去年年底,MarkLogic 发布了 MarkMail 。MarkMail 是一款专门提供免费邮件列表档案搜索的工具,基于他们的 MarkLogic XML 服务器。最初发布时,它仅支持搜索 apache.org 邮件列表,最近,Mozilla.org,PHP 以及 MySQL 列表也加入其中。O’Reilly 的 Rader 在上个月针对 MarkMail 发表说:
……MarkMail 提供的不仅仅这些,还有更多的东西。MarkLogic 存储了近 550 万的邮件信息,涵盖了 700 多个开源的邮件列表——所有 Apache,MySQL,Mozilla,以及 PHP 的列表,还有其他一些列表,随着时间的推进还会有更多列表加入(希望很快就能实现)——并且它的用户界面比 google 搜索漂亮。它运行起来也一样很快,甚至更快。但更重要的是,你可以有内嵌数据挖掘功能,我相信最终更传统的邮件系统也会引入这个功能……MarkMail 真正的闪光点在于管理大量的邮件存档。这当然也是 MarkLogic 将 MarkMail 作为免费工具的原因。MarkLogic 知道潜在的客户群就是那些拥有巨大的邮件存档想要对存档做数据挖掘的公司,而他们的现存系统的性能根本办不到(更不用说用户界面了)。
InfoQ 和 MarkLogic 的 Jason Hunter 坐下一起探讨目前的详细状况以及未来的发展方向。
请问您是否可以给我们一些尚且不太了解的读者简单地讲一下什么是 XML 上下文服务器?
XML 内容服务器就是为内容而建的数据库 (相对于为数据而建来说)。内容是文字的,有层次,但通常不存在重复性的结构。它经常使用 XML 来编码。举例来说,像书,文章,网页,博客日记,以及邮件信息等等都属于内容范畴。
我们开发的 MarkMail 建于 MarkLogic 服务器之上,该服务器是一个商业化的 XML 内容服务器。MarkLogic 服务器有一个事务仓库(transaction store),但它并不以表的方式来思考,取而代之以 XML 的方式思考。在 MarkMail 中,每个邮件都被当作一个 XML 文件。你所看到文本搜索,分页导航,分析性查询和 HTML 网页的处理都由这单个 MarkLogic 服务器机器来运行处理上百万个 XML 文件而完成。
为什么说对于邮件,XML 的格式比关系数据库管理系统来的更好呢?
我曾在基于关系数据库的邮件查询系统上工作过,我可以这样告诉你,由于邮件的自然属性,那实在是一个挑战。邮件是凌乱的,是文字化的,是没有规律的,并且自有它的层次。这些都是对于传统以关系为核心的数据库的挑战。 邮件报头是有非常好的结构的,但并不完美,并且在任何域上都不存在固有的大小限制。邮件体本身可能看起来只是纯文本(所谓无结构式),但实际上并不仅仅这样。它有段落,嵌套的引用段落 (A 引用 B 的言论),开头的问候语,以及信末的署名。它们还时常有附件,在附件中还有成页成页的像文字、段落这样的东西,所有这些一层一层地组织起来。
通过 MarkMail,我们将每一个邮件都作为 XML 文件导入 MarkLogic 服务器。这对于邮件来说是非常自然的格式。我们标识出邮件报头、邮件体的段落、引用、问候、信末署名等等,几乎是标识一切,甚至是附件和附件的内容。然后,通过采用 XQuery 作为一种能够理解 XML 的查询语言,我们可以创建一个系统来使用前面标识出的结构。
我们使用内部 XML 结构实现了很多目的。比如,在作基本查询的时候,我们就略去了信尾例行公事的签名。我们能做到这点是因为我们能识别出它是什么。
当然有时候你想要将这些信尾文字包含进来,实际上可能仅仅需要这些信尾,比如联系方式的信息查询服务。想象这样一个服务,你只需要提供给我们一个人名,我们就可以从他的信末签名中为你取得他的联系方式,并将他最近的联系方式显示于最上方。我们能做到这点是因为我们可以将邮件体中的结构(没有规律和无法推测,但仍然存在的结构)和元数据的结构(更有规律但仍不可完全推测的结构)结合起来,最终得到是谁发送了这些邮件,他又是在什么时候发送这些邮件。
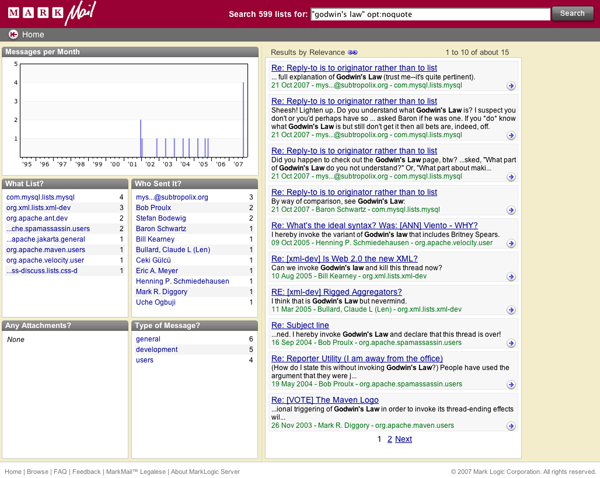
另一个例子是我们的 opt:noquote 选项。这个选项的意思是你想要在原文并只在原文中找到匹配的文字,而不是在引用的段落中匹配。以这样一个搜索举例来说:
“godwin’s law” opt:noquote
它可以查找到邮件发送者在哪里写有这样的词组“godwin’slaw”,并且将那些发送者仅仅引用了这个词组的邮件忽略不计。因为我们能识别出邮件中的引用结构,所以是非常简单的。我们还可以引用结构来做其他的事,比如在显示邮件的时候用不同的彩色来区分。
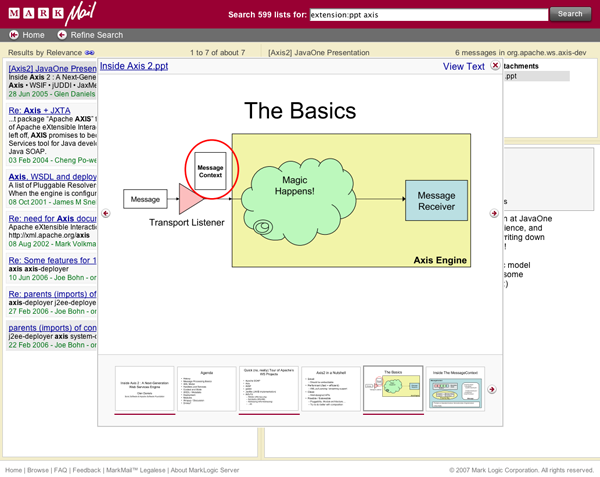
再举个例子,我们使用结构来处理附件。试一下这样一个搜索:
extension:ppt axis
这样一个搜索可以查找到包含文件扩展名为 PPT 的附件,并与 axis(一个 Apache 网络服务项目)相关的那些邮件。在搜索到的邮件结果中,你可以看到我们不仅知道哪些附件含有“axis”,我们还也知道有多少张幻灯片,在你查看附件的时候我们会在搜索命中的幻灯片下添加下划线。这些都是可能的,因为那些看起来不存在任何结构的东西事实上包含了很多结构。
在开发 MarkMail 的过程中,关于 MarkLogic 服务器,你觉得最有趣的发现是什么?
在开发 MarkMail 的过程中,我们决定更激进一点,不使用 Java、Ruby、Python、Perl 或者任何其它传统网络开发语言来开发站点。我们实际开发采用了 XQuery,这是一种 W3C 组织定义的以 XML 为核心的语言。 想象一下一个传统的 Java 网络应用软件是如何工作的。你的数据被储存于关系数据表中,将事物编程为对象,并因为网页浏览器的缘故将对象转换成结构化的 HTML。这个过程里存在双重的阻抗不匹配,实在很痛苦。这也是为什么每个月都有新的 ORM 工具和网络开发框架 (framework) 诞生并且许诺会消除痛苦。
通过使用 XQuery,我们在各个层次保持一个统一的以 XML 为核心的视角。我们的模型是以无数的 XML 文件来存储邮件,我们的控制器是 XQuery 以及它本身对 XML 的支持,我们是视图则是一组可以将任何邮件或邮件碎片转换成 XHTML 的 XQuery 库。
在开发过程中我们发现的优势之一是当需要处理的东西是“活的”,即仍然与它的上下文保持联系的时候,一切就变得很简单很顺利。因而,如果我命令一个渲染库说“从这个邮件中将信末署名提取出来。”于是它便遍历树结构来找到相应的时间,发送者,主题,或任何其它想要的信息,它甚至可以通过查询而获知这是否是该邮件发送者最近的签名。当你面对“死的”数据的时候,你就必须给视图逻辑传递它可能需要的所有信息。虽然也行,但是随着时间的演进,你不得不调整你的"握手(handshake)”来适应改变(或者更常见的是视图不处理一些它本可以处理的东西,因为传递给它所需的数据不是件容易的事。)有时候你会遇到这样的情况,有些数据计算起来很昂贵,且视图只是“有些时候”需要这些数据,这时候你会怎么做呢?每次都付出一样的代价?当然不会,你常常会试着倾向于选择性地传递这样的数据。我很高兴现在我们完全不用为这些情况而杞人忧天。
当然,我们选择使用纯 XQuery 的无可抗拒的基本原因是混合性内容(比如说这里提到的邮件)实在是除了 XML 以外再没有任何更好的表现方式可替代。所以从模型的角度来说,它非常需要 XML。虽然我热爱 JDOM,但用它来写处理 XML 的控制器要比使用 XQuery 弱很多。当你的模型是 XML,视图也产生出 XML(XHTML) 的时候,如果你用来编写模型和创建视图的语言也是以 XML 为中心的就最好不过了。
在搜索过程中,MarkMail 提供了非常重要的各种分析视图。究竟是什么推动了目前的视图,对于未来的强化方向又有什么端倪呢?
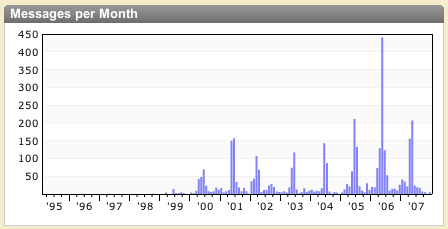
我们相信人们并不只是想要搜索内容,他们想要的是和内容交互。有时候你想要找到绣针,有时候你想要看整个草垛长什么样子。(注:a needle in a haystack 是一个谚语), 又有时候你只是想要浏览。 我们发现直方图可以帮助人们找到方向感。同时,它也是识别发展趋势及探索所谓“群体智慧”的好助手。
关于某个话题的讨论是向上还是向下发展呢?讨论来来回回反反复复?其中是否能看出某种模式?有一个很有意思的例子,试着查询“javaone”,你会看到峰值出现在每年大会前后的一个月里。你可能想不到,这个话题每年都在增长,2006 年最突出。
MarkMail 分析的下一步会是什么呢?是与图表交互,新的图表类型,以及新的数据表现方式。我可以十分肯定地告诉大家。
网站运用了大量的 Ajax,你们曾经考虑过哪些框架,为什么你们最后选择了现在这一个?
我们也想有一个简单的 Ajax 构架能满足我们所有需求,给予我们所有想要的 widget,将一切简化得就像在公园里散步一样简单惬意。但实际上没有,我们只在底层 Ajax 交互上使用了 MochiKit,除此以外我们几乎自己开发了全套 Widget 架构。左/右滑栏、修饰的选择框,弹出式缩略图查看器,以及互动的结果列表,全都是我们自己开发的。
在开发中最具挑战性的用户界面功能是什么?
“搜索结果组”和“线程/消息”视图之间切换的左 / 右滑栏,我们尝试了很多次才得到正确的实现。这是来自于 Ryan Grimm 的背景故事,他发明了令左/右滑栏正常工作的“魔法”: "起初,我试着使用三个 div,将它们都设置成 float left,这样它们看起来互相紧挨着。原先的打算是随后调整第一个 div 的左边距,其它的 div 也随之向左靠拢。结果证明这样的安排在主要的浏览器中很难成功。
所以后来我说忘掉这些精美的 CSS 布局,试试用表格来布局又如何。一行三列的表格,每个部分一个表格。我本想调整表格的位置,但就在我有这个想法的时候,我认识到我可以将这两个方法结合起来得到一个完整的解决方案。
所以我最终将这三个 div 置于一个主 div 中 (该 div 的 id 为 please,因为我当时真的是希望这个方案能行得通)。然后通过调整“please”div 的左边距,终于使得它们三者能够同时滑动。
该滑栏“把戏” 的一个缺点是需要明了在用户重新设置浏览器视窗大小的时候该如何处理。当用户将浏览器视窗变大的时候,我们需要调节一些东西,主要是查询结果 div 的宽度,防止消息 div 一声不吱地溜到视图中去。就在这时,我们发觉一些最新的显示器实际上有足够的宽度来完整显示这三个栏目。所以在重新设置大小的时候,我们不断地查看确认用户的视窗是否大到可以同时显示三个栏目。
我并没有调节任何滑栏的可视性,它们都仍然是可视的(只不过在屏幕之外),并且内容的宽度实际上并没有改变。
尽管我们尚未在公开网站上发布,事实上我们还开发了一个甚至于比滑栏更具技术挑战的功能。这是一个新的呈现技术,它能使有多处命中搜索关键字的邮件消息变得更易于阅读。我们更乐意在将它向公众发布之后,对这个技术做更多更详细的介绍。
在你们的日程上,对于新版本的 MarkMail 有怎样的计划?在为大部分开源邮件列表建档方面,你觉得它会成为 GMane 或 Nabble 强力竞争对手吗?
GMane 设计的目的是将它作为一个邮件与新闻之间的网关,我向所有想要像查看新闻 feed 一样查看邮件列表的人们推荐使用 GMane。Nabble 主要是为人们提供论坛,所以如果你想要的是论坛,那么它是一个很好的选择。 在 MarkMail,我们关注于研究、分析以及性能——特别关注于帮助一些组织和团队从他们的历史邮件中获取更多的东西。自启动以来,我们已经载入了两百多万的邮件,并还将继续载入更多邮件列表,我们同时面向开源项目和其他一些项目,目前包括载入和等待载入的邮件已经达到六百万。我们可以根据组织和团队的要求优先载入数据,所以如果你们想要加入你们的列表,请告诉我们 http://markmail.org/docs/feedback.xqy 。




