
Agentica项目和Together AI发布了DeepCoder-14B-Preview,这是一个基于Deepseek-R1-Distilled-Qwen-14B的开源 AI 编程模型。该模型在LiveCodeBench上的通过率达到了 60.6%,超过了 OpenAI 的 o1 模型,性能与 o3-mini 相当。
DeepCoder-14B-Preview 是使用强化学习(RL)在 24K 编码问题数据集上对 Deepseek 模型进行微调的。开发人员修改了verl分布式 RL 框架,将端到端训练效率提高了 2 倍。他们发布了与创建模型相关的所有构件:代码、数据、训练日志、以及对 verl 的改进。他们在几个编码基准(包括 LiveCodeBench、Codeforces和HumanEval)以及数学基准AIME2024上评估了该模型。DeepCoder 在所有这些测试中表现出色,得分“可比”甚至优于 o1 和 o3-mini 等闭源推理模型。项目团队表示:
我们的目标是对大语言模型(LLM)的 RL 训练民主化......通过完全共享我们的数据集、代码和训练配方,我们赋予社区复制我们工作的能力,并使所有人都可以使用 RL 训练。我们相信推进 RL 扩展是一个集体的、社区驱动的努力,我们欢迎开源贡献和赞助。让我们携手推动 RL 在 LLM 推理——以及更广泛的领域——的前沿!
DeepCoder 团队发布了他们训练过程的一些细节以及他们克服的几个问题。首先是缺乏针对编码问题的“高质量、可验证”的训练数据:几个流行的数据集“有噪声或包含不可验证的问题”,或者对于模型来说太容易解决。为了创建训练数据集,团队开发了一个自动化流程,只保留有可验证解决方案和至少五个单元测试的问题。
他们还解决了 RL 训练中的一个瓶颈问题“采样”,即对正在训练的模型进行推理。解决方案是将流程管道化:并行运行训练和推理,并使用推理输出作为下一批训练的输入。这将训练迭代时间减少了 1.4 倍。
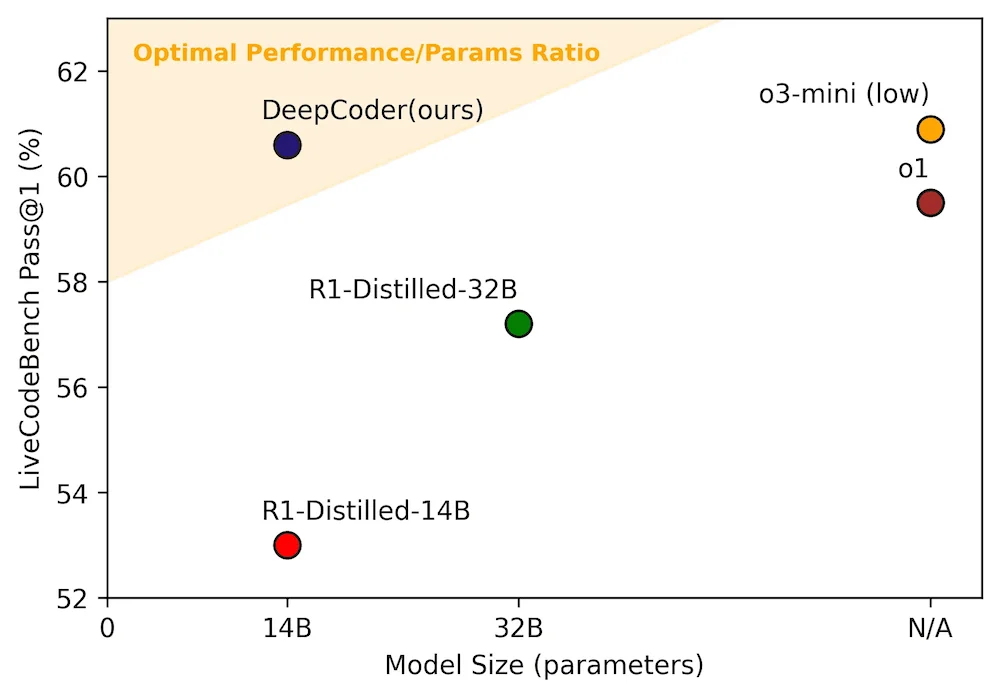
LiveCodeBench Pass@1 准确率与模型大小对比。图片来源: Together AI博客
在 Reddit 上关于该模型的讨论中,一位用户写道:
我刚刚在 olama 上试用了 14b 版本的 q4 量化版,我不得不说我印象非常深刻。这绝对是我在这种大小中尝试过的最好的模型。我需要更多的测试来得出结论,它是否真的和 o3-mini low(特别是因为我只测试过 o3-mini medium)一样好,但在我对日常任务的初步测试中,我感觉它确实超过了 40。
Andrew Ng 的新闻通讯记者 The Batch 赞扬了DeepCoder,说道:
将强化学习应用于编码是有效的,但它有两个大问题:(i)可验证代码的训练示例相对稀缺,(ii)计算代码的奖励信号非常耗时,因为它需要评估许多测试用例。DeepCoder-14B-Preview 的优化减少了这种复杂性,将强化学习训练从几个月缩短到几周。这些优化内置于 Verl-pipeline 中,这是 Together.AI 和 Agentica 提供的一个开源 RL 库,为开发强化学习提供了一个强大的模型训练工具。
向 DeepCoder 团队致敬,他们开源了他们的推理配方!一些公司已经发展出了执行 RL 的专业知识,但许多团队仍然在成功实施方面遇到困难。RL 训练方法和数据管理技术的开放配方对于推动该领域的发展至关重要。
DeepCoder-14B-Preview 的训练代码可在 GitHub 上找到。模型文件可以从 Huggingface 下载。
原文链接:
https://www.infoq.com/news/2025/06/deepcoder-outperforms-openai/




