

前言
随着视频数量的爆发式增长,特别是近年来短视频领域的迅速崛起,视频已经成为大部分互联网用户娱乐的首要选择,占据了用户大部分娱乐时间。面对如此海量的视频,如何帮助爱奇艺用户从冗长的视频中筛选出更具吸引力的视频片段,提高用户的观看体验,提升用户粘性,成为我们十分关注的研究课题。为此,我们深入研究了视频精彩度分析技术,成功实现了不同时间粒度下精彩视频片段的自动筛选,并能给出片段包含的看点标签,在多个业务场景中都得到了较好的应用效果。
爱奇艺拥有十分丰富的 PPC(Professional Produced Content)视频资源,视频内容多样,仅仅是综艺就可分为搞笑、选秀、访谈、情感、职场、脱口秀等十几种类型,如果每个类型都建立一个精彩度模型,不仅资源消耗巨大,而且模型的自适应能力也将大大降低。学术界的精彩看点检测技术大多聚焦于 UGC(User Generated Content)视频,且通常是针对特定领域视频的分析,因而并不适合直接应用于爱奇艺的精彩度分析技术中。业界公开的关于视频的精彩度探索比较少,较有影响力的为 2017 年百度公开的 Video Highlight 数据集,该数据集包括 1500 个综艺长视频,视频总时长约 1200 小时,只对片段进行了精彩/非精彩标注。如何针对爱奇艺多个业务场景的需求,对内容多样的视频建立通用精彩度模型,并对视频内容进行更加精细化的精彩度分析,是我们面临的主要挑战。
本文将介绍我们探索出的视频精彩度分析技术方案,整体技术框架如下:
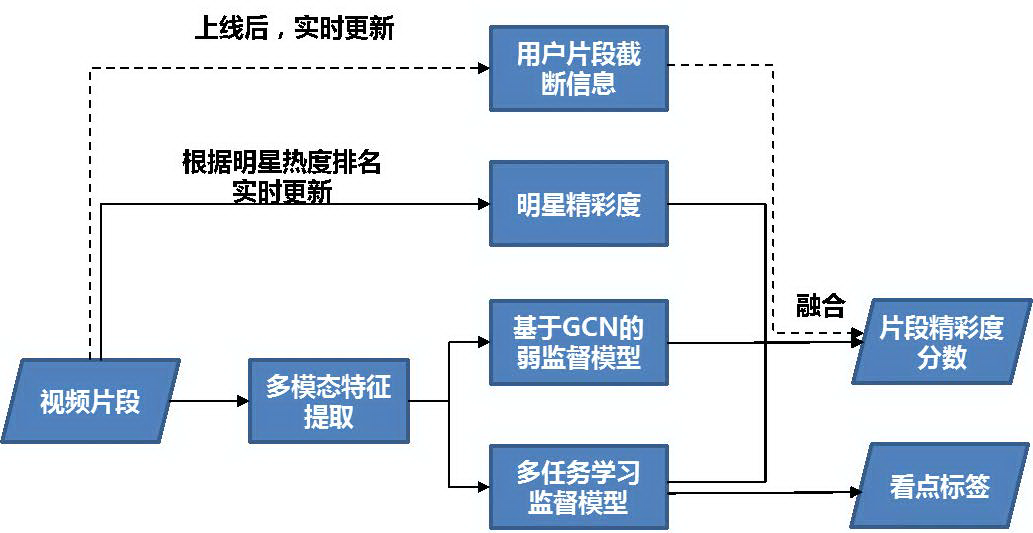
图 1 视频精彩度分析技术方案
该方案融合了监督模型、弱监督模型和明星、用户片段截取等其他维度的信息,能够综合给出较为符合人为主观评价的视频精彩度评分。下面我们将详细介绍各个模块的具体技术解决方案。
视频精彩度分析技术方案
1 视频精彩度监督模型
我们的目标是对视频的精彩度进行较为准确的评分,而非简单的精彩/非精彩二分类,因而我们将精彩度建模为一个回归任务,而建立监督模型的前提是拥有高质量的标注数据集。我们的数据集来自 5000 多部爱奇艺影视剧和综艺长视频,每条数据为 10s 左右的视频切片,标注人员对切片根据精彩度进行打分 0 到 10 打分,并对精彩切片从场景、行为、情感、对话等多个维度上人工打出精彩看点标签,建立了包含超过 36 万切片的视频精彩度分析数据集。该数据集具有以下特点:
(1)数据集大,从头训练端到端的模型,训练成本高;
(2)精彩度评分主观性较大,标注人员对同类型切片的打分可能有 1-3 分的差异;
(3)精彩度评分与精彩看点标签高度相关,精彩切片一定包含看点标签;
(4)看点标签为多标签,标签内部具有较大的相关性,如搞笑和大笑、鼓掌和欢呼等。
针对数据集的以上特点,我们采用迁移学习,先提取多模态特征对视频切片进行表征,再进行后续训练,提高模型性能的同时大大降低了训练成本;对于精彩度分数,采用标签分布学习算法去学习分数标签的分布,而非传统的回归 loss;对于看点标签,我们采用典型相关自编码器算法去学习标签内部的相关性;最后我们采用了多任务学习模型,同时训练精彩度分数和看点标签,获得了比单个任务更佳的性能。下图是我们的精彩度监督模型技术框架。
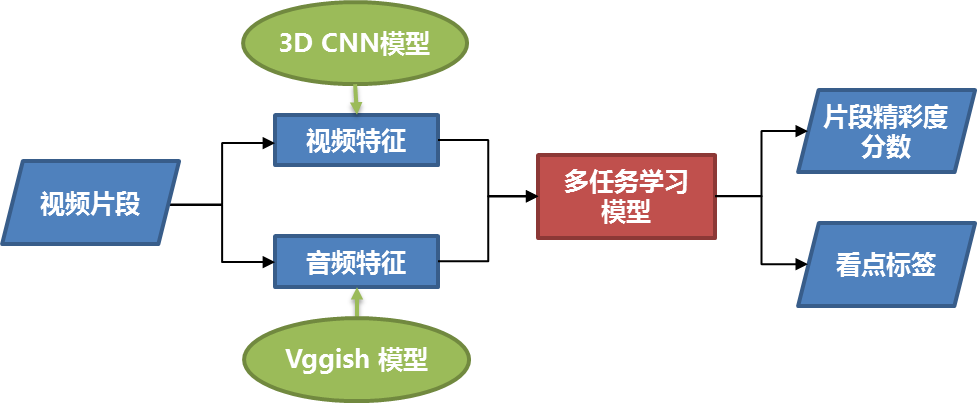
图 2 精彩度监督模型技术框架
下面我们分别详细介绍各个技术模块:
特征提取
我们的数据集包含超过 36 万的视频切片,已经超过了行为识别数据集 kinetics-400 的规模。研究表明,3D CNN 是比 2D CNN 更好的视频表征模型,我们的实验也证明了这一点,但同时 3D CNN 的模型参数也达到上千万甚至上亿。如果用几十万视频数据从头训练 3D CNN 模型,每次超参数调优如 batch size、学习率、正则系数、优化器等的组合变化,都需要几十万次的迭代才能看到效果,不仅需要耗费更多的计算资源和训练时间,也可能会影响模型的最终效果。
因而,我们借鉴 2D 视觉任务中比较流行的基于预训练的 ImageNet 模型进行迁移学习的做法,首先用基于 kinetics-400 训练得到的行为识别 I3D 模型,对我们的数据提取视频特征,基于视频特征进行网络训练。另外,我们还基于精彩度数据集对 I3D 的高层网络进行了微调,用微调网络提取视频特征比直接用原始 I3D 模型特征效果更好。最后,我们考虑到视频的精彩度不仅与视频的视觉内容有关,还与音频高度相关,因而我们用基于包含 200 万个 10 秒音频的 AudioSet 数据集训练得到的 Vggish 模型,对我们的数据集提取音频特征,将音视频特征融合后输入自己设计的神经网络进行训练,相比单模态特征,采用多模态特征使得模型性能得到了显著提升。下图是我们基于百度 Video Highlight 数据集进行精彩度二分类进行的实验结果。
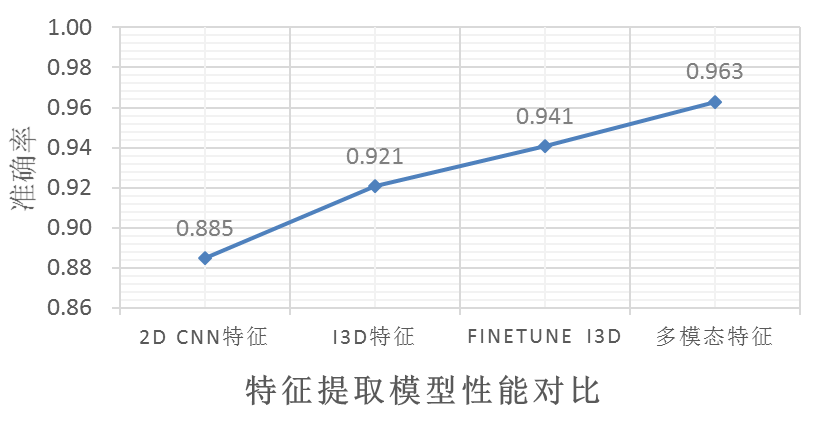
图 3 不同模型提取特征性能对比
2018 年,在 kinetics-600 数据集公开后,我们在自己的精彩度数据集上,又进行了基于 kinetics-600 数据集预训练模型进行特征提取的实验。实验表明,相比微调后的 kinetics-400 模型,直接采用 kinetics-600 预训练模型使得精彩度评分的 mse 下降了 0.06,而再对 kinetics-600 预训练模型进行网络微调,则对精彩度评分的性能无显著增益,因而,目前我们线上采用的视频视觉特征提取模型为 kinetics-600 预训练模型。
精彩度评分
精彩度评分的主观性较强,如果想要获得更加客观真实的训练数据分数标签,需要多人对同一个视频进行标注评分,标注成本巨大。我们的训练集一条数据只有一个受训过的专业人员进行标注,这不可避免的会导致标注分数与真实分数之间有一定差异。为了降低人为标注主观因素对模型的干扰,我们采用深度标签分布学习(Deep Label Distribution Learning,DLDL),即将标注分数转化为一个分布在 0-10 区间的一个分布,而非直接去用模型拟合学习标注分数。具体地,假设对于数据 X,标注分数为 S,我们用均值为 S,方差为 1 的高斯分布来拟合其分数分布 y,如下:
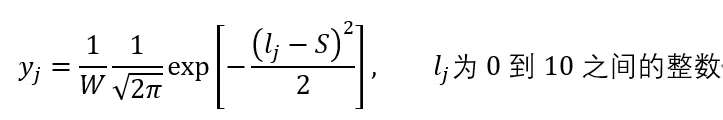
其中
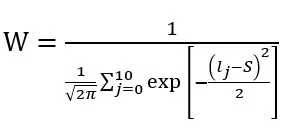
为归一化参数。假定我们模型网络的最后一层输出为 x,我们用 softmax 激活函数将输出转化为概率分布,如下:
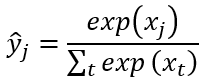
我们的目标是优化网路,使得网络输出分布 与分数分布 y 尽量相似。如果用 KL 散度衡量这两个分布的相似性,则损失目标函数为:
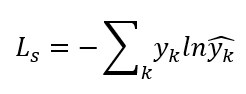
训练完成后,我们用模型输出分布的期望在作为预测分数,即:
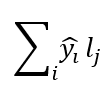
采用 DLDL 方法能够有效建模精彩度分数标签的不确定性,大大降低了标注噪声的影响,相比使用常规的 MSE 回归 loss,我们的精彩度评分准确性得到比较明显的提升。
精彩看点标签分类
由于一个视频可能包含一个或多个彩看点标签,因而我们的精彩看点标签分类是一个多标签分类任务。多标签分类最简单常用的方法是假设各个标签之间无相关性,在输出层对每一个标签的输出层使用 sigmoid 激活函数,采用二值交叉熵 loss 进行独立的二分类。
上述思路存在的问题之一是没有考虑标签间的相关性,而这种相关性可能能够提高特定问题上模型的效果,例如,在进行看点标签分类时,搞笑和大笑经常一起出现,而搞笑与悲伤一起出现的概率则很低,如果能充分利用这种标签间的相关性,则将进一步提升多标签分类模型的效果。其中,标签嵌入(Label Embedding)是常用的一种标签关联方法,它是将标签转换为嵌入式标签向量,从而来获取标签之间的相关性。我们借鉴 C2AE (Canonical-Correlated Autoencoder)方法,采用 DNN 编码获得标签嵌入式表示,并使其与输入特征向量在编码空间产生关联,分类 loss 则仍采用二值交叉熵损失函数,模型如下:
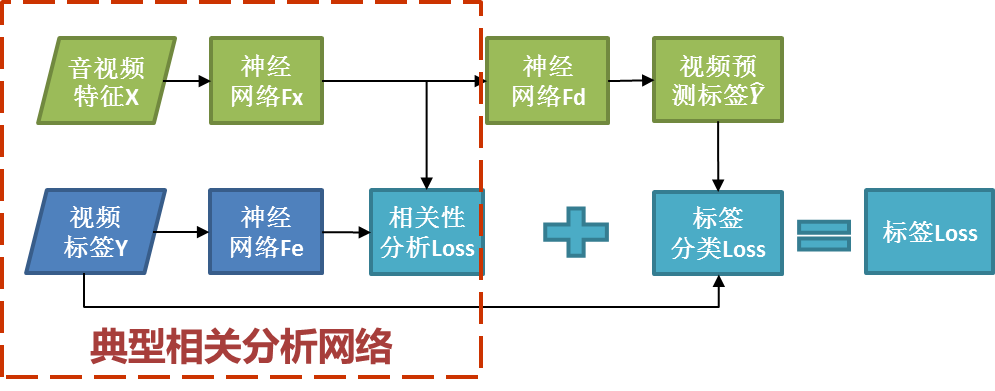
图 4 精彩看点标签分类模型技术框架
上图中,Fx,Fe,Fd 是 3 个 DNN,分别代表特征编码、标签嵌入和隐向量解码,具体地,我们的 Loss 定义如下
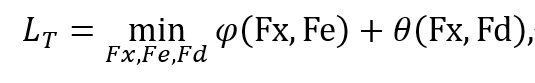
其中相关性分析 Loss 为:
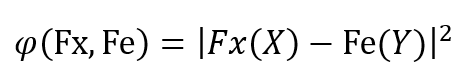
标签分类 Loss 为:
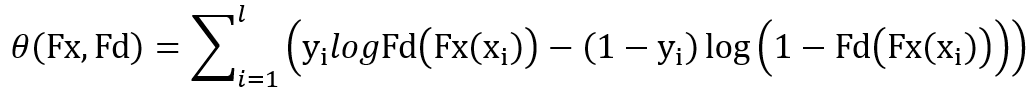
相比常规多标签分类方法,典型相关分析网络的加入使得我们的精彩看点标签分类 MAP 提升了 1.1 个百分点。
多任务学习模型
考虑到视频中的精彩度和存在的看点标签是息息相关的,因而我们可以通过联合训练互相促进,从而提升精彩度评分的准确性。我们采用的多任务学习模型如下图:
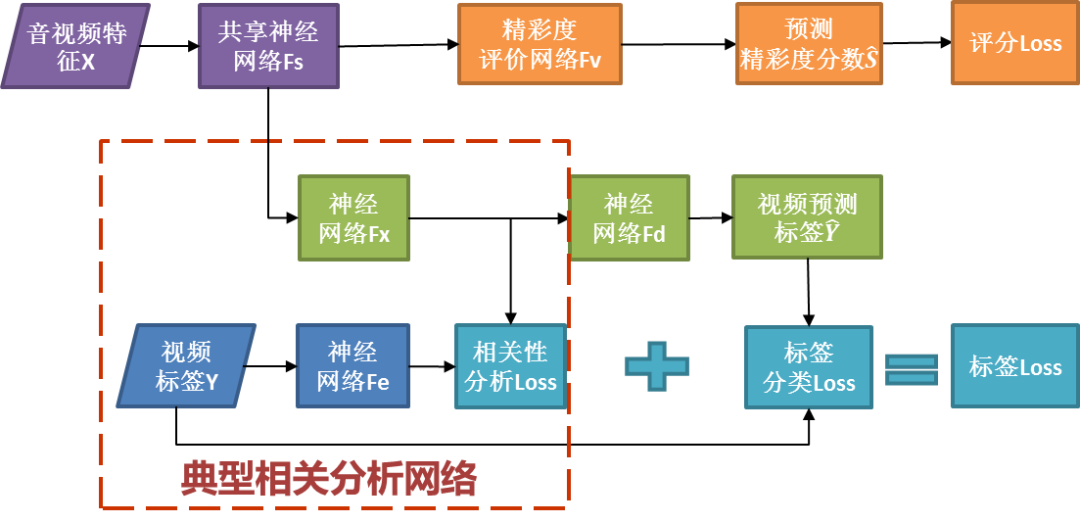
图 5 多任务学习模型技术框架
多任务学习模型包含基于 DLDL 的精彩度评分和基于 C2AE 的精彩看点多标签分类两个子网络,在训练时,我们采用交叉训练的方式,分别优化评分 Loss 和标签 Loss。其中共享神经网络 Fs 的加入不仅提高了模型分析效率,使网络减少了近 50%的模型参数,且通过特征共享进一步提高了精彩度评分的准确性,使得均方误差下降了 0.10。
2 视频精彩度弱监督模型
虽然我们的视频精彩度监督模型已经具备了良好的精彩度评分能力,但是该模型是建立在昂贵的标注成本之上,模型的可扩展性和更新效率都具有一定的局限性。目前,一些研究将视频精彩度分析建模为一个弱监督任务,取得了较好的效果。爱奇艺拥有海量的用户数据,我们可以从这些珍贵的用户行为数据中,获得与精彩度相关的弱监督数据。例如,爱奇艺有一个用户从长视频中截取片段并进行分享的功能,我们认为,用户一般更倾向于截取视频中更精彩的片段进行分享,即一个视频切片被用户截取片段包含的次数越多,该视频精彩的概率越大,反之,不精彩的概率越大。我们利用这个用户截取片段的行为数据,建立了我们的视频精彩度弱监督数据集,该数据集覆盖电影、电视剧、综艺、动漫四大频道 1 万多个长视频,共包含近 300 万个视频切片。我们的弱监督模型采用 ranking loss,如下:
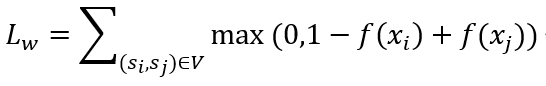
其中视频切片对 ,,来自同一个长视频 V,分别代表被用户截取片段包含次数较多的视频切片和被用户截取片段包含次数较少的视频切片,即精彩和非精彩视频切片 , 分别为 , 的特征, 代表 DNN。
上式假设我们的弱监督数据集不包含噪声,然而事实上,相比监督数据集,弱监督数据集包含了更多的噪声,例如在综艺视频唱歌、跳舞的精彩表演片段中,极有可能也包含一些观众、评委观赏等一些不精彩的片段。因此,只有一些样本对是有效的,我们希望模型仅仅学习有效样本对,而忽略无效样本对,为此,我们引入权重变量 ,,得到损失函数如下:
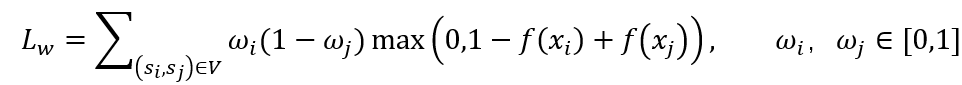
其中 , 分别表示 ,,属于精彩样本的概率,即我们通过 ,,对样本的 label 进行重新标定。
这种通过某种技术手段对样本 label 进行重标定的方法在弱监督学习中也比较常用,通常我们可以将样本特征映射到新的特征空间,使得拥有相似表观的视频切片之间的特征距离最近,然后通过 K-近邻的思想,通过样本 k 个最近样本的 label 对样本的 label 重新标定。近年来,图卷积网络(Graph Convolutional Networks, GCN)在半监督和弱监督任务中表现出巨大的潜力,取得了较好的效果。在我们的技术解决方案中,也利用了 GCN 对样本特征进行重新编码,使得相似视频切片的特征聚合在一起。整体技术架构如下图:
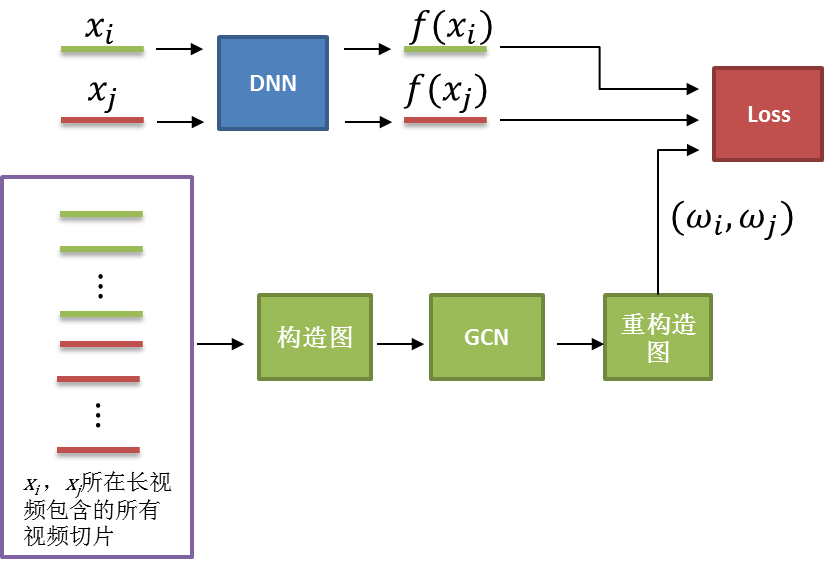
图 6 精彩度弱监督模型技术框架
下面具体介绍我们的技术方案。首先,我们把一个长视频包含的所有视频切片作为一个图的节点,视频切片的音视频特征作为节点特征,图的邻接矩阵构造如下:
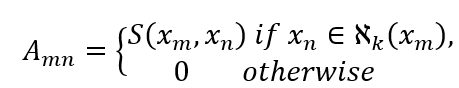
其中 表示 , 之间的相似度, 代表与 最相似的 k 个近邻。
我们采用一个具有低通性质的图滤波器进行图卷积操作,它能够聚合高阶邻接节点的特征来表示当前节点的特征,经过 G 的作用,相似视频切片的特征更加聚合,相对的,不相似视频切片的特征更加分散,如下图所示:
1

原始特征
2
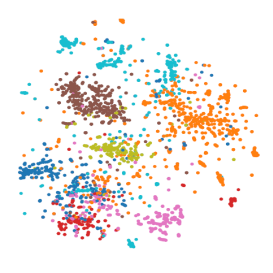
图滤波后的节点特征
图 7 原节点特征与图滤波后的节点特征示意图
由上图可以看出,经过图滤波卷积作用后的特征在一定程度上实现了聚类,我们利用图滤波后的节点特征 ,重新构造图如下:
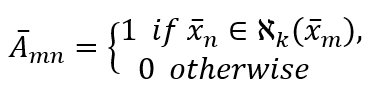
则节点 属于精彩样本的概率可定义为,
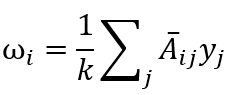
其中 为节点 对应的弱标签。上式可以通过节点 的 k 个近邻节点的弱标签,得出 属于精彩样本的概率。由置信度不高的样本组成的样本对,我们认为它们是无效的,进而希望 Loss 可以忽略这些无效样本对,因此修正 Loss 如下:
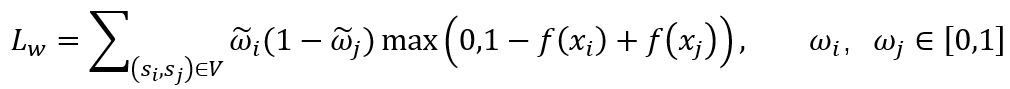
其中,
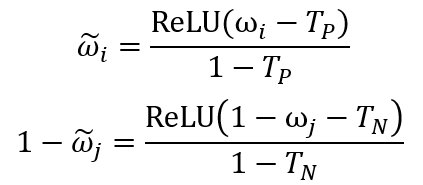
上式中 和 分别是正、负样本是否可信的概率阈值,可根据数据集的噪声水平、正负样本比例等先验设定。
GCN 的引入使得视频切片得到更好的特征表示,进而可以根据特征相似性找到近邻样本,从而对自身弱标签进行重新考量,尽量避免噪声样本对 Loss 的影响,使得我们的精彩度弱监督模型对于标签噪声更加鲁棒。在模型预测时,只需将测试样本输入到图 5 中的 DNN 模块,即可得到样本精彩度预测分数。弱监督模型在性能上略差于监督模型,但是大大降低了获取数据的成本,可扩展性更强。在业务应用中,我们将监督模型和弱监督模型精彩度分数预测结果进行融合,相比单一监督模型,使得优质视频片段的分类准确率提高了约 2 个百分点。
3 融合更多维度信息的精彩度
PPC 视频中的精彩度不仅仅与视频本身的视觉和音频内容有关,还与很多其他因素有关,例如是否包含明星以及明星的重要程度、受欢迎程度等,这也是 PPC 与 UGC 视频最大的不同。因而,我们在模型精彩度打分的基础上,还根据视频片段内的人脸识别信息和人脸时长占比,得到视频片段内包含的主要明星信息, 根据主要明星在视频中的重要程度(可根据是否为主演、常驻嘉宾等信息计算)和受欢迎程度(可根据明星热度、明星影响力等信息计算)得到一个明星精彩度得分。
在冷启动阶段,模型精彩度分析对优质内容的筛选尤其重要,但当视频上线一段时间后,我们也可以根据与该视频相关的一些用户行为对我们的模型精彩度打分进行进一步修正。比如上文提到的用户截断片段信息,我们根据被用户截取片段包含次数的多少,经过一定的数据分析和处理,也可以得到一个精彩度分数;基于用户在观看视频中时产生的快进、快退等拖拽行为得到的数据,也在一定程度上反映了视频片段在用户中的受欢迎程度。
在实际的业务场景中,我们将明星精彩度和用户截取片段等用户行为数据信息与模型分数融合,有助于帮助我们找到模型难以召回的热点内容,使得视频的精彩度评分的准确性得到进一步提高。
总结和规划
我们的视频精彩度技术方案已在多个业务场景中实现落地和应用,如生成 AI 广告产品前情提要、辅助创作,筛选优质视频进行智能分发、自动生成精彩集锦等,明显提升了业务产出质量和效率。
在后续的研究中,我们会从特征提取、算法模型和融合更多维度的信息等方面继续进行优化,建立更加完备的视频精彩度分析系统,具体包括以下几方面:
1)特征提取: 目前我们的视频特征包括视觉和音频特征,后续我们将加入文本特征,也将进一步探索多模态特征的融合方式。
2)算法模型优化: 我们分别利用标注数据集和弱标签数据集训练了监督模型和弱监督模型,然后对两个模型预测的精彩度分数进行后融合。后续我们打算利用半监督的思想,将标注数据集和弱标签数据集联合进行训练,有望获得更好的模型性能。
3)融合更多维度的信息 :爱奇艺已经拥有多种标签识别模型,如行为识别、物体检测、场景分类、音频分类、台词分类等,我们可以融合这些模型对视频片段的分析结果,进一步修正精彩度分数,完善精彩看点标签。
参考文献:
[1] https://ai.baidu.com/broad/introduction
[2] Gao B B, Xing C, Xie C W, et al. Deep label distribution learning with label ambiguity[J]. IEEE Transactions on Image Processing, 2017, 26(6): 2825-2838.
[3] Yeh C K, Wu W C, Ko W J, et al. Learning deep latent space for multi-label classification[C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[4] Xiong B, Kalantidis Y, Ghadiyaram D, et al. Less is more: Learning highlight detection from video duration[C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 1258-1267.
[5] Zhao K, Chu W S, Martinez A M. Learning facial action units from web images with scalable weakly supervised clustering[C]//Proceedings of the IEEE Conference on computer vision and pattern recognition. 2018: 2090-2099.
[6] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.
[7] Li Q, Wu X M, Liu H, et al. Label efficient semi-supervised learning via graph filtering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 9582-9591.
[8] Zhang X, Liu H, Li Q, et al. Attributed graph clustering via adaptive graph convolution[J]. arXiv preprint arXiv:1906.01210, 2019.
本文转载自公众号爱奇艺技术产品团队(ID:iQIYI-TP)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论