

当地时间 7 月 28 日至 8 月 2 日,自然语言处理领域顶级会议 ACL2019 在意大利佛洛伦萨召开,会上滴滴正式宣布开源基于深度学习的语音和自然语言理解模型训练平台 DELTA,以进一步帮助 AI 开发者创建、部署自然语言处理和语音模型,构建高效的解决方案,助力 NLP 应用更好落地。
自然语言处理模型和语音模型是很多 AI 系统与用户交互的接口,此次滴滴正式开源深度学习模型训练框架 DELTA,旨在进一步降低开发者创建、部署自然语言处理系统和语音模型的难度。
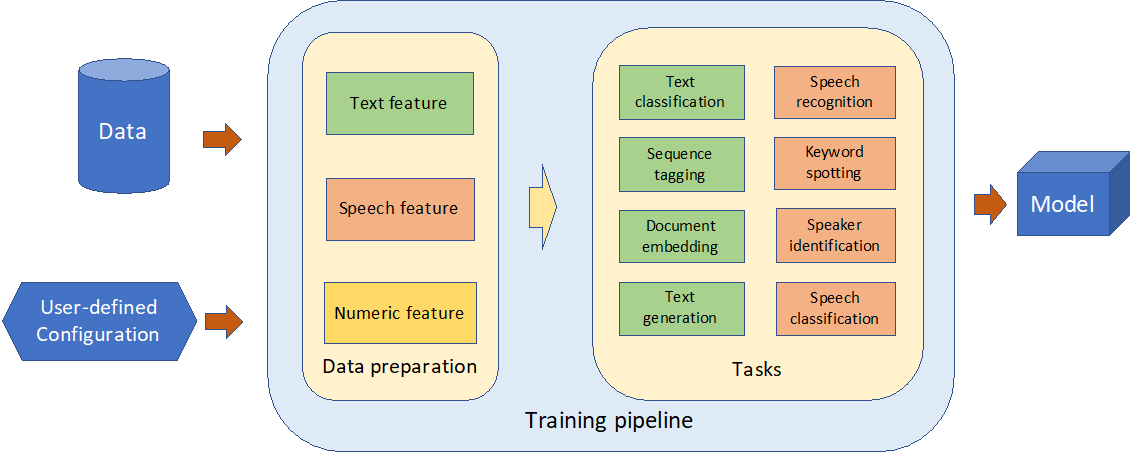
DELTA 是滴滴第 22 个开源项目,主要基于 TensorFlow 构建,能同时支持 NLP(自然语言处理)和语音任务及数值型特征的训练。
据了解,滴滴在 NLP 和语音领域已有一定积累,希望借开源 DELTA 这个机会将自身能力开放,进一步降低开发者创建、部署自然语言处理系统和语音模型的难度。同时 DELTA 专门针对工业界场景做了优化设计,填补了从算法模型到产品上线之间的空缺。
目前 DELTA 整合了包括文本分类、命名实体识别、自然语言推理、问答、序列到序列文本生成、语音识别、说话人验证、语音情感识别等重要算法模型,形成一致的代码组织架构,整体包装统一接口。
用户只需要准备好模型训练数据,并指定好配置,模型训练 pipeline 就可以根据配置进行数据处理,并选择相应的任务和模型,进行模型训练。在训练结束之后,DELTA 会自动生成模型文件保存。该模型文件形成统一接口,可以直接上线使用,快速产品化,能让从研究到生产变得更容易。
DELTA 研发团队告诉 InfoQ 记者,NLP 和语音模型训练需要对数据做各种特征抽取和预处理,针对这一情况,团队优化了文本和语音特征和数据处理模块,将这一部分整合进整体模型框架之中,开发者只需提供数据,所有预处理和特征抽取可以由模型框架自动实现。另外,NLP 和语音更关注对序列的建模,DELTA 针对性地提供了大量序列的建模方法。
值得注意的是,除可支持多种模型的训练,DELTA 还支持灵活配置,开发者可基于 DELTA 搭建成多达几十种的复杂的模型;此外,DELTA 在多种常用任务上提供了稳定高效的 benchmark,用户可以简单快速的复现论文中的模型的结果,同时也可以在此基础上扩展新的模型。在模型构建完成后,用户可以使用 DELTA 的部署流程工具,迅速完成模型上线,实现从论文到产品部署无缝衔接。
目前业内还没有与 DELTA 完全一样的开源项目,业界的开源项目多用于研究目的,DELTA 是专注学术界和工业界级别的开源项目。此外,相较业界已有项目,DELTA 同时支持 NLP 和语音任务,也支持数值型特征的训练,及几种特征输入的联合多模态训练,这是实际应用中常见的场景,也是 DELTA 性能更加优越的地方。
目前 AI 开发者可登陆Github查看 DELTA 的详细介绍和源代码,利用 DELTA 加快实验进度,部署用于文本分类、命名实体识别、自然语言推理、问答、序列到序列文本生成、语音识别、说话人验证、语音情感识别等任务的系统。用户亦可在滴滴开源平台上获取更多滴滴开源项目的相关信息。

InfoQ 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论