

本文介绍了高效保证强化学习过程中安全性的一种方法,将强化学习与控制屏障函数结合起来,从而求得安全的控制输入。
强化学习
强化学习(RL)是机器学习的一个子领域,代理通过与环境交互来学习,观察这些交互的结果并相应地获得奖励(正面或负面)。 这种学习方式模仿了我们人类学习的基本方式。
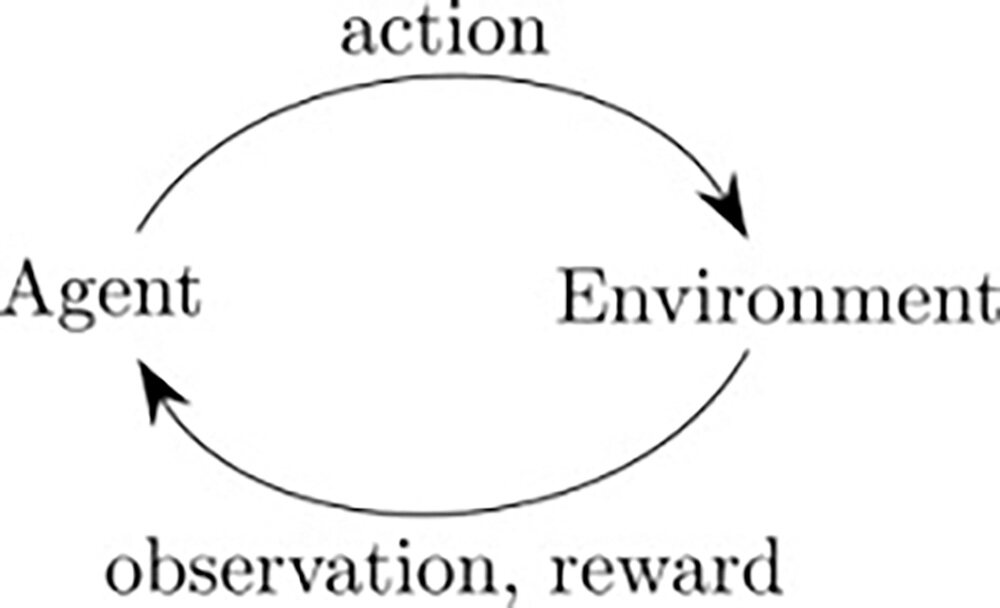
随着我们朝着通用人工智能(AGI)的方向发展,设计一个可以解决多个任务(即对图像进行分类,玩游戏等)的系统确实具有挑战性。当前的机器学习技术范围,无论是有监督的学习还是无监督的学习,都擅长随时处理一项任务,同时这也就限制了 AI 实现通用性的范围。
为了实现 AGI,RL 的目标是使代理执行许多不同类型的任务,而不是只专注于一项任务,这可以通过多任务学习和记忆学习来实现。
我们已经看到了 Google Deep Mind 在多任务学习方面的最新工作,在该工作中,代理可以学习识别数字并玩 Atari。但是,在扩展流程时,这确实是一项非常具有挑战性的任务,因为学习任务需要大量的训练时间和大量的迭代。
另一个挑战来自代理对环境的感知方式。在许多现实世界的任务中,代理没有观察整个环境的范围。这种局部观察使代理人不仅从当前的观察结果,而且从过去的观察结果中采取最佳行动。因此,记住过去的状态并对当前的观察采取最佳行动是 RL 成功解决现实问题的关键。
RL 代理总是从探索和开发中学习。RL 是一种基于反复试验的连续学习,代理试图在状态上应用不同的动作组合来获得最高的累积奖励。在现实世界中,探索几乎是不可能的。让我们考虑一个示例,在该示例中您希望使机器人学会在复杂的环境中导航以避免碰撞。随着机器人在环境中四处学习,它将探索新的状态并采取不同的动作进行导航。但是,在现实世界中采取最佳行动并不可行,因为在现实世界中,环境动态变化非常频繁,对于机器人来学习的代价是非常高昂的。
因此,为避免上述问题,在 RL 代理上应用了其他各种机制来使其学习。很少有人尝试在机器人上尝试通过模仿来模仿期望的行为来进行学习,通过演示进行学习以在模拟中学习环境。但是,这种学习变得非常针对环境。
在过去几年强化学习算法在模拟应用之外取得了很有限的成功,其中一个主要原因就是在学习过程中缺乏安全保证。
考虑由元组(S,A,f,g,d,r,ρ0,γ)定义的带有控制仿射,确定性动力学(处理机器人系统时的一个很好的假设)的无限水平马尔可夫(MDP)决策过程。 S 是一组状态,A 是一组动作,f:S→S 是名义上的未激励动力学,g:S→R^n,m 是名义上的激励动力学,d:S→S 是未知的系统动力学。 系统的时间演化由下式给出:
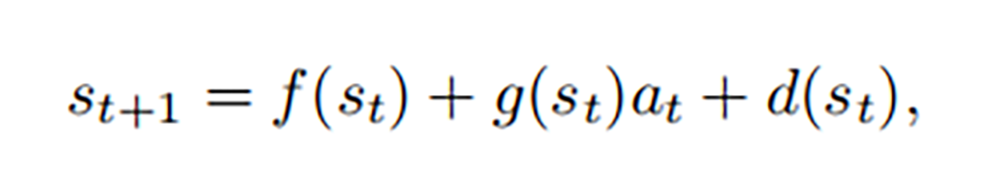
控制屏障函数(CBF)
考虑由连续微分函数 h : R^n -> n 定义的超水平集(安全集合)
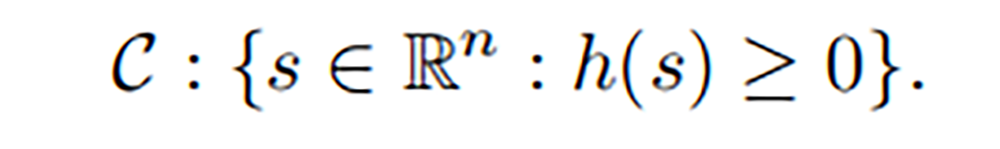
为了在学习过程中保持安全,系统状态必须始终保持在安全集 C 内(即,集合 C 为正向不变) 。 例如,将操纵者保持在给定的工作空间内,或确保四轴飞行器避免障碍物。 本质上,学习算法应仅在集合 C 中学习/探索。
其中 h 函数就是控制屏障函数(control barrier funcations),C 就是安全集合。
通过控制屏障函数来补偿强化学习
通过控制屏障泛函的概念,我们很容易就发现,如果我们针对 MDP 采用 CBF 方法,我们就能得到满足安全要求的控制输入 u,正如下图所示:
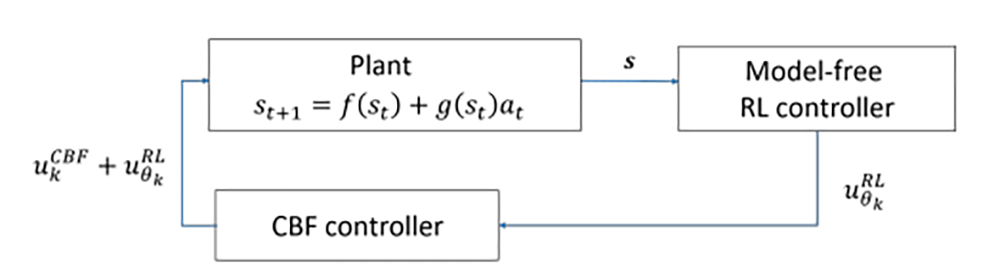
无模型的 RL 控制器 u_RL 提出了一种试图优化长期奖励的控制措施,但可能并不安全。 在部署 RL 控制器 u_RL 之前,CBF 控制器 u_CBF 会过滤建议的控制措施,并提供所需的最小控制干预措施,以确保整个控制器 u3 将系统状态保持在安全范围内。本质上,CBF 控制器 u_CBF 将 RL 控制器 u_RL“投影”到安全策略集中。 在自动驾驶汽车的情况下,无论 RL 控制器建议采取何种行动,此行动都可能会在附近的汽车之间保持安全距离。
取决于 RL 控制的 CBF 控制器 u_CBF 由以下二次规划(QP)定义,可以在每个时间步上有效地对其进行求解:
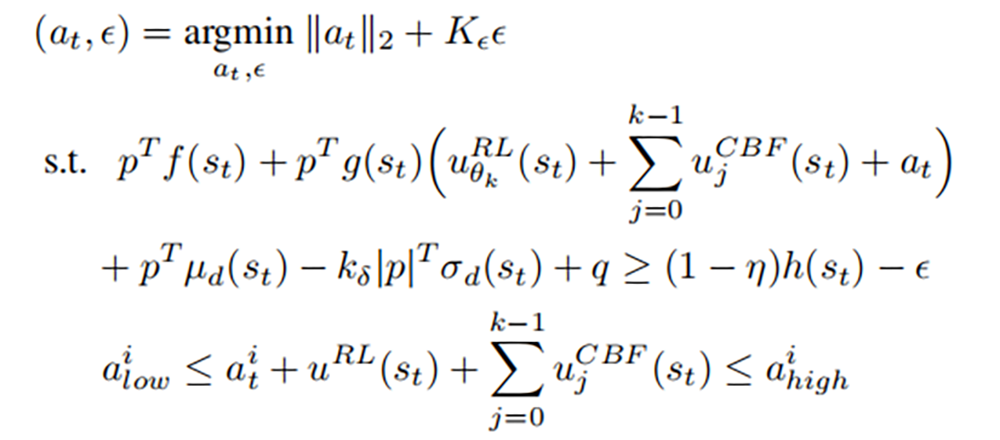
直观地,RL 控制器提供了“前馈控制”,而 CBF 控制器则补偿了使安全设置向前不变所必需的最小控制。 如果不存在这样的控制(例如由于扭矩约束),则 CBF 控制器将提供使状态尽可能接近安全设定的控制。
小结
在无模型的 RL 框架中甚至添加了粗略的模型信息和 CBF,就能使我们能够在确保端到端安全的同时改善对无模型学习算法的探索。这一方法可以高效的保证强化学习过程中的安全性。
作者介绍:
刘文有,研究生在读,主要从事控制器相关理论与人工智能深度强化学习的结合方面的相关研究。

InfoQ编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论