

四、query 分析技术演进
4.1 城市分析
在高德地图的检索场景下,从基础的地图数据索引、到在线召回、最终产品展示,均以市级别行政单位为基础粒度。一次完整的检索需求除了用户输入的 query 外,还会包含用户的图面城市以及用户位置城市两个城市信息。
通常,大多数的搜索意图都是在图面或者用户位置城市下,但是仍存在部分检索意图需要在其他城市中进行,准确的识别出用户请求的目标城市,是满足用户需求的第一步,也是极其重要的一步。
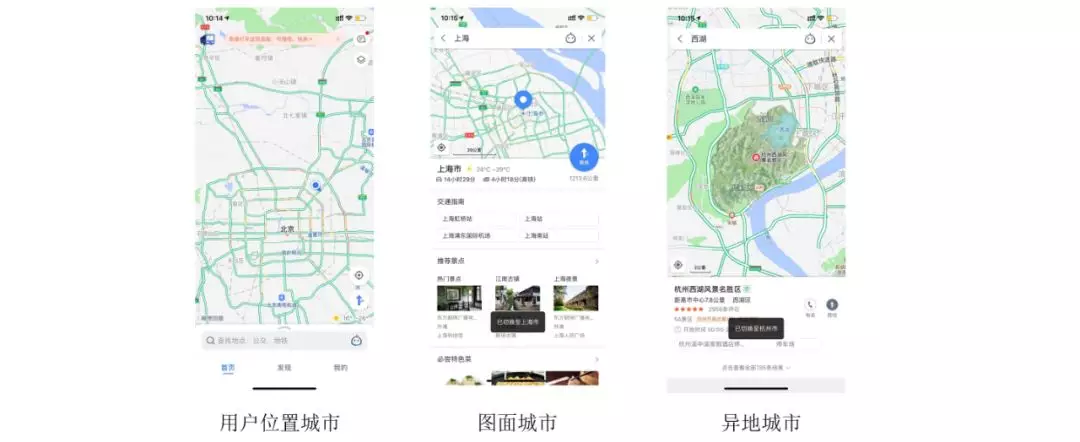
在 query 分析策略流程中,部分策略会在城市分析的多个结果下并发执行,所以在架构上,城市分析的结果需要做到少而精。同时用户位置城市,图面城市,异地城市三个城市的信息存在明显差异性,不论是先验输出置信度,还是用后验特征做选择,都存在特征不可比的问题。
在后验意图决策中,多个城市都有相关结果时,单一特征存在说服力不足的问题,如何结合先验置信度和后验的 POI 特征等多维度进行刻画,都是我们要考虑的问题。
原始的城市分析模块已经采用先验城市分析和后验城市选择的总体流程

但是原始的策略比较简陋,存在以下问题:
问题 1:先验和后验两部分均基于规则,效果不好并且可维护性差;
问题 2:特征体系存在缺陷。原始的城市分析仅使用 query 级的特征,包括点击,session 改写,query 和城市共现等,对于低频 query 处理得不好。
技术改造
改造 1:城市分析
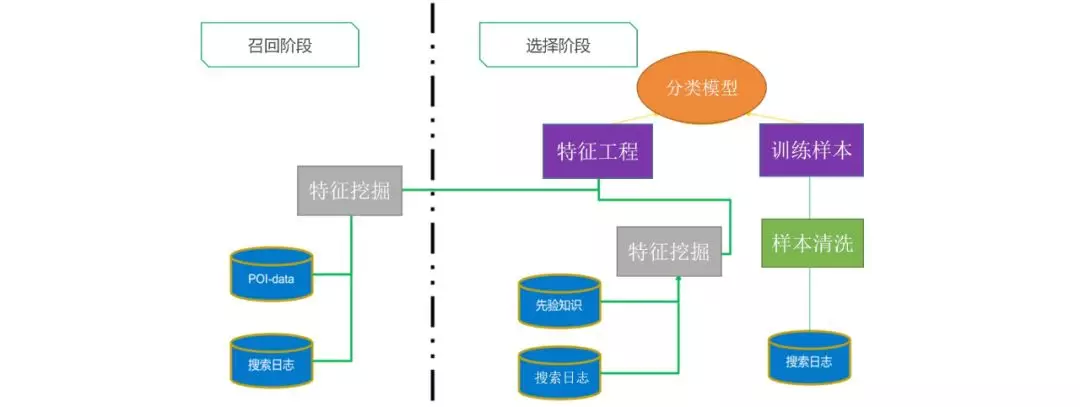
方案
城市分析是一个轻召回重选择的问题,我们将城市分析设计为召回+选择的两阶段任务。
召回阶段,我们主要从 query 和 phrase 两种粒度挖掘特征资源,而后进行候选城市归并。
排序阶段,需要对候选城市进行判断,识别是否应为目标城市,用 gbdt 进行二分类拟合。
样本构建
样本方面,我们选择从搜索日志中随机抽取,简单清洗后,进行人工标注。构造样本时存在本异地分样本分布不均的问题,本地需求远远多于异地,这里需要剔除本地和异地相关的特征,避免模型学偏。
特征体系
主要特征包括:
query 级特征:如用户在特定 query&city 下的点击;
phrase 级特征:类比于 query 级的特征,在更细粒度下进行统计;
组合特征:为了克服单一特征表征能力不足的问题,这里我们进行了一些人工特征组合。
改造 2:城市选择
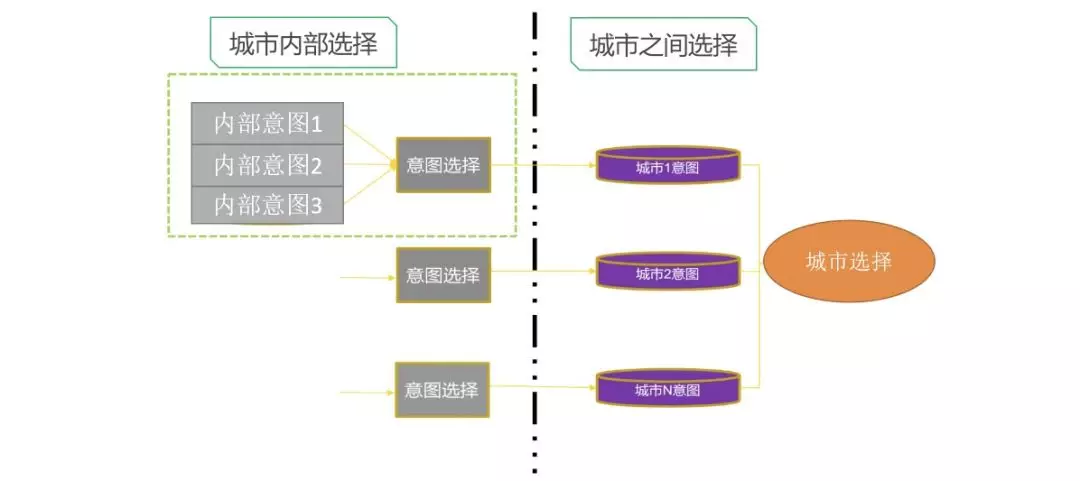
方案
城市选择在整体的意图决策中处于下游,多种意图先在城市内部 PK,然后城市互相 PK。城市选择问题可以理解为多个城市间的排序问题,这里我们使用 ltr 进行城市选择的建模。
样本构建
使用随机 query 的多个城市意图结果作为样本,每次检索只有 1 个展示城市,因而每次只需要从候选城市中选择目标作为正样本,其他候选城市均作为负样本,与目标城市构成 pair 对。
特征构建
主要特征包括:
先验特征。如城市分析部分输出的置信度;
文本特征。一些基础的文本相关性特征;
点击特征。如不同意图城市中的点击强度;
意图特征。一些特征可能影响用户的城市倾向,如用户位置与首位 POI 距离。
相比原始的城市分析和城市选择,两个模块全部实现机器学习化,在恶劣 badcase 显著降低的同时,可维护性大幅提高。在后续的建模中,我们将城市分析作为一个上层应用任务,通过多任务的方式接入到 query 分析的统一模型中来,降低了特征间的耦合,同时实现进一步的效果提升。
4.2 wherewhat 分析
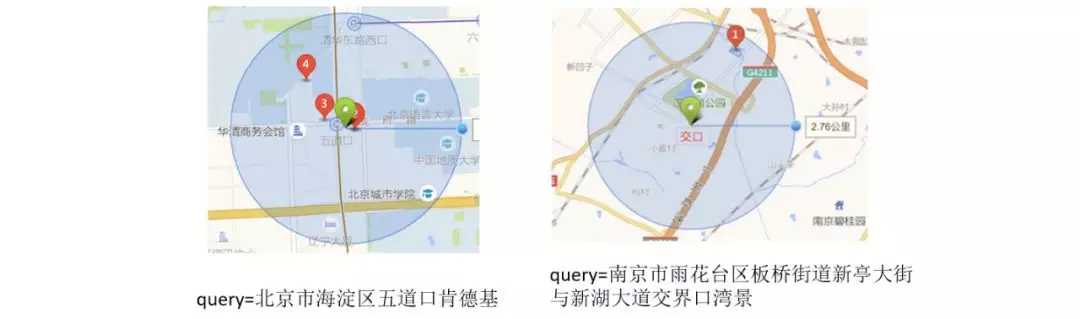
地图场景下的 query 经常包含多个空间语义片段的描述,只有正确识别 query 中的核心部分做 what 用于召回,同时用空间描述部分做 where 进行限定,才能够得到用户想要的 POI。如 query=北京市海淀区五道口肯德基,what=肯德基,是泛需求。query=南京市雨花台区板桥街道新亭大街与新湖大道交界口湾景,what=湾景,是精确需求。这种在 A 附近找 B 或者在 A 范围内找 B 的需求我们把它称作 wherewhat 需求,简称 ww。
wherewhat 意图分析主要包括先验和后验两个部分。先验要做 wherewhat 切分,是一个序列标注问题,标注出 query 中的哪些部分是 where 哪些部分是 what,同时给出 where 的空间位置。后验要做意图选择,选择是否展示 wherewhat 意图的结果,可以转化成分类或者排序问题。
wherewhat 体系的主要难点在 ww 切分上,不仅要应对其他 query 分析模块都要面对的低频和中长尾问题,同时还要应对 ww 意图理解独特的问题。像语义模糊,比如北京欢乐谷公交站,涌边村牌坊这样的 query 该切还是不该切,结果差异很大。像语序变换,如 query=嘉年华西草田,善兴寺小寨,逆序的表达如果不能正确识别,效果可能很差。
现状与问题
现状
切分:wherewhat 模块在成分分析模块下游,主要依靠了成分分析的特征。对于一些比较规整的 query,通过成分分析组合的 pattern 来解决,对于一些中长尾的 query,通过再接入一个 crf 模型进行 ww 标注。
选择:基于人工规则进行意图的判断和选择。
问题 1:切分模型简陋。基于 crf 的切分模型使用特征单一,对成分特征依赖严重,处于黑盒状态无法分析;
问题 2:后验意图判断,规则堆砌,不好维护;
问题 3:逆序问题表现不好。由于 query 的语料大部分是正序的,模型在小比例的逆序 query 上表现不好。
技术改造
crf 问题分析工具
为了能够分析原始 crf 切分模型的问题,我们基于 crf++源码开发了一个 crf 模型的分析工具,能够将基于维特比算法的预测过程交互式的展示出来,将模型的黑盒分析变成白盒,分析出了一系列问题。
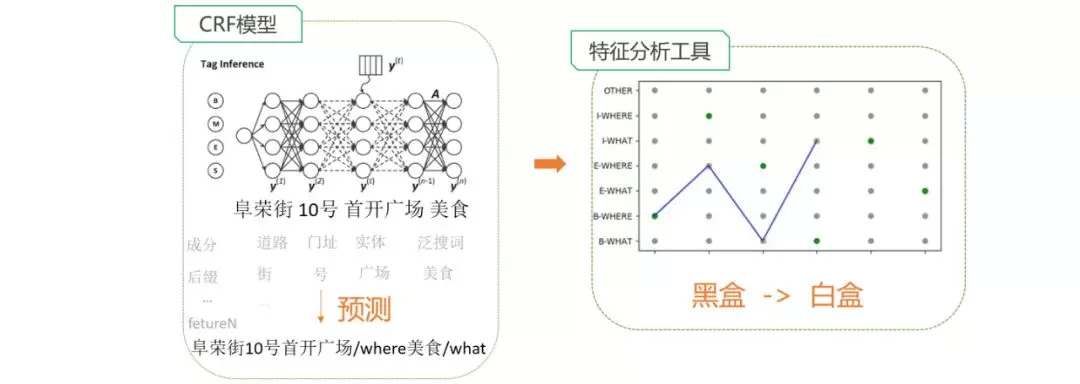
同时,crf 问题分析工具也应用在了其他 query 分析模块。
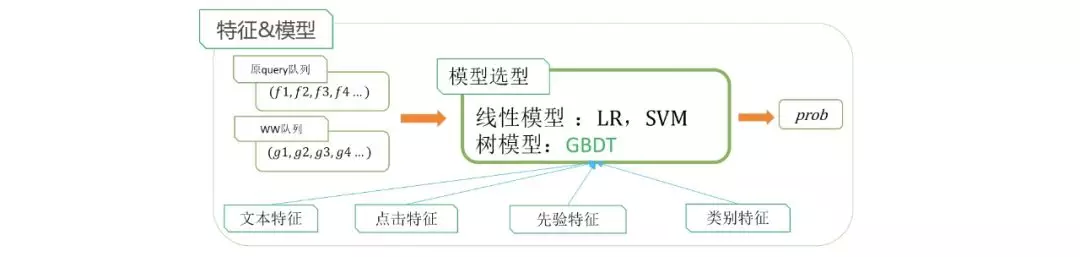
改造 1:特征建设和模型优化
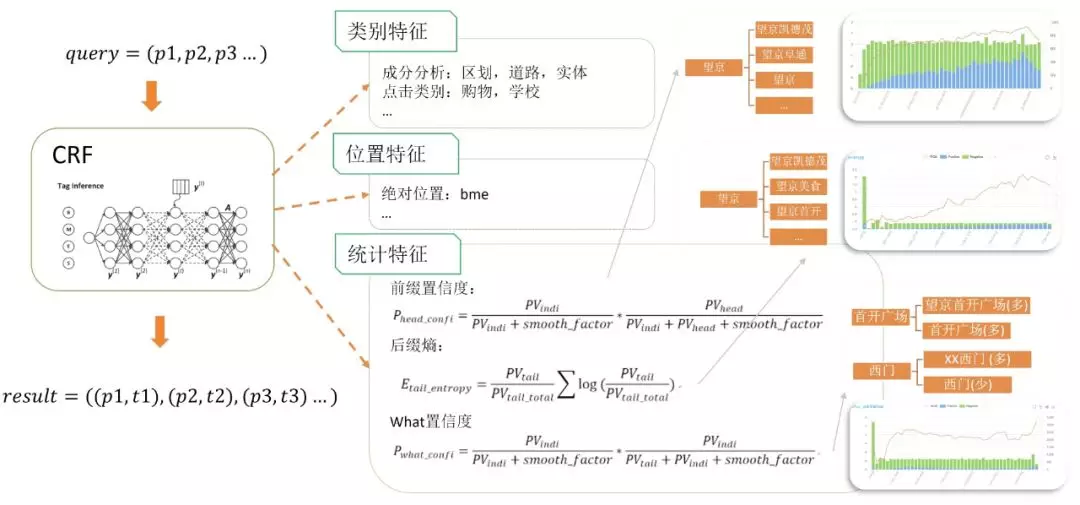
原始的模型依赖成分分析比较严重,由于成分分析特征本身存在准确率的问题,我们从用户的 query 中总结了一些更加可靠的统计特征。
前缀置信度
描述了片段做前缀的占比。比如望京凯德茂,望京阜通,也有望京单独搜,如果望京在前缀中出现的占比很高,那说明这个片段做 where 的能力比较强。
后缀熵
描述了后缀的离散程度,如望京凯德茂,望京美食,望京首开,后缀很乱,也可以说明片段做 where 的能力。
what 置信度
片段单独搜占比,比如西门经常是在片段结尾出现,但是单独搜比较少,那片段做 what 的能力比较弱。
以特征值域做横轴,where 和 what,label 作为纵轴,就得到了特征-label 曲线。从这几个特征的特征-label 曲线来看,在某些区间下区分度还是很好的。由于 crf 模型只接受离散特征,特征-label 的曲线也指导了特征离散化的阈值选择。对于低频 query,我们通过低频 query 中的高频片段的统计信息,也可以使我们的模型在低频问题上表现更好。
改造 2:后验意图选择升级
将原始的堆砌的规则升级到 gbdt 机器学习模型,引入了先验特征,在拿到一定收益的同时也使得整个体系更加合理。
改造 3:鲁棒性优化
将 ww 中逆序的问题抽象出来,可以归纳为 query 分析中的鲁棒性问题。随着策略优化进入深水区,存在策略提升用户不可感知,攻击 case 容易把系统打穿的问题。
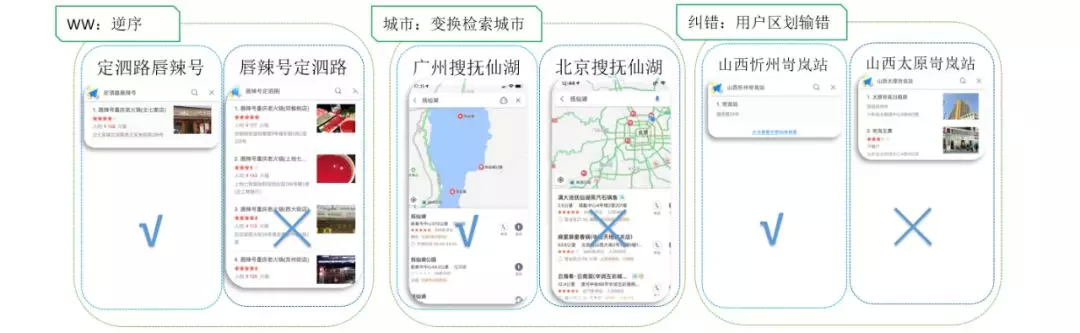
如上图,用户变换 query 中 where 和 what 的顺序,效果可能变差。变换下检索城市,对于同一个知名景点,跳转逻辑不一致。用户区划输错,纠错不能识别,效果变很差。这种模块对非预期的 query 变换,或者更通用地叫做,对上下游的特征扰动的承载能力,我们可以把它叫做模块的鲁棒性。
这里我们设计了对于通用鲁棒性问题解决的思路
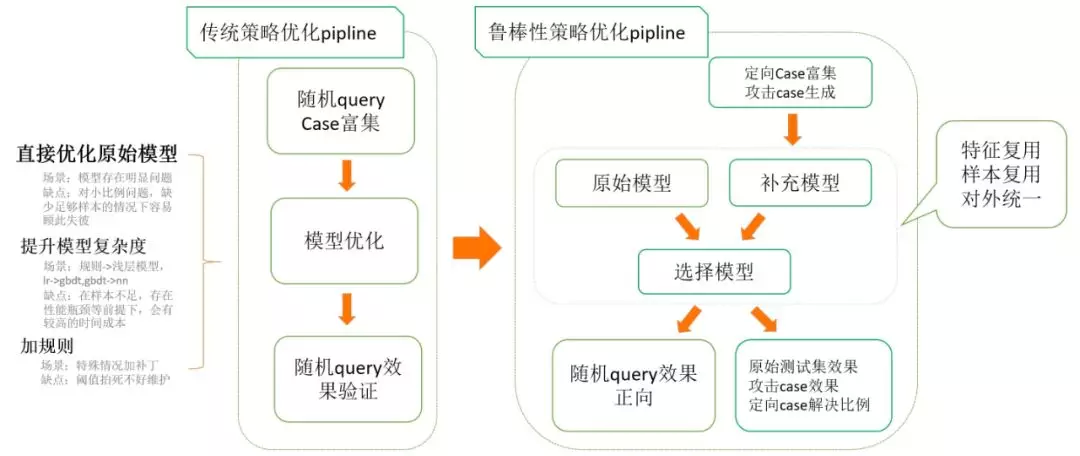
在不引入复杂模型的前提下,通过构建 ensemble 的浅层模型来优化特定问题,降低了问题解决的成本。
对于 ww 逆序这个特定问题进行了特征复用用本复用,并且模型对外统一
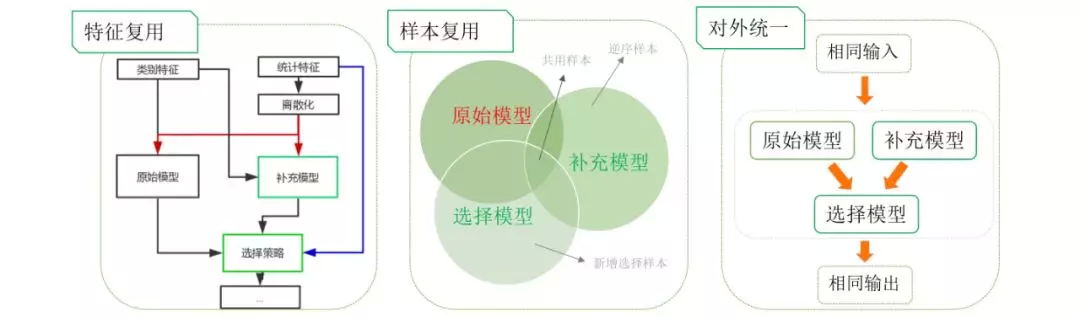
效果上,新的模型在原始测试集效果持平,人工构造攻击 case 集合准召明显提升,目标 case 集合具有可观的解决比例,验证了鲁棒性优化的思路是有效的。
这里基本完成了对于 ww 体系的一个完整的升级,体系中的痛点基本都得到了解决。优化了切分模型,流程更加合理。意图决策上完成了规则到机器学习模型的升级。在优化或者引入浅层机器学习模型的同时尽可能发挥浅层模型的潜力,为从浅层模型升级为深度模型打下基础。
在后续的建模中我们使用字粒度 lstm+crf 模型代替现有的 crf 模型,彻底摆脱了对成分分析特征的依赖,同时通过融合知识信息到 lstm+crf 模型,进一步提升效果。
4.3 路径规划
在高德地图的搜索场景中,一类用户搜索意图为路径规划意图。例如,当用户在高德地图 App 的搜索框中输入“从回龙观到来广营”,点击搜索按钮后,搜索服务能识别出用户的搜索意图为路径规划,并识别出用户描述的起点为“回龙观”,终点为“来广营”,进而检索到对应的 POI 点给下游服务做出路线的规划。
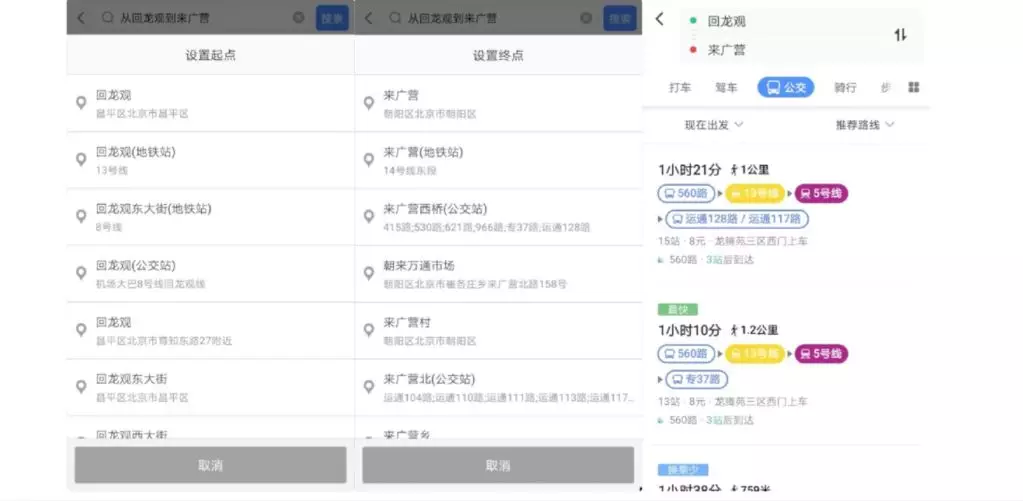
从用户输入中识别路径规划意图,并提取出对应的起终点,这是一个典型的 NLP 任务。早期的路径规划模块使用的是模板匹配的方式,这种方式开发成本低,能解决大部分常见的路径规划问题,如上面这种“从 A 到 B”类的问题。
但随着业务的不断发展,模块需要解决的问题越来越复杂,比如“坐地铁从西直门到大兴狼垡坐到哪里下车”,“广东到安徽经过哪几个城市”,“去往青岛的公交车有吗” 等等各种非“从 A 到 B”模式的问题。由于模板匹配方式没有泛化能力,只能通过不断增加模板来解决,使得模块越来越沉重难以维护。
优化
由于线上所有的搜索 query 都会经过路径规划模块,若是让模型去处理所有的 query,那么模型不仅要解决意图识别问题(召回类问题),又要解决槽位提取问题(准确类问题),对于模型来说是很难同时将这两个任务学好的。因此,我们采取了以下三段式:

模型前使用关键字匹配策略进行简单意图识别,过滤掉大部分非路径规划 query;模型处理疑似路径规划的 query,进行槽位提取;模型后再对模型结果进行进一步检验。
样本和特征
机器学习的样本一般来源于人工标注,但人工标注耗时长成本高。因此我们采取的是自动标注样本方式。通过富集路径规划模式,如“从 A 怎么乘公交到 B”,再用清洗后的随机 query 按照实际起终点的长度分布进行起终点替换,生成大量标注样本。
特征方面,我们使用了成分分析特征及含有关键字的 POI 词典特征。它们主要在如“从这里到 58 到家”这类起终点 中含有关键字的 query 上起着区分关键字的作用。
模型训练
crf 算法是业界常用的为序列标注任务建立概率图模型的算法。我们选取的也是 crf 算法。
效果评估
在验证集准确率召回率,以及随机 query 效果评比上,指标都有了明显的提升。
对于路径规划这样一个定向的 NLP 任务,使用 crf 模型完成了从规则到机器学习模型的升级。作为一个应用层任务,路径规划也很容易被迁移到 seq2seq 的多任务学习模型中来。
五、展望
过去两年随着机器学习的全面应用,以及基于合理性进行的多次效果迭代,目前的地理文本处理的效果优化已经进入深水区。我们认为将来的优化重点在攻和防两方面。
攻主要针对低频和中长尾问题。在中高频问题已经基本解决的前提下,如何能够利用深度学习的技术进行地理文本处理 seq2seq 的统一建模,在低频和中长尾问题上进行进一步优化,获得新一轮的效果提升,是我们目前需要思考的问题。另外,如何更好地融合知识信息到模型中来,让模型能够具有接近人的先验判断能力,也是我们亟待提升的能力。
防主要针对系统的鲁棒性。如用户的非典型表达,变换 query 等定向的问题,如何能够通过定向优化解决这些策略的死角,提高系统的容错能力,也是我们目前需要考虑的问题。
地图搜索虽然是个垂类搜索,但是麻雀虽小五脏俱全,并且有地图场景下很多有特色的的难点。未来我们需要继续使用业界先进的技术,并且结合地理文本的特点进行优化,理解将更加智能化。
本文转载自公众号高德技术(ID:amap_tech)。
原文链接:
https://mp.weixin.qq.com/s/9GuyWUZ_qCH5Q_rin1yQwg

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论