
过去十年中,人工智能行业的一大趋势就是通过创建更大的深度学习模型来解决问题。这种趋势在自然语言处理领域最为明显,这也是人工智能最具挑战性的领域之一。
近年来,研究人员已经证明,向神经网络添加参数可以提高它们在语言任务上的表现。然而,语言理解的根本问题——单词和句子下隐藏的,名为含义的冰山——仍有待解决。
伦斯勒理工学院两位科学家的著作《人工智能时代的语言学》讨论了当前各种自然语言理解(NLU)方法的缺点,并探索了一些开发先进智能代理的未来途径——这些智能代理可以与人类自然交互,而不会让交流陷入困境或犯愚蠢的错误.
《人工智能时代的语言学》的作者 Marjorie McShane 和 Sergei Nirenburg 认为,人工智能系统不能止步于对单词的操纵。在他们的书中,他们证明了 NLU 系统可以理解世界,向人类解释它们获得的知识,并在它们探索世界时不断学习。
基于知识的系统与知识精益的系统
考虑这句话,“I made her duck.”这句话的主题是扔了一块石头让对方弯下腰,还是他给她煮了鸭肉?
现在再考虑这句话:“Elaine poked the kid with the stick.”Elaine 是用棍子戳了那个孩子,还是用她的手指戳了碰巧拿着棍子的孩子?
语言充满了歧义。我们人类使用语言的上下文来解决这些歧义。我们使用来自说话者的语气、先前的单词和句子、对话的一般性设置以及关于世界的基本知识等线索来建立上下文。当我们的直觉和知识未能解决歧义时,我们会提出问题。对我们来说,确定上下文的过程是很容易的。但要以可计算的方式定义这种过程,那就是说起来容易做起来难了。
通常有两种方法可以解决这个问题。

人工智能时代的语言学——Marjorie McShane 和 Sergei Nirenburg
在之前几十年的人工智能研究中,科学家使用基于知识的系统来定义句子中每个单词的作用,并以此提取句子的上下文和含义。基于知识的系统依赖于大量关于语言、情境和世界的特征。这些信息可以来自不同的来源,并且必须以不同的方式计算。
基于知识的系统提供了可靠且可解释的语言分析结果。但它们最后失宠了,因为它们需要太多的人力来设计特征、创建词汇结构和本体,和开发将所有这些部分结合在一起的软件系统。研究人员将知识工程中的人工环节视为一种瓶颈,并寻求其他方法来应对语言处理过程。
“人们普遍认为,克服这种所谓知识瓶颈的任何尝试都是徒劳的;而这种看法也深刻地影响了通用人工智能,尤其是 NLP[自然语言处理]的发展道路,使该领域远离了理性主义和基于知识的方法,并导致了 NLP 中经验主义、知识精益、研究和开发范式的出现,”McShane 和 Nirenburg 在《人工智能时代的语言学》中写道。
近几十年来,机器学习算法一直是 NLP 和 NLU 的核心。机器学习模型是一种知识精益(knowledge-lean)系统,它试图通过统计关系来处理上下文问题。在训练期间,机器学习模型处理大量文本,并根据单词彼此之间的位置关系调整其参数。在这些模型中,上下文是由单词序列之间的统计关系,而不是单词背后的含义来决定的。自然,数据集越大、示例越多样化,这些数值参数就越能捕捉单词彼此之间的各种位置组合。
知识精益系统之所以能流行,主要归功于可用来训练机器学习系统的大量计算资源和大型数据集。借助维基百科等公共数据库,科学家们能收集到庞大的数据集,并针对翻译、文本生成和问答等各种任务训练他们的机器学习模型。
机器学习不计算含义
如今,我们的深度学习模型可以生成文章篇幅的文本序列、回答科学考试问题、编写软件源代码以及回答基本的客户服务咨询问题。由于深度学习架构的种种改进(LSTM、transformer),更重要的是由于神经网络每年都在变大,这些领域中的大多数都取得了进展。
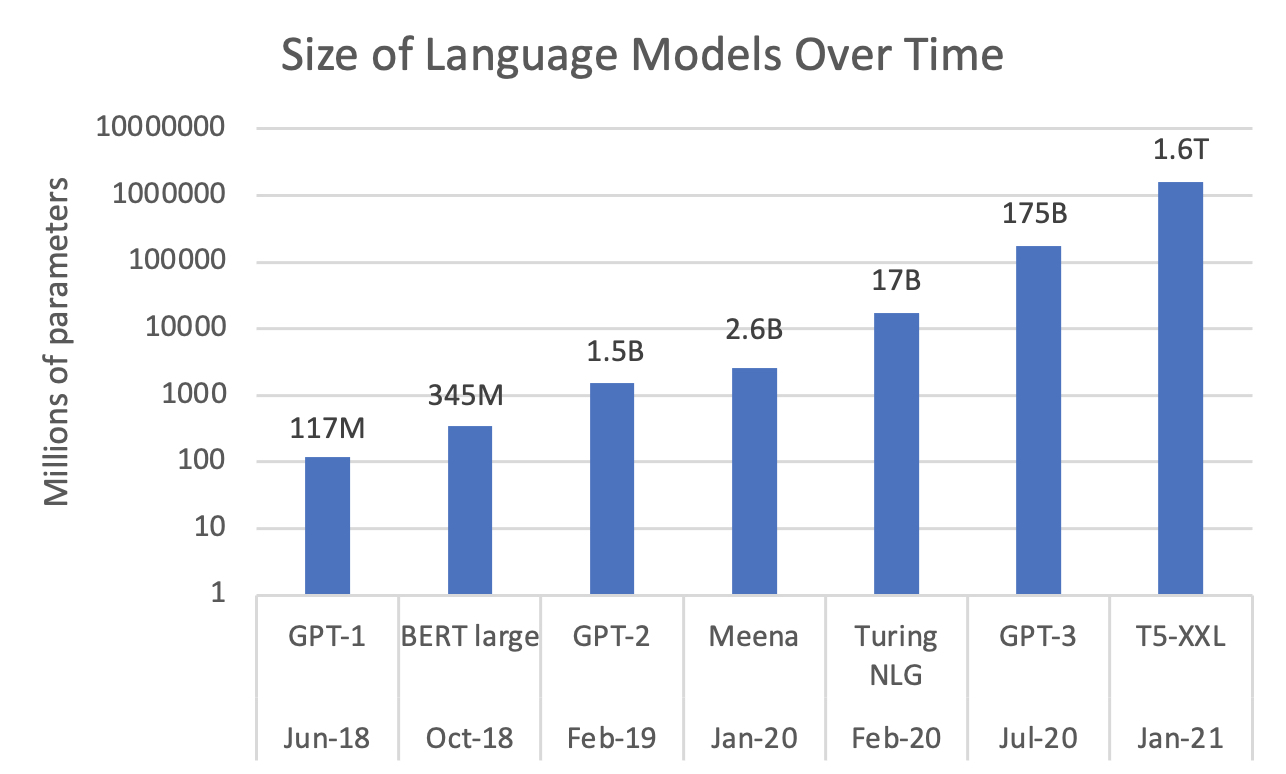
近年来,深度学习语言模型的规模不断扩大(以对数尺度制图)
但是,虽然更大的深度神经网络可以为许多任务类型提供增量改善,但它们并没有从宏观层面上解决自然语言理解的一般性问题。这就是为什么各种实验都表明,即使是最复杂的语言模型也无法解决关于世界是如何运作的一些简单问题。
在他们的书中,McShane 和 Nirenburg 将当前人工智能系统所解决的问题描述为“唾手可得的果实”。一些科学家认为,神经网络继续扩展下去,终有一天会解决机器学习所面临的问题。但 McShane 和 Nirenburg 认为我们需要解决一些更本质的问题。
“这样的系统并不像人类那样思考:它们不知道自己在做什么以及为什么这样做,它们解决问题的方法与人类不同,而且它们不依赖于世界、语言或代理的模型,”他们写道。“相反,它们在很大程度上依赖于将通用机器学习算法应用于更大数据集的路径,并得到了现代计算机惊人的速度和存储容量的支持。”
在 TechTalks 上发表的评论中,认知科学家和计算语言学家 McShane 表示,机器学习必须克服几个障碍,其中首当其冲的是含义的缺失。
“统计/机器学习(S-ML)方法并不会去计算含义,”McShane 说。“相反,从业者一路向前,就好像只凭单词就足以代表句子的含义一样,而事实并非如此。实际上,当涉及到句子的完整上下文含义时,句子中的单词只是冰山一角。将词语与含义混淆的这种人工智能方法,就像一艘驶向冰山的巨轮一样令人担忧。”
在大多数情况下,机器学习系统通过缩小任务范围或扩大训练数据集来回避处理单词含义的问题。但是,即使一个大型神经网络设法在相当长的一段文本中保持了连贯性,但在背后,它也仍然无法理解它所生成的那些单词的含义。
“当然,人们可以构建看起来表现得很聪明的系统(例如 GPT-3),只不过这些系统真的不知道到底发生了什么事情,”McShane 说。
一旦你问一系列简单但互相关联的问题,所有基于深度学习的语言模型就会开始崩溃,因为它们的参数无法捕捉日常生活中潜藏的无限复杂性。在这个问题上投入更多数据并不能将知识显式集成到语言模型中。
语言赋能的智能代理(LEIA)

Marjorie McShane 和 Sergei Nirenburg,《人工智能时代的语言学》的作者
在他们的书中,McShane 和 Nirenburg 提出了一种解决自然语言理解过程中“知识瓶颈”的方法,这种方法无需求助于需要大量数据的纯机器学习手段。
《人工智能时代的语言学》的核心是称为“语言赋能的智能代理(LEIA)”的概念,其具有三个关键特征:
LEIA 可以理解语言的上下文相关含义,并从单词和句子的歧义中找到合适的理解。
LEIA 可以向它们的人类合作者解释它们的想法、行动和决策。
与人类一样,LEIA 可以在与人类、其他代理和世界互动时进行终身学习。终身学习(Lifelong learning)减少了为扩展智能代理的知识库而持续投入人力的需求。
LEIA 通过六个阶段来处理自然语言,这些阶段从确定单词在句子中的作用到语义分析,最后是情境推理。这些阶段让 LEIA 可以解决单词和短语的不同含义之间的冲突,并将句子整合到代理正在处理的更广泛的上下文中。
LEIA 为它们对语言表达的各种解释分配置信度,并且知道它们的技能和知识何时不足以解决歧义。在这种情况下,它们与人类同行(或它们环境中的智能代理和其他可用资源)互动以解决歧义。这些互动反过来又让它们能够学习新事物并扩展它们的知识。
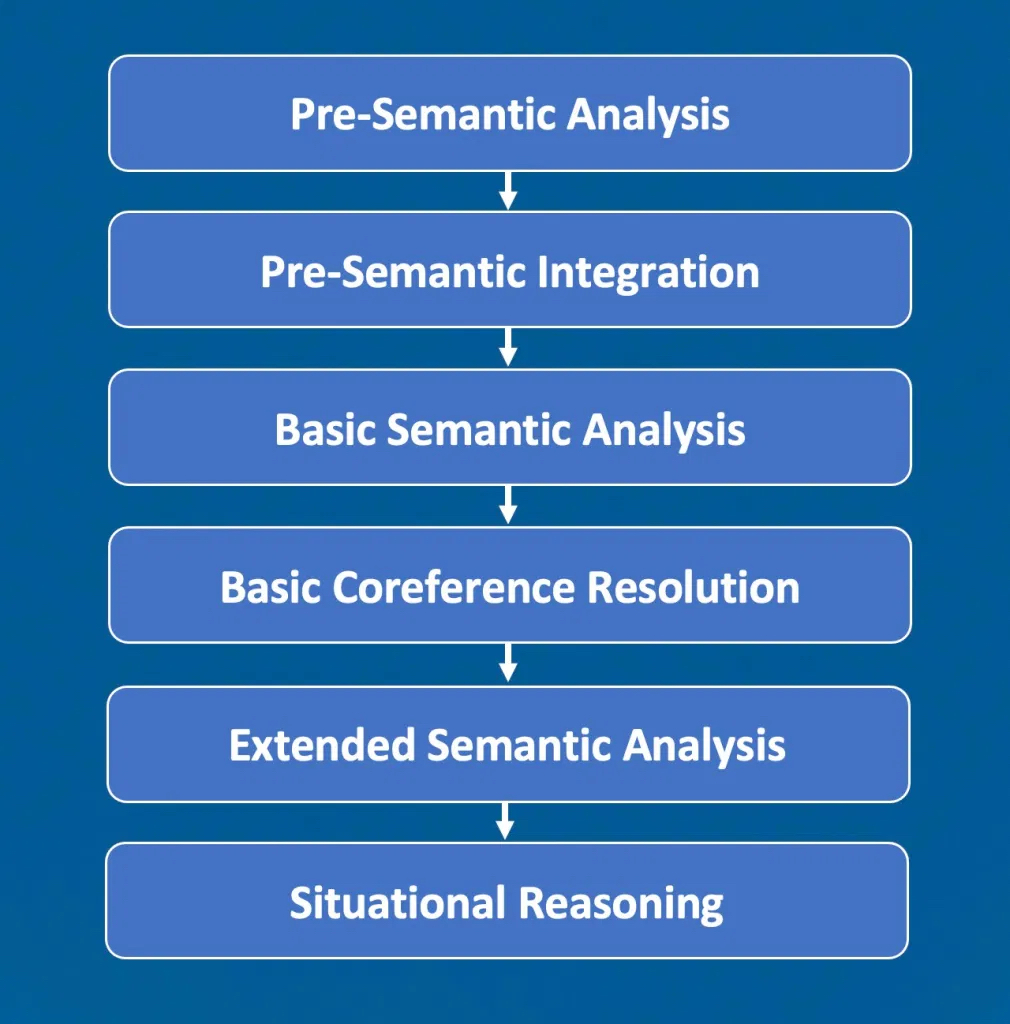
LEIA 分几个阶段处理语言输入
LEIA 将句子转换为文本含义表示(TMR),这是对句子中每个单词的可解释和可操作的定义。LEIA 根据它们的上下文和目标来确定需要跟进哪些语言输入。例如,如果一个维修机器人与几位人类技术人员共用一个机器维修车间,并且人类在讨论昨天的体育比赛结果,那么人工智能应该能够分辨出哪些对话与其工作相关(机器维修),哪些是它可以忽略的(运动)。
LEIA 倾向于使用基于知识的系统,但它们也在流程中集成了机器学习模型,尤其是在语言处理一开始的句子解析阶段。
“我们很乐意集成更多 S-ML 引擎,只要它们能够提供各种类型的高质量启发式证据(但是,当我们合并黑盒 S-ML 结果时,代理的置信度估计和可解释性都会受到影响),”McShane 说。“我们也期待结合 S-ML 方法来执行一些面向大数据的任务,例如选择示例来辅助阅读学习过程。”
语言理解需要人脑复制品吗?

LEIA 的主要特征之一是知识库、推理模块和感官输入的集成。目前,计算机视觉和自然语言处理等领域之间几乎没有重叠。
正如 McShane 和 Nirenburg 在他们的书中指出的那样,“语言理解不能与整体的代理认知过程区分开来,因为支持语言理解的启发式方法也要运用其他感知模式(例如视觉)生成的结果,来推理说话者的计划和目标,并推理需要花费多少资源来理解困难的输入。”
在现实世界中,人类利用他们丰富的感官体验来填补语言表达的空白(例如,当有人对你说“看那边?”时,他们假设你可以看到他们的手指指向的地方)。人类进一步开发了理解彼此思维的模型,并使用这些模型做出假设并忽略语言中的细节。我们希望任何以我们自己的语言与我们交互的智能代理都具有类似的能力。
“我们完全理解为什么现在孤立方法成了常态:每种问题解释起来都很困难,每个问题的实质都需要单独分析,”McShane 说。“然而,如果没有集成,所有问题的实质层面都无法解决,因此重要的是要抵制(a)假设模块化必然会导致简化,以及(b)无限期地推迟集成的想法。”
同时,实现类似人类的行为并不需要 LEIA 成为人类大脑的复制品。“我们同意Raymond Tallis(和其他人)的观点,即他所谓的神经躁狂症——渴望解释作为一个生物实体的大脑可以告诉我们哪些关于认知和意识的内容——导致了许多无法真正解释的可疑主张和解释,”McShane 说。“至少在当前的发展阶段,神经科学无法为我们的认知建模类型和目标提供任何内容(句法或结构)支持。”
在《人工智能时代的语言学》中,McShane 和 Nirenburg 认为复制大脑不符合 AI 的可解释性目标。“运行在人类代理团队中的[代理],需要在一定程度上了解输入,以确定它们应该追求哪些目标、计划和行动,来作为 NLU 的输出结果,”他们写道。
一个长期目标

《人工智能时代的语言学》中讨论的许多主题仍处于概念层面,离实现还有很长的距离。作者提供了 NLU 的每个阶段应该如何运作的蓝图,尽管实际的系统尚不存在。
但 McShane 对 LEIA 的发展持乐观态度。“从概念和方法来说,工作进展都是非常顺利的。主要障碍是在当前的行业氛围下缺乏资源来分配给基于知识的方法,”她说。
McShane 认为,在批评基于知识的系统时,焦点都集中在知识瓶颈上,但其实这种批评在几个方面都有误导性:
实际上并不存在所谓的瓶颈,只要向前迈步就对了。
相关工作在很大程度上可以自动执行,可以让代理通过自己的操作学习语言、了解世界,并由人类获得的高质量核心词典和本体引导代理。
尽管 McShane 和 Nirenburg 认为 AI 代理可以自动学习多种知识——尤其是当引导代理的知识库变得更大时——但最有效的知识获取流程定然需要人工参与,这种参与可能是为了质量控制或者处理困难用例等目的。
她说:“我们准备发起大规模的工作计划来推动 LEIA 的采用,这将使涉及语言交流的各种应用程序更像人类。”
在他们的著作中,McShane 和 Nirenburg 也承认我们需要做很多工作,且 LEIA 的发展是一项“持续的、长期的、范围广泛的工作计划”。
“要做的工作的深度和广度与目标的崇高程度是相称的,这个目标就是:让机器能够像人类一样熟练地使用语言,”他们在《人工智能时代的语言学》中写道。
原文链接:
https://bdtechtalks.com/2021/07/12/linguistics-for-the-age-of-ai/




