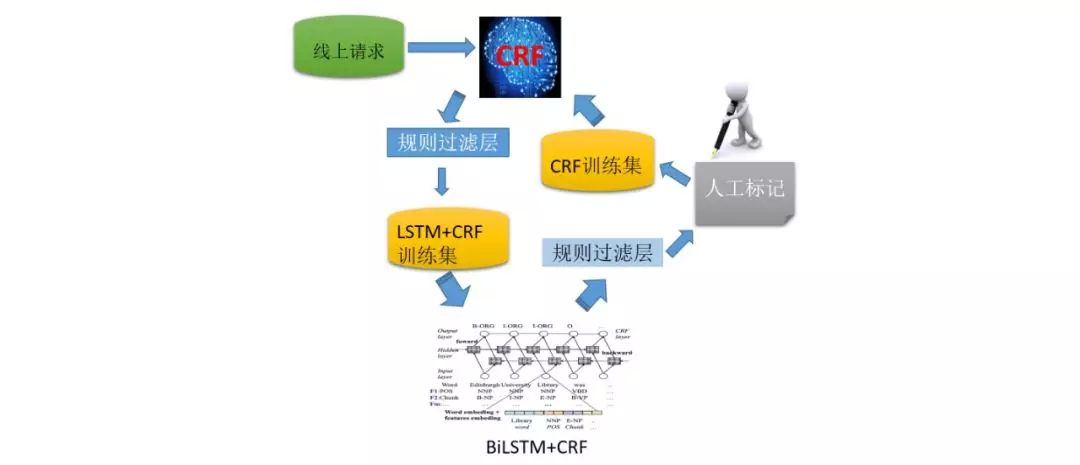
使用了这种方式,样本从万级很容易扩充到百万级,我们仍然使用 crf 模型进行训练和线上应用。
在省略模块,我们完成了规则到机器学习的升级,引入了成分以外的其他特征,提升了模型的鲁棒性。同时并且利用离线深度学习的方式进行样本构造的循环,提升了样本的多样性,使得模型能够更加接近 crf 的天花板。
在后续深度模型的建模中,我们逐步摆脱了对成分分析特征的依赖,对 query 到命中 poi 核心直接进行建模,构建大量样本,取得了进一步的收益。
本文转载自公众号高德技术(ID:amap_tech)。
原文链接:
https://mp.weixin.qq.com/s/2QQ_lWUCExvdiXn2wJJeRQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论