

OCR 从流程上包括两步:文本检测和文本识别,即将图片输入到文本检测算法中得到一个个的文本框,将每个文本框分别送入到文本识别算法中得到识别结果。
1. 基于深度学习的文本检测算法大致分为两类:基于候选框回归的算法*和*基于分割的算法。
基于候选框回归的文本检测,是源于目标检测算法,然后结合文本框的特点改造而成的,包括 CTPN、EAST 和 Seglink 算法等。CTPN 是基于 faster RCNN 改进的算法,在 CNN 后加入 RNN 网络,主要思想是把文本行切分成小的细长矩形进行检测再拼接起来;SegLink 算法的检测思路与 CTPN 类似,也是先检测文本行的小块然后拼起来,但网络结构上采取了 SSD 的思路,在多个特征图尺度上进行文本检测,然后将多尺度的结果融合起来,另外输出中加入了角度信息的回归;EAST 算法,它是直接回归的整个文本行的坐标,而不是细长矩形拼接,网络结构上利用了 Unet 的上采样结构来提取特征,融入了浅层和深层的信息,并且在输出层回归了角度信息,可以检测斜框。
基于分割的文本检测,其基本思路是通过分割网络进行像素级别的语义分割,再基于分割的结果构建文本行,包括 PixelLink、Psenet 和 Craft 算法等。PixelLink 算法,网络结构上采用 FCN 提取特征,直接通过实例分割结果中提取文本位置,输出的特征图包括像素分类特征图和像素 link 特征图。Psenet 算法,网络结构上采用 FPN 特征金字塔提取特征,对每个分割区域预测出多个分割结果,然后提出一种新颖的渐进扩展算法,将多个分割的结果进行融合。Craft 算法,网络结构上采用 UNet 的结构,输出的特征图包括 Region score 特征图和像素 Affinity score 特征图,另外特征图中使用了高斯函数,将预测像素点分类的问题转成了像素点的回归问题,能更好的适应文字没有严格包围边界的特点。
2. 基于深度学习的文本识别算法则相对较为统一,一般都采用 CNN+RNN+CTC 的结构,俗称 CRNN 结构,因为这种结构的识别效果很好,且泛化性好,工业上大多都用的这种结构,然后在该框架上做一些改进,如更换 CNN 主干网络,缩减卷积层以提高速度缩减空间,或者改进 RNN 加入 Attention 结构等。
本文主要介绍了我们在生产上使用的文本检测和文本识别算法。算法的训练流程一般包括以下步骤:
1. 准备训练数据,有的是需要标注(如文本检测中),有的主要是造数据(如文本识别中);
2. 定义算法网络,这里主要是明确输入和输出;
3. 准备好 batch 数据集,这里主要是处理输入的图片和标签数据,标签数据结构与第 2 步中的网络输出对应,例如 craft 要进行高斯函数计算等,而文本识别中则无需处理,直接将造好的数据输入即可;
4. 定义 loss,优化器和学习率等参数;
5. 训练,这里主要是定义每批次数据训练的操作策略,如保存策略,日志策略,测试策略等。
OCR 文本检测
我们在文本定位中采用的是 Craft 算法,它是一种基于分割的算法,无需进行大量候选框的回归,也无需进行 NMS 后处理,因此极大提升了速度,并且它是字符级别的文本检测器,定位的是字符,对于尺寸缩放不敏感,无需多尺度训练和预测来解决尺度方差问题,最后其泛化性能也能达到 SOTA 的水平。
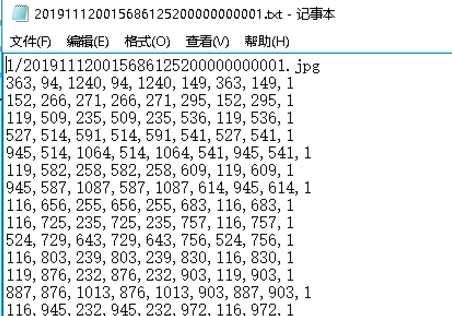
1、训练数据标注
该方法是基于分割的,背景文字是指的原本就在票据上的文字,如“姓名”、“出生年月”等文字,前景文字是指的待识别的文字,也就是用户后填进去的内容。标注步骤就是将这些文字框出来,标上相应的类别。我们采用自己开发的标注工具,这里也可以使用开源的 labelme 工具,生成的标注文件如下所示,第一行是图片所在路径,从第二行开始就是坐标框信息,最后一位是类别。
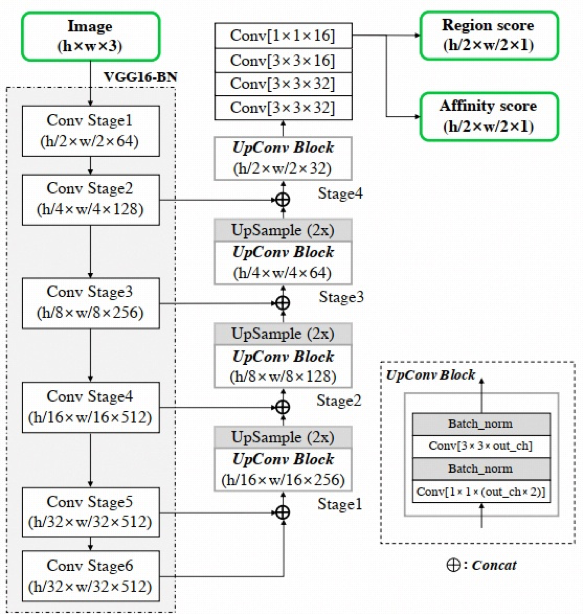
2、网络设计
下图是网络结构图,整体采用了 Unet 的主结构,主干网络用的 vgg16,输入图片首先经过 vgg16 后,接 UNet 的上采样结构,其作用是使得深层和浅层的特征图进行拼接作为输出。然后再接一系列的卷积操作,充分提取特征。最后输出的特征图包括 Region score 特征图和像素 Affinity score 特征图。
网络的代码如下所示:
我们也从代码中把网络结构打印出来,可以看到最后一层输出的结构,最终网络的输出结构是(batchsize, 2, w, h),即通道数为 2 的特征图。

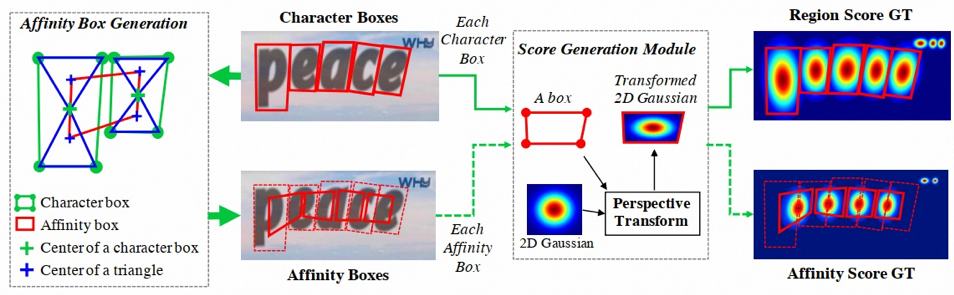
3、训练标签生成
图片的标签数据包括 region_score 和 affinity_score 两个特征图,region_score 表示给定的像素是字符中心的概率,affinity_score 表示相邻两个字符中间空白区域中心的概率。其特征图不像二进制分割图那样用离散方式标记每个像素,本文使用高斯热图对字符中心的概率进行编码,将分类问题转化为回归问题,另外采用高斯热度图的好处是它能很好地处理没有严格包围的边界区域,因为文字不像传统目标检测的物体,它没有明确的轮廓边界。生成高斯热图的流程图如下所示:
高斯热图的生成代码如下所示:
调用上述函数计算好 region_map 和 affinity_map 的结果,用 .npy 格式保存起来,然后在数据类中调用,自定义数据类的代码如下所示:
4、损失函数设计
由于输出的特征图采用高斯函数构建,因此分割的损失函数也由交叉熵损失函数换成了回归用的 MSE 损失函数,优化器选用经典的 SGD。代码如下所示,
5、网络训练设计
由于文字定位需要的数据量极大,而真实数据集通常很少,标注也较困难,这里使用的是 finetune 方式,即载入预训练权值然后微调训练的方式,用较少的训练集就能达到很好的效果。代码如下所示:
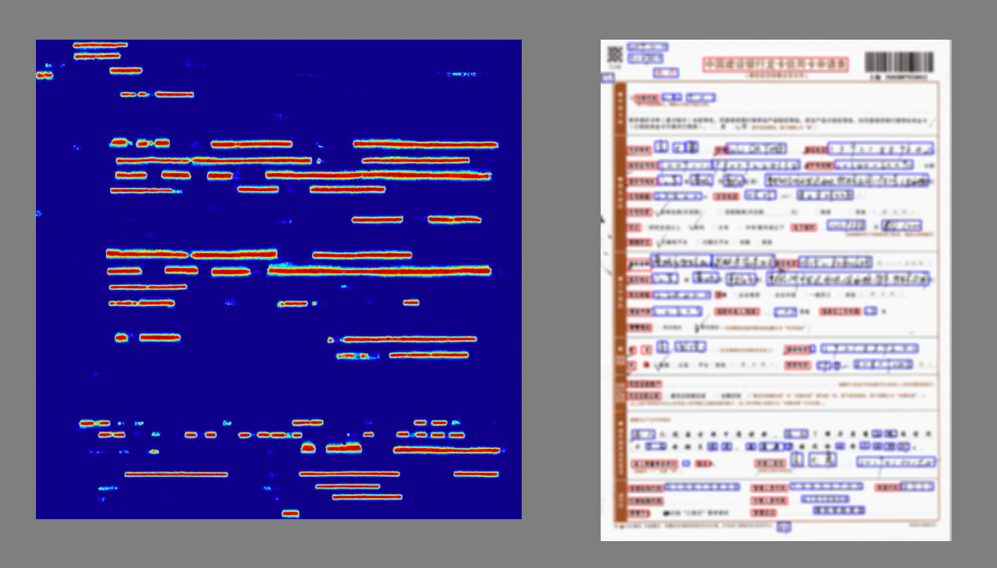
6、测试结果
测试结果如下图所示,其中左图是预测出的高斯热图,为了便于进行一系列的图像操作,所以统一 resize 成了正方形,右图是由高斯热图转化出的矩形框图,也就是最终可以放入识别模型中的切片框图,为了保护隐私信息做了模糊处理。可以看到,票据中的字被不同颜色的框给框出来了,并且分好了类别,其中红色的为背景字,蓝色的为前景字。
OCR 文本识别
我们在文本识别中采用的是 CRNN 算法,它结构非常简单,就是 CNN+RNN+CTC 的结构,CNN 用来提取图像特征,RNN 用来提取文字的序列特征,CTC 用来对齐输出与标签来计算 loss。
1、训练数据生成
在之前的《 OCR 数据处理篇》已经介绍过如何生成训练数据,生成的图像如下所示。
训练数据的生成有两种方式,离线生成和在线生成,离线方式意思是先将图片数据生成好存入硬盘中,然后读取;在线方式是指:在每个 batch 的训练开始前动态的生成训练图片,从而不会保存图片。
OCR 识别模型的训练需要大量的数据,通常需要的数据量是字符集的 1000 倍,例如要训练一个能认 5000 字的模型,至少需要 500 万条数据才能训练,这么多的小图片数据存入内存中,一是占用内存,二是小文件的读取会非常慢。因此在 OCR 识别模型的训练时通常会采用在线的方法。
生成训练数据前需要先准备字符集,将字符集处理成如下的 txt 文件,一行为一个字。

在线生成数据的代码如下,主要就是自定义一个 pytorch 的 Dataset 类,它自带的__getitem__方法是个迭代器, 每个 batch 载入数据时会自动调用该方法,取出 batch_size 大小的数据,然后定义好字符集、字体、背景、颜色等信息就可以了,也可以制定一些随机策略生成。
2、网络设计
是由 cnn+rnn 组成,代码如下所示:
自定义一个 pytorch 的 Module 类,cnn 层这里用的结构是 vgg16,ConvBlock 结构如下所示,就是卷积,batchNormalization 加 relu。这里也可以根据需要换成 resnet 或者 densenet 主干网络。
然后 rnn 层是一个双向的 rnn,这里为了加速用的 gru 代替 lstm,最后接一个线性层,最终输出为(batchsize, unit, class_num),其中 unit 是根据识别的切片长度不同而变化的,class_num 是字符集的个数,因为最后是计算 softmax。
3、损失函数的设计
在上述 rnn 的输出单元 units 后,因为每个切片的字符数量不同,字体大小样式不同,导致每个 unit 的输出与结果的字符并不是一一对应的,因此采用了 CTC_loss 的损失函数。用的 torch.nn.CTCLoss(),是 pytorch 自带的函数。代码如下所示:
4、网络训练设计
每个 epoch 的训练过程如下:输入图片—》预测—》计算损失—》反向传播更新参数—》保存模型,pytorch 可以动态的把整个训练步骤用代码形式写出来,因此很容易编写和调试中间步骤。
5、结果展示
测试代码如下,主要就是模型的加载调用和预测结果的处理。
测试准确率在 98% 左右,测试的样例结果如下所示,3 张全部识别正确。

文章转载自:金科优源汇(ID:jkyyh2020)
原文链接:OCR模型训练

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论