

欢迎阅读新一期的数据库内核杂谈。新一期的杂谈特别安排在中秋节后,祝大家中秋快乐(主要还是忙得又拖更了)。本期的杂谈继续来学习蒋晓伟老师发表在 VLDB2020 上的文章:Alibaba Hologres: A Cloud-Native Service for Hybrid Serving/Analytical Processing。这一期,着重介绍存储,执行的技术细节。
数据模型(Data Model)
首先介绍 Hologres 的数据存储模型(data model)。对于每一张表,用户需要设置一个 clustering-key 和一个全局唯一的 row locator(我觉得就可以理解为 row key)。如果 clustering-key 本身就是唯一的,就会被默认用作 row locator;如果不是,会有一个额外的唯一标识(uniquifier)和 clustering-key 组合成为 row locator <clustering-key, uniquifier>。
一个逻辑数据库(database)里面的所有 tables 都会按照某种规则组成多个 table groups(后续写作 TG)。这个规则可能是根据 access pattern 来定的。一个 TG,还会被进一步被分拆(shard)到多个 table group shards(后续写作 TGS)。每个 TGS,会保存一部分的 base data(理解为表数据)和与之对应的所有的 Indexes 信息。每一部分的 base data 加上相关的 indexes 信息就被划为一个 tablet。Tablet 有两种存储模式,row tablet(行存)和 column tablet(列存)。它们分别被用来针对点查询和分析型查询。一个 tablet,取决于 access pattern,可以被存为 row tablet,或者 column tablet,或者两者都存(可惜文中,并没有给出具体的 case,什么时候会存储成什么?让用户来设置的话,感觉有点复杂)。
Tablet 里存储的数据需要一个唯一的 key,所以对于 base data tablet 来说,上面讨论的 row locator 就能作为唯一的 key。对于 secondary indexes(二级索引)的 tablets 来说,如果这个 index 是唯一的,那 index column 本身就能成为唯一的 key。否则,base table 的 row locator 会被一起作用,作为唯一的 key <secondary_index, row_locator>。举个例子,假设一个 table 有 2 个二级索引,1 个是唯一的 key(k1->v1),另一个不唯一(k2->v2)。那么 base table 的 key 就是 <row_locator>,唯一 key 的二级索引的 key 就是<k1>,而非唯一 key 的二级索引的 key 就是<k2, row_locator>。
文中也介绍了,为啥要把多个 table 组合成 TGS。因为绝大部分的写入,会 access 一些相关的 table,已经对应的 indexes。把这些 tables 合成一个 TGS,就可以把相关的多个写操作转换成一个 atomic write,并且只有一个 write log entry 被记录到文件系统中,由此提升性能。此外,将经常需要被 join 的表组成 TGS,也能避免 join 的时候需要重新 shuffle 数据(如果基于同一个 row key 进行 hash 的话)。
Table Group Shard(TGS)介绍
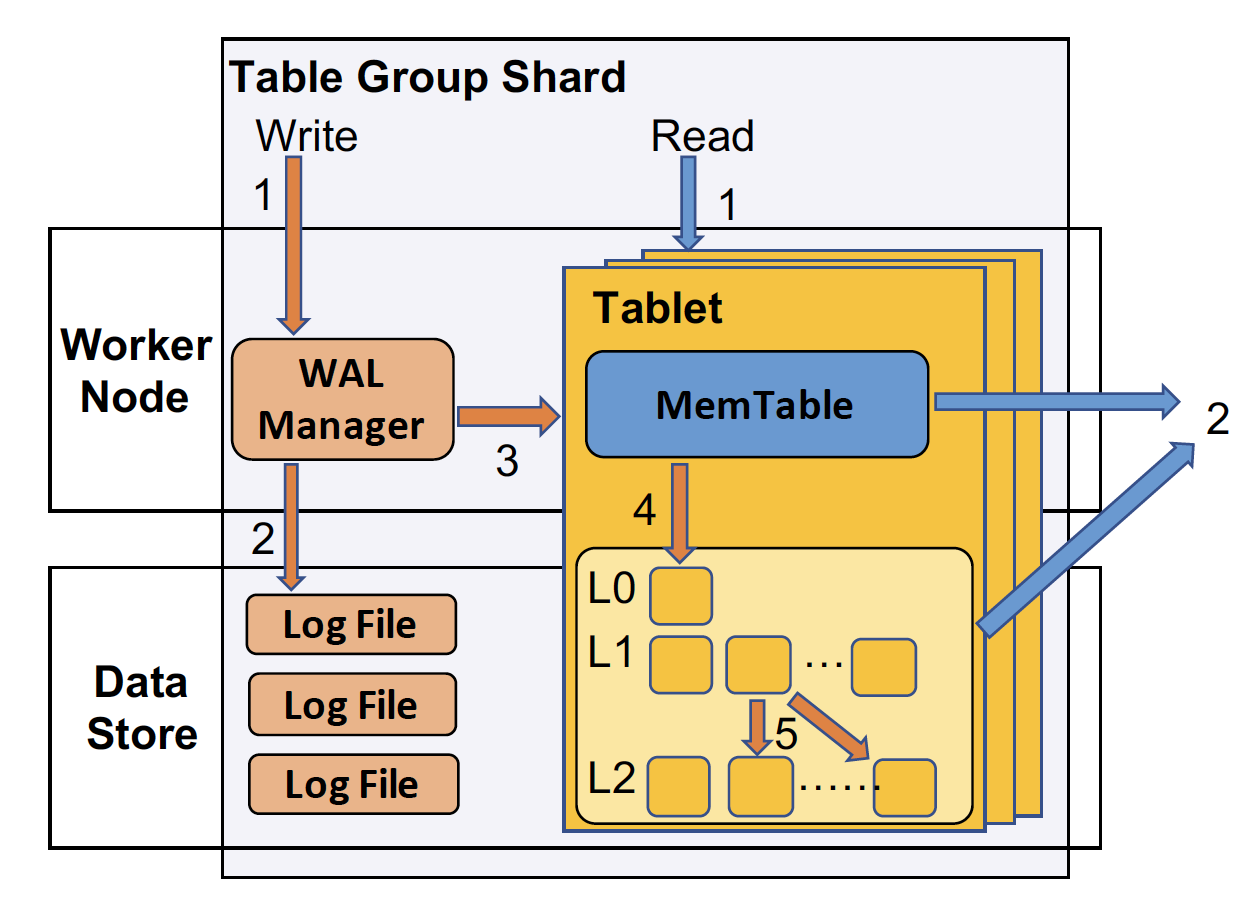
(TGS 介绍图片)
TGS 是 Hologres 里数据管理的基本单位。结合上面的 TGS 图片来讲解。一个 TGS 由一个 write ahead logger(WAL)和多个 tablet 构成。所有的 tablets,无论是 row tablet,还是 column tablet,都是以 log-structured-merge-tree(LSM tree)形式存储:一个 mem-table,和多 level 的不可变的 shard-tables=。所有的 shard-tables 都保存在 distributed file systems 里面(这边用的是阿里的盘古分布式文件系统)。LSM tree的工作方式就不在这边赘述了。 每个 tablet 也会保留一个 metadata 文件来记录这些 mem-table 和 shard-tables 的状态,和 RocksDB 的工作方式类似。所有的数据都有版本记录(MVCC),且读操作和写操作是完全分离的。并且,系统设计里保证一个 TGS 只有一个 writer 可以写 WAL,但允许多个 reader 同时读。
写操作:Hologres 支持两种类型的写操作:单 TGS 写和分布式批量写。这两种类型的写操作都可以被认为是原子的。单 TGS 写通过单个 writer 写 WAL 保证原子性,而分布式批量写通过两阶段事务保证。
单 TGS 写:继续结合上图来看。1)WAL manager 会给当前的 write request 分配一个 LSN(现在的时间戳和一个递增数字),2)创建一个 log entry(涵盖 replay 的所有数据)在 log 文件里。写操作等到 log 文件存储成功才 commit。3)写操作会作用到 tablet 的 mem-table 里。4)当 mem-table 写满的时候,会触发 LSM tree 写到 shard-tables 里。level compaction 是异步发生的。
分布式批量写:通过两阶段提交事务来保证原子性。FE(Front-end)节点在接到写操作时,会锁住所有需要参与的 TGS。然后,每个 TGS 会 1)获得一个 LSN,2)作用写操作到所有的 mem-tables,3)如果需要,触发 LSM tree 写。参与的 TGS 在完成操作后会发结果 vote 给 FE,FE 会决定是否要 commit 还是 abort。如果 FE 决定 commit,每个 TGS 会 commit log,否则,前面的操作都会被作废(典型的两阶段提交)。
分布式 TGS 管理:文中也快速讨论了一下分布式的 TGS 管理,目前,TGS 的 writer 和多个 reader 都是 co-located 在一个节点上,但 Hologres 在支持允许 read-only replicas 部署在一个 remote 节点上来进一步平衡读写负担。并且支持两种 read-only replicas:1)完全 synced replicas 可以支持任何读操作,2)部分-synced replicas 来支持数据只存在 shard-tables 里的数据。
Row Tablet 介绍
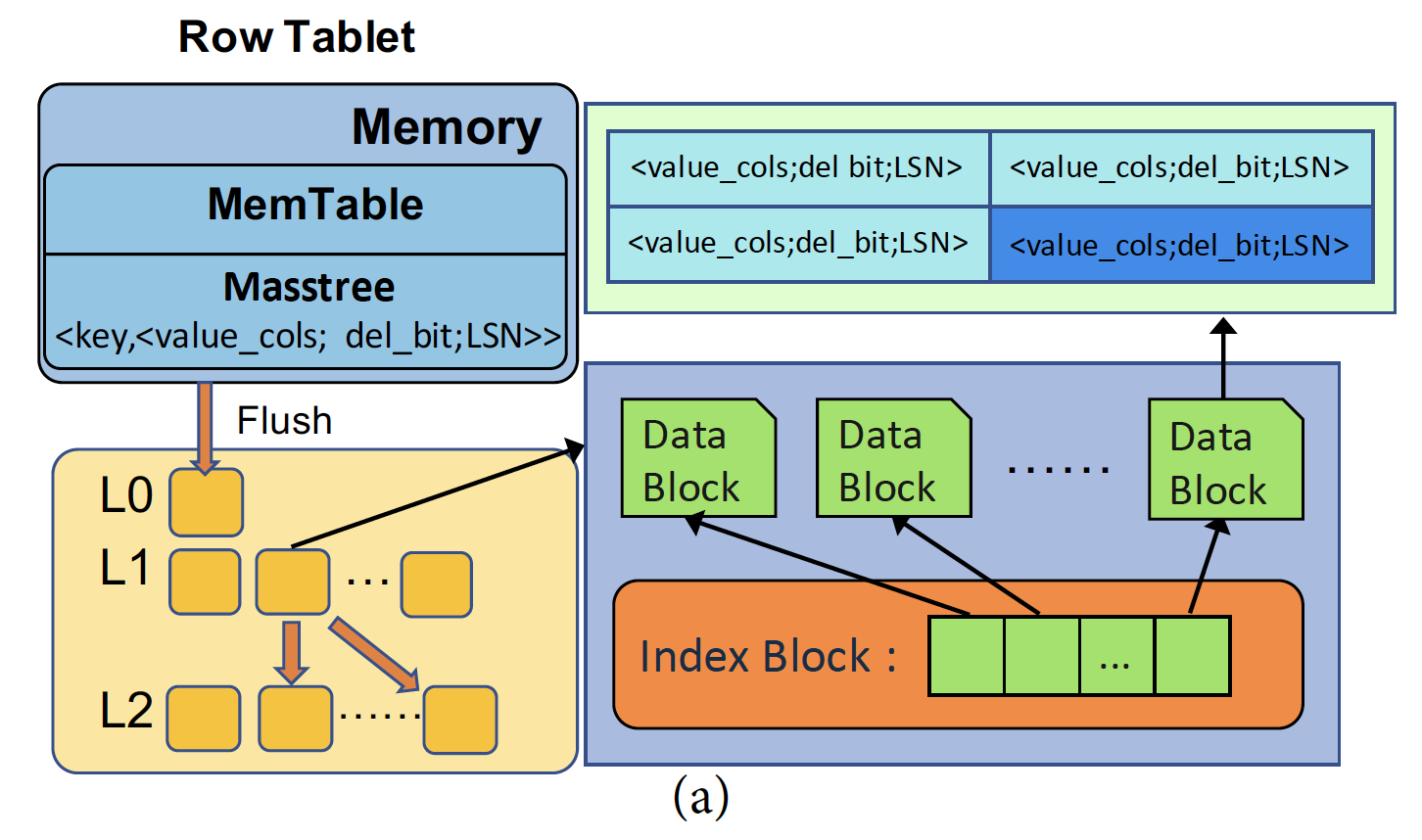
(Row Tablet 介绍图片)
Row tablet 是针对高性能的点查询做优化支持的。结合上述图片来看 Row tablet 的结构:Row tablet 的 mem-table 结构是 Masstree,数据是按照 key 进行排序的。而写到文件中的 shard-文件则被分为了数据 block 和 index block。index block 记录了每个 data block 的 offset 以及对应的 starting key 来加速读取。
为了支持 mult-version data,Value 值存了三类信息<val_cols, del_bit, LSN>:一是 non-key 的 value columns 的值; del_bit 代表这行是否被删除了;和 LSN version 信息。
读操作:每个读操作需要输入读 key 和 LSN。结果的获取类似于读 LSM-tree,通过读取 mem-table 和文件系统重的 shard-table;只有有 key 重合的 shard-table 文件才会被扫描。
写操作:典型的 LSM-tree,会 specify column-values,del_bit 和 LSN。如果 mem-table 满了,会 trigger flush 到 shard-table 上。
Column Tablet 介绍

(Column Tablet 介绍图片)
相对于 row tablet, column tablet 用来更好地支持某个 column 的 scans。结合图片来介绍。和 row tablet 不同的地方在于,column tablet,除了维护一个 column-store 的 LSM tree,还需要额外维护一个 delete map(由于是 column store 的限制)。Column tablet 的 mem-table 的存储格式是 Apache Arrow(一种高效的 columnar memory format)。数据会按照顺序被写进 mem-table 里面。在文件系统的 shard-table 里,数据依然是按照 key 来排序,但从逻辑上被划分为 row groups。某一个 column,它的值按照 row group 的划分,会存储到不同的物理 data block 上。一个 column 的 data blocks 会被连续的存储在一起来支持 sequential scan。同时在,shard-file 里,会保存 index-block 和 meta block 来加速读取,index-block 存储了 row 相关的信息,而 meta block,则存储了每个 column 的 data block 的相关信息,比如 offset, value ranges, total row count 等等。
delete map 本身其实是一个 row tablet:key 就是 shard file 或者 mem-table 的 ID,然后 value 就是一个 bitmap 来表示这个 shard-file 里面,哪些 records 被删除了。
读写操作本质都是对 mem-table 以及 shard-file 的 flush 操作,和 row-table 并没大区别。
Hierachical cache
文中也介绍了 Hologres,为了进一步提升性能,采用了多阶段的 caching 来减少 IO 和计算 cost:local disk cache, block cache 和 row cache。Local disk cache 就是用来 cache shard-files 来避免频繁数据的 IO 读写操作。在这之上,内存为主的 block cache 用来存储 shard-file 里面的读取的 blocks。在 block cache 上,我们还保留了一层内存机制的 row cache 来存储最近被查询过的 row tablets,以加速读取。
Query Execution Pattern
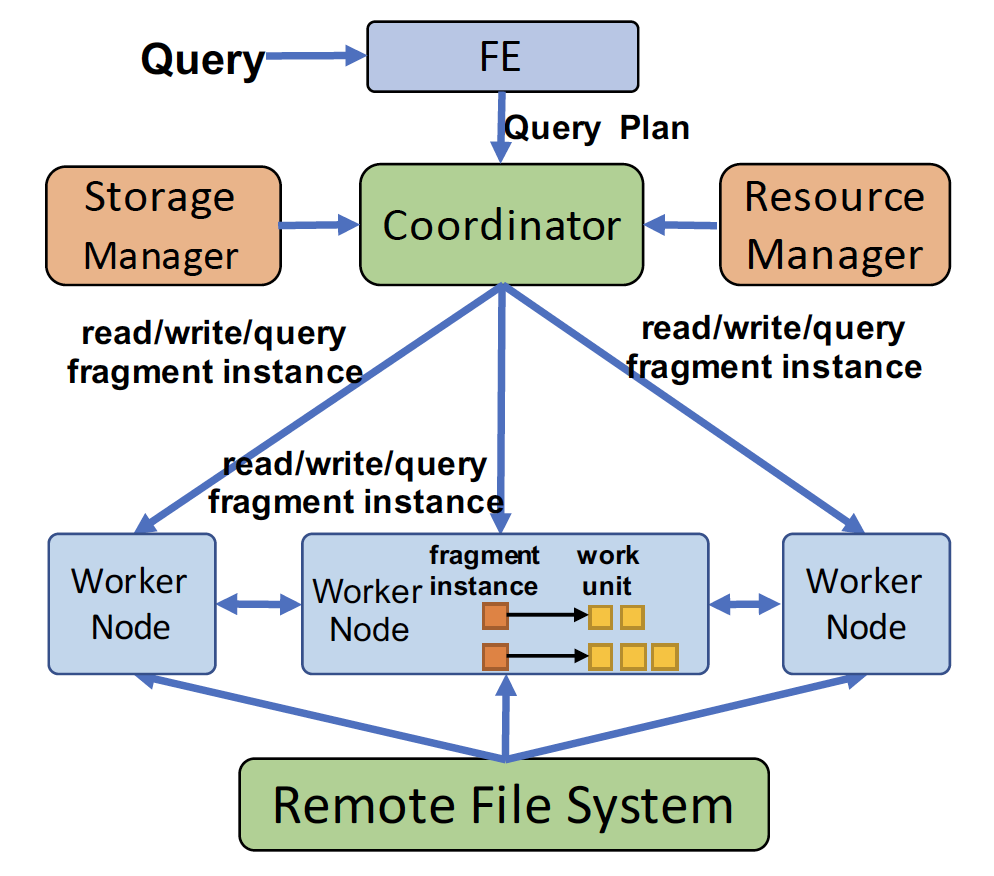
(Query Execution 示例图)
结合图片来看 Hologres 在收到一个查询请求后,是如何一步一步执行的。1)在收到查询语句后,在 FE 节点上的 query optimizer 会生成一个 DAG 的执行计划;并且把这个计划按照 shuffle boundaries(类似于 map-reduce 里面的 map-reduce 阶段)划分成多个阶段(fragments)。Fragments 有三种,读,写 fragments,以及数据处理 fragments。每个 fragments 可以生成多个并行的 instances 来处理相应的数据。比如,对于每一个 TGS,都可以起一个并行的 reader 或者 writer fragment。
FE 节点会把这个执行计划发给 coordinator 节点,然后被 coodinator 节点分发到相应的 worker 节点上。读写 fragments 总是会被分派到 host 某个 TGS 的 worker 节点,数据处理节点可以被任意分配,来保持 load balancing,并且也会考虑到数据传输的 local 性。在每个 worker 节点里,一个 fragment 可以进一步被拆分成多个 work units(WU)来做具体的执行工作。WU 是执行的基本单位。
Execution Context
另一个值得一提的优化就是 Hologres 构建的 execution context。因为 Hologres 需要支持多用户的并发查询需求。这会导致多个 WU 同时执行的时候会不可避免地进行 context switch。而过多的 context switch 会造成性能瓶颈。为了解决这个问题,Hologres 构建了一个 user-space thread(就是协程吧),称为 execution context(EC),用来记录 WU 的资源使用情况。调度 EC 不会牵涉到任何系统调用,所以 EC 之间的 context switch 就非常小。Hologres 以 EC 为调度基本单位,计算资源也以 EC 的粒度被分配。EC 在执行中,会跑在一个线程上。
Pull-based query execution
Hologres 采用了类似于 Volcano 模式的执行计划,异步的 pull-based query execution。首先由 coordinator 会发送 pull request 到底层的 WU,WU 会继续发送 pull request 到下游 WU 里,直至到 leaf WU,会开始读取 mem-table 或者 shard-file 里的数据。这个和大部分的执行引擎类似。
总结和一些思考
读完整篇 paper,最让我觉得最最创新的地方应该就是在 Tablet 中支持了 row tablet 和 column tablet 来同时优化OLTP和OLAP workloads。其他的NewSQL系统可能选择在更上层的架构中支持全部:比如通过 CDC 同步 OLTP 的数据到 OLAP 系统中。目前另一趋势就是 updatable data structure 比如Apache Hudi和Apache Iceberg。目前工作的团队也在这方面探索,我也想借这个机会深入学习一下,以后写到内核杂谈和大家分享。感谢阅读!
内核杂谈微信群和知识星球
内核杂谈有个微信群,大家偶尔会讨论些数据库相关话题。但目前群人数超过 200 了,所以已经不能分享群名片加入了,可以添加我的微信(zhongxiangu)或者是内核杂谈编辑的微信(wyp_34358),备注:内核杂谈。
除了数据库内核的专题 blog,我还会 push 自己分享每天看到的有趣的 IT 新闻,放在我的知识星球里(免费的,为爱发电),欢迎加入。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 4 条评论