

当前微博服务化采用公有云+私有云的混合云部署方式,承载了每天百亿级的流量,vintage 作为微博微服务的注册中心,为管理 10w 级微服务节点以及在流量激增的情况下的服务快速扩缩容,面临了极大挑战。例如:复杂网络条件下 vintage 服务的高可用保障、解决大批量节点状态变更触发的通知风暴、异常情况下 vintage 节点的自适应和自恢复能力、vintage 多云部署场景下节点数据同步和一致性保障等。
vintage 3.0 优雅的解决了上述问题,具备了良好的扩展性,可用性达到 6 个 9。在 12 月 8 日北京 ArchSummit 全球架构师峰会上,来自微博研发中心的边剑,以挑战和问题切入与大家分享了 vintage 设计原则与方案,以及线上应用的最佳实践。
一、突发热点对微博注册中心的要求与挑战
1.1 突发热点热点事件
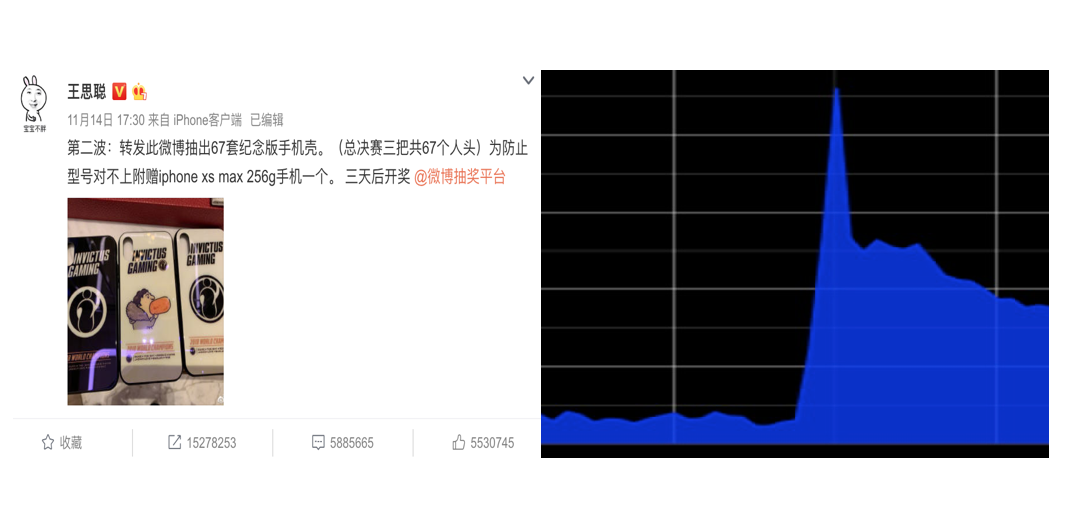
突发热点是微博面临的最常见、最重要的挑战,左图显示的就是最近的一个热点事件,右图是当时热点发生时的流量图,我们可以看出热点事件发生时,在短时间内会引发微博流量的数倍增长。那么面对如海啸般的突发流量,如何应对就显得尤为重要。
根据峰值流量模型不同,应对策略多种多样,但通常总结为下面三种措施:
常备充足的 buffer:该方式更佳适用于可提前预测的流量高峰。如:双十一购物节,微博的春晚保障等。而极热事件往往都具备突发性,很难提前预料,并做好充足的准备。同时极热事件发生时的流量往往高于日常峰值的数倍,且不同极热事件之间流量峰值和流量模型不尽相同,因此也很难准确评估 buffer 的数量。
采用服务降级的方式,保障核心业务:通过对系统接口逻辑中,非核心业务的逐步剪枝,缓解核心接口整体压力,保障业务接口的功能运行及性能稳定,这类方式在很多年前是比较流行的。但此类方式通常会伴随系统功能受限,页面内容不完整等是用户体验下降的情况发生。另外如果在极端场景下,出现降无可降的情况,就非常尴尬。因此这种方法也不是我们目前最好的选择。
弹性扩容:为了克服前两种措施带来的不足,经过多年应对突发流量的经验积累,微博目前使用混合云的部署方式。通过对后端微服务资源的快速扩容,在短时间内迅速为整个系统构建起坚实的大坝。
1.2 突发热点事件对微博注册中心的要求与挑战
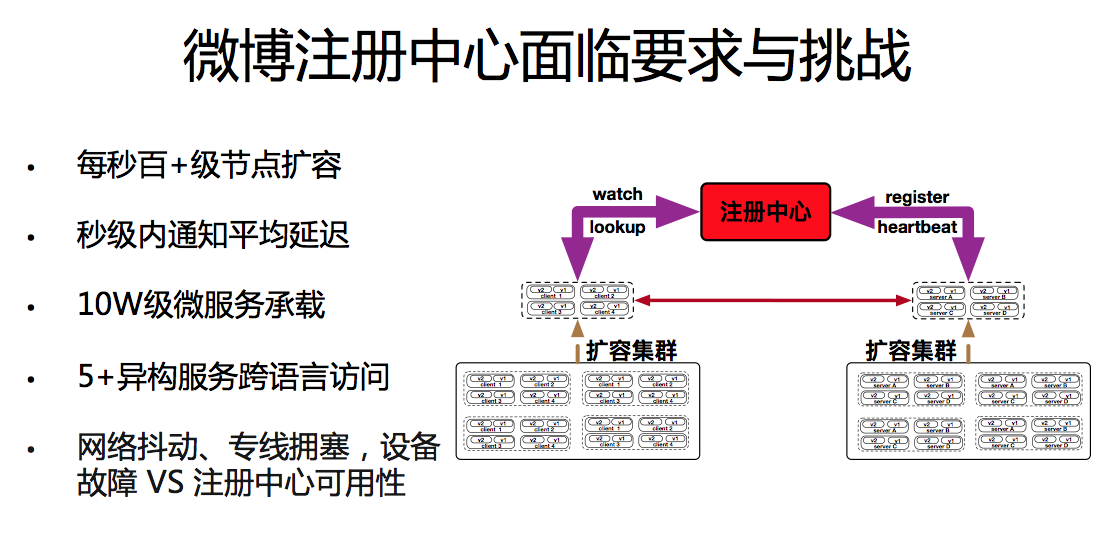
众所周知,微服务的运行必须依赖注册中心的支持。这就对微博注册中心提出了 4 点要求:
要支持每秒百级别以上的微服务扩容
秒级别的微服务变更通知延迟
能承载 10w+ 级别微服务节点
公司级多语言微服务注册&服务发现支持
然而即使我们满足了以上四个要求,但时常还会遇到网络抖动,流量极端峰值时专线带宽拥塞等情况。那么如何在网络状态不好情况下,保障微博注册中心的可用性,实现微服务正常扩容就成为了微博注册中心在设计时必须要面临的挑战。
**二、vintage **高可用设计 &实践
2.1 设计目标:

针对上面提到的要求和挑战,设计微博注册中心时在功能上要实现公司级别的注册中心及配置管理平台,支持多 IDC,支持多语言,具备 10w+级微服务承载能力,可用性上需满足 6 个 9。在服务性能方面,要具备每秒对百级别以上微服务的扩容能力。同时要求通知平均延迟低于 500ms。而在伸缩性上,微博注册中心自身必须具备十秒级节点扩容,以及分钟级 IDC 注册中心搭建。
2.2 选型对比
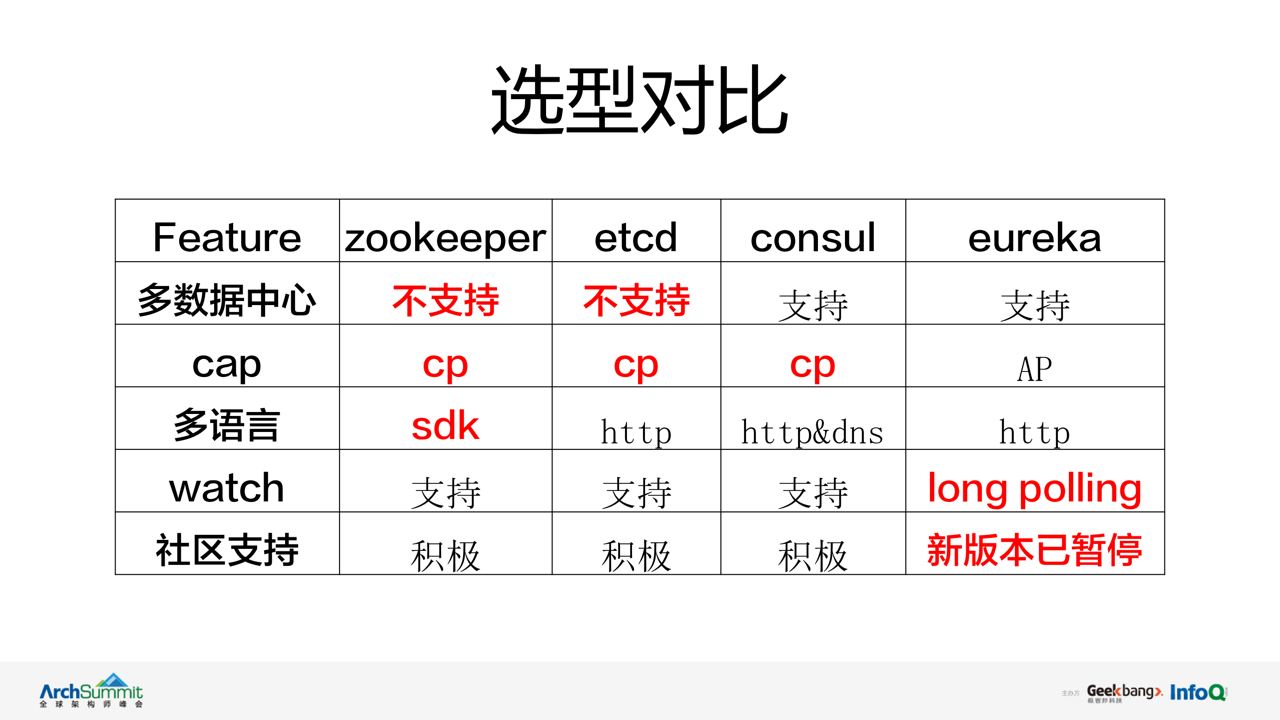
根据设计目标,对业界比较流行的注册中心进行了调研。ZooKeeper,Etcd 无法较好满足微博对多机房支持要求。Consul 虽然满足了多机房的支持,但在网络 QoS 发生时由于其本身的 CP 模型设计,在服务可用性方面不能提供很好的保障。而 Eureka 虽然在多机房和可用性方面都满足微博的要求,但 Eureka 目前仅支持以长轮询的方式订阅服务,在通知延迟方面不能很好的支持,同时 Eureka 在社区支持方面已暂停了新版本的研发。
综合考虑上述指标 ZooKeeper,Etcd,Consul,Eureka 均都无法很好的满足微博对注册中心提出的要求。因此我们决定在现有的 vintage 系统基础上进行升级改造,来满足具备公司级注册中心的能力。
2.3 vintage 架构设计
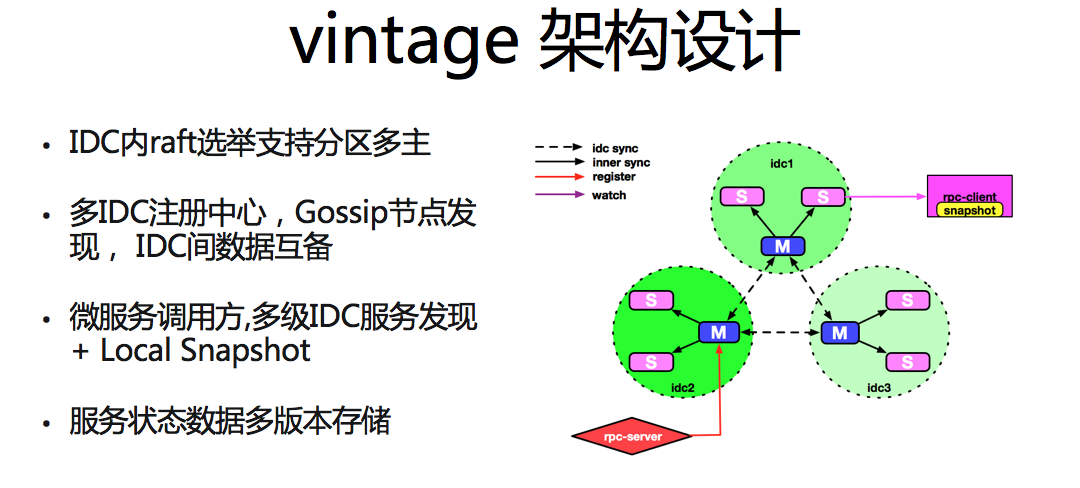
vintage 部署拓扑
先从系统拓扑部署了解下新版 vintage 的整体设计。vintage 服务采用多 IDC 的部署方式,通过 Gossipe 协议,实现节点间的自动发现。IDC 间主主通信实现多机房间数据同步。IDC 内采用一主多从的部署方式,基于 Raft 实现了可支持分区多主的选举协议,主从节点角色之间实现读写分离。
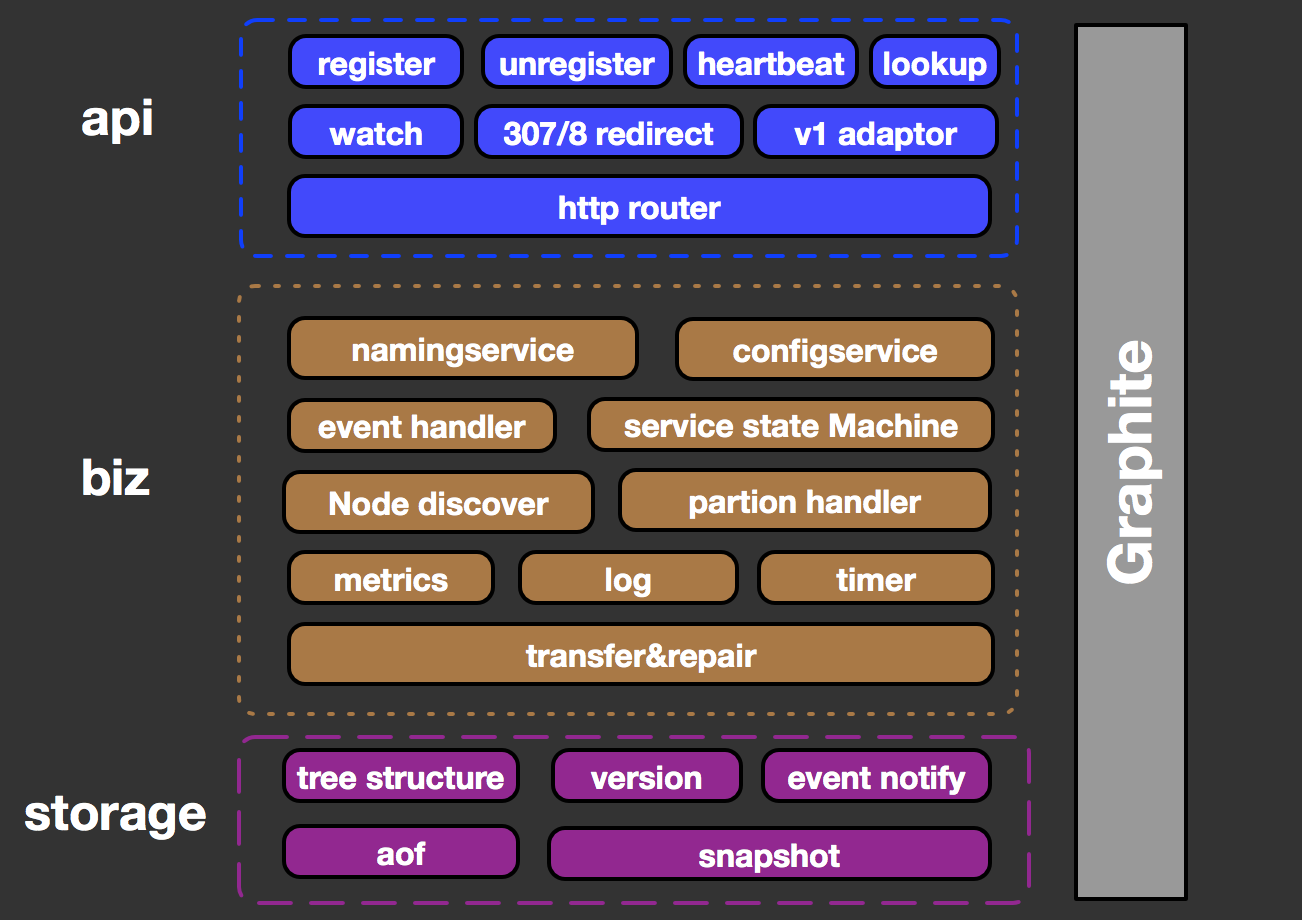
vintage 模块架构图
vintage 系统采用典型三层结构设计,将网络层,业务层,存储层抽象分离。
最上层是 Restful 风格实现的 API 接口,提供微服务注册,订阅及健康检测等功能。同时通过307,308模块完成对上下行流量的主,从节点分流。
中间的业务层包括命名和配置两大核心业务的功能实现。在 vintage 内部功能方面,Node discovery 模块实现了集群的全局节点自动发现,timer 和 service state Machine(微服务状态机)共同配合完成对微服务状态的高效管理。同时在 vintage 中的任何注册,注销及微服务元数据更新,节点状态变更等行为都将被抽象为一个独立事件并交由 event handler 进行统一处理。Transfer 和 repair 模块用于整个集群的节点间数据同步及一致性修复功能。而为应对网络问题对注册中心及整个微服务体系可用性产生的影响,vintage 内部通过 partion hanlder 实现网络分区状态的感知并结合多样化的系统保障策略予以应对。
最下面的存储层:采用基于树形结构的多版本数据存储架构,实现了对众多微服务及其所属关系的有效管理,支持微服务的灰度发布。event notify 模块将数据变更事件实时通知到业务层,配合 watch hub 完成对消息订阅者的实时推送。在数据可靠性方面,采用 aof+snapshot 方式实现本地的数据持久化。
2.4 高可用实践

了解整个系统后,将通过网络分区,通知风暴,数据一致性,高可用部署四个方面介绍 vintage 在高可用方面的实践,以及 AP 模型注册中心在数据一致性保障方面的措施。
网络分区
场景一:vintage 内部网络分区
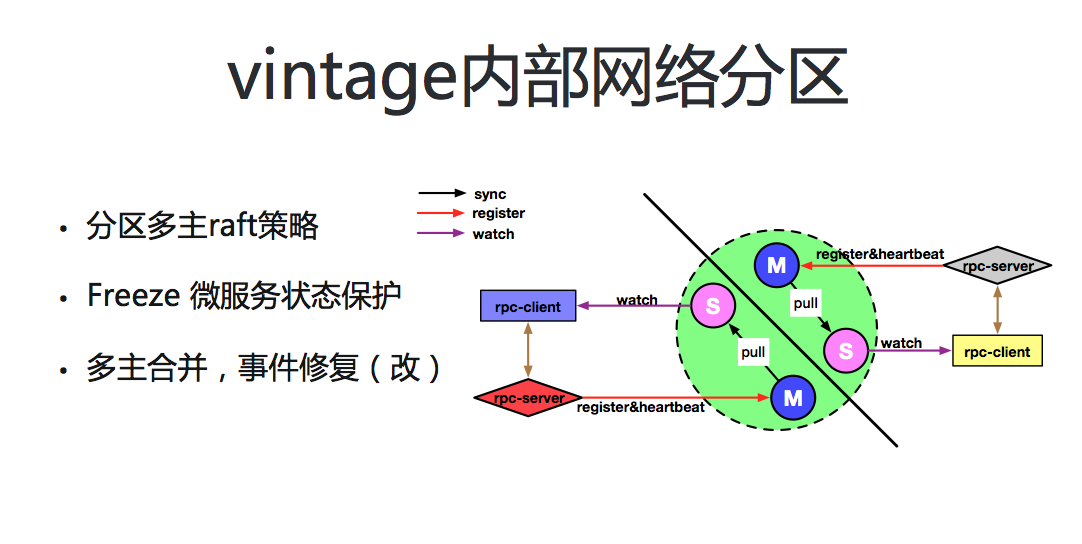
如上图,网络分区将 vintage 集群一分为二,同时每个分区中的节点数量均少于 n/2+1 个(n 为该 IDC 子集群 vintage 服务的节点总数)。在该场景下基于传统 Raft 协议的注册中心,由于对数据强一致性的要求,将无法提供正常的读写服务。而 Etcd 和 Consul 在解决这个问题时,也仅是通过 stale read 的方式满足了对数据读取的需要,但仍然无法实现在该场景下对微服务注册的需要。
微博注册中心为实现在网络分区下注册中心服务高可用,对原有 Raft 协议选举机制进行改造,实现了可对任意分区情况下的多主选举支持:(1)解决了分区发生时处于少数分区内 rpc-server 与 rpc-client 的注册及服务发现能力。实现任何粒度分区下 vintage 服务的高可用。(2)对故障节点的承受能力大幅提升,由原 Raft 协议的 n/2-1 个节点,提升至最大 n-1 节点。
同时在该场景下网络分区后,微服务会将自己的心跳汇报到所属分区的主节点。而由于分区存在,分区间节点数据无法通信。对于(vintage)IDC 集群中的其他主节点来说就出现了微服务心跳丢失的现象,而心跳是作为服务健康状态的重要识别手段。心跳超时的微服务节点将会被标识为不可用状态,从而不会被调用方访问。网络分区时往往会出现大批量的微服务心跳超时,未能妥善处理将直接影响业务系统服务的稳定性及 SLA 指标。而此时 partion handler 模块将会优先于心跳超时感知到网络分区的发生,启动 freeze 保护机制(freeze:注册中心内部对微服务状态的保护机制,基于乐观策略冻结当前 vintage 系统中的微服务节点状态,禁止节点不可用状态的变更,同时对于接受到心跳的微服务节点,支持其恢复可用状态)。
分区恢复后,各节点间通信恢复正常。vintage 会进行再次选举,从分区时的多个主节点中选举出新的主节点。vintage 中的数据变更都会抽象为一个独立事件,系统基于向量时钟实现了对全局事件的顺序控制。在多主合并过程中通过 repair 模块完成节点间数据的一致性修复,保障 IDC 内集群最终一致性。
场景二:client 与 vintage 间网络分区
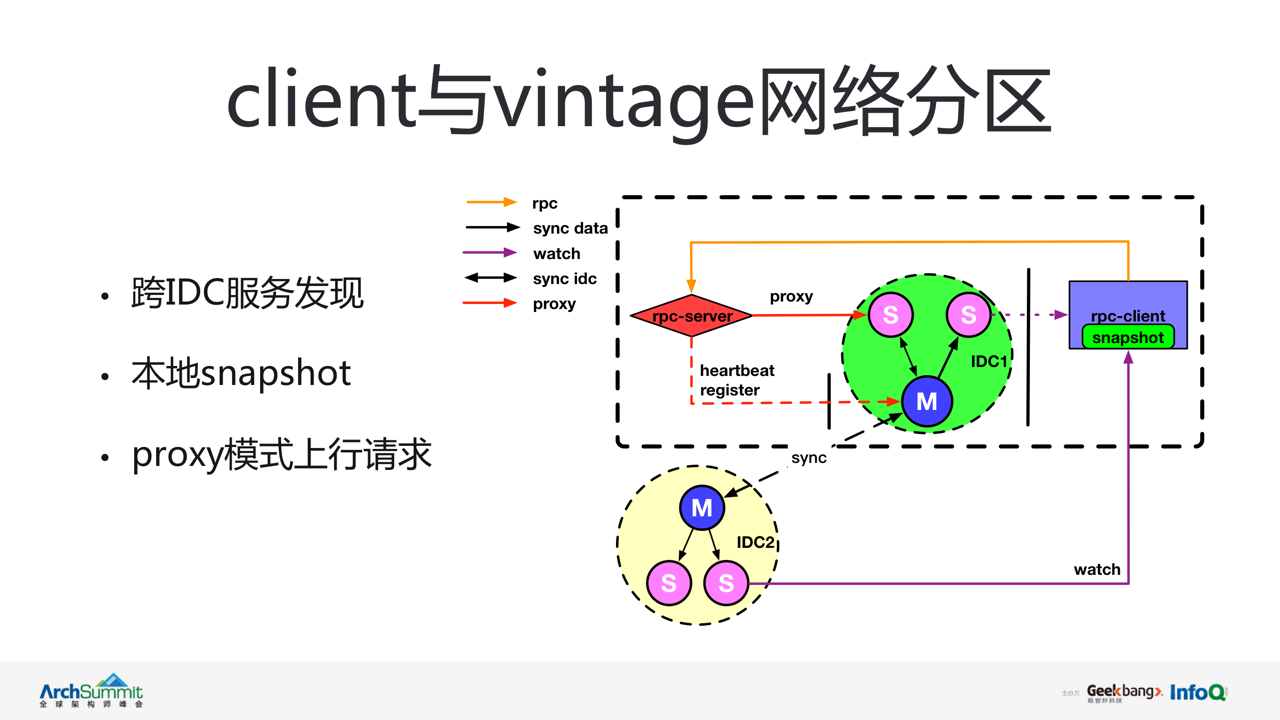
图中绿色和黄色区域分别代表两个不同 IDC 中的 vintage 子集群。红色和紫色代表 IDC1 内的 rpc-server 和 rpc-clinet。此时红色的 rpc-server 与 IDC1 中的 vintage 主节点出现了网络分区,而紫色的 rpc-client 与 IDC1 的 vintage 集群整体存在网络隔离现象。rpc-server 和 rpc-client 之间网络通信正常。虽然这是一个相对复杂且极端的分区场景,但对于微博注册中心的高可用设计要求是必须要解决的问题。下面我们来看看 vintage 是如何解决的。
在该场景下 rpc-server 可通过 DNS 发现的方式获取该 IDC 内 vintage 子集群的全部机器列表,并使用 proxy 模式将注册请求发送至子集群中任意可达的从节点。并通过从节点代理,将注册请求转发至主节点完成服务注册。rpc-server 会定期检测自己与主节点的连接状态,一旦发现连接恢复,将自动关闭 proxy 模式,并通过向主节点发送心跳维护自身状态。
rpc-client 可通过跨 IDC 服务发现方式,在 IDC2 中订阅所关注的 rpc-server 服务信息,其自身还会定期将获取到的 rpc-serve 服务列表保存至本地 snapshot 文件。防止即使 rpc-client 与全部的 vintage 服务均出现网络隔离,也可保证自身正常启动及调用。从而实现了 client 与 vintage 服务分区时,微服务注册与服务发现的高可用。
注:vintage 服务同样支持跨 IDC 的微服务注册。但从实际访问及运维模型考虑,要求每个 rpcserver 节点在同一时刻仅可属于一个 IDC 集群。
通知风暴:
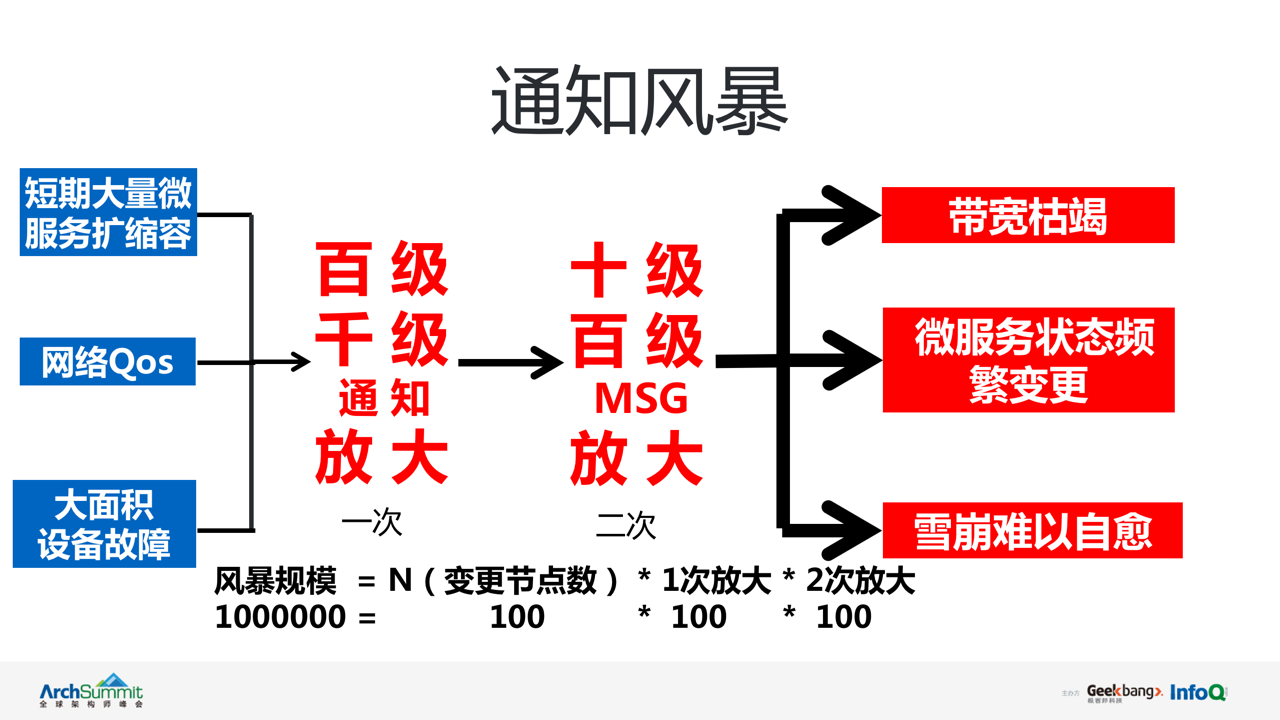
在微博场景下,根据调用方对每种微服务的订阅数量的不同,通常会出现百级至千级别的通知放大,老版本 vintage 的订阅功能是基于 sign(md5 后服务列表指纹)对比+全量数据拉取的方式,根据微服务自身规模同样会出现十级至百级别的消息体放大(二次放大现象)。若此时出现大量微服务扩缩容,网络 QoS 或大面积微服务机器设备的故障,经过两次放大的通知规模可达到百万甚至千万级别,严重占用机器带宽资源。
带宽枯竭,直接影响注册中心业务功能使用;
带宽枯竭还将导致大面积心跳丢失,从而触发大量微服务被标示为不可用状态,直接影响线上微服务的调用;
网络抖动极可能伴随大部分的心跳丢失,易触发频繁的微服务状态在‘不可用’和‘正常’之间来回变化,产生更大量级的通知变更,发生风暴叠加阻塞网络,导致 IDC 内注册中心服务不可用。
针对通知风暴严重危害,改造后的 vintage 系统使用了“梳”和“保”两种策略应对。
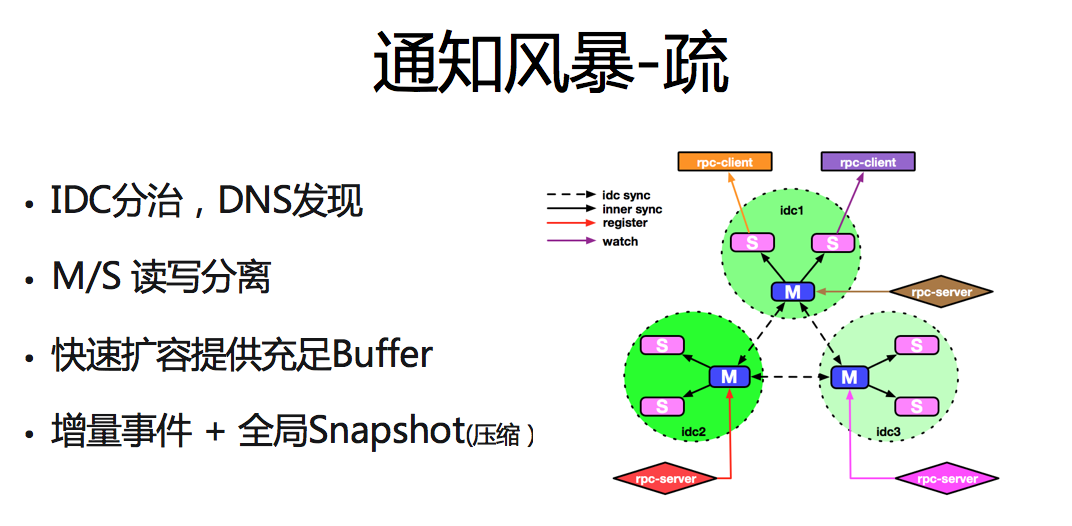
“疏”主要采用的三种策略
分流及负载均衡:首先互联网公司通常根据用户的地域和运营商等信息,将请求分流至不同 IDC,并在核心 IDC 内部部署全量的核心服务,保障 IDC 内完成对用户请求的响应。根据微博流量分配及业务服务多机房部署的特点,vintage 在公司几大核心机房均有部署,实现了多机房微服务上行请求的流量分离。同时根据注册中心写少读多的特点在 IDC 内采用一主多从的部署结构,除保障了服务的 HA 外,也对下行流量实现了负载均衡。
快速扩容:对于通知风暴造成的下行流量,可通过对从节点快速扩容的方式提供充足的服务吞吐及带宽。
增量事件,避免消息体二次放大:vintage 内部将全部的数据变更,统一抽象为独立事件并在集群数据同步,一致性修复和服务发现&订阅功能上均采用增量通知方式,避免了消息体放大问题。将整体消息量有效压缩2-3个数量级,降低带宽的使用。而发生事件溢出时,系统也会先对全量数据压缩后再进行传递。
“保”是通过系统多重防护策略,保障通知风暴下 vintage 及微服务的状态稳定。其主要采用的三种策略:
首先使用 partion handler 实现对 vintage 集群内分区和微服务与集群节点分区网络问题的综合监控。结合 freeze 机制有效避免了微服务节点状态的频繁变更从而同样避免了在网络 QoS 引发的通知风暴。
其次对于业务系统来说,系统整体服务状态相对稳定。基于这点 vintage 为服务增加了保护阈值的设计(默认60%)。通过设置保护阈值,可有效控制通知风暴发生时 vintage 内部异常服务数据变更的规模。更保障业务系统的整体稳定,避免发生服务雪崩。
最后对于带宽枯竭问题,vintage 增加了对带宽使用率的检测和限制。当超过机器带宽消耗>70%,会触发系统304降级,暂停全部通知推送,避免 vintage 节点带宽枯竭保障集群角色心跳维护,节点发现,数据同步等内部功能对带宽的基本要求,维护整个集群的稳定运行。
数据一致性
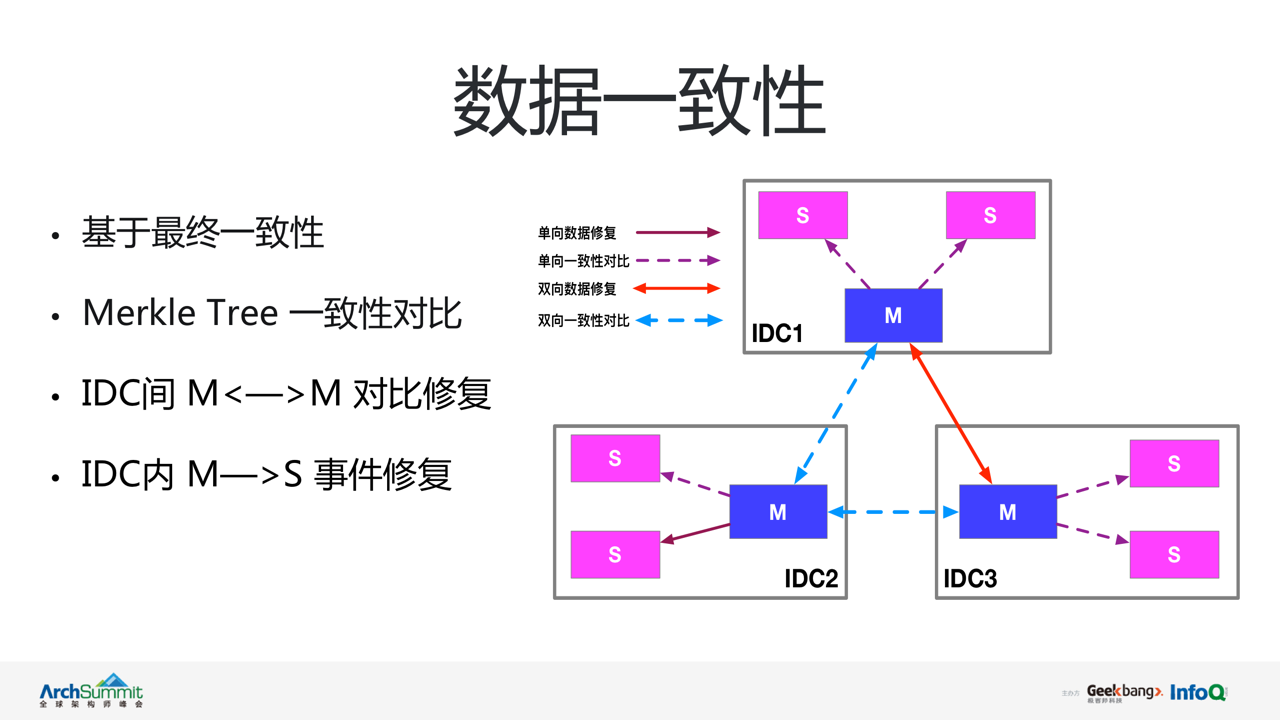
不难看出 vintage 是基于 AP 模型设计的注册中心。该模型下注册中心内节点间数据的一致性问题,成为了 vintage 必须要处理的核心问题。vintage 选择了最终一致性作为集群的数据一致性模型。
接下来介绍 vintage 的最终一致性实现机制。
首先来回顾下 vintage 集群的部署拓扑。vintage 采用多 IDC 部署,各 IDC 间分治独立,IDC 间通过主主节点完成数据同步,IDC 内主从角色读写分离。在该拓扑下,vintage 通过集群内主从,集群间主主的数据同步+差异对比修复相结合的方式,实现节点间数据的最终一致性。(1)数据同步:各 IDC 内均由主节点负责上行请求处理,从节点通过拉取主节点新增的变更事件完成数据同步。(2)同时 vintage 内部对全部存储的数据构建了对应的 merkle Tree,并随数据变化进行实时更新。
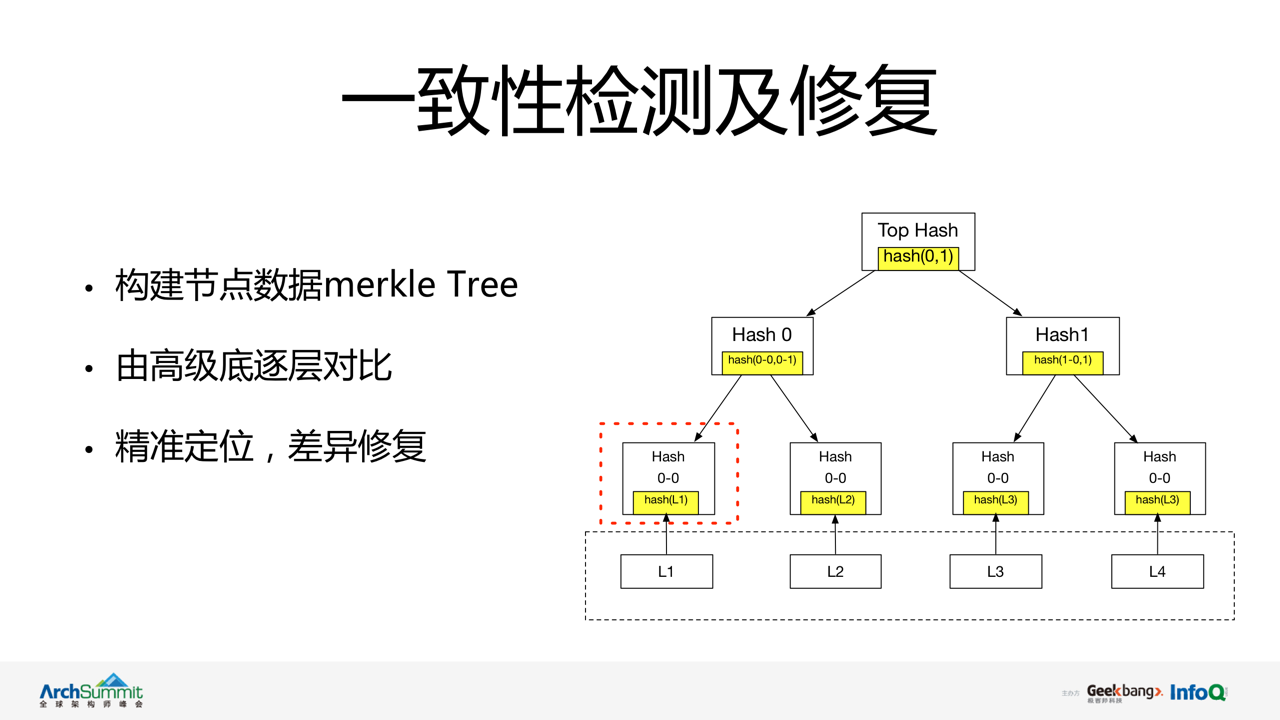
vintage 会定期触发集群一致性检测逻辑。以主节点中数据为标准,IDC 内采用主从,IDC 间则是主主方式使用 merkle tree 特点由根节点逐层对比,精确定位数据差异节点,并完成一致性修复。
注:通过线上运行统计,通常仅有<0.5%的检测结果出现数据不一致现象。利用 merkle Tree 的特点有效优化了数据对比及修复过程中对网络带宽不必要的消耗:
99.5%一致性检测仅需对根节点数据对比即可确认数据一致性。
支持逐层节点对比,可准确定位不一致节点,并针对该节点进行数据修复。
高可用部署:
服务的高可用通常与部署方式必密不可分,vintage 作为公司级别的注册中心本身必须具备极高的可用性和故障恢复能力。
vintage 在部署上主要考虑以下 4 点:
适度冗余度部署:冗余度方面,vintage 服务采用2倍冗余部署,冗余的节点在提升注册中心自身可用性的同时,也为业务系统在突发峰值流量时的快速扩容反应提供了良好的弹性空间。
与网络消耗型业务隔离:作为带宽敏感型服务,vintage 在机器部署时会与网络消耗类业务尽量隔离
多机架部署,同机架内多服务部署:考虑到网络分区和设备故障的因素,vintage 采用多机架部署方式,同机架内通常部署至少两个服务节点。
多 IDC 间数据互备:vintage 天然实现了 IDC 间的数据互备,同时通过冗余一套 IDC 子集群用于全集群的数据灾备。极端情况时可在分钟级实现 IDC 维度的任意子集群搭建,并通过系统内部接口优先从数据灾备的子集群中完成数据恢复。
2.5 高性能:
在介绍 vintage 高可用后,再来看看 vintage 系统在高性能方面如何实现 10w+ 节点的支撑及平均百毫秒级别的通知延迟。
List+Map 数据结构实现了支持 10w 节点高性能定时器。
watch 变更实时推送机制。
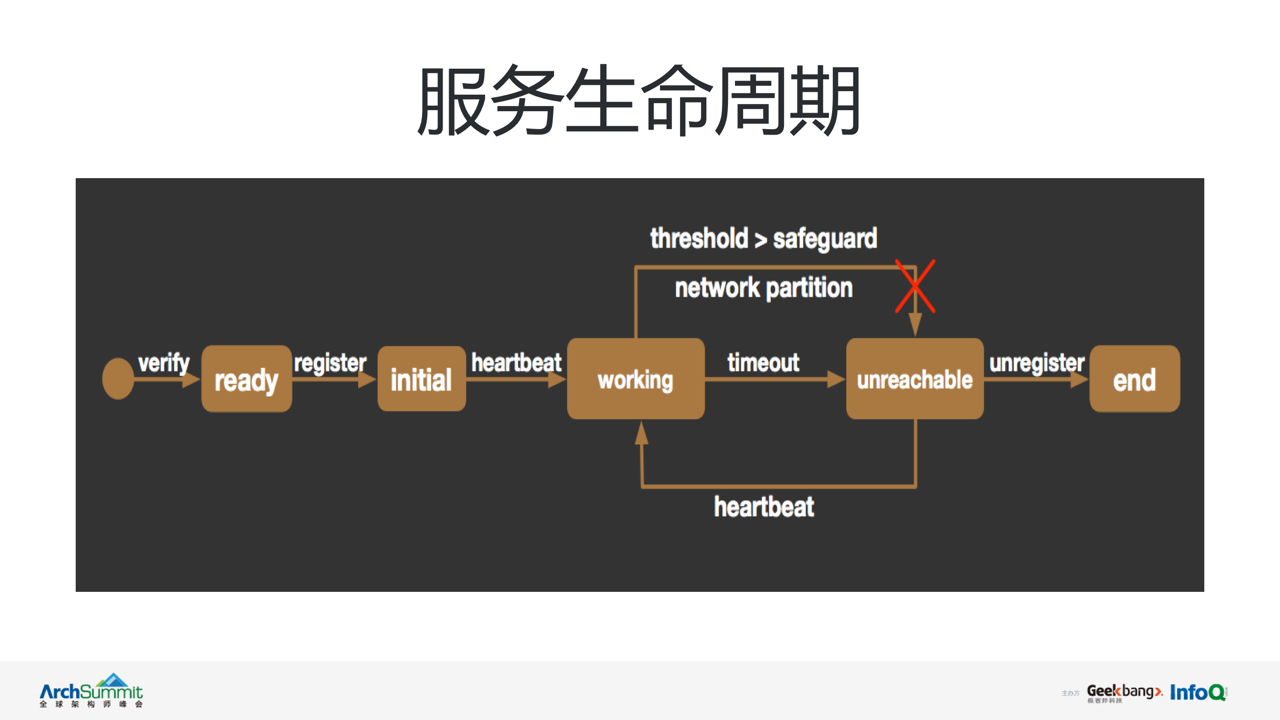
首先了解下微服务在 vintage 系统中的生命周期,这是一张 vintage 内部维护微服务生命周期的状态机。其中 initial,working,unreachable 为 vintage 内部对管理微服务的三个状态,分别用于说明节点处于初始注册状态,可用状态,以及不可用状态。
微服务节点通过调用 register 接口完成注册,vintage 会将该节点状态设置为 initial。注册成功后微服务节点会周期性(5s)向 vintage 发送心跳,汇报自身健康状态,更新服务心跳超时时间。vintage 在收到第一个心跳请求后,将该节点状态被为 working。vintage 会周期性触发对全部 working 状态微服务节点的健康检测,当发现节点心跳超时,该节点状态将被变更至 unreachable,并通过 watch 接口将变更时间推送给订阅方。而 unreachable 状态可通过再次发送心跳,转变为 working 状态。在 working To unreachable 的变更过程中如果触发了 vintage 节点状态保护机制,或出现网络分区,状态变更会被冻结。微服务节点下线时可通过调用 unregister 接口实现注销,完成整个生命周期。
vintage 每个 IDC 中仅由主节点负责全部的上行请求并通过心跳方式维护该 IDC 内全部微服务的健康检测及状态变更。而心跳作为周期性的高频请求,当单 IDC 内节点数达到一定量级时,对主节点的处理能力带来极大的挑战。并直接影响到单 IDC 集群的吞吐和服务节点承载能力。这就需要一个高效定时器来完成上述的挑战。
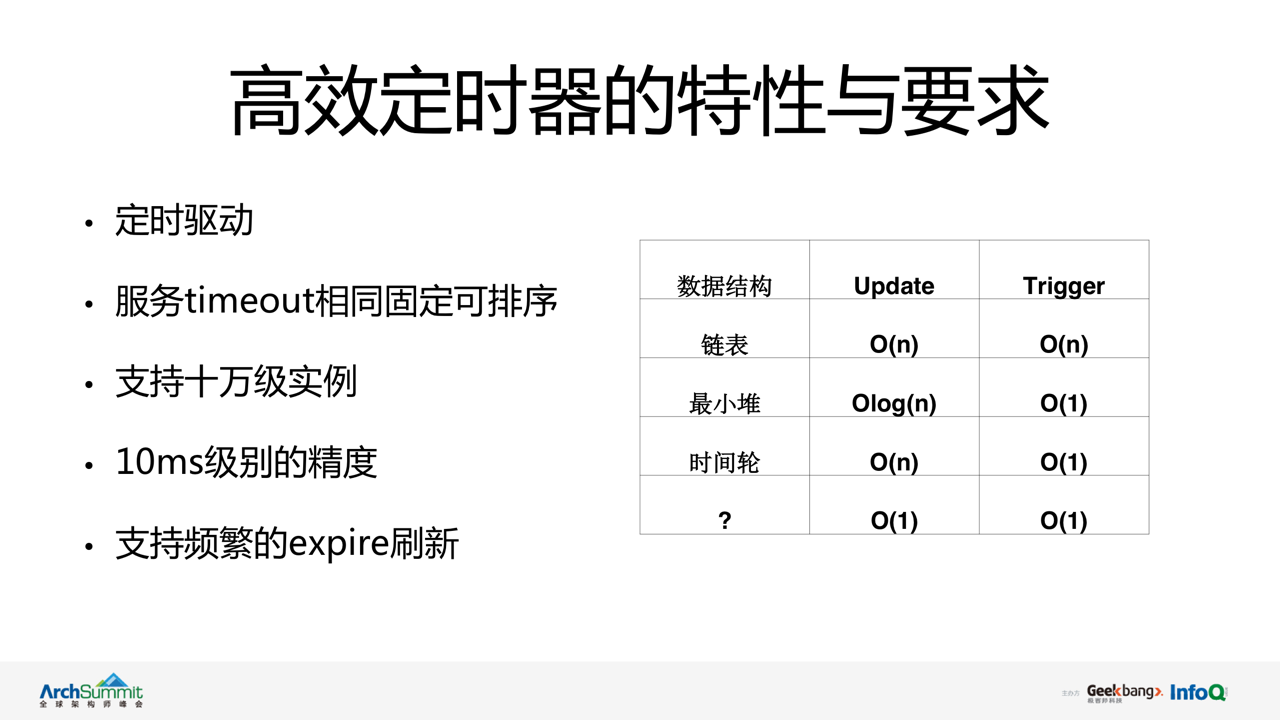
从图中可以看出,在设计上要求单 IDC 集群同样可承担 10w 级的服务节点,支持频繁的 expire 更新,同时要求对节点状态变更精度达到 10ms 级别。
首先对现有的 heartbeat 汇报及超时检测模型分析后,得出以下几个特点:
heartbeat 汇报请求时间,为节点 expire 的续租起始时间。
由于 heartbeat 续租时间固定,节点过期时间可根据续租时间固定排序。
健康检测与心跳独立处理。采用周期性触发机制实现对已排序数据 expire 的超时判断。
通过对特点的分析,并参考了目前比较流行的一些定时器处理算法。不难看出链表,最小堆以及时间轮这些主流定时器的时间复杂度上均会受到节点数的直接影响。那是否有一种数据结构可以做到 update 和 trigger 都是 o(1) 的时间复杂度呢?
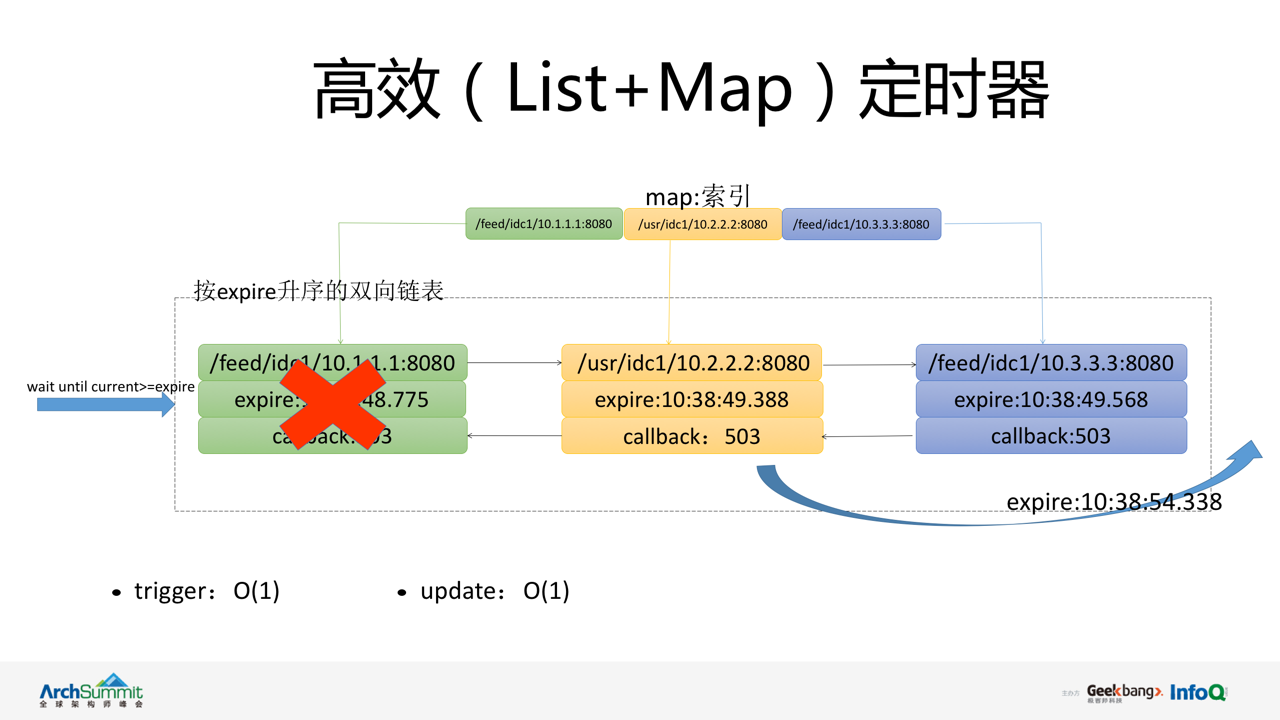
定时器(timer)由 List+Map 共同组成用于维护 vintage 内部所有 working 状态的微服务节点的健康监测和心跳续租。
List 是一个根据 expire 升序排列的有序双向链表,链表中的元素为微服务节点的状态对象,包括节点 ID 和超时时间。Map 保存了微服务的 ID 及状态对象的引用。当 vintage 收到某个节点的心跳请求,会根据节点 ID 从 Map 中获取该微服务节点状态对象,由于心跳续租时间固定,完成 expire 字段更新后无需排序,可直接将节点对象插入在链表的尾部。
timer 会定期触发微服务的超时检测,根据链表 expire 升序的特点,每次检测的顺序都是由首都到尾部,发现首节点 expire 小于当前时间,触发过期操作,将节点从列表中删除,并调用 callback 函数,通知存储模块将节点状态更新为 unreachabl。依次向后检查链表中的各节点,直到出现第一个未过期的节点为止。
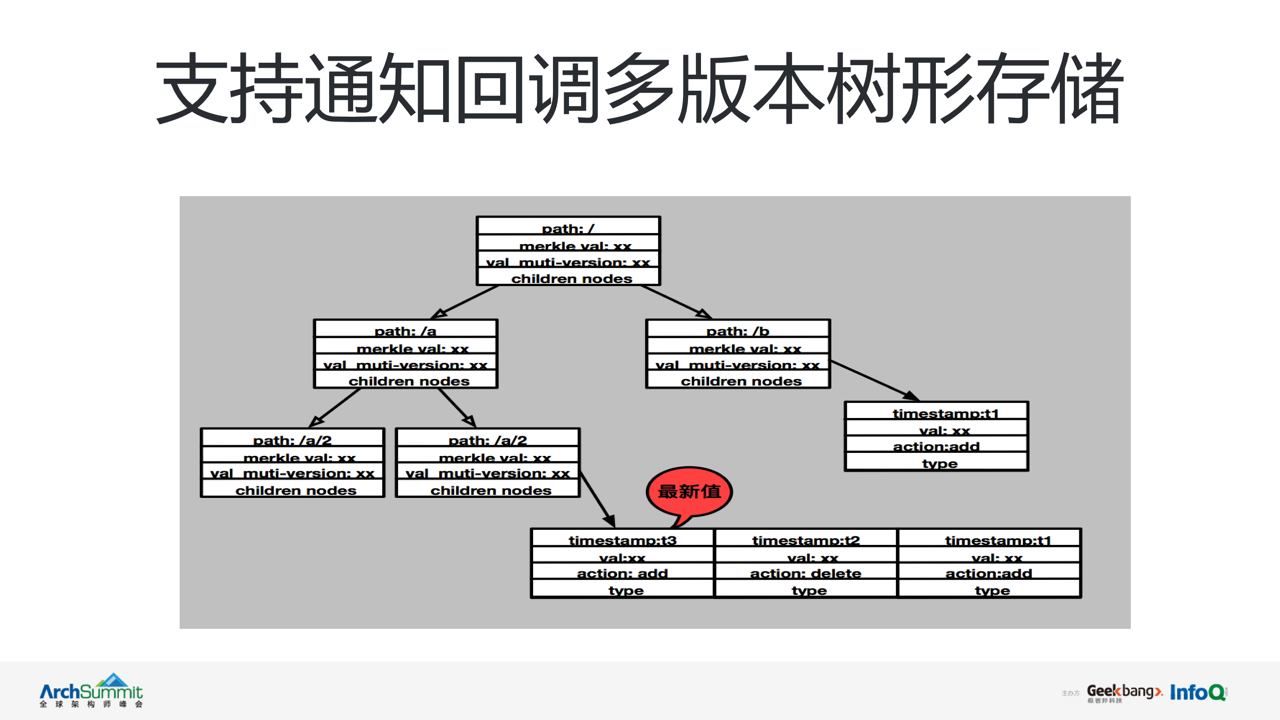
当服务状态变更,节点的注册与注销时都会将数据记录到存储中。vintage 实现了一套基于树形结构的多版本数据存储。依赖于树形存储结构,vintage 在实现对数据存储能力外,还可将微服务依照 /IDC/部门/业务线/服务/集群/服务节点 的方式分层管理。同时借助于多版本实现了从数据到事件的转换,并通过 Event notify 模块将变更事件实时回调通知 watch hub,完成对新增事件的订阅推送。
watch 推送机制
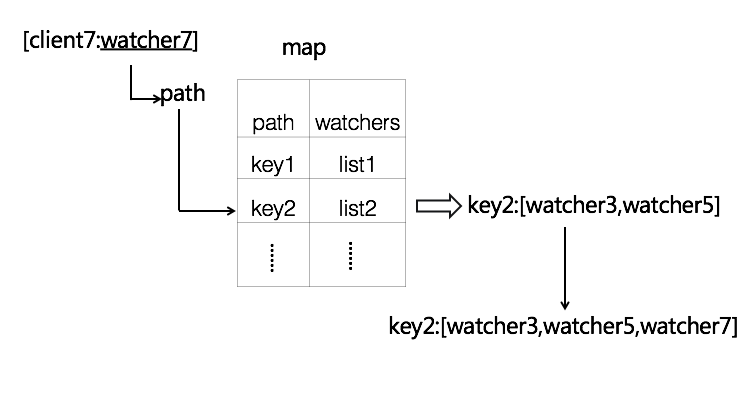
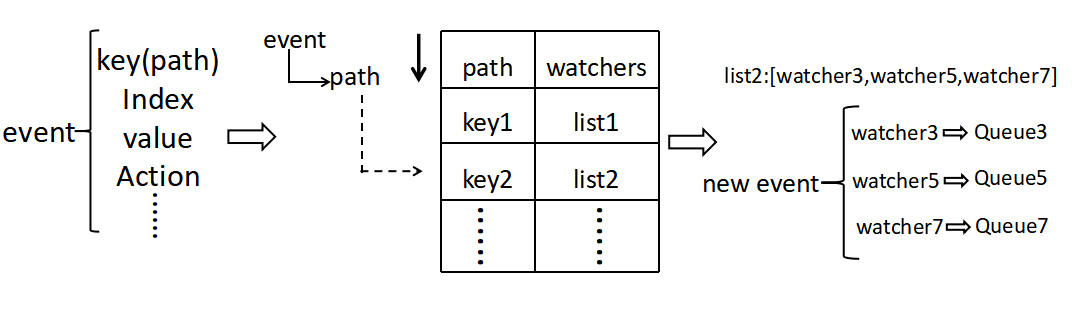
client 注册 watchhub
client 向 vintage 订阅服务变化过程。会首先向 vintage 的 watch hub 进行注册,watch hub 会为每个订阅方生成一一对应的 watcher 对象,并根据订阅目标的 path(ID),将相同路径的 watcher 合并至一个 watchers 列表中,保存在 watch hub 的 map 索引结构。
存储层数据变更通知
当 storage 完成数据存储后,会将数据变更的信息转换为新增事件通过 Event notify 模块回调通知 watch hub。watch hub 通过该 event 中的 path 在 map 索引找到订阅的 watchers 对象,并将事件写入全部 watcher 的 event queue 中。由 watch 函数完成事实数据推送。
注:若 path 是多层结构时,watch hub 通过逆向递归的方式,将该事件依次插入多个 event 队列,实现 watch hub 的 path 递归功能。
系统伸缩性
为保障微服务的快速扩容,vintage 服务自身必须具备快速的扩容能力 vintage 会通过 Docker 化部署及 node discovery 节点自动发现能力,实现秒级别的扩容。并通过整合 Jpool+Dcp 体系,目前可实现分钟级 IDC 注册中心搭建。
多语言支持
在多语言支持方面,vintage 系统通过 HTTP Restful API 满足了公司级跨语言注册中心的服务支持。同时也在不断扩展多语言官方 SDK,目前已实现了 Java,Go 的支持。
三、总结
新版 vintage 系统已在线上运行了一年多,经历了微博春晚保障,土城、永丰核心机房网络升级以及数不胜数的突发热点事件。
vintage 系统使用多 IDC 部署方式支持公司混合云战略,承担十万级别微服务注册与服务发现。同时系统可用性达到 99.9999%,通知变更平均延迟< 200ms,p999 延迟低于 800ms。vintage 注册中心在可用性和性能上,也满足了业务在突发热点时的应对保障,将常备业务机器的 buffer 由 40% 降低至 25%。
嘉宾介绍:
边剑:新浪微博技术专家,专注于高可用架构,有多年高并发系统架构设计和研发经验,现就职于微博研发中心-平台架构部,主要从事微博平台公共服务及中间件系统的设计及优化,作为核心技术成员参与微博服务化建设。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...









评论 2 条评论