

紧跟大数据前沿,尝鲜 MapReduce 2.0 版本—增加了诸多新特性、功能进行了完善与升级、作业效率与易用性大大提升,下面就由小编给大家详细介绍下 MapReduce2.0 的新特性。
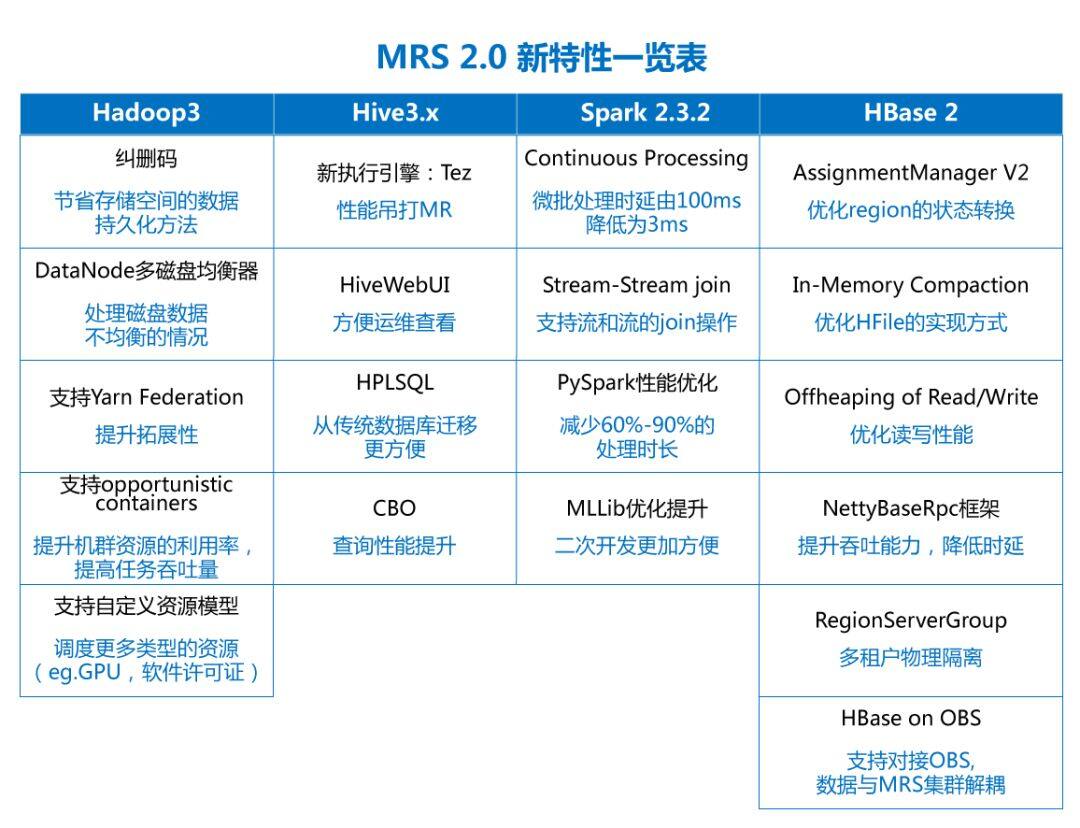
一. MRS 2.0 vs 1.X ——Hadoop 篇
冷数据占存储空间更小
对于冷数据的存储,我们一直希望能够减少其所占存储空间。纠删码作为给 HDFS 拓展的新特性,是一种与副本相比更节省存储空间的数据持久化方法。比如 Reed-Solomon(10,4)标准编码技术只需要 1.4 倍的空间开销,而标准的 HDFS 副本技术则需要 3 倍的空间开销。
新机制实现 Yarn 的高扩展
新引入 Yarn federation 机制:将一个超大的集群分解成多个子集群的方式来实现 Yarn 的高扩展性,每个子集群有自己的 ResourceManager 和 NodeManager,Yarn federation 将这些子集群拼接在一起使他们成为一个大集群。在 Yarn federation 环境中,Application 看到的是一个超大的集群,并且能够在整个集群的任何节点执行 Task。
支持自定义资源模型
从 MRS2.0 开始,Yarn 支持自定义资源模型(support user-defined countable resource types),不仅仅支持 CPU 和内存,比如集群管理员可以自定义诸如 GPU,软件许可证等等资源,Yarn 任务可以根据这些资源的可用性进行调度。
除此之外,华为云 MRS 服务 2.0 全面兼容 Hadoop 3 版本,提供了 DataNode 节点内多磁盘均衡工具,来处理添加或替换磁盘时可能导致的 DataNode 内部多块磁盘存储的数据不均衡的问题。Hadoop 3 同时支持 opportunistic containers,主要目的是提升集群资源的利用率,提高任务吞吐量。
二. MRS 2.0 vs 1.X ——Hive 篇
新执行引擎,性能吊打 MR
Tez 是一个现代的支持有向无环图的分布式计算框架,性能吊打 MR。提供的 UI 界面功能强大,又让人耳目一新。
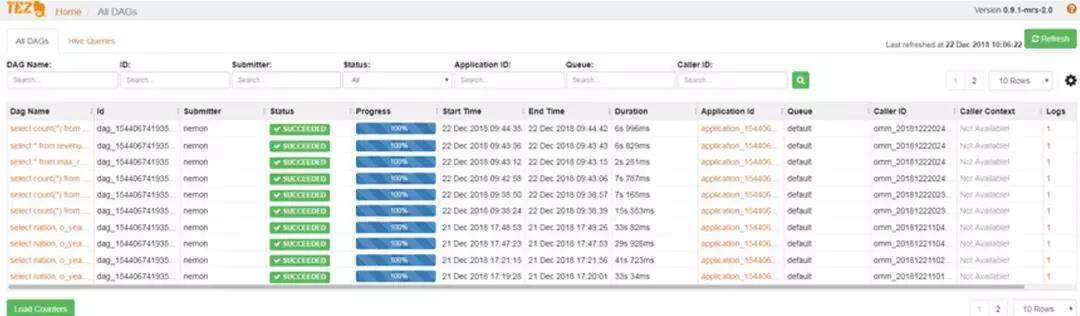
HiveWebUI 使运维更加简单
HiveServer 如今提供的 web 界面,可以方便查看正在运行的 SQL 有哪些,执行了多长时间等,可以说是运维同学的一大福音。
提供了 HPLSQL
从此 Hive 有了存储过程。从传统数据仓库,ORACLE 等关系数据库迁移过来更方便啦。一个简单的例子:
CREATE FUNCTION hello(text STRING)
RETURNS STRING
BEGIN
RETURN 'Hello, ’ || text || ‘!’;
END;
FOR item IN (
SELECT s1,s2 FROM test limit 10
)
LOOP
PRINT item.s1 || ‘|’ || item.s2 || ‘|’ || hello(item.s1);
END LOOP;
新版本的 Hive 还充分利用现代 CPU 提供的 SIMD,AVX2 等指令集,来提高 CPU 利用效率。例外,CBO 这种基于代价的查询优化,对于多表 join 性能优化效果显著。使用新版本后,根据不同场景,Hive 的性能提升了不止 50%呢。
三. MRS 2.0 vs 1.X ——Spark 篇
真正毫秒级低延迟处理
无论是最早的 Spark Streaming,还是 Spark 2.0 中推出的 Structured Streaming,均采用定时触发,生成微批的方式实现流式处理,微批处理的方式存在最小延迟的极限(100 毫秒左右)。Structured Streaming 新加入的 Continuous Processing 模式,可以实现毫秒级的低延迟处理(实测 3-5 毫秒左右)。
支持流和流的 join 操作
Structured Streaming 用来替代原先的 Spark Streaming。此前,Structured Streaming 仅支持流和静态数据集之间的 join 操作,Spark 2.3 提供了期待已久的流和流的 join 操作,支持内连接和外连接,可用在大量的实时场景中。例如比较常见的点击日志流的 join 操作。
PySpark 性能优化
基于 Apache Arrow 和 Pandas 库,实现了 pandas_udf。利用 pandas 对数据进行矢量化的优化,并通过 Arrow 降低 Python 与 Spark 的通信开销。使用 pandas_udf 替代 pyspark 中原来的 udf 对数据进行处理,可以减少 60%-90%的处理时长(受具体操作影响)。
MLLib 优化提升
在 Spark 2.3 中带来了许多 MLLib 方面的提升,例如,支持 Structured Streaming 中使用 MLLib 的模型和 pipeline;支持创建图像数据的 DataFrame;使用 Python 编写自定义机器学习算法的 API 简化等。
四. MRS 2.0 vs 1.X ——HBase 篇
HBase on OBS: 数据与 MRS 集群解耦
MRS 2.0 上的 HBase 2.x 支持对接对象存储服务(OBS),可以将最终的数据存储到 OBS,适用于需要大量数据进行归档存储的场景,数据与 MRS 集群解耦,灵活切换。
新的多租户方案
RegionServer Group 作为新的多租户方案,可以将多个 RegionServer 进行分组,组成不同的 RGS。不同的表可以分布在不同的 RGS 中,不同 RGS 中的表不会互相受到影响,以这种从 RegionSever 中物理隔离的方式,从而实现多租户的方案。
优化 region 状态转换
AssignmentManager V2 基于 Procedure V2 实现,能够更快速的分配 Region,维护的 region 状态机存储不再依赖于 ZooKeeper,移除了 region 在 zookeeper 中的状态信息,只在 HMaster 的内存和 Meta 表中维护 region 状态,极大的解决了 region 状态转换过程中引起的问题。
优化 HFile 实现方式
MemStore 中的数据达到一定大小以后,先 Flush 到内存中的一个不可改写的 Segment,内存中的多个 Segments 可以预先合并,达到一定的大小以后,才 Flush 成 HDFS 中的 HFile 文件,这样做能够有效降低 Compaction 所带来的写 IO 放大问题。
此外,HBASE 2.x 更改了数据的读写方式,会直接在二级缓存中进行读写,采用堆外内存 Offheap 替代之前的堆内内存,减少对 Heap 内存的使用,有效减少 GC 压力。HBase2.x 开始默认使用 NettyRpcServer 替代 HBase 原生的 RPC server,大大提升了 HBaseRPC 的吞吐能力,降低了延迟。
MRS2.0 新增了这么多特性,进一步实现了完整统一的计算系统,为大家提供 7*24 小时不间断服务的系统级平台。同时具有强大的包容的生态圈,并支持计算存储分离的功能,大家从各个平台迁移过来都非常方便。开源中的所有新特性,都可以来 MRS 2.0 上抢先一步体验到。
MRS 2.0 2019 年 1 月 31 日前登录华为云,在这之前可先行体验 MRS 大数据场景,包含车联网、气象、水务、游戏等热门行业场景。可视、可触、已落地的大数据,来试试就知道了!
MRS 体验馆入口
本文转载自 华为云产品与解决方案 公众号。
原文链接:https://mp.weixin.qq.com/s/JNTDAigB5p94bDeiUNGE0A

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论