

本篇介绍深度学习在自然语言处理(NLP)中的应用,从词向量开始,到最新最强大的 BERT 等预训练模型,梗概性的介绍了深度学习近 20 年在 NLP 中的一些重大的进展。
在深度学习之前,用于解决 NLP 问题的机器学习方法一般都基于浅层模型(如 SVM 和 logistic 回归),这些模型都在非常高维和稀疏的特征(one-hot encoding)上进行训练和学习,出现了维度爆炸等问题难以解决。并且基于传统机器学习的 NLP 系统严重依赖手动制作的特征,它们极其耗时,且通常并不完备。
而近年来,基于稠密向量表征的神经网络在多种 NLP 任务上得到了不错结果。这一趋势取决了词嵌入和深度学习方法的成功;并且深度学习使多级自动特征表征学习成为可能。因此,本文从词的分布式表征开始介绍深度学习在 NLP 中的应用。
分布式词表征(词向量)的实现
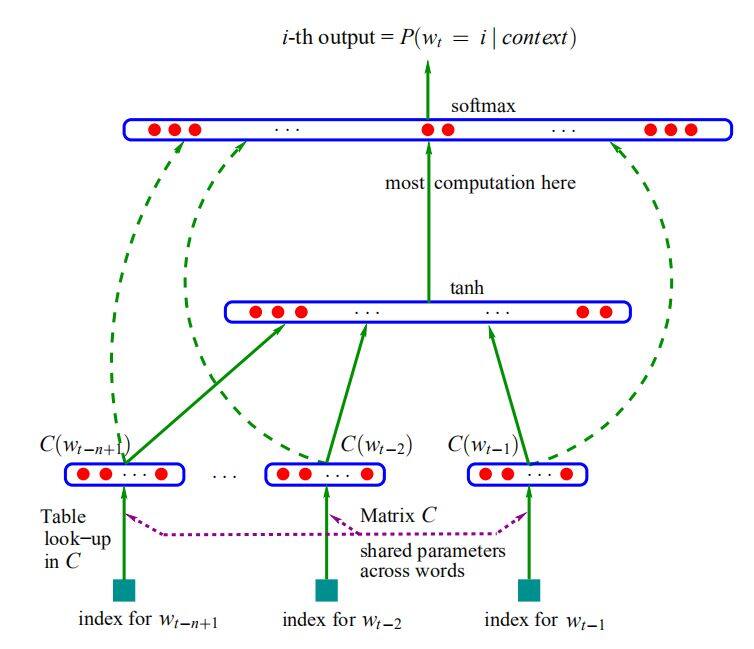
通常来讲,在 2003 年的《A Neural Probabilistic Language Model》中 Bengio 等人提出了神经语言模型(NNLM),而它的副产品,词向量,可以实现词的分布式表征。该文通常被认为是深度学习在自然语言处理中应用的开始。提出伊始,由于届时计算机计算能力的限制,该网络并不能较好的得到训练。因此,这一篇成果,在当时并没有得到相当的关注。其神经网络结构如下:
2008 年 Collobert 和 Weston 展示了第一个能有效利用预训练词嵌入的研究工作,他们提出的神经网络架构,构成了当前很多方法的基础。这一项研究工作还率先将词嵌入作为 NLP 任务的高效工具。
不过词嵌入真正走向 NLP 主流还是 Mikolov 等人在 2013 年做出的研究《Distributed Representations of Words and Phrases and their Compositionality》。
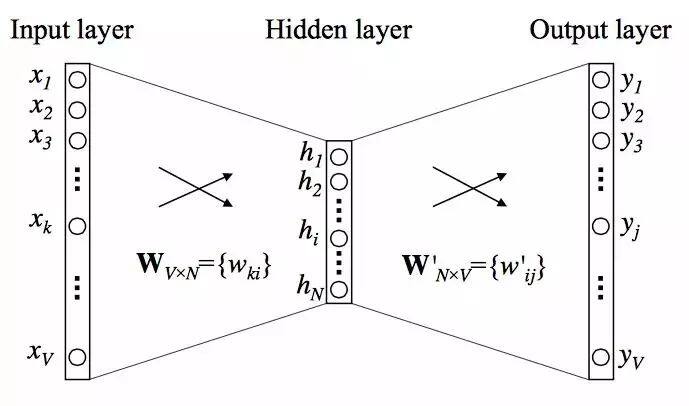
Mikolov 等研究者在这篇论文中提出了连续词袋模型 CBOW 和 Skip-Gram 模型,通过引入负采样等可行性的措施,这两种方法都能学习高质量的词向量。CBOW 模型的网络结构如下:
分布式的词表征的一大好处是实现了语义的合成性,即两个词向量相加得到的结果是语义相加的词,例如[man]+[royal]=[king]。
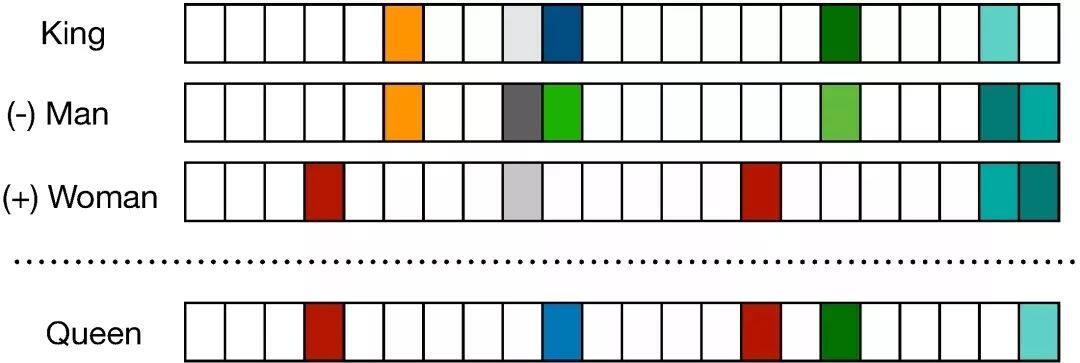
这种语义合成性的理论依据最近已经由 Gittens et al. 在 2017 年给出,他们表示只有保证某些特定的假设才能满足语义合成性,例如词需要在嵌入空间中处于均匀分布。
GloVe 是另外一个很有名的获得词向量的方法,在有些情况下,CBOW 和 Skip-Gram 采用的交叉熵损失函数有劣势。因此 GloVe 采用了平方损失。同时,它基本上是一种基于词统计的模型,它令词向量拟合预先基于整个数据集计算得到的全局统计信息,从而学习高效的词表征。
NLP 中特征提取方法的进化
随着词分布式表征的问题得到了有效的解决,人们开始思考如何提取词序列中高级的语义信息,然后才能将这些提取到的语义信息,应用到下游的 NLP 任务中,例如情感分析、问答系统、机器翻译以及自动摘要等。
最早用来对自然语言词序列进行特征提取的,其实是卷积神经网络(CNN)。这主要归因于卷积神经网络在图像领域取得的骄人成绩。
使用 CNN 进行句子建模可以追溯到 Collobert 和 Weston 在 2008 年的研究,他们使用多任务学习为不同的 NLP 任务输出多个预测,如词性标注、语块分割、命名实体标签和语义相似词等。其中查找表可以将每一个词转换为一个用户自定义维度的向量。因此通过查找表,n 个词的输入序列 {s_1,s_2,… s_n } 能转换为一系列词向量 {w_s1, w_s2,… w_sn}。
在 Collobert 2011 年的研究中,他扩展了以前的研究,并提出了一种基于 CNN 的通用框架来解决大量 NLP 任务,这两个工作都令 NLP 研究者尝试在各种任务中普及 CNN 架构。CNN 具有从输入句子抽取 n-gram 特征的能力,因此它能为下游任务提供具有句子层面信息的隐藏语义表征。
因为语言序列常常具有长程性,需要记忆很早时候的输入信息,CNN 并不具备这种能力。这个时候,循环神经网络(RNN)网络被提出。
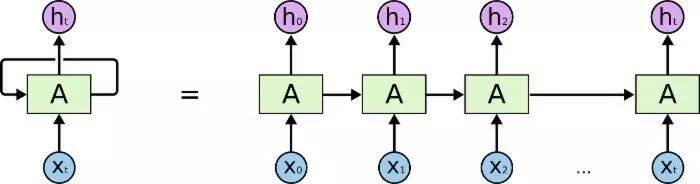
RNN 的思路是处理序列信息。“循环”表示 RNN 模型对序列中的每一个实例都执行同样的任务,并且权重共享,从而使输出依赖于之前的计算和结果。
通常,RNN 通过将 token 挨个输入到循环单元中,来生成表示序列的固定大小向量。一定程度上,RNN 对之前的计算有“记忆”,并在当前的处理中使用对之前的记忆。该模板天然适合很多 NLP 任务,如语言建模、机器翻译、语音识别、图像字幕生成。因此近年来,RNN 在 NLP 任务中逐渐流行。
但是 RNN 容易出现梯度消失和爆炸的问题,因而其改进版本 LSTM 和 GRU 被提出来了。
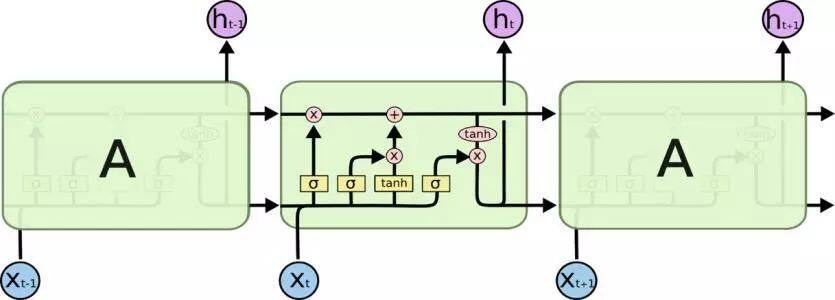
LSTM 比简单 RNN 多了“遗忘门”,其独特机制帮助该网络克服了梯度消失和梯度爆炸问题。与原版 RNN 不同,LSTM 允许误差通过无限数量的时间步进行反向传播。它包含三个门:输入门、遗忘门和输出门,并通过结合这三个门来计算隐藏状态。另一个门控 RNN 变体是 GRU,复杂度更小,其在大部分任务中的实验性能与 LSTM 类似。GRU 包括两个门:重置门和更新门,并像没有记忆单元的 LSTM 那样处理信息流。因此,GRU 不加控制地暴露出所有的隐藏内容。由于 GRU 的复杂度较低,它比 LSTM 更加高效。
在 llya Sutskever 等人 2014 年的研究《Sequence to Sequence Learning with Neural Networks》中,作者提出了一种通用深度 LSTM 编码器-解码器框架,可以实现序列之间的映射。使用一个 LSTM 将源序列编码为定长向量,源序列可以是机器翻译任务中的源语言、问答任务中的问题或对话系统中的待回复信息。然后将该向量作为另一个 LSTM 解码器的初始状态。在推断过程中,解码器逐个生成 token,同时使用最后生成的 token 更新隐藏状态。
传统编码器-解码器框架的一个潜在问题是:有时编码器会强制编码可能与目前任务不完全相关的信息。这个问题在输入过长或信息量过大时也会出现,选择性编码是不可能的。因此,能够根据编码器编码内容动态解码内容的注意力机制(Attention)得到提出。
《Neural Machine Translation by Jointly Learning to Align and Translate》首次将注意力机制应用到机器翻译任务,尤其改进了在长序列上的性能。该论文中,关注输入隐藏状态序列的注意力信号由解码器最后的隐藏状态的多层感知机决定。通过在每个解码步中可视化输入序列的注意力信号,可以获得源语言和目标语言之间的清晰对齐。
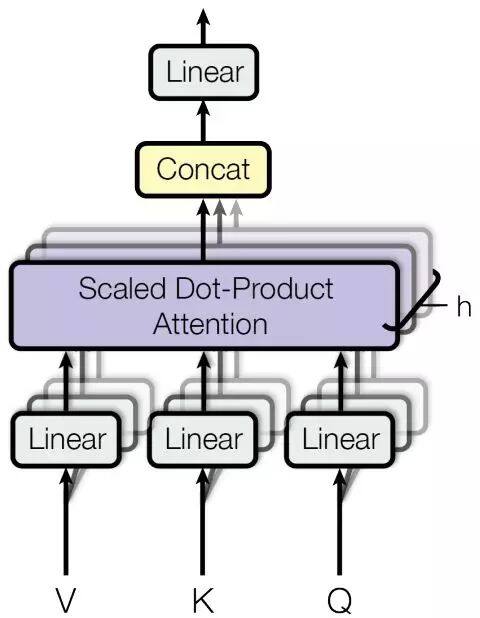
但是 RNN 及其优化变种,因为都要按时序输入,都存在编码效率低下的问题。Transformer 这种基于 self-attention 机制的强大特征提取器应运而生。《Attention Is All You Need》提出了 Transformer,它完全去除了编码步中的循环和卷积,仅依赖注意力机制来捕捉输入和输出之间的全局关系。因此,整个架构更加并行化,在翻译、解析等任务上训练得到积极结果所需的时间也更少。
NLP 中的预训练模型
训练得到的词向量表征的词语之间的信息其实有限。词向量一个难以解决的问题就是多义词的问题,例如“bank”在英文中有“河岸”和“银行”两种完全不同意思,但是在词向量中确实相同的向量来表征,这显然不合理。
2017 年,为了解决这个问题,ELMO 模型在“Deep contextualized word representation”被提出。
ELMO 的本质思想是:用事先训练好的语言模型学好一个单词的 Word Embedding,此时多义词无法区分,不过这没关系。在实际使用 Word Embedding 的时候,单词特定的上下文就可以知道,这个时候模型可以根据上下文单词的语义去调整单词的 Word Embedding 表示,这样经过调整后的 Word Embedding 更能表达在这个上下文中的具体含义,自然也就能克服多义词的问题。
从 ELMO 开始,这种先预训练,在实际应用时再 fine-Tune 的模式就开始流行起来了。我们再看 ELMO,通过双向语言模型,能够学到较丰富的语义信息。但其用的是 LSTM 作为特征抽取器,在特征抽取能力上较弱。
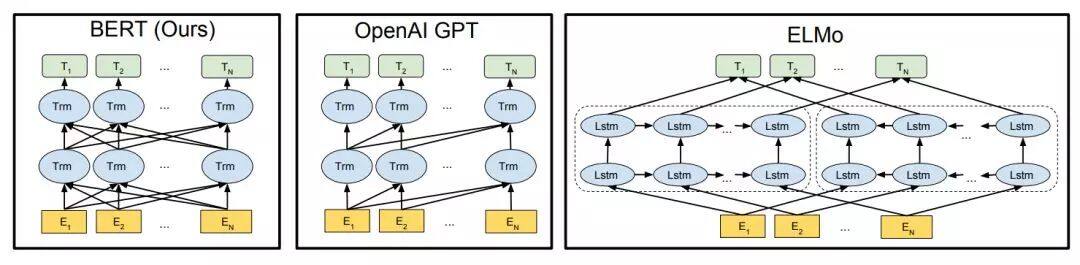
2018 年,Generative Pre-Training(GPT)采用单向语言模型,用 Transformer 作为特征抽取器,取得了非常不错的效果,但由于主创人员营销能力欠佳,并没有像下面这一个主角一样,在 NLP 领域掀起滔天巨浪。
2018 年 10 月,谷歌推出 BERT(Bidirectional Encoder Representation from Transformers)模型,刷新了几乎所有 NLP 任务的榜单,一时风头无两。仔细看 BERT 的实现,其与 GPT 的主要差别在于,BERT 用的“双向语言模型”,它通过 MASK 掉预料中的部分词再重建的过程来学习预料中词语序列中的语义表示信息,同样采用 Transformer 作为特征抽取器。BERT 的出现,因其效果太好,几乎让其他所有的 NLP 工作都黯然失色。
2019 年 2 月 openAI 用更大的模型,规模更大质量更好的数据推出了 GPT2.0,其语言生成能力令人惊叹。
目前来看,出彩的工作都是基于 BERT 和 GPT 的改进工作。在 2019 年 6 月,XLNet: Generalized Autoregressive Pretraining for Language Understanding 诞生,其基于 BERT 和 GPT 等两类预训练模型来进行改进,分别吸取了两类模型的长处,获得的很好的效果。
需要注意的是,所有的预训练模型都是无监督的,这意味着,模型的数据来源是廉价而且数量巨大的。因为 XLNET 在训练时一直是 under-fitting 的,因此即使是通过增加数据量,都还能提升 NLP 预训练模型的效果。这无疑是振奋人心的。
总结
以上大体上介绍了深度学习在自然语言处理领域的一些标志性进展。可预见的是,现阶段是 NLP 最好的时代,后续一段时间内,会有更多更好的模型出现,不断刷新各个任务的"state of the art"。
原文链接
https://mp.weixin.qq.com/s/1z5RCYyEiHRbaERaXvgwQw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论