

众所周知,RocketMQ 作为一款分布式、队列模型的消息中间件,具有以下特点:
严格保证的消息顺序
丰富的消息拉取模式
高效的订阅者水平扩展能力
实时的消息订阅机制
亿级消息堆积能力
在复杂的应用场景中,将 RocketMQ 作为技术解耦的消息中间件,可以简化服务部署,以下是 RocketMQ 在联想大数据的实践分享。
场景分析
在联想大数据中,应用 RocketMQ 的使用场景中经常会出现:异步请求,应用解耦和日志处理等场景情况。
异步请求的业务处理:
经常遇到如下两种情况,一种为串行方式的业务流程(如图 1),另一种为并行方式的业务流程(如图 2)。
串行方式:在联想大数据解决方案中,针对顺序化、流程化的业务场景经常使用串行方式,实现 RocketMQ 的技术解耦。如在某卷烟厂的解决方案中,针对制烟流程,将各个车间的处理流程做为独立的业务体创建一个 Topic,对业务体中的各个处理阶段创建对应的 Tag,并按照制烟流程顺序进行数据推送、清洗、业务处理及监控等,如下图 1。

图 1
并行方式:因业务的独立性,处理流程可分开进行处理,相互之间没有业务交叉。这种情况下,我们可以考虑使用并行方式对业务流程进行技术解耦。在联想大数据的相关解决方案中,针对某汽车的数据监控及相关画像的流程中,一部分是基础业务处理流程,另一部分是通过 Bin Log 数据进行数据监控与消息提醒等附加处理业务流程。针对这种场景,我们在给客户进行程序部署时,便采用了并行方式,如图 2。
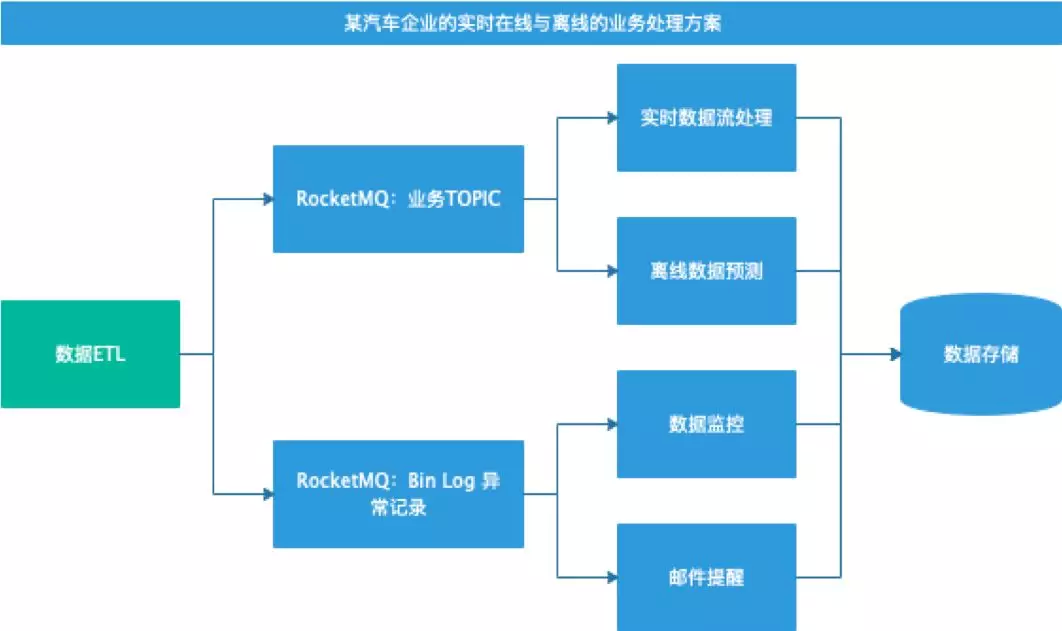
图 2
错峰削谷
虽然联想商城的并发请求数不像淘宝、天猫、京东商城等互联网公司的并发请求数高,但在技术要求上经过多年的业务总结和摸索过程中,总结出适合联想的技术架构体系,以解决高并发数据带来的业务处理压力,并实现技术架构的高可用。
在应对高并发,处理高可用,保证不丢数据的前提下,我们使用 RocketMQ 做为应对特殊的业务处理流程的技术手段,需要在数据生产端承接瞬时高数据流量,在数据消费端平稳地将数据推送到下游业务线。
基本处理方法采用业界普遍的“漏斗”模式,如图 3:
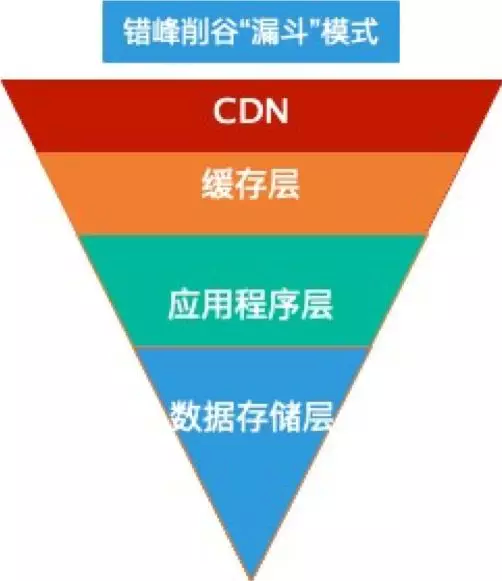
图 3
应用解耦
对于解耦架构来说,在联想物联网(IOT)的应用非常普遍。我们结合 StreamSets 进行二次开发,使用 StreamSets 通过界面上拖拽的方式制定数据流程,并在客户的解决方案中,说明 RocketMQ 区别于其他 MQ 组件的技术特点,针对客户的使用场景进行优化,使用 RocketMQ 进行解耦数据。
日志处理
RocketMQ 的设计模式借鉴于 Kafka,且后者经常用于日志管理系统充当数据缓冲的角色。但
Kafka 过度依赖 ZooKeeper,而 RockerMQ 则可实现无 ZooKeeper 部署,简化安装部署工作,所以,在联想大数据业务线和解决方案中,将 RocketMQ 应用于日志处理业务,逐渐增加 RocketMQ 的使用率。
应用实例
在联想大数据解决方案中,目前使用 RocketMQ 的实例也有不少,下面就举个实例说明一下,我们是如何使用的。
目前,在联想大数据部门,我主要负责数据流组件研发,并基于 StreamSets 开源组件进行定制化开发。在给客户的解决方案或现场实施中,我们可以通过在界面上的操作,设定好相关参数,便可设计出符合客户需求的数据流。如图 4 所示:
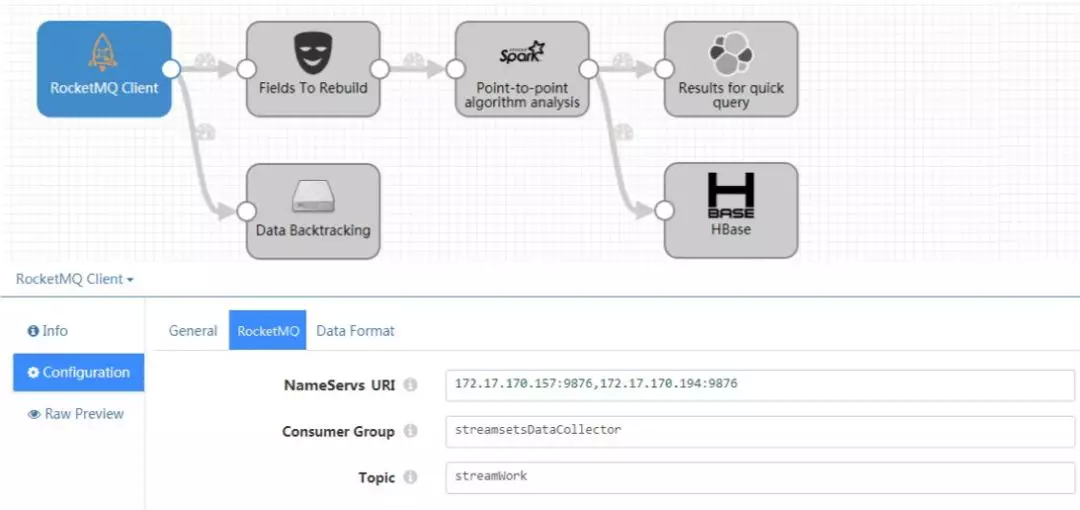
在每一个功能模块上,我们只需要设置若干必要的参数配置,也可以通过在文本框中编写更多的参数配置,在启动数据流时,即可加载这些配置,并实现数据流中各个功能模块的初始化、启动等等功能。
在这个实例中,我通过开发一个 RocketMQ 的功能模块,并设定一些基本参数,如 NameServers 组、消费组名和 Topic,便可从 RocketMQ 服务端获取数据。
通过使用这个工具进行设计,大大降低了使用人员的学习门槛,而且也简化了开发流程。在对外的解决方案或项目交付过程中,极大地赢得了产品和交付工程师的认可,在各个 POI 项目中也 PK 掉不少大厂公司。
优势
在此仅对比 Kafka,在实际应用中所具备的优势:
架构差异,简化部署
在集群部署上,Kafka 的部署,必须依赖 ZooKeeper,并实现 WaterMark 的监控和 Leader 的选举。而 RocketMQ 可实现不依赖 ZooKeeper 的部署,大大降低使用门槛和学习成本。
Kafka 架构设计:
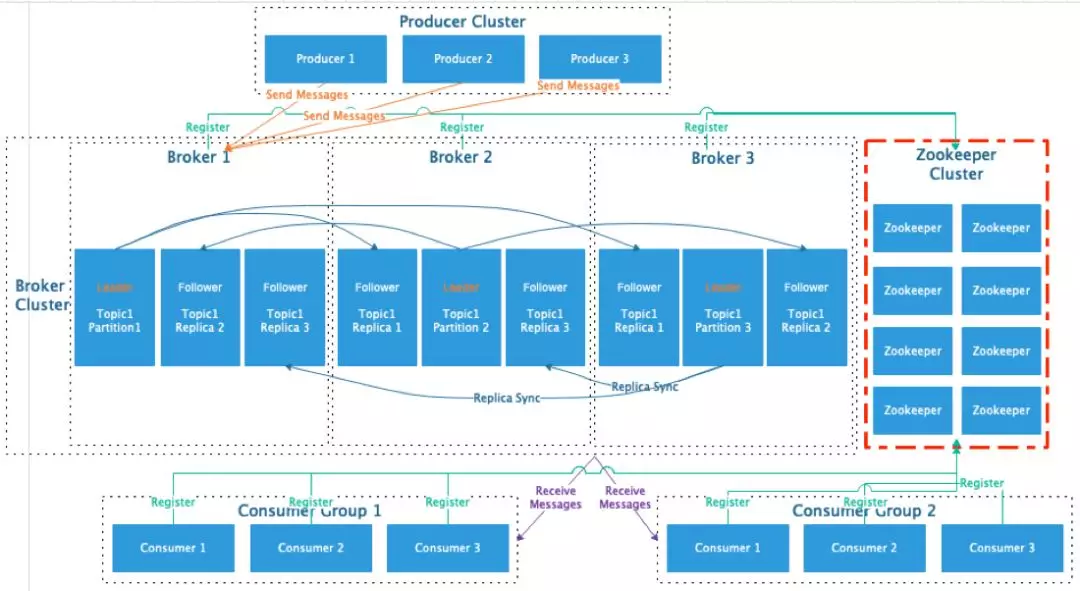
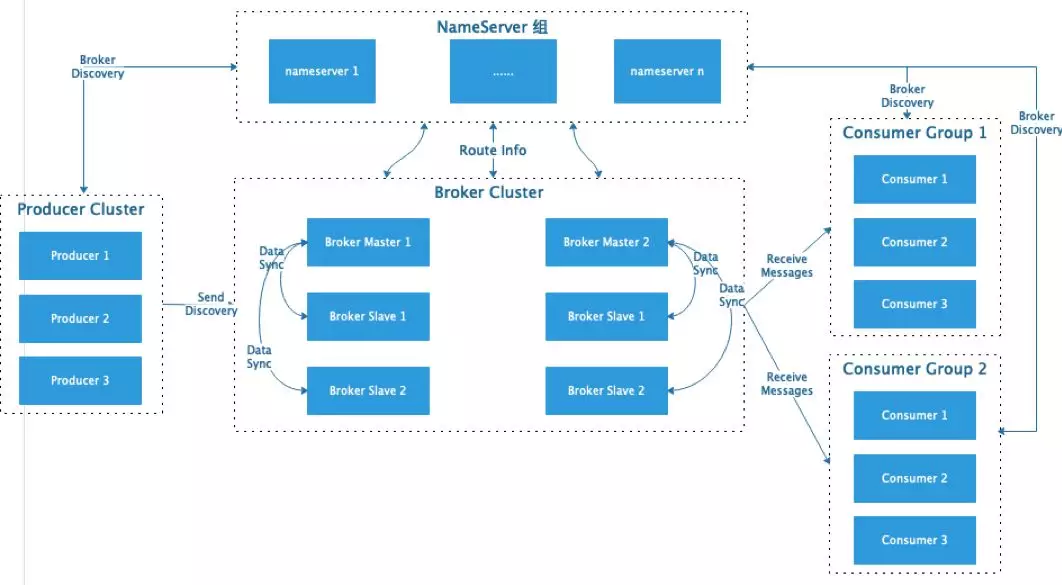
RocketMQ 架构设计,参考官网架构设计:
性能优势
1、RocketMQ 可支持上万 Topic 的创建和使用,并且不会影响实例的整体性能及处理能力。
反观 Kafka,我们在使用 6000 左右的 Topic 时,整个集群性能突然下降,并有部分节点出现卡顿现象。
2、写入效率虽略低,但磁盘 IO 不是瓶颈。
在实际测试过程中,同时写入 Kafka 和 RocketMQ 进行测试:
Kafka 的吞吐量高达 15~17w/s,体现出较高的吞吐量。这主要取决于它的队列模式保证了写磁盘的过程是线性 IO,但此时 broker 磁盘 IO 已达瓶颈,写入响应已经出现略大的延时,有小部分数据出现重试写入。
RocketMQ 的吞吐量基本保证在 11~12w/s,磁盘 IO 率虽已接近 100%,但消息写入内存后即返回 ack,由单独的线程专门做刷盘的操作,所有的消息均是顺序写文件。
在“坑”中摸爬滚打
在近些年的使用中,联想大数据逐渐在提高 RocketMQ 的使用率,不仅仅因为其具有区别于其他 MQ 消息中间件的优势,并且学习成本略低于 Kafka,更重要的是 RocketMQ 是阿里开源的消息组件,经过大量的生产实践,且在公司内部经历多年的版本更新,达到一个相当稳定的版本,而且各种学习资料也是相当丰富。
因此,在联想内部开始尝试 RocketMQ 作为各个业务线和解决方案中推荐使用的消息中间件。尽管在应用一种新的技术过程中会遇到各种各样的“坑”,但是在摸爬滚打的过程中我们痛苦并快乐着。
下面总结一下,我们遇到的一些比较有特点的“坑”及相应的解决方法:
坑一:
因 consume offset 不能与 commitlog 同时刷盘,导致 offset 不能对应数据。
因为 consume offset 最终要索引到 commit log,假如 commit log 没有对应的数据,那么
consume queue 保存的这个 offset 也没有意义,所以最终就算有了这个 offset,还是要根据 commit log 来修复一遍,因为他们不是一起刷盘的。
所以,我们对源码进行了一定优化,将 consume offset 和 commit log 通过一个事务进行刷盘,保证每一个 consume offset 与 commit log 一一对应。
坑二:
RocketMQ 的 common 包 MixAll 类中,默认指定 WS 使用 8080 端口,不能动态设置。
因为 8080 端口一般为 Web 应用使用端口,但当启动 RocketMQ 后,发现此端口被占用,导致某个 Web 应用程序不能正常启动。针对这个问题,我们在社区 Jira 中看到类似的 Issue,并提供了相应的 Bugfix 方法。所以,我们在使用过程中,基于源码进行了二次开发,并在 RocketMQ 的配置文件中增加了对此端口的动态配置项。
在使用和学习过程中,还有很多的问题,我们仍处于学习和提高的阶段。
总结
通过对 RocketMQ 的学习和使用,联想大数据在对外项目和解决方案中,不仅仅可以使用 Kafka 作为消息中间件进行数据解耦,还能够借助 RocketMQ,进一步丰富应对不同使用场景的消息解决方案。
对于 RocketMQ,联想大数据还处于认识学习的过程中,目前我们更多地是在使用它,并没有完全研究透彻。希望以后积极参与到社区的讨论和研究中,贡献自己的一份力量。
作者介绍:
雷明,现就职于联想大数据团队。
本文转载自公众号阿里巴巴中间件(ID:Aliware_2018)。
原文链接:
https://mp.weixin.qq.com/s/z3fHgm4Aew7yz8J_mbXuuA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论