

Jarvis 深度学习平台介绍
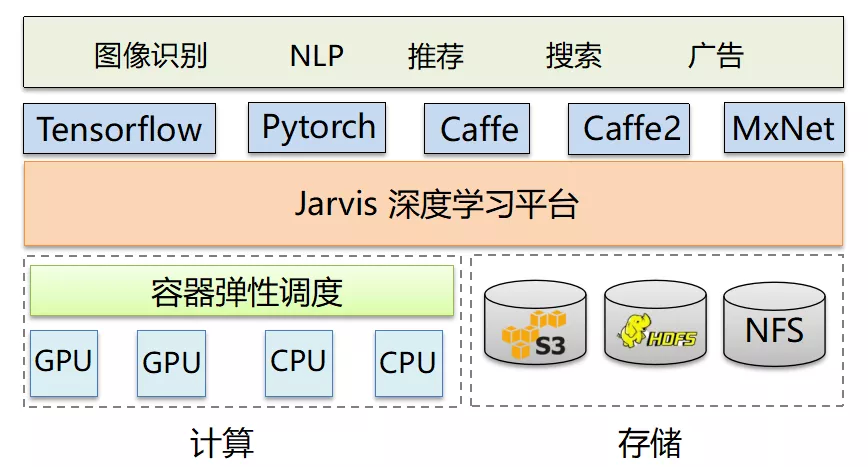
1 平台整体架构
平台支持 GPU 和 CPU 的训练/推理,支持 S3、HDFS 和 NFS 作为训练数据的存储、模型的存储。平台支持 Tensorflow、Pytorch、Caffe、Caffe2、MxNet,但主要以 Tensorflow 和 Pytorch 为主,支持 tensorflow 从 1.X 到 2.X 的各个版本。
支撑公司的广告、搜索、推荐、NLP 等业务。我们基于 mesos + marathon 作为我们的弹性容器平台。这是因为我们容器弹性平台起步比较早,当时 k8s 还不是很成熟。因此在很长一段时间内,我们的容器并不是运行在 K8s 平台上,这点需要大家注意。
2 一站式平台服务
这里主要是通过 4 个小平台实现的, 第一个是数据预处理平台 :通过数据预处理平台可以对训练数据进行可视化分析,帮助用户合理的调参,并及时发现异常数据。
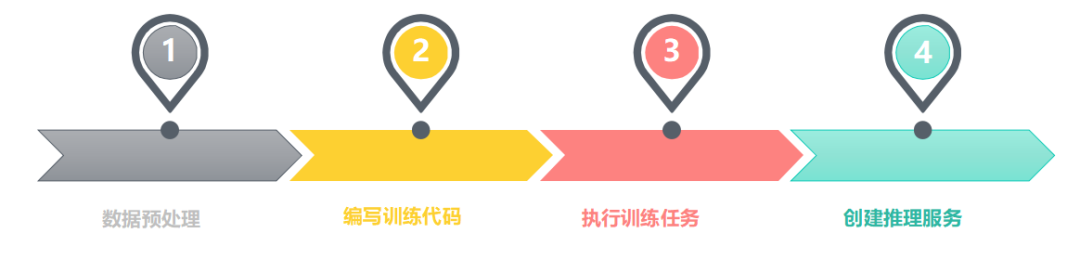
第二个是编写训练代码平台: 用户可以通过 runonce 训练或者 notebook 训练,得到一个和训练环境相同的环境编写训练代码,并上传 gitlab。
第三个是执行训练任务平台: 用户通过 Jarvis 训练平台执行训练任务,然后训练任务将执行用户的训练代码,输出算法模型。
最后用户通过 Jarvis 推理平台 创建推理服务,并对外提供服务。
3 平台发展

我们是从推理平台入手,首先解决让用户训练好的模型能对外提供服务的能力,而后再逐步的将平台功能扩展到支持训练、开发及数据预处理,目前我们正处在将容器弹性平台从 mesos + marathon 迁移至 k8s + volcano 的过程中。
4 使用 Volcano 之前训练平台架构
如图所示为我们在使用 Volcano 之前的训练平台架构:
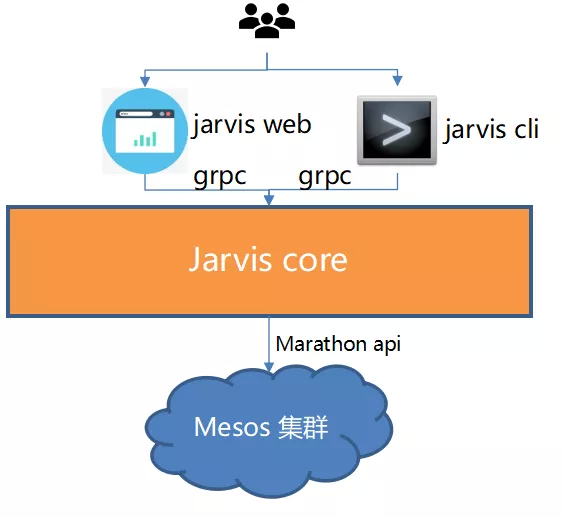
其运行的流程为:
(1)用户编写训练代码并提交到公司内部 gitlab。
(2)用户通过 web 页面、命令行工具去创建训练任务。创建训练任务需要用户填写的信息有:
所需的资源
使用的镜像,每一个框架的每一个版本都通过一个镜像来支持,选择镜像就等于选择了算法框架
我们可能会有多个集群,需要用户指定在哪个集群上运行任务
需要 Gitlab project 的 url,这个 project 中包含了用户编写的训练代码
(3)Jarvis cli/web 将请求转化为 grpc 发送给 Jarvis core。
(4)Core 中将请求转换,调用 marathon api 创建容器。
(5)容器在对应的集群中启动,执行训练任务
5 训练平台迁移到 K8s 的挑战
主要有 3 个方面的挑战:
原生 Pod/Deployment/Job 无法满足分布式训练的要求
无队列管理、配额管理。
调度能力缺失、如 Gang Scheduling
6 引入 Volcano
实际上,Volcano 对于我们来说最重要的是这么几个概念,一个是 vcjob,可以简单的理解成 vcjob 是对 K8s job 的一种扩展,或者是对 pob 的一种封装。
第二个对于我们比较重要的是 Queue ,也就是队列,因为在 Queue 上可以分配一些配额,可以做一些配额的管理、队列的管理;
第三个对我们比较重要的是 podgroup,可以把它看成是 pod 的一个集合,因为有了 pod 集合这个概念,所以它才能做一些更高级的上层调度。
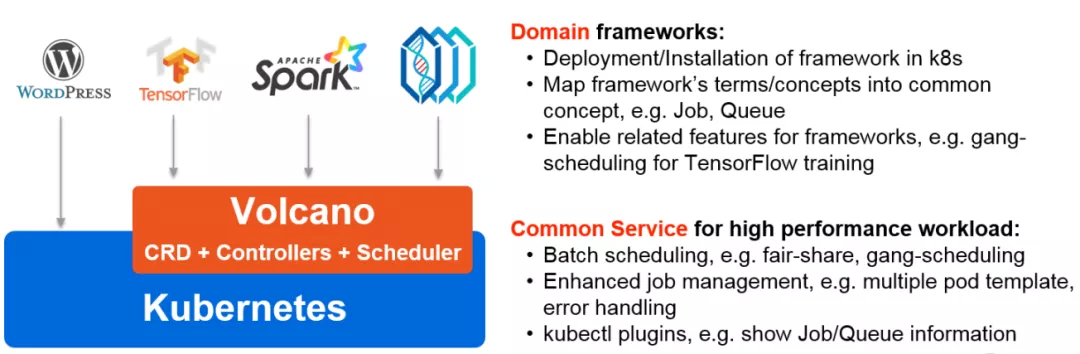
按照我的理解:
Volcano 是 K8S 原生的 batch System,高度符合 AI 训练场景。
不侵入 k8s 源码,符合 k8s 的开发规范。(简单来说,方便我们二次开发)
项目加入 CNCF,成熟度高
Power of Volcano
Volcano 要如何解决迁移到 K8s 上遇到的问题:
1 Gang Scheduling 的问题
Gang Scheduling :可以简单的理解为要么同时被调度,要么同时不被调度,这对于 AI 训练场景来说是非常重要的,因为我们的大部分的训练都是基于分布式训练,分布式训练的特点是一次启动的 pod 非常多,可能最多的话是有四五十个 pod, 如果一个任务下有个别的 pod 被调度,部分 pod 没有被调度,那显然这个任务是不能正常运行的,那这些运行起来的 pod 是没有任何意义的,会造成资源的浪费,同时可能会引发死锁的问题。
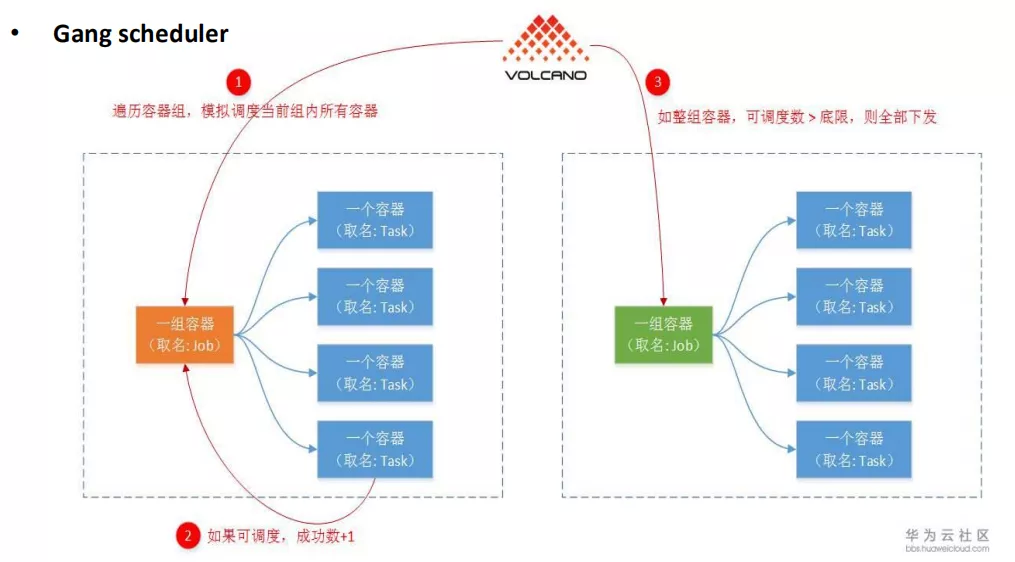
比如,我们整个资源池只有 4 张 GPU 卡,有训练任务 A 和 B,A 任务有 4 个 pod,每个 pod 需要一张卡;另外 B 任务也是同样的情况,当 A 和 B 同时被创建,如果没有 gang scheduling,A 可能拿到了 2 张卡,而 B 拿到了 2 张卡,那这个时候无论哪个任务都不能顺利完成,这个时候系统就产生死锁了,除非你增加资源,否则就一直保持死锁的状态。
如果有了 Gang scheduling , 就能避免上述问题。Volcano 通过 podgroup 这个 CRD,能够以 podgroup 为单位对 job 进行整体调度,实现 Gang scheduling 的功能。
2 分布式任务原生支持
我们以 Tensorflow 分布式训练为例,它主要有这几个角色,PS、master、worker。Parameter Server(PS)是用来存储参数的,master、worker 简单理解为进行计算梯度的,在每个迭代过程,master、worker 从 parameter sever 中获得参数,然后将计算的梯度更新给 parameter server,parameter server 聚合从 master、worker 传回的梯度,然后更新参数,并将新的参数广播给 master、worker。
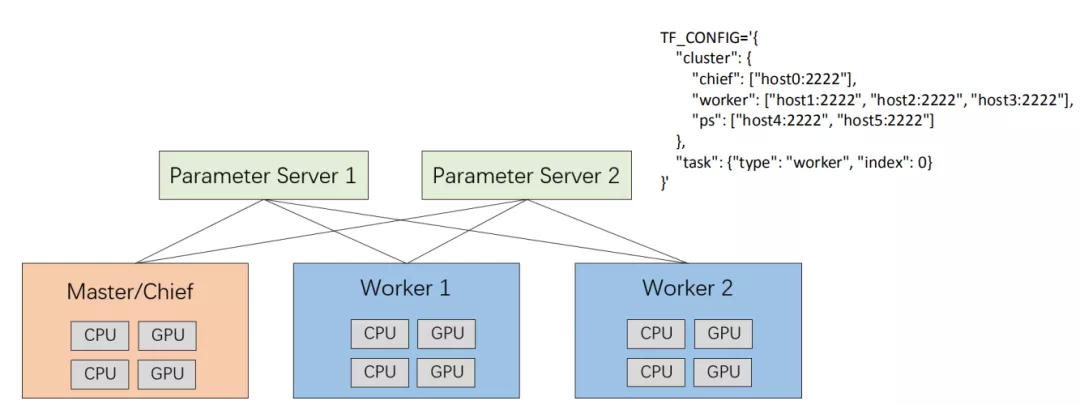
当然我们在这里不是分析 Tensorflow 分布式训练的细节。我们只讨论它的一个网络结构。比如 master、worker 它要和这个 Parameter Server 去做通信,那么要做通信的话就存在一个问题,如果我去创建一个 pod,在创建的时候我可能并不知道这个 pod 的 IP 是什么,如果我在一个 Deployment 创建多个 pod, pod 之间也互相不知道对方的 IP 地址或域名是什么,我们需要通过其他的办法来做这样一件事情,对于我们来说相当的复杂。
这里的每一个角色都要互相知道对方的 IP 地址或者域名,最终要组成 TF_CONFIG 这样一个配置文件,这个配置文件里面其实写的很清楚,至少包括 master、worker、ps 的 IP 地址或者域名,这些都要写在这个配置文件里面,每一个节点都需要知道这个东西,除此之外还需要知道自己所担任的是什么角色,Index 是多少,对于 K8s 的话是很难实现的,但有了 Volcano 后就变得非常简单了。
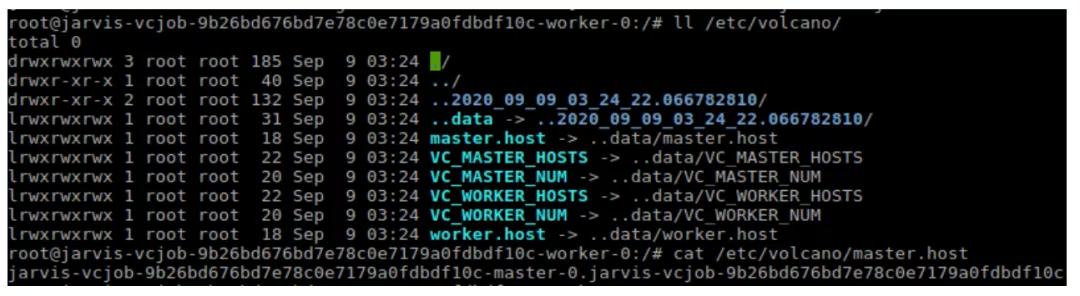
Volcano 会帮你在一个 vcjob 下多个 pod 去注入一个文件夹(etc/volcano),这个文件夹下面就会有所有的 master、volcano、ps 的域名,都会填在这里面,这样的话每个 pod 都知道整体集群里都有哪些 peer ,非常方便去组成 TF_CONFIG 这个文件,只要组成了这个 TF_CONFIG 文件,我们就能进行 Tensorflow 分布式训练。
现在的话 Tensorflow 提供一些高层的 API,比如说 TF estimator ,这个 estimator 里代码的单机和分布式代码是一模一样的,只不过这个 TF_CONFIG 的配置是不一样的,所有说只要有那样一个格式的环境变量或者配置文件传进去的话,就可以做分布式训练,对于我们平台方来说,帮助用户构建 TF_CONFIG,用户拿来直接运行就可以了。Volcano 通过注入文件,可以方便构建 TF_CONFIG,以支持 TF 分布式训练。
3 Horovod/mpi
Volcano 支持 Horovod 训练,Horovod 训练其实和 Tensorflow 分布式训练有点类似,因为大家都是分布式训练,区别是更新参数的方式不一样,大家可以注意一下 Horovod 训练简单来说它更新参数是环形的更新方式。
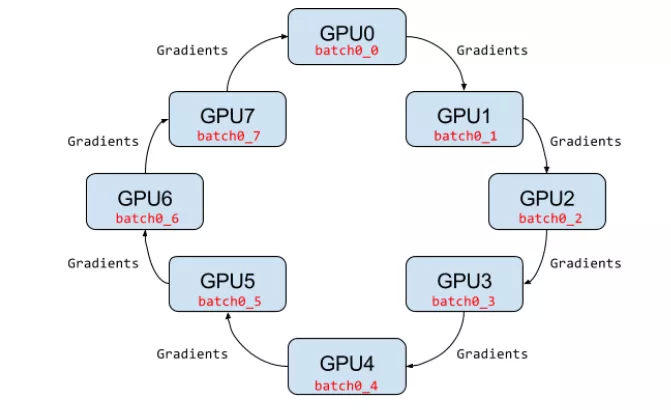
但这个并不重要,因为对我们平台侧的话,我们主要想要做的事情是我们要构建好基础环境,让上层应用来使用,这种 Horovod 网络架构,它对于我们基础环境有什么要求呢?
它的要求很简单,它除了要保证每一个节点都要知道对方的域名和之前的需求是一模一样的之外,它还额外的 ssh 互信,因为它经过 22 端口做 ssh 登录,去做一些工作,所有在这里面需要做好互性,互性的工作如果让我们来做,就很麻烦,我们要想一堆办法来做这个事情,Volcano 可以通过设置 ssh plugin 自动完成容器里的互性,就可以达到 Horovod 对于训练任务的网络要求。
4 配额系统、排队系统
Volcano 其实是通过 Queue 这么一个 CRD 来支持的,在图中这个是表示资源池里的一个资源,我们假设有两个 Queue,一个是 Queue1,一个是 Queue2,一个的配额有 20 个 GPU,一个有 10 个 GPU,当 Queue 已经使用的资源不太多时,新任务来了之后是可以被调度的,但是如果 Queue2 已经被使用了非常多,就已经使用完了,下面的新任务来了之后那就不可以被调度,只能继续排队,你 podgroup 的状态就处于 pending 的状态,就一直处于排队中。
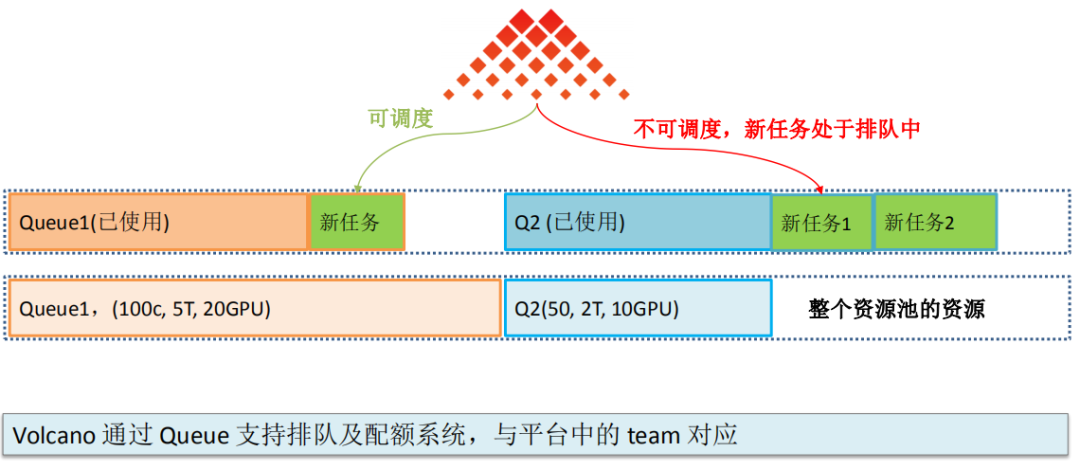
Volcano 通过 Queue 支持排队及配额系统,正好与平台中的 team 对应,因为我们的结构也是一个组有一个独立的配额,这个配额与配额之间是相互独立的,你只能用这么多,使用量超过配额后,任务就将排队,当然排队的任务支持优先级策略,高优先级的任务将在有资源后首先被执行,正好和我们系统的设计是一致的,所以就非常的好对接。
5 与 volcano 集成
新增了 volcano_plugin,其封装了 vcjob、queue、podgroup 的 restful api,将 grpc 请求的内容转成 k8s api 规范的 yaml 配置,并调用 k8s api 创建容器。
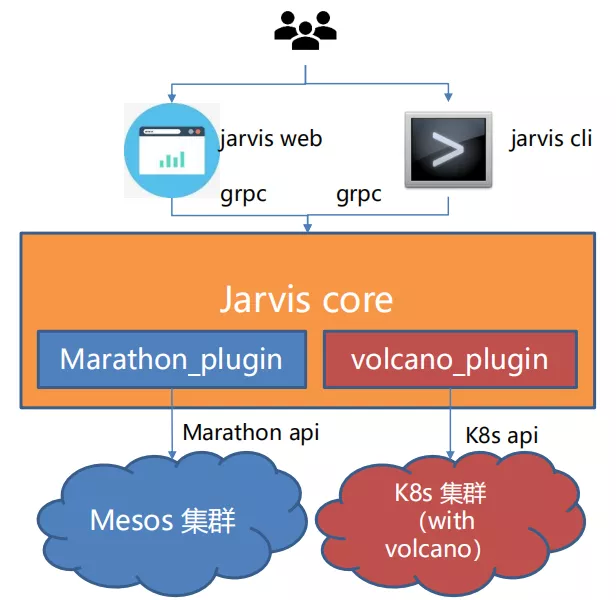
Jarvis Core 根据传入的集群信息,决定使用哪个 backend。
实际使用中遇到问题
1 问题一
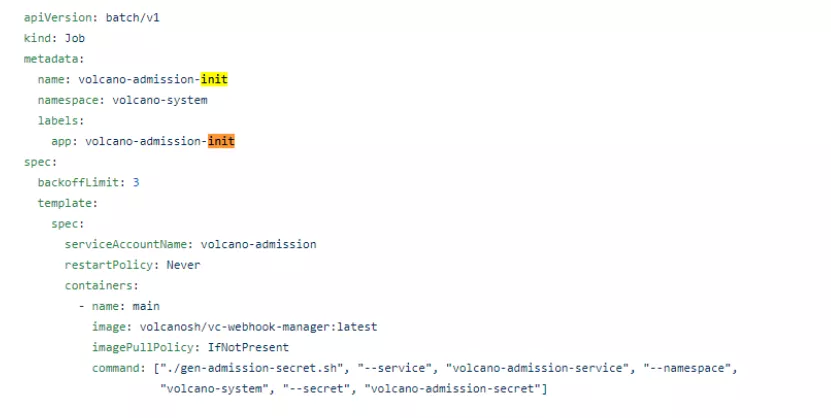
现象: 当升级 volcano 版本的时候,直接修改https://github.com/volcano_x0002_sh/volcano/blob/master/installer/volcano-development.yaml 中的 image,然后执行 kubectl apply -f <yaml file>,会导致已经存在的 queue/vcjob 等全部消失。
原因: yaml 中的 volcano-admission-init 会重复执行,导致 volcano 整体被 reset 现象
解决办法: 升级的时候想清楚升级对应的组件就可以了
2 问题二
现象: 通过 list_and_watch 监控 vcjob 状态变化的程序进行遇到 watch 连接无故断开的问题,即如果没有新的 events 产生,大约 80~90s 就会断开一次,每次时间还不固定,但是同样的代码 watch pod 就没有问题。
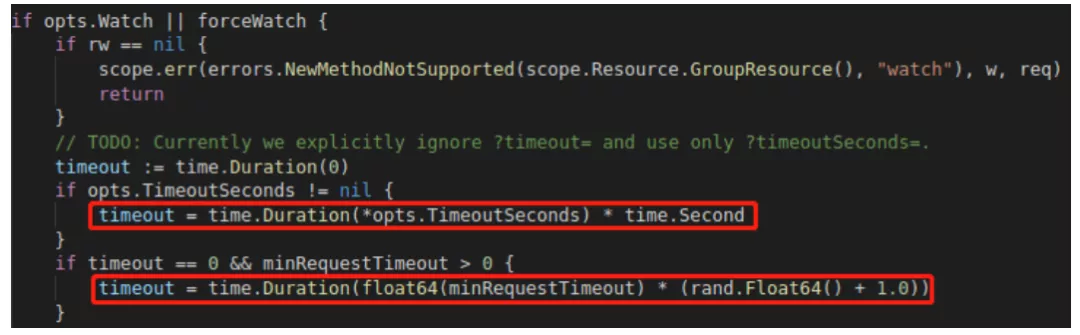
原因:
通过阅读 k8s 源码,K8s 对于 CRD 资源,默认的 http timeout 的时间是 time.Duration(float64(minRequestTimeout) * (rand.Float64() + 1.0)),其 minRequestTimeout 为 1 分钟,因此会出现上述的问题。可以通过客户端指定 timeoutSecond 来避免该问题。
3 问题三
现象: Jarvis 训练平台中容器入口地址是一个 bash 脚本,在 k8s 下运行时,会出现 stop 命令下发后,等约 30s 才退出。
原因:
bash 不会把 signal 传递给子进程中。当 graceful stop timeout 到了之后,守护进程发现容器还没有退出,会再发 SIGKILL,此时会将 bash 脚本杀掉,容器退出,但是容器中的其他进程将无法主动完成清理工作。
解决方案:
使用 dumb-init,比如入口脚本:
#!/usr/bin/dumb-init /bin/bash
my-web-server & # launch a process in the background
my-other-server # launch another process in the foreground
4 对 Volcano 的修改
SVC plugin 支持传入参数,参数为 nodeport 的端口号,当创建 vcjob 并传入 SVC 参数时,将创建对应的 nodeport,这是因为我们的 tensorboard 及其他服务需要让外部访问。
ssh plugin 的名字超过 63 字节则会创建失败,我们自己修复了这个 bug。
Queue 的 capability 存在 bug,用户可以突破 capability 来使用资源,目前官方已经修复了这个问题。https://github.com/volcano-sh/volcano/issues/921
给 vcjob annotation 后,某个 pod 失败时,无法触发删除 vcjob,https://github.com/volcano_x0002_sh/volcano/issues/805
总结
(1)Volcano 弥补了 kubernetes 深度学习场景下的基本能力的缺失
gang scheduler
队列管理
(2)Volcano 代码遵循 kubernetes 的标准,采用非侵入式方案
减少开发者的开发对接成本
便于二次开发
(3) 基于 Volcano 的 Jarvis 训练平台目前已经上线并运行良好
作者介绍:
本文转载自微信号容器魔方(ID:K8S-Huawei)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论