
软件测试,特别是在大型项目中,是一个非常耗时的过程。测试套件可能计算成本高昂,互相竞争可用的硬件,或者是导致相当大的结果延迟。在实践中,可能出现运行几个小时甚至几天的情况。这也会影响到开发人员;等待测试结果的时间过长,可能意味着一旦发现错误,就不得不重新熟悉自己的代码。
这远远不是一个学术问题:由于需要进行大量的构建和测试,在一天的时间里,Siemens Healthineers 的测试环境并行执行的测试加起来有 1-2 个月的时间。虽然可以横向扩展,但受限于可用的硬件,效率并不高。因此,值得探索下用不同的方式优化测试执行,节省机器资源,缩短向开发人员反馈的时间。
在提交时预测测试结果
经典的软件开发过程会产生大量有用的数据。特别是源码控制系统和测试执行日志包含的信息可用于机器学习的自动推理;结合这些数据,特别是在哪个代码修订版上观察到哪个测试结果,可以创建一个有标签的数据集用于监督学习。
这种标注可以自动完成,不需要人类参与,这意味着我们可以快速收集大量的训练数据。然后,针对特定的提交,典型的监督学习算法就可以利用这些数据预测失败的测试。
使用决策树来实现这种方法(更多信息参见scryer-ai.com和 InfoQ 的文章“用机器学习预测失败的测试”),使得系统能够以平均 78%的准确率预测 79361 个真实测试用例的结果;每个测试用例都有自己的模型,在可用数据的不同部分上进行了多次训练,以观察数据选择的影响。每次运行的准确率都通过宏平均法进行汇总。图 1 显示了所有测试用例的平均准确率分布。
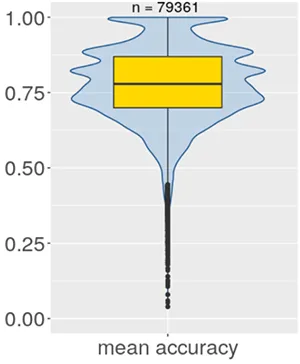
图 1:测试结果预测的准确率
这些模型的平均准确率的中位数为 0.78。虽然有一些测试用例的平均准确率较低,但大多数是离群值,即只占少数。这也可以从 25%四分位数为 0.7 得到证明,这意味着,对于四分之三的测试用例,模型的平均准确率为 70%或更高。这满足了项目最初的需求,即无需实际执行测试即可获得快速反馈。除了运行测试并稍后获得结果外,开发人员可以在提交后几秒钟内访问预测结果,并根据测试失败的可能性采取合适的步骤。
数据集成的额外好处:减少“缺陷烫手山芋”
集成源码控制和测试结果数据开辟了一个“额外的”用例,即在多团队环境中实现缺陷的正确路由。有时候,有一些缺陷/问题不清楚应该分配给哪个团队。通常情况下,如果有两个以上的团队,要找到合适的团队来处理一个修复问题就很麻烦。这可能会导致团队之间的缺陷乒乓,因为在缺陷最终被分配给合适的团队之前,没有人觉得应该负责。
由于 Siemens Healthineers 的数据也包含了变更管理日志,所以有关于缺陷及其修复的信息,如哪个团队进行了修复或哪些文件被更改。在许多情况下,有一些测试用例会关联到缺陷——有的是已有的测试用例,在发布前运行测试时发现问题,有的是新增的测试,因为发现了测试空白而增加的。这样就可以解决”缺陷烫手山芋“这个问题了。
缺陷与测试用例有多种关联方式,如一个测试用例在缺陷描述中被提到,或者缺陷管理系统支持在缺陷和测试用例之间建立明确的链接。如果缺陷之间共享测试用例,那么就将它们定义为“相似的”。如果出现新的缺陷,则按照之前修复类似缺陷的团队对缺陷做聚合,通常,会有一个团队会最适合承担修复任务——例如,“团队 A 修正了 42 个类似缺陷,而团队 B 修正了 7 个”,诸如此类。
这种分析甚至不需要任何机器学习——它只需要在为预测而收集的数据集上做几个查询(见上文)。对来自 92 个团队的 7470 个缺陷进行评估,返回三个最合适的团队,召回率约为 0.75,也就是说,合适的团队将以 75%的概率被检索出来——反过来说,这意味着派工的人通常只需要考虑一小部分团队,而不是全部 92 个团队。
顺便说一下,这里有一个有趣的更大的原则在起作用——ML 领域流传着这样一种说法,ML 项目中 80%的工作是数据收集和准备。既然已经付出了这样的努力,那么有必要研究一下在最初的用例之外还有什么好处。
利用预测来优化测试套件
另一个用例是利用系统的输出优化测试套件。将提交(或者更确切地说,它的元数据)输入到系统中,输出一个测试用例列表,其中每个用例都有一个失败或通过的预测。此外,每个测试用例会报告它先前运行训练时的准确性——举例来说,大概是这样,系统报告”根据模型,测试用例 A 将失败。在过去所有用例中,对于测试用例 A 的结果,预测正确率为 83%“。对于系统已知的所有测试用例,它都这样做。将报告的准确率解释为预测结果出现的概率(这并不完全相同,但对于这个用例来说已经足够接近了),我们可以根据失败的概率对测试用例列表进行排序。
这样,我们也可以改变测试套件的顺序,按照失败概率的降序执行测试用例,这样就可能更早地发现失败。我们在测试套件的大约 33000 次实际运行中验证了这一点(包括近 400 万次不同的测试执行),并比较了到达第一个失败结果的时间。我们发现,如果按照实际的顺序,测试套件到达第一个失败结果的中位数为总执行时间的 66%。基于预测重新排序后,这将减少到 50%(见图 2)。在有些情况下,重新排序会增加测试运行的时间(不出所料,没有一个模型是 100%正确的),但总体而言会节省计算时间,例如在有门控签入的情况下。直接比较这两种方法,预测顺序在约 57%的情况下胜出,约 10%是平局,而通常的顺序只在 33%的情况下胜出——这很好,因为这意味着我们明显地节省了时间(见图 3)。在一次测试运行中,实际失败的结果越多,这种效果就越明显,但即使只有一次失败,平均而言,预测的顺序也比实际的顺序好。
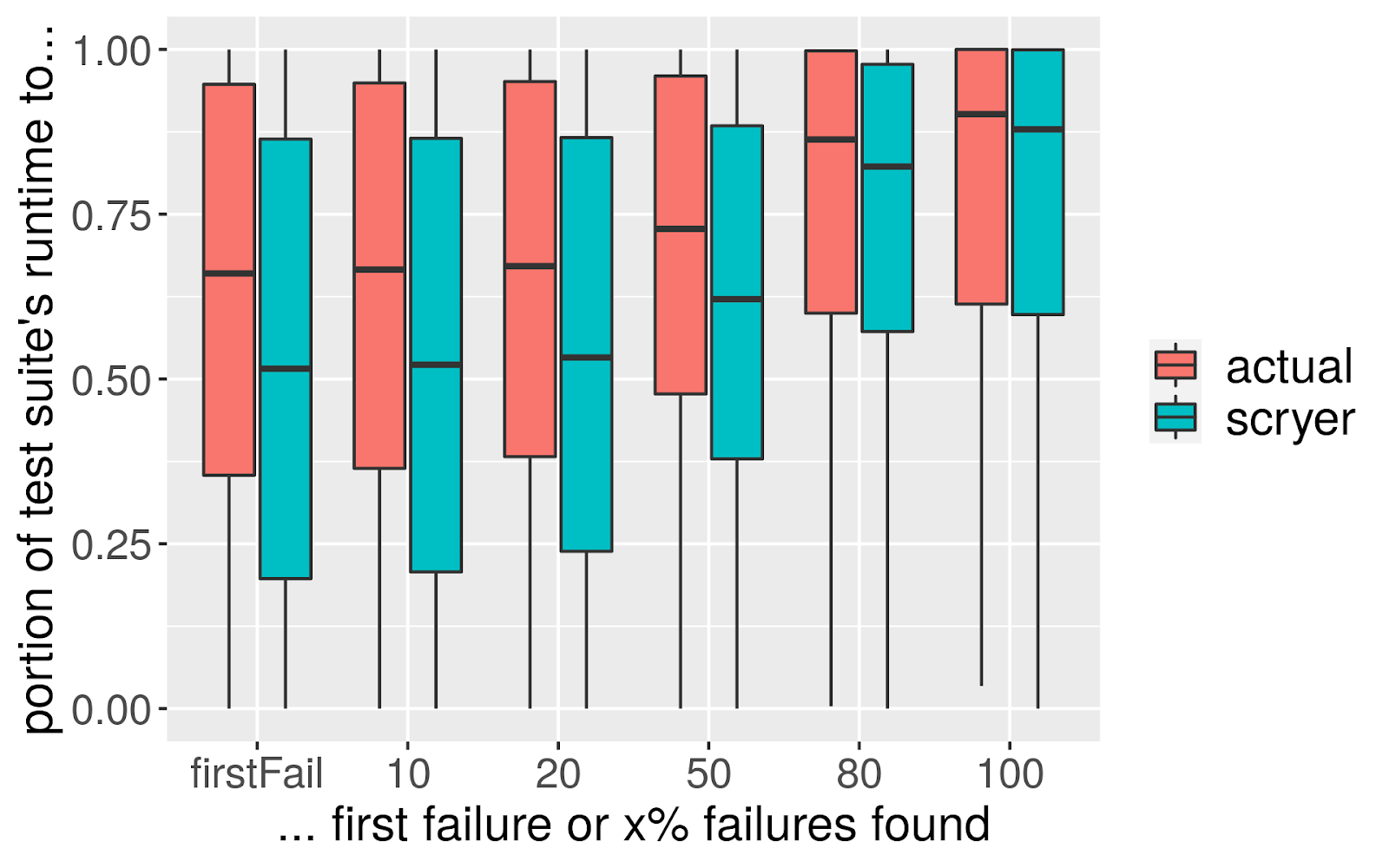
图 2:发现第一个/10/20/50/80/100%失败消耗的时间
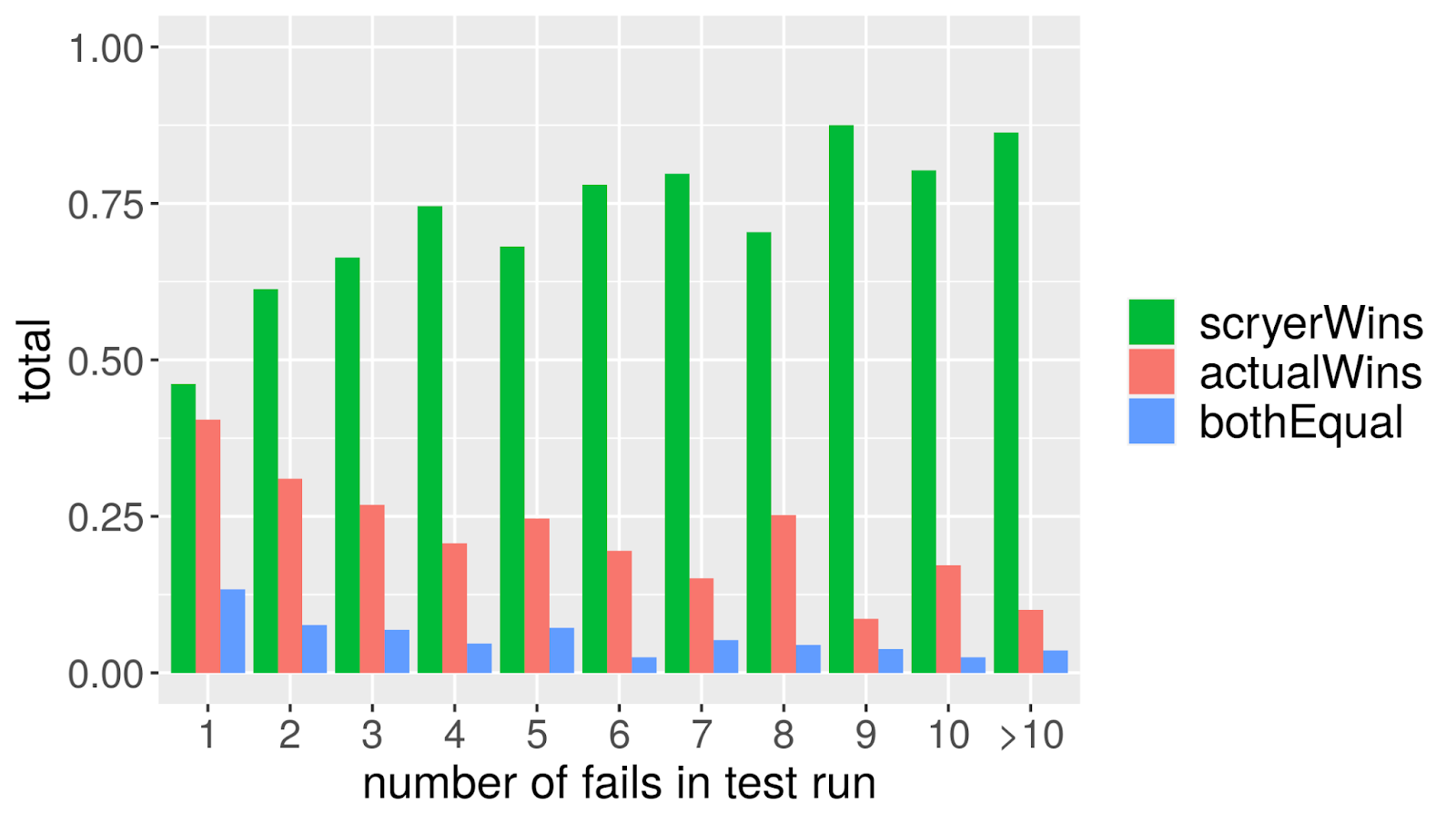
图 3:预测顺序与实际顺序对比
通过模拟现实世界的应用,计算和比较预测顺序和实际顺序的测试总运行时间,发现预测顺序能够将运行时间减少~10%。具体来说,对于 Siemens Healthineers 的测试执行,这相当于减少了 418.25 小时的运行时间。在实践中,这意味着可以减少测试机器的数量,降低资源或管理任务的成本。
实践应用
上述评估结果表明,该方法在真实数据上有效。
从评估阶段到将结果付诸实践,工作重心将从快速实验转向工程。用于源码控制和测试结果存储的具体系统各不相同,这就是为什么与 Scryer API 的连接器必须要根据领域甚至具体的客户来定(图 4 中用”Arbitrary API“表示)。
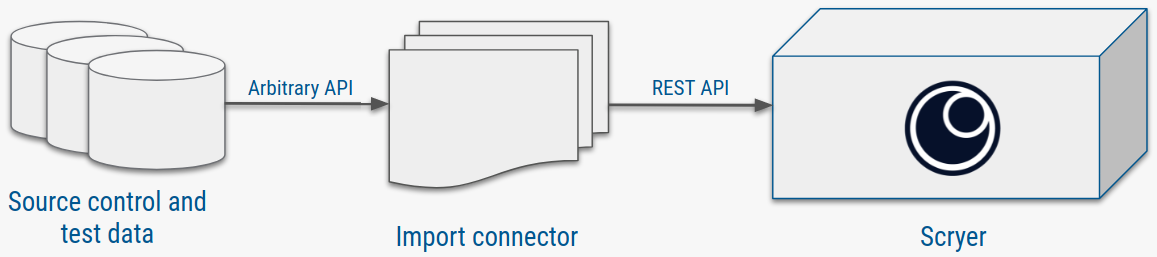
图 4:数据集成
一旦连接到 Scryer REST API,就可以以恰当的格式持续地摄入数据供机器学习使用了。
在管道的另一端,推理功能的 REST 端点将训练好的模型开放给感兴趣的人,例如为开发人员提供反馈的 IDE 插件或将测试套件重新排序的测试调度器(见图 5)。
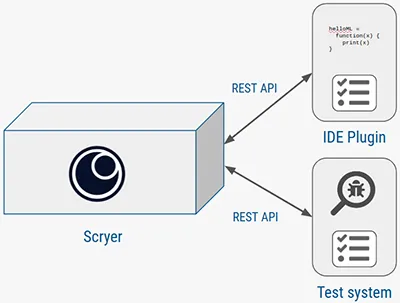
图 5:推理
摄取步骤需要在源码控制和测试结果之间显式地建立起链接——这个过程本身就可能启发人们对组织中已有的数据做新的思考,并可能开辟出新的数据分析方法。例如,将所有的测试结果放在一个统一的数据库中,可以检查出在数据所在的时间范围内从未失败的测试。这些测试用例在测试套件的审查候选用例中优先级较低,甚至可能被删除。将源码版本附加到测试上,可以方便地监控不稳定的测试,即在同一源码上得出不同结果的测试。
主要的经验教训
对于上述所有情况,数据质量是关键。在项目过程中,这主要意味着要修改已经存在的不同数据源之间的连接方式;一般来说,在大型项目中,很可能有数个独立的数据源,因为不同方面会有不同的工具。对于许多有趣的分析,特别是对于机器学习,确保不同数据源之间的可追溯性是很重要的。这甚至可能意味着在收集的数据上构建一个总体的领域模型,或者包括额外的解析和挖掘步骤来发现数据之间的关系。
另一个方面是关于扩展的问题;在我们的案例中,系统从一个单进程单线程的应用程序发展到多线程,然后是多进程,最后是多容器。在实验阶段,将脚本化的数据收集与分析和 ML 混在一起可能没什么问题。然而,当投入生产应用时,需要有可扩展性,以便能够消化传入的数据量。还需要保持管道中不同的项目相互独立,以确保它们不会相互干扰。
在“人”的方面,要考虑到使用新技术或目前热炒的技术推出新工具的特殊性。特别是当向技术人员推广时,他们对工具的机制更感兴趣,而不是它在日常工作中给他们带来什么好处。因此,在开始的时候,说明它的工作机制和实际处理的内容非常重要。这里可以运用传统的变更管理技术,那会很有帮助。
最后但同样重要的是,检查下组织中的数据源。通常情况下,黄金近在眼前。你不需要成为一个数据挖掘专家——只需要对已有的数据以及如何将它们连接起来有一个更高阶的看法,就已经足以迅速回答开发周期中非常紧迫的问题。无论是否应用机器学习或人工智能方法,这都是有好处的。
作者简介:
Gregor Endler 拥有计算机科学博士学位,他的论文是关于时间戳数据的完整性估计。他在 codemanufaktur 公司的工作涉及机器学习和数据分析。
Marco Achtziger 是 Siemens Healthineers 的一名测试架构师。他拥有 iSTQB/iSQI 的多项资质,是西门子公司的认证软件架构师,同时也是测试架构师课程的培训师。
原文链接:
Using Machine Learning for Fast Test Feedback to Developers and Test Suite Optimization




