
简介
业界目前已经在以下这一点上达成了强烈的共识:API 的设计应该是按照前端到后端的次序进行的,将重点放在开发者对 API 的使用上。在某个发展兴旺的商业体中,通常会存在着许多互相竞争的产品与 API 的实现,而易于使用、并且设计良好的 API 在吸引与保留开发者这一点更有优势。此外,新的工具不断涌现,它们不仅能够帮助开发者按照迭代方式设计 API,而且能够帮助开发者学习与使用这些 API。
API 设计中的关键因素在于“人”,这意味着API 设计工具与文档格式必须便于人的读写,这一段时期以来的API 设计标准都在强调“以人为本”。 API Blueprint 在这一领域是较早使用 Markdown 作为格式的产品,而进行 API 设计的广大开发者与商业分析人士都熟悉这种格式。
去年晚些时候,Mulesoft 发布了自己的 RESTful API 建模语言——RAML。这门语言本身只是一种具有专利的第三方语言,但由于它的一系列特色,使得广大的 API 社区都对它产生了浓厚兴趣:
- RAML 本身是开源的,并且它内置了一系列工具和对普通语言的解析器。它的开发始终处于一个 API 的指导委员会和一些用户体验从业人员的高度关注之下,并且围绕着 RAML 所开发的第三方工具也在形成自己的生态系统。
- Mulesoft 首先尝试了 Swagger 这种文档格式,但随即意识到这种格式标准更适用于为一个现有的 API 进行文档化,而不适用于从头开始设计的新 API。而它们所需的是一种支持简洁的、专注于人类语言的 API 设计方式的格式,RAML 正满足了这一需求。
- API 的描述通常是很冗余并且容易重复的,这有碍于它的结构、可理解性和对它的使用。RAML 引入了一些新的语言特性,支持结构化的文件、继承,以及对横切关注点的处理。这些特性正是本文所关注的要点。
RAML 本身不会带来良好的 API 设计,这门语言及其工具也没有任何内置的“最佳实践”。正如 MuleSoft 的 CTO Uri Sarid 所说,RAML 的目标是:“以一种开放的、简单且简洁的规格对 API 进行描述,它能够捕捉到 API 的结构,并鼓励基于模式的设计和重用,它将有助于释放 API 的商业潜力。”
RAML 并不负责 API 的实现,它仅仅是一门规格说明语言。现在仅有为数不多的一些开源工具能够实现由 RAML 语言所描述的 API。 APIKit 能够将一个 RAML 规格转变为 Mule ESB 流,如果你的运行时平台使用的是 Mule ESB,那这一工具能起到些作用。 JAX-RS Codegen 的使用更加广泛,因为它能够将一个 RAML 规格转变为 JAX-RS Java 代码。毫无疑问,对其它语言和平台的支持,将在很大程度上决定 RAML 最终是否能够取得成功。
本文的目的是以一个示例为你展示如何使用 RAML 设计一个简单的,但又实用的 API,并展现 RAML 的一些选择性。而不是作为与其它 API 设计或描述格式进行比较的依据,例如 API Blueprint 、 IO Docs 或 Swagger 。它令人振奋的地方在于,我们现在设计的选择上有了一种可行并且有竞争力的生态系统,它有希望建立起 RESTful API 设计与规格的共识。
API 示例的需求
我们将要设计的这个示例 API 的功能是将事件日志记录到一个流中,以支持在线分析与报表业务。使用日志文件保存正在运行的软件的状态与进度,这种模式大概与计算机本身历史一样长。但随着系统变得越来越分布式,负载也被分到大量系统中(或许只是短暂的发生),使用文件来管理及分析日志成为了一种不可能的任务。目前流行的设计模式是将日志看作为事件流。这样一来,这个 Eventlog API 就包括了以下一些基本需求:
- 允许第三方应用将某个事件写入某个命名的事件流当中。
- 事件本身带有少量的必要属性,同时还有可扩展的“上下文”属性。
- 支持获取一个事件流。
- 获取某个时间段内的一系列事件。
- 获取一个分页的事件列表。
- 支持对所获取的事件数量加以限制,合理的默认值设为 100。
- 支持通过 Id 获取到某个事件。
- 事件是不可变的,既不能被删除、也不能被修改。
- 该 API 的读取是公开的,但写入操作必须由一个 OAuth 2.0 安全性 schema 进行保护。
现在让我们开始对 RAML 的探索,看看如何使用它描述一个满足以上需求的 API。
在本文中,我们将使用 Anypoint API 设计器编写 RAML。这个设计器允许我们在设计过程中查看可交互的文档,并且能够对 API 进行模拟(mock)。我们将从一个简单的规格开始,随后再使用 RAML 中更高级的特性,以使我们的规格更加 DRY。REST API 的规格有时重复性很高,包含大量的样板代码,而且对于非常接近的资源信息也不得不重复编写它们的规格。RAML 提供的特性能够帮助你避免或是管理这种重复性,包括资源类型(resourceType)、trait 和文件中包含的指令。我们会在过程中逐步讲解这些特性,在示例的最后将讲述安全性规格。
一个简单的 RAML API
你可以在 raml.org 网站上下载到 RAML 的文档与入门指南,包括完整的 RAML 规格说明。在这个示例的开发中,我使用了 Anypoint API 设计器,它包含了一个在线的 RAML 编辑器。
定义资源
首先,这个事件日志 API 包含了两种主要的资源:一个事件集合,我们将其称为一个事件流;以及每个独立的事件对象自身。对于事件流来说,我们需要一个 POST 方法,在事件流中创建一个新的事件,还需要一个 GET 方法以返回流中的事件。可以通过事件流名称和事件 Id 获取每个独立的事件。下面这段代码片段展示了这个规格的相应 RAML 代码:
#%RAML 0.8 # Basic starter raml with two resources and corresponding methods. title: Eventlog API version: 1.0 baseUri: http://eventlog.example.org/{version} /streams/{streamName}: displayName: A Named Stream description: A stream is a collection of related events. A Named Stream has been defined by the user to contain a list of related events. Named Streams are created by POSTing an event to a Named Stream. get: description: Get a list of events in this stream. post: description: Create a new event in this stream. /streams/{streamName}/{eventId}: get: description: Get a particular event by its Id.
baseUri 属性包括域名和一个版本号,大括号中所指定的是 Uri 参数。我们要处理的资料集合是基于“/stream/{streamName}”这个地址的一个相对路径,对这个路径调用 GET 或 POST http 方法,会对这个集合进行相应的操作。而事件资源是基于根路径“/streams/{streamName}/{eventId}”的一个相对路径,对应一个单独的 GET 方法。RAML 允许我们为这些资源和方法提供一个便于人类阅读的描述信息。API 设计器会将这个规格说明以一种可交互的文档形式进行展现,如图 1 所示:
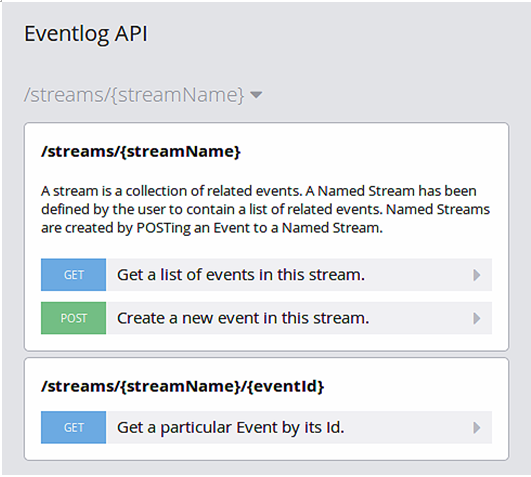
这个 API 设计器允许我们使用一个模拟的服务来测试这个 API。作为一个简单的例子,我们可以通过指定事件流名称,并单击“POST”按钮以创建一个事件。在默认情况下,你会得到一个 HTTP 200 响应。
请求、响应、Schema 和示例
默认的 POST 方法并不足以完全表现出我们的 API 所必需的行为与结构。我们必须告知开发者事件对象的对应数据结构,以及在创建时应发生的行为。RAML 提供的两个补充选项能够描述这些信息:即 schema 和示例。
虽然许多的新的公共 API 倾向于使用 JSON 表达方式,但也有很大一部分 API 会同时提供 XML,或仅仅提供 XML 格式。因此 RAML 可以以一种可编程的方式将规格说明转化为 XML 或 JSON schema。可以选择在一个资源描述文件的内部或 RAML 头文件的内部指定 schema,也可以通过一个外部文件或 url 进行指定。由于 schema 内容可能会非常庞大,因此通常来说将它定义在外部是一种良好的实践,因为内联的 schema 会干扰对使用者对整个 RAML 规格的理解。
#%RAML 0.8 title: Eventlog API version: 1.0 baseUri: http://eventlog.example.org/{version} schemas: - eventJson: !include eventSchema.json eventListJson: !include eventlistSchema.json
在该示例中定义了一个由外部文件引用的 JSON schema 描述,RAML 可以包含本地文件或基于 HTTP 的资源。我们选择的方式是通过 API 设计器指定了几个本地文件。如果这时选择了基于 HTTP 的资源,会产生了一个跨站脚本错误,因为脚本编辑器不能够引用来自其它域名的资源。在文件的最上方是一个 schema 标签,可以在之后的资源定义中引用这个标签名称。
有许多 API 选择用一个示例,而不是 schema 来表述资源信息,因此 RAML 也允许你在 schema 中提供一个示例。下面的代码片段就包含了这样一个示例标签,所谓示例就是一段 JSON 或 XML 代码,它表述了该资源体的内容。
当开发者向事件流中 POST 了一个新事件后,他们应当收到一个信息,表示该事件资源已经被创建,并且收到这个新事件的 url(其中包含了 Id 信息)。服务端将返回一个 HTTP 201 响应(已创建),并且在 HTTP 头中包含一个属性“location”,指向新资源的 url。下面的示例为我们展示了在向事件流中 POST 一个新事件时,应该怎样指定请求与响应信息。
/streams/{streamName}: displayName: A Named Stream description: A stream is a collection of related events. A Named Stream has been defined by the user to contain a list of related events. Named Streams are created by POSTing an event to a Named Stream. post: description: Create a new event in this stream. body: application/json: example: | { "name": "Temperature Measurement", "source": "Thermometer", "sourceTime": "2014-01-01T16:56:54+11:00", "entityRef": "http://example.org/thermometers/99981", "context": { "value": "37.7", "units": "Celsius" } } responses: 201: description: A new event was created. headers: location: description: "Relative URL of the created event." type: string required: true example: /streams/temperature/123456 body: null
这段代码示例的作用是向一个名为“temperature”(天气)的事件流中 POST 一个天气预测事件的 RAML 描述。其中描述了 JSON 对象的结构,并提供了一个示例。事件包含了一系列你所需的属性,例如它的名称(或类型)、来源和时间戳。我们还加入了一个可选的引用对象,它指向某个与该事件相关的信息实体(entity ref),以及一个用来指定事件类型(在这个例子中是指 value 和 units)的上下文数据(context data)。
在响应的规格中,我们详细描述了这个 201 响应的相关信息。当然,规格中或许可以包括 400 或 500 等范围的响应信息,用以表示的发生的问题,不过现在就使用这个默认的设定就可以了。这个 API 的重要之处在于,开发者应该收到一个 201(已创建)响应,并且在它的头信息中应该有一个包含了新创建事件的相对路径的属性。我们还指定了响应体的内容为空。如果开发者需要再次获取这个事件,那他们就可以使用这个相对 url 进行访问。
对该事件集合执行 GET 方法,要么返回一个 404 响应(如果该事件流尚未创建),要么返回一个 200 响应,并在响应体中包含了一个事件数组。请看以下代码:
get: description: Get a list of events in this stream. responses: 404: description: The specified stream could not be found. 200: description: Returns a list of events. body: application/json: example: | [ { "id":"123456", "name": "Temperature Measurement", "source": "Thermometer", "sourceTime": "2014-01-01T16:53:54+11:00", "entityRef": "http://example.org/thermometers/99981", "context": { "value": "37.1", "units": "Celsius" } } { "id":"123457", "name": "Temperature Measurement", "source": "Thermometer", "sourceTime": "2014-01-01T16:54:54+11:00", "entityRef": "http://example.org/thermometers/99981", "context": { "value": "37.3", "units": "Celsius" } } { "id":"123458", "name": "Temperature Measurement", "source": "Thermometer", "sourceTime": "2014-01-01T16:55:54+11:00", "entityRef": "http://example.org/thermometers/99981", "context": { "value": "37.5", "units": "Celsius" } } ]
让这份规格说明变得更加 DRY
尽管我们才刚开始编写这个 API 规格,但它已经显得非常臃肿了。大量的资源,以及它们的方法、参数和示例造成了该规格说明极大的重复性,并且有可能因此产生 bug。但 RAML 提供了一系列特性,它能帮助我们避免这种重复性。
资源类型
对于集合来说,一个 POST 方法会得到一个 201 响应,其中包含了资源的地址;并且一个 GET 方法会返回一个资源列表,这已经成为一种通用的模式了。因此我们可以将这种模式抽象出来,建立一个 resourceType 规格,而其它资源对象都可以从它进行继承。
resourceTypes: - collection: post: responses: 201: headers: location: description: The relative URL of the created resource. type: string required: true example: /streams/temperatures/12345 get:
这种方式极大地简化了事件流资源的描述,它允许我们只需指定事件流中特定的部分就可以了,例如示例中的请求体与响应体。请特别留意在资源定义中的 type 关键字。
/streams/{streamName}: type: collection displayName: A Named Stream description: A stream is a collection of related events. A Named Stream has been defined by the user to contain a list of related events. Named Streams are created by POSTing an Event to a Named Stream. post: description: Create a new event in the stream body: application/json: example: | { "name": "Temperature Measurement", "source": "Therometer", "sourceTime": "2014-01-01T16:56:54+11:00", "entityRef": "http://example.org/thermometers/99981", "context": { "value": "37.7", "units": "Celsius" } } get: description: Get a list of events in the stream. responses: 200: body: application/json: example: | [ { "id":"123456", "name": "Temperature Measurement", ... etc ...
特征(Traits)
在我们当前已实现的 API 规格中,还遗漏了一项重要的特性,即针对各种标准对所请求的事件进行过滤的功能。我们的需求中包括这些内容:根据时间段获取事件、或者获取一个分页的事件列表,对返回的事件数量加以限制,以避免服务 端或客户端的数据量过载。我们可以通过指定 trait 的方式为所有资源实现这一需求:时间段是一个 trait,分页是另一个 trait,而数量限制又是一个 trait。resourceTypes 为资源规格提供了继承的能力,而 trait 则负责处理横切关注点,通常情况下在指定查询参数时会遇到这种问题(但不仅限于这种情况)。
下面一段代码描述了三种 trait:Slidingwindow 指定了两个查询参数,它代表了相对于当前时间的一个时间窗口。Windowstart 则代表了当前时间与该时间窗口开始时间的间隔,通过一个整数与一个单位符号的方式表示。例如:“1h”表示一个小时,“30m”表示三十分钟,而“86164s”则是以秒为单位来表示一整天。Windowsize 是另一种时间间隔(使用相同的表达方式),它表示该时间段的长度。
paginated 这个 trait 表示通用的查询参数,每次都返回一个页大小的查询数据,pagenumber 和 pagesize 参数对应于当前页面和页面大小。
最后,limited trait 指定了一个通用的行数限制,这是为了防止某个缺乏经验的客户端程序试图返回事件流中的所有事件,并影响到整个系统的运作。默认的限制大小是 100,也可以在任意请求中覆盖这个值。
traits: - slidingwindow: description: Query parameters related to retrieving a sliding window of timestamped entities relative to now. queryParameters: windowstart: description: The begining of the sliding window expressed as a time interval from now represented as an integer concatenated with units h (hours), m (minutes), s (seconds) or ms (milliseconds). type: string example: 1h, 30m, 3600s windowsize: description: The end of the sliding window expressed as a time interval from the start as a concatenated integer and unit suffix. type: string example: 10s, 1h, 25m - paginated: pagenumber: description: The page number of the result-set to return. type: integer minimum: 0 pagesize: description: The number of rows in a page request. type: integer maximum: 100 - limited: queryParameters: limit: description: A general limit on the number of rows to return in any request. type: integer default: 100
事件流资源规格通过 is 关键字,以一个 YAML 数组的方式列举所有相应的 trait,并将这些 trait 应用到 GET 方法中:
/streams/{streamName}: type: collection ... etc ... get: is: [ slidingwindow, paginated, limited ]
在应用了 resourceType 和 trait 的改动之后,我们可以在 API 设计器中重新审阅一下这些 API,观察所生成的文档,并利用模拟服务尝试调用 API。图 2 展示了调用的结果,包含了完整的查询参数文档。所生成的文档同时指定了事件流资源的 resourceType 以及与事件流资源的 GET 方法相关的所有 trait。
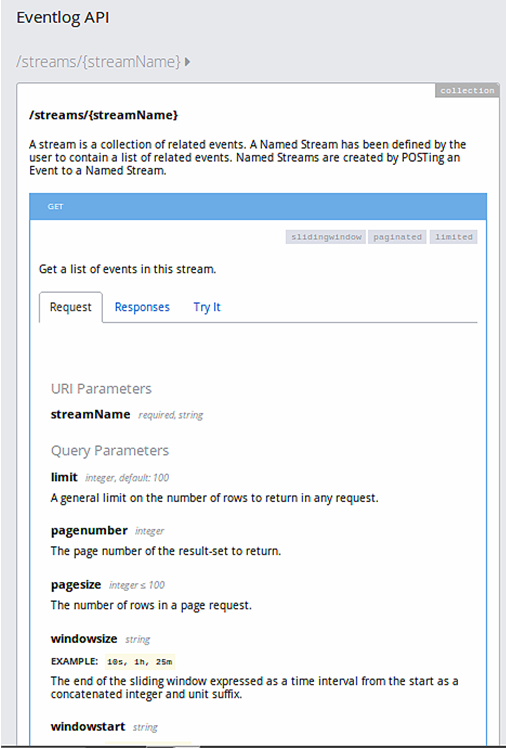
安全性 Schema
对于 API 设计者来说,API 的安全性是最高优先级的任务,并且要不断地兼容各种协议与标准。幸运的是,RAML 为广泛的安全性 schema 提供了支持,包括 OAuth 2.0、OAuth 2.0、基本验证(Basic Authentication)和摘要验证(Digest Authentication),另外还可以应用自定义 schema。所有这些 schema 都必须提供头、查询参数和响应的定义。在这个示例中,我们将使用 OAuth 2.0,但只将其应用到事件的 POST 方法。任何人都可以读取事件流,但只有授权客户才能够 POST 事件。
以下代码描述了一个 OAuth 2.0 安全性 schema,它由一个 HTTP 头字段 Authorizaton 指定,并且只使用客户端凭证授权。 RAML 规格中还描述了各种安全性 schema 的不同使用方式。
securitySchemes: - oauth_2: description: Eventlog uses OAuth2 security scheme only. type: OAuth 2.0 describedBy: headers: Authorization: type: string description: A valid OAuth 2 access token. responses: 401: description: Bad or expired token. 403: description: Bad OAuth request. settings: authorizationUri: http://eventlog.example.org/oauth2/authorize accessTokenUri: http://eventlog.example.org/oauth2/token authorizationGrants: [ credentials ]
oauth_2 安全性 schema 是通过在事件流 POST 方法中指定 securedBy 关键字的方式得以应用的。
/streams/{streamName}: post: securedBy: [ oauth_2 ]
注意,这个 securedBy 关键字接受一个数组,它允许指定将多种安全性 schema 应用到 API 上,或者是应用到单独的资源上。
结论
我们使用了一个非常简单的 API 简要地介绍了一个 RAML 规格的各个方面,目的是为了强调 RAML 的特性对 API 描述方面在代码重用和 DRY 原则方面所起的作用,包括以下关键因素:
- 通过!include 指令可以允许在主 RAML 文件中引入其它 RAML、YAML、JSON、XML 或 schema文件,从而实现模块化和代码重用。
- resourceTypes 实现了对多个资源中的共同行为的继承。
- trait 能够处理某方面常见的横切关注点,例如 url 查询参数。
最后,RAML 提供了一种可以描述广泛的安全性 schema 的机制,包括当今我们通常使用的 schema。
本文所描述的 RAML 的完整示例可以在 Github 上找到: github.com/scaganoff/example-eventlog-api 。
关于作者
 Saul Caganoff是一家澳大利亚的系统整合顾问公司 Sixtree 的 CTO,他在系统整合和软件项目开发上具有大量的架构师和工程师的经验,所参与的项目横跨澳大利亚、美国和亚洲。Saul 的专业爱好包括所有级别的架构,包括企业架构和解决方案架构,以及各种类型的应用程序,包括分布式系统、组合应用、云计算和云 API。
Saul Caganoff是一家澳大利亚的系统整合顾问公司 Sixtree 的 CTO,他在系统整合和软件项目开发上具有大量的架构师和工程师的经验,所参与的项目横跨澳大利亚、美国和亚洲。Saul 的专业爱好包括所有级别的架构,包括企业架构和解决方案架构,以及各种类型的应用程序,包括分布式系统、组合应用、云计算和云 API。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...












评论