

在公司“核心产品看稳定性,通用产品看丰富度”的指导思想下,短短一年多的时间,笔者所在的公司对外提供的近 200 个产品中,公测产品占比超过 30%,这还不算处于内测和孵化期的产品。
产品丰富度是上去了,但大家都担心一个问题,在这么短的时间内,上线如此多的产品,质量是否能够做到最好?外加 2018 年,公有云厂商发生了至少 9 次较为严重的故障,于是,混沌工程作为提升产品质量的头号工程,便应运而生。
通过业界标杆确立演进路线
在混沌工程的开始,我们主要参考的是混沌工程的鼻祖 Netflix 公司,加之 Netflix 是基于公有云进行的部署,对公有云厂商来讲,具有很强的借鉴和推广意义,因此标杆就这么愉快的确定了。在确立标杆的同时,我们也持续跟进着业内其他厂商的实践经验,避免走太多的弯路。
在对业界厂商的混沌工程落地经验进行多次复盘后,我们总结出适合于自身现状的演进路线,分为以下六个阶段。这部分我们已经在混沌工程系列的第一篇文章中进行了介绍,详情参考文章《混沌工程落地的六个阶段》。

单机破坏进展缓慢
开始做单机破坏的时候,结合 Simian Army 的功能点和模块数量较多的情况,我们也做了最坏的打算,通过半年左右的时间把单机问题彻底消灭,事实证明,我们还是 too young too simple,在历时一年之后,我们也仅仅是解决了单机破坏中关机和重启两个场景的绝大部分问题,并开始进行单机房破坏和依赖治理。
让我们回到 Netflix 落地混沌工程的时间线,看看我们遇到的问题是否属于个例。
Netflix 首次公开 Chaos Monkey 在 2010.12.16,参见此处。
Netflix 首次公开 Simian Army 在 2011.07.19,参见此处。
Netflix 首次公开故障注入测试(FIT)则是在 2014.10.23,参见此处。
从上述的时间点,看到从一个猴子到一堆猴子,只需要半年,但一堆猴子依然是单机维度的,仅有 Simian Army 中的 Chaos Gorilla 是做 AZ 故障模拟的,类似于文中的单机房场景。但从单机维度到 FIT,则足足经过了三年时间。随着技术的发展,我们在今天重新开始混沌工程的时候,所面对的基础架构要远好于 Netflix 在 2010 年的情况,同时还有很多业界的分享和实践,让我们少走许多弯路,这也是我们得以在一年内做到前人三年工作的原因吧。
单机破坏进展缓慢的原因分析
下图是我们对单机破坏过程中出现的 92 个问题的原因分析,在这里,我们主要对前十类问题进行说明,毕竟同类问题多,原因归类相对能准确一些。
需要明确的是,下述的问题包含如下破坏场景:
单机重启
单个机房 30%的服务器重启
单个机房 100%的服务器重启
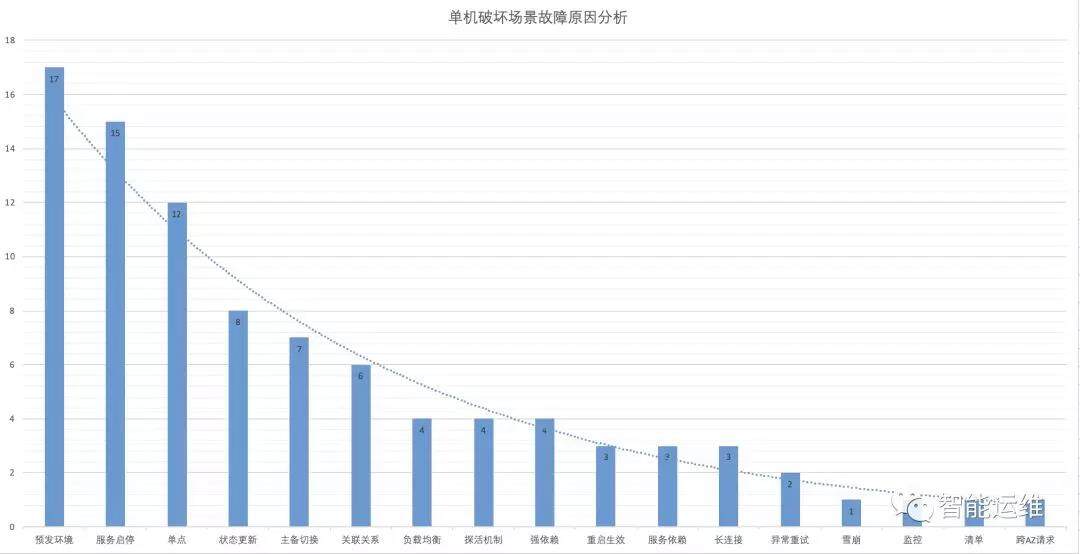
预发环境,是单机破坏问题最多的环节,也是投入时间最长的环节。为避免直接在线上做单机破坏可能出现的风险,我们必须在预发环境确保多次重启没有问题后,才能进行线上操作。因此,环境导致的阻塞问题,只能硬着头皮去解决。以下是预发环境出现高频问题的罗列:
预发环境套数不足,混沌工程破坏演练和业务线的系统集成测试是互斥的,如果有业务线在单机破坏期间进行上线变更操作,可能会导致非预期的问题,耗费较长的时间去定位;
预发环境的物理机过保比例较高,重启后经常会出现硬件故障,大部分时候的硬件故障需要搬迁替换机器来解决,因此耗时较高;
服务器的基础配置不一致,如 DNS、NTP、YUM 以及部分内核参数的配置,以 NTP 为例,如果仪表盘所在节点的时钟比标准时间快一天,那么查询近期数据的结果就全为空,原以为是服务重启后异常,忙活半天发现是 NTP 不同步导致。类似的 DNS 的缓存时间线上线下不一致,DNS 切换后久久不生效新 IP,或者生效 IP 的速度相差较大,也带来很多困扰;
部分实例异常导致的功能偶发性故障,会耗费较长的时间去定位,如配置错误,版本不一致,实例挂掉等,这和很多业务在线下环境没有监控,没有仪表盘,报警被屏蔽也有很大关系;
部分实例分布不均,如三副本在同一个机器或者同一个机架下,这时候就需要协调资源进行服务的迁移;
线上和线下依赖服务的不一致,如开源软件版本不一致,线下的依赖服务是删减版等,也会导致一些问题无法在线下复现;
服务启停,因为没有统一的方案,我们面对的服务来自于上千研发同学开发的模块,也有很多开源软件,大家的解法各不相同,因此这里的坑也格外多:
重启后出现多进程的;
启动脚本中需要拉起多个服务,部分服务未成功拉起的;
有脏数据导致重启失败,进入死循环无限次重试的;
配置更新不完整,服务器重启后,服务无法正常启动;
没有设置在服务器重启后自动拉起服务的;
Systemd 脚本中存在 Bug,导致进程没有被自动拉起的;
NGINX 存在无效域名,DNS 无法解析,重启机器后 NGINX 无法正常启动;
服务重启时间达到 3Min 以上的;
磁盘加载失败导致服务启动异常的;
使用 Systemd 拉起服务后,并不知晓/etc/security/limits.conf 的限制不会生效,而出现资源使用过量影响其他服务的;
单点,该部分主要存在于线下,但线上也有隐患,我们将单实例部署和单机房部署均置于单点问题之下,发现了如下问题:
部分存储节点的三副本放置于同一台物理机之下;
部分存储节点的三副本放置于同一个交换机之下;
多个服务未在预发环境的 AZ2 机房部署,仅在 AZ1 机房进行部署;
部分服务在每个 AZ 中仅部署一个实例;
分配四台机器只部署了一台机器;
依赖的底层 LB/DNS/NTP 服务仅在一个 AZ 部署;
Kafka 做双 AZ 部署,但其 partition 分布不合理,导致部分数据失效;
部分业务使用的下游提供的域名,仅包含单个 AZ 的机器列表;
部分业务部署了两个 AZ,但 LB 上仅绑定了一个 AZ1 的机器,AZ2 的设置为了冷备,不接流量;
状态更新和容错机制的一些问题:
关闭 AZ1 后, worker 状态未更新成功,导致创建任务下发到关机节点,创建任务无法执行;
关闭 AZ1 后,Mysql 的从库挂掉,系统默认还在 AZ1 创建从库,导致创建失败;
关闭 AZ1 后,自动触发 failover,但 task 表中重复插入了 failover 任务;
关闭实例后,其状态无法上报,导致控制端无法获取其状态,需要人工介入去修改状态;
关闭实例后,LB 探测其状态仍然属于正常状态,或者状态未及时更新,导致流量受损;
etcd 的一个节点处于非健康状态时,其 client 通过 etcd sdk 获取的返回值是 500,因此继续请求该节点;
主备切换的一些问题:
有些新的业务预案情况是这样的,没有预案,停留在 WIKI 上,只有老人知道;
有些新的业务的预案有脚本,需要临时修改参数和配置,容易搞错;
有的同学没有预案平台的权限,不能操作;
有的同学对预案平台不熟悉,操作耗时较长;
有的预案较长时间没有使用,已经不再适配当前情况;
部分业务的程序 DNS 缓存时间较长,执行 DNS 切换预案后,5-10min 才能生效;
部分业务无法选主,因为故障机房的实例比例偏大;
关联关系的一些问题:
在/etc/hosts 中将部分域名的地址写死;
服务配置中写死下游的 IP 地址;
对于通过名字服务获取的地址没有进行存活性判断;
上述的这些问题,对我们测试 case 丰富度也起到了巨大的帮助,从而避免新的业务继续出现上述问题。
改进思路
仿真环境建设
仿真环境是按照是公有云线上 Region 来实施的,包含三个 AZ,只是他的用户,仅限于内部测试用途,不会暴露给公有云的对外客户。考虑到实施成本,我们仅在一个 IDC 内部搭建了三个 AZ 区域,在外网接入和跨 AZ 的专线上有所简化,除此之外,大部分都和线上完全相同,仿真度达到 90%以上。
因为有线下较多的用户场景和业务需求,不仅满足了流量丰富度的问题,而且集群也开始有专人维护,之前预发环境的种种问题,得到了极大改善,从此不在制约混沌工程的发展。
同时,仿真环境的硬件选型以及超售比,都更加激进,线下场景的使用成本也较之前降低了 30%。最后,仿真环境的选址远离在线机房的地方,让一般业务无法容忍这种延时,并且进行了严格的网络隔离,可以彻底避免线下和线上互联的风险。
环境一致性维护
引入 Puppet 对所有线上和线下环境进行持续维护,这样既可以确保关键配置项在各个环境中的一致性,同时 Puppet 也能将不符合要求的配置进行修复。基于此项能力的落地,类似于 NTP 问题,DNS 问题,/etc/hosts 问题等,都被彻底解决。
同时,取消研发和测试在仿真环境的操作权限,仅提供只读权限账号供其进行问题分析和定位,从而尽量减少研发和测试同学对仿真环境的非授权修改。
虚拟化和部署系统
首先是仿真环境不允许手工上线和手工修改服务配置,仅支持从部署系统进行发布。通过业务的虚拟化改造,既减少了对基础环境的依赖,又能复用同一个镜像来消除线上和线下服务配置的差异。
在部署系统中增加了多个约束策略,如禁止单实例和单机房部署,将一个服务的实例置于高可用组中从而避免部署在同一个机架下,部署系统仅接受来自于公司官方 GIT 的代码,在操作系统的基准镜像中内置 Monit 对服务进行启停管理,必须部署完毕仿真环境才能够进行线上发布等。
代码扫描
通过部署系统约束 GIT 的源头之后,在 GIT 中我们主要是增加了对关联关系的静态扫描,如是否包含 IP 地址,是否包含主机名地址,域名是否为公司内网域名,诸如此类的策略,从而在源头将这些依赖关系的问题消灭掉。
服务启停和启动自检
将服务启停的方式收敛到 Systemd 方式,然后提供基于 Systemd 启停方式的最佳实践,包含重启的最大次数,重启的间隔,资源限制等,进程启动前的启动自检,从而避免之前的各种异常导致的服务启动失败。
启动自检包括如下内容,如运行账号是否正确,目录权限是否正确,配置文件是否合法,资源限制是否生效,硬盘是否挂载,JDK 版本是否正确,从而让进程启动在一个符合预期的环境中运行。
监控和仪表盘
通过在仿真环境中建立仪表盘,具备了对关键事件以及系统全貌的掌控能力,例如当前是否有上线和变更,核心功能是否正常(需要通过黑盒监控进行探测),哪些服务和实例有问题,存在哪些历史报警和新增报警,当前的流量情况,资源使用率,谁登陆了哪个服务器执行了什么命令,哪些系统文件被修改了等等。在出现问题后,通过仪表盘,在进行单机破坏前,确认是否具备破坏条件,在单机破坏实施中,能够快速定位问题、评估影响。
仿真环境的建设方向
仿真环境是混沌工程的起点而非终点,之所以投入较多的精力进行仿真环境的建设,是希望在线上做混沌工程的时候,尽量减少风险和影响。因此,仿真环境的拟真度会成为我们持续提升的一个目标。
如何彻底解决运行时环境的一致性问题呢?按照我们 SaaS 产品的实践,一个 docker 走天下。从效果上看,就是 docker 镜像不做任何更改,就可以同时在集成,测试,预发,仿真和线上环境上正常运行。举一个简单的例子,我们在公有云上开设两个账号,然后部署同一个程序,这时候,其关联关系不论是 IP,域名等,我们都可以保持完全相同,从而实现一个 docker 走天下的梦想。相信,不远的将来,环境问题也许就不再是困扰大家的问题了。
参考文章:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 4 条评论