

本文整理自 2018 年 Archsummit 北京站蚂蚁金服 OceanBase 团队高级技术专家隗华(花名:风羿)的演讲,本文将带读者深入了解 OceanBase 应对业务挑战时在架构上的演进和思考。

写在前面
OceanBase 自 2010 年开始立项,到现在已经走过了大约八年多的时间。这八年风风雨雨,几度生死。我们一直秉承着这样一个理念:产品和技术最终是为了解决业务的实际问题,帮助业务持续成长而存在的。
关于 OceanBase

关于 OceanBase 数据库,我会从以下四个断言开始介绍:
1.100% 自主知识产权的国产数据库:这意味着 OceanBase 数据库不基于任何开源数据库,比如 MySQL。我们的百万级的代码都是整个团队一行一行地积累起来的,所以 OceanBase 完全是一个拥有自主知识产权的数据库;
2.商业数据库:OceanBase 在早期 0.4 版本的时候曾经开源过,从 0.5 版本后,OceanBase 开始在支付宝的核心链路上线以后,整个团队调整了产品的整体定位,逐渐向商业数据库的方向发展。在这样一个大背景下,在可预期的未来很长的一段时间里,OceanBase 还会是一个闭源的数据库;
3.通用关系型数据库:OceanBase 是满足 ACID 特性的通用关系型数据库;
4.原生分布式数据库:OceanBase 也可以被归到 NewSQL 数据库里,OceanBase 一直坚持的一点就是:在数据库层能够解决的事就全都放在数据库里去解决,所以我们支持两阶段提交协议、全局索引和全局一致性等。
OceanBase 项目从 2010 年开始启动,到现在为止走过了八年。2014 年,OceanBase 在内部开始承接支付宝的核心业务。截止到今天,几乎所有的支付宝业务,不管是核心链路和非核心链路,都是跑在 OceanBase 上。2017 年底,OceanBase 开始走向外部,正式对外商用,到现在已经服务了数十个客户,持续帮助客户打造互联网金融的核心。
OceanBase 目前已经发布到了 2.0 版本,而且这个版本已经经历了 2018 年双 11 的洗礼,后面我们也会把 OceanBase 2.0 版本推向外部,来帮助更多的外部客户解决他们的实际问题。
OceanBase 架构介绍
OceanBase 本身是一个分布式的集群,通常情况下是多副本的存储。所以一般会分为三个子集群,每一个子集群叫做一个 zone。一个 zone 里有多个节点和服务器组成,我们管它叫 OBServer。对于每一个分区,在整个集群内它都有三个副本。
Paxos 协议介绍
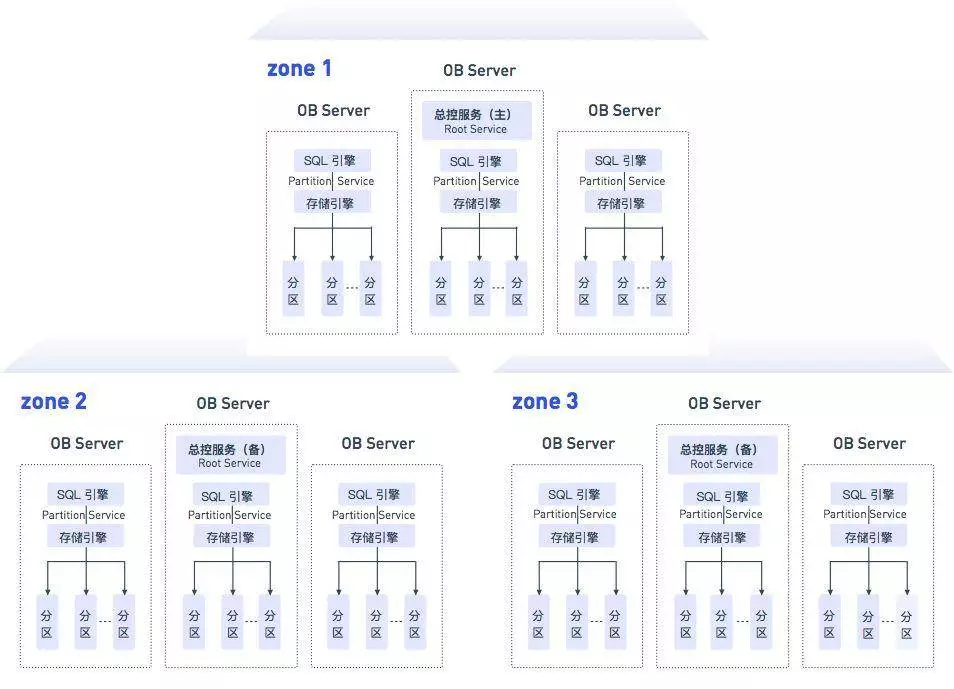
另外值得一提的是,OceanBase 支持的 Paxos 协议。Paxos 协议本身相对复杂,但是其哲学思想是非常简单的,就是一个多数派投票协议。比如一个事情,A 认为成功,B 认为成功 ,C 认为不成功,根据多数派协议认定这个事情最后是成功的。那么具体到这里,这三个分区的一主两备,就形成了 Paxos 协议的成员组。
微观来看,这是实现数据库高可用和强一致性的一个基础。简单的描述一下:
每个分区在集群里的数据实际有三份,即三副本。三副本之间的数据同步靠 Leader 副本的事务日志同步到其他 Follower 副本中。Paxos 协议会保障这个事务日志传输的可靠性(事务日志在一半以上的成员会落盘,剩余成员最终也会落盘),同时还有以分区为粒度的选举机制,保障 Leader 副本不可用的时候,能快速从现有两个 Follower 副本里选举出新的 Leader 副本,并且数据绝对不丢。
那么通过这种方式,在任何一个时间点数据在三个 zone 当中,必然是有两份完全一致的数据,而且是强一致的,这个是 OceanBase 实现一致性的基础。
同时通过这种方式,也可以实现数据库的高可用。现在有三个副本,其中有两个是完整数据的。如果宕掉一个副本的话,还剩下两个,那么其实对整个集群对外服务是完全不受任何影响的。

这里就体现了故障切换时的两个重要指标:RPO=0,RTO<30s。
OBProxy 介绍
OceanBase 是一个集群数据库,应用又该如何访问这个数据库?
每一个 OBServer 都提供直连的功能,那么对于应用来说,当然第一个做法可以直接连里面任意的一个 OBServer,但连了之后有相当大的概率会面对你所连的 OBServer 上并没有要访问的数据。但是 OBServer 本身提供这样一种能力:可以通过解析 SQL 语句,跟内部的位置信息进行比对,然后知道你要访问的数据在哪个 OBServer 之上,然后再做一次转发。
但是这样就存在一个问题:首先你要做一个 SQL 的解析,SQL 解析本身会耗去一段时间;然后解析完了之后,如果发现数据没在这里的话,你还要再做一次转发,这个转发又会耗去一部分时间,那么对于 SQL 的响应时间是一个很大的挑战。
所以在这个基础上我们做了一款产品叫做 OBProxy,OBProxy 简单理解就是一个轻量级的 SQL 解析器。
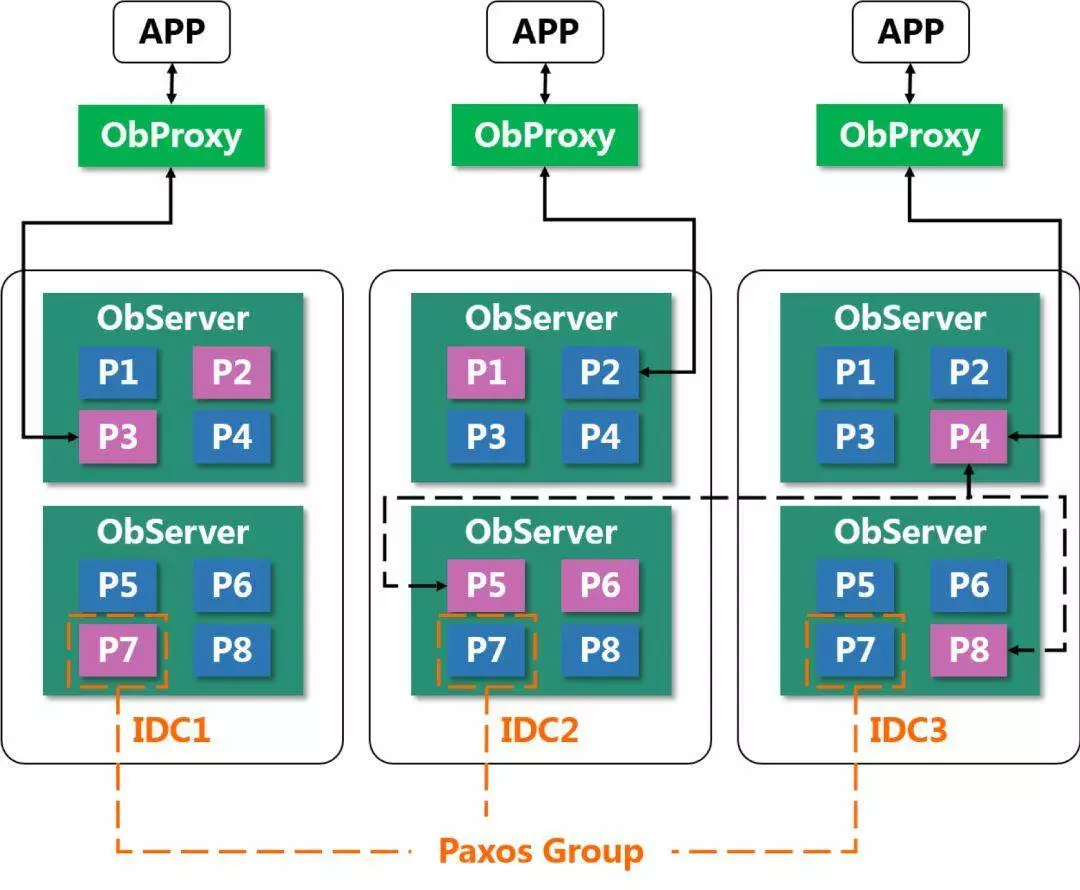
那么当 SQL 来的时候,通过解析器可以做一个轻量的解析,大体看一下数据的位置。每一个 OBProxy 会维护一个本地的 location cache,然后做一个比对,知道数据在哪,然后直接做转发,把它发到对应的 OBServer 节点上去执行。执行完之后,结果通过 OBProxy 再返回给这个应用。
存储引擎介绍
那么最后简单给大家介绍一下 OceanBase 的存储引擎,基于 LSM-Tree 的架构。增删改的数据其实都是在内存里。OceanBase 跟传统数据库不太一样的地方,就是传统数据库中当一个数据修改来的时候,要实时去修改存储,但是在这种架构下,增删改的数据就是增量数据,它始终是放在内存里的。
那么这个架构带来的一个好处就是增删改相对来说会比较快。这个是肯定的,因为全部都在内存当中进行。
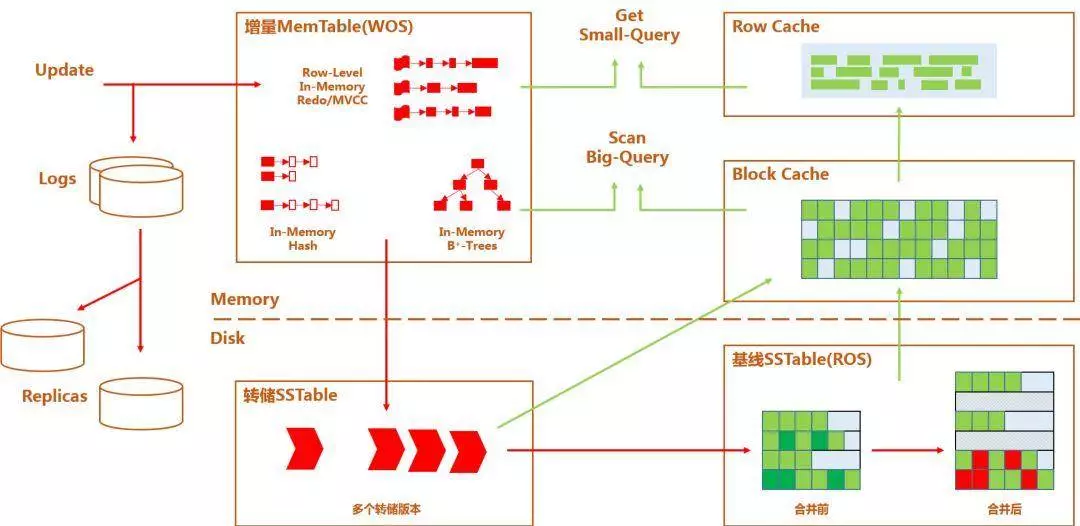
但是有一个架构上的缺点。在读的时候,可能你的数据在内存和磁盘上同时都有。那么我们的做法是说我们接受这个事实,然后在里面做一些优化。
如上图所示的数据库中经常提到的 “Row Cache”、“Block Cache” 还有 “Bloom Filter Cache” 等,热数据会缓存起来,大部分单行操作只需要一次缓存查找,没有额外开销。那么相对来说性能能够达到一个比较好的状态。
我们线上的机器一般内存都比较大,一般都在 512G,这些数据是不会往磁盘里去刷。当然,内存当中的增量数据到达一定的条件后,即便有 512G 也总会爆的,最后总得把它写回到磁盘上来,我们管这个过程叫合并。那么合并的过程会产生大量的 IO,其实对性能会有一定的影响,影响可能在 10% 左右。
当然这个合并其实也会带来一些额外的好处,比如说数据压缩。一般来说数据库在做数据压缩都是及时的;但是在 OceanBase 里,可以选择在合并的时候做一个集中的压缩。
现在大家知道,其实数据库我们广泛的使用 SSD,随机读写型的 SSD 相当的贵。但是在 OceanBase 里,因为我们有这样的一个操作:写操作都在内存里进行,写磁盘都是在合并的时候,所以能够实现顺序的写,最终使得硬件的成本大幅度的降低。
OceanBase 架构演进
OceanBase 是从 2017 年的时候开始走向外部,在这中间经历过很多艰难和挑战,可能是原来在淘宝和支付宝体系中根本不可能碰到的一些挑战。比如:
如何在业务高峰平滑扩容,高峰后如何缩容,甚至对业务无感知;
如何去 O,如何保证风险可控地去 O;
如何解决多活和异地容灾;
如何备份分布式数据库,如何恢复到一个全局一致的时间点;
如何规避分布式数据库的种种限制,如分区键和主键的绑定关系;
如何合理部署分布式数据库,与现有云平台如何整合;
如何解决业务数据量膨胀之后的冷热数据问题。
通过副本类型变更支持弹性大促
首先介绍一下 OceanBase 的副本类型:

支付宝的弹性大促
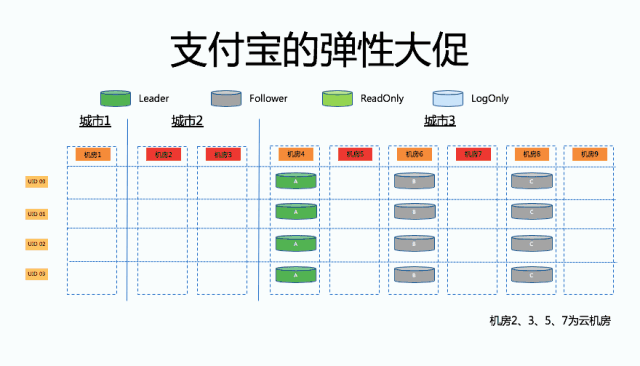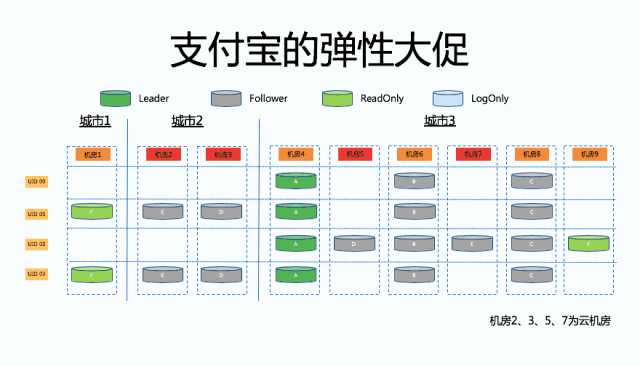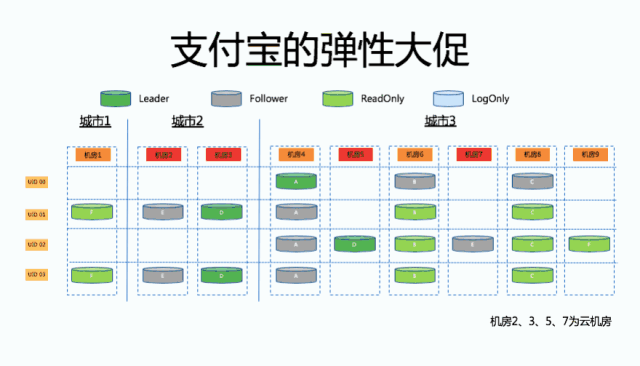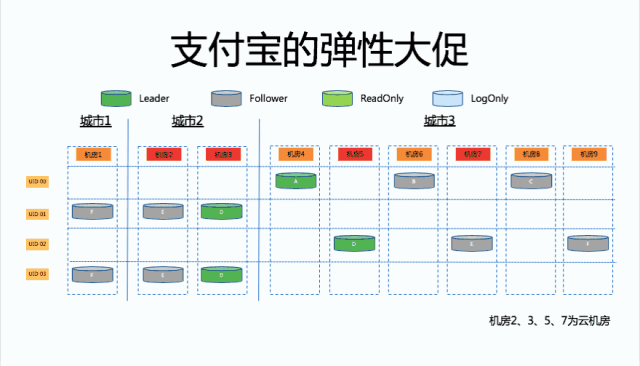
上图就是支付宝弹性大促的简单示意图。在支付宝,我们会根据 UserID 做单元化。那么对于 OceanBase 来说,其实就是上图可以看见的四个 UserID 的数据,都是由机房 4、机房 6 和机房 8 组成的 OB 集群来提供的数据能力。上层的应用肯定会有一些租借的机房,就是如上图所示的 2、3、5、7 这些所谓的云机房。那当应用发布过去以后,我们要做的就是把 OB 相关的数据也挪到相应的云机房去,最终实现从原来 1 个机房服务 4 个 UserID 到最终每个机房只服务 1 个 UserID,达到一个扩容的效果。
那么具体是怎么做的?
第一步,在异地的机房里部署三个只读副本,它们不参与 Paxos 协议的投票,但是会不断地从主从副本里把数据传过去。只读副本本质上对集群本身是完全没有影响的,包括应用也是完全无感知的。
接下来要做的一个事情就是把其中的两个只读副本 D 和 E 把它通过副本变更变成一个从副本 Follower。那么大家可以看到现在的 OB 集群,它是由一个三副本的状态变成了五副本状态。
那么同样的,对应用来说,它访问集群是在机房 4,所以是完全没有感知的。然后接下来要做的一个事情,就是我们又把五副本降为三副本,把原来的两个同步变成了只读副本。
接下来一步,这一步其实对业务相对来说是敏感的。原来的机房 4 的 A 做了一个切除的操作,也就是把原来的 Leader 副本变成了 Follower 副本,然后把它切到了机房 3。那么这个时候我们形成了新的三副本的集群。
再往后走,我们又做了一个副本变更的操作,把原来的从副本 A 变成了一个只读副本,然后把原来的最后一个只读副本 F 变成了一个从副本。
那么大家可以看到这个时候,UserID 1 服务的数据库集群已经不在原来的机房 4 了,最后我们把这些只读副本全部下掉了,最后就完成了整个支持弹性大促的过程。那么大促完之后,我们基本上也是一个反向操作,可以把它恢复成原状。
通过热备库解决异地容灾
刚才提到,阿里内部硬件条件是比较好的。当我们在走向外部的时候,突然发现很多客户其实是没有三机房,甚至它的网络条件也很差。
可能会面临最明显的两个问题:
1)如果只有两机房如何部署三副本?一般来说一个机房部署两个副本,一个机房部署一个副本。这个时候有一个问题:如果放两个副本的机房宕掉了,你就只剩下放一个副本的机房。那就意味着丢数据。
2)这里基于一个硬件不稳定的假设,当你只剩下一个副本的时候,我们可以利用一些手段重新启动,但是当再一次发生硬件的故障的时候,那么这个数据就会完全的丢失。
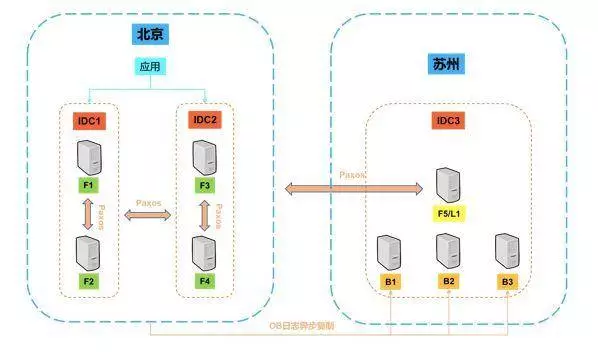
所以我们在这个基础上,做了这么一个方案:就是在两个机房同时也是两座城市,分别放上,如上图所示在北京放上 4 个副本,在苏州放 1 个副本,然后形成一个 OB 的业务集群。那么平时客户的应用在北京的集群这边进行访问。然后在苏州,我们其实还有三个备份副本。
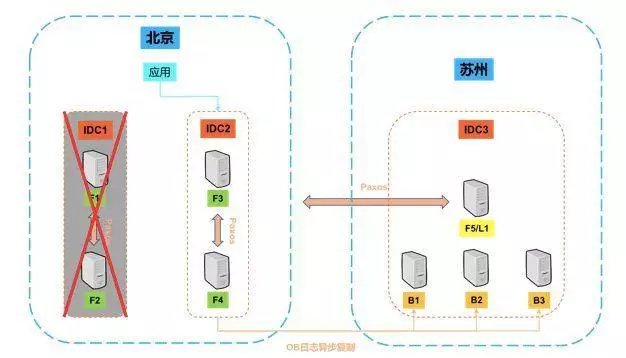
如果北京的 1 个机房发生灾难,那么五个副本中还剩下三个,集群还是可以正常工作。
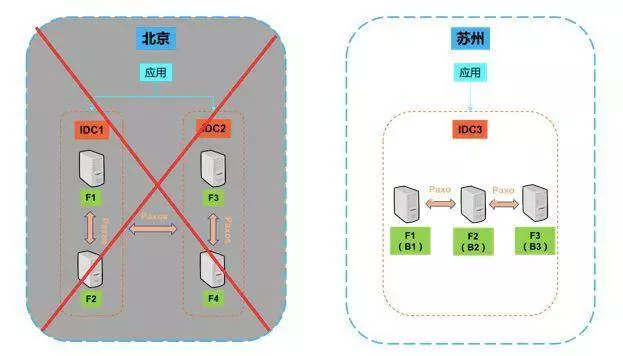
如果北京的两个机房都发生灾难,垮掉了,那么我们会做一个接管的操作,把这三个备份副本升级成一个全功能副本构成一个新的集群,然后为业务提供服务。
OMS 迁移服务:向分布式架构升级的直接路径
其实我们原来积累了很多去 O 的经验,但是在淘宝和支付宝,去 O 很多时候是通过应用层的改造去实现。对于客户来说,这件事就变得很复杂,不少客户应用层的代码不够完善。
只能完全以 Oracle 的这种方式去解决他的问题,所以我们打造了这款一站式数据迁移解决方案—— OceanBase 迁移服务(简称 OMS ),从评估兼容性,到验证 SQL,最后等到所有的校验都完成以后可以一键完成切换。
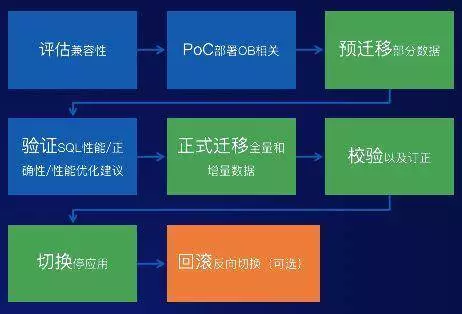
如果 Oracle、MySQL 等其他的一些数据库往 OB 上迁,那么最后的关键一步是什么呢?
最关键的一点,就是 OMS 有随时回滚的能力,而且回滚是无损的。比如说从 Oracle 把数据迁到 OB,在切应用的那一瞬间,其实原来的 Oracle 在继续跑,然后把新的数据同步的链路做一个反向——从 OB 到 Oracle,也就是说新的系统如果跑在 OB 上,新产生的数据它会同样回到原来的 Oracle 数据库中去。
通过 OMS 就可以轻松完成从传统商业数据库到分布式数据库的完整迁移,这是企业稳妥创新的基石。
下一代 OceanBase
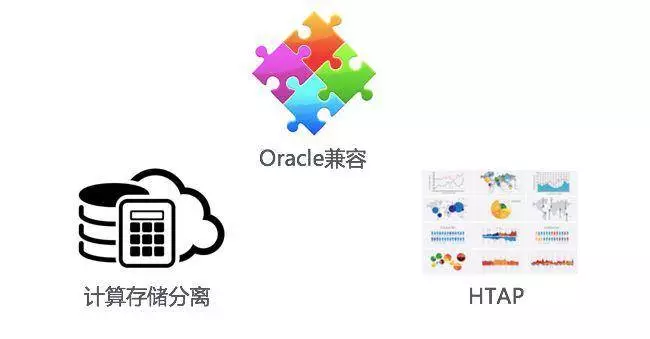
最后简单展望一下下一代的 OceanBase,其实所谓的下一代也就是可能一年半之后就能达到的一个状态。
第一点是 Oracle 兼容性,我们始终致力于 Oracle 兼容性方面的工作。那么现在我们的产品能达到 20~30% 的 Oracle 兼容性,当然这其中包含有几个层次的东西。首先最简单的语法兼容,那么第二个是功能和性能的兼容,第三个由于 OceanBase 本身是一个分布式数据库,Oracle 它是一个集中式数据库,那么对于客户来说,还要屏蔽掉架构上的差异,让客户无感知。大体上兼容可能分为这么几个层次,那么我们会逐步深入往下做。
第二点是计算存储分离,我前面其实也讲过,OceanBase 是一个计算和存储融合的这么一个架构。这个架构它相对来说比较简单,但是存在一个问题,就是你的业务是计算先达到瓶颈的,还是存储先达到瓶颈的。这两种情况往往是不一样的,往往时间点也是不一样的。在架构里就存在一定的浪费。如果说计算不够,也是加一台机器;存储不够,还是加一台机器。所以本身就对成本是一种浪费,所以我们现在致力于更深入做计算和存储的分离。
最后还有一点就是 HTAP。现在的场景更多是 TP 类的场景,也就是联机交易。当然其实我们也支持很复杂的查询,我们在阿里内部也有一些像广告类的偏查询类的业务。我们在持续的打造 AP 的能力,包括资源的 SQL 执行器的一些并行计算框架,力争在不久的将来能够更好的支持混合型的负载。
OceanBase 未来会持续打磨自身,通过不断迭代的产品帮助更多企业、更多业务稳妥创新,持续成长。
本文转载自公众号蚂蚁金服科技(ID:Ant-Techfin)。
原文链接:
https://mp.weixin.qq.com/s/JBl8orNpPwx24L0LZ_xVxQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论