

目前为止我听播客已经有几年的时间了, This American Life 和 Serial 让我开始了我的播客之路,而 The Political Gabfest 让我真正变得为之着迷。我很快发现,每周听一个小时是不够的。我需要找更多的播客加入到我的播放列表中来。但后来我遇到了一个问题:怎么找到那些你所喜欢的类型的播客? iTunes 是最大的播客系统,但它的推荐和搜索体验非常糟糕。
以 Meownster ——一个关于猫的播客为例,如果你在 iTunes 上查找相关的播客,你可能希望得到宠物爱好者的其他播客。 但你真正得到的是这样:
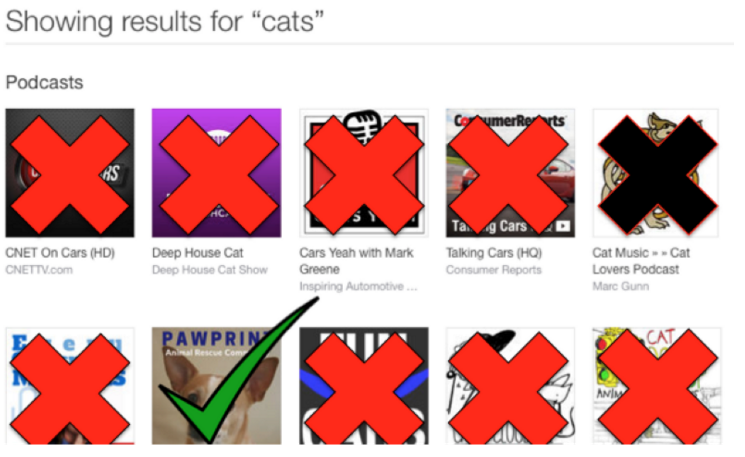
它是社会 / 文化类播放最多的播客列表,当然你可能会喜欢,但从我的角度来看很难说它们是“相关”的。
如果你尝试在 iTunes 上搜索“cat”播客,同样的最终得到结果也不会比这个好多少。一半的结果实际上是关于汽车,有些恰好在标题中有“cat”一词,其中两个是无效的 ; 你只能得到一个较好的结果。
那么播客爱好者会怎么做呢?当我在 Insight 开始我的研究生涯的时候,我意识将这个问题作为我的研究项目会是一个很好的方向。我认为利用和每个播客相关联的文本数据(即标题和描述),可以构建一个更好的播客推荐系统。于是我这样做了!结果就有了 thesauropod.us ,播客推荐库。
准备数据
为了让播客推荐算法正常运作,需要得到大量播客的标题和描述。幸运的是,有一个 iTunes API ,但不幸的是,我需要的信息是不允许查询的。
我需要解决的第一个问题是指定需要查询哪些播客。iTunes API 不允许获取 iTunes 集合中的部分或所有播客的列表 _[脚注 1]_。必须通过(例如,按标题)搜索特定的播客或使用其 iTunes ID 查找特定的播客。我从 github 上找到了一个大约 135,000 个播客的数据集,从中得到数千个播客的标题,解决了这个问题。
我需要解决的第二个问题是获得每个播客对应的标题和描述。但很遗憾,这些信息不能通过 API 获得,但通过播客的 ID 是可以从 iTunes 网站上获取到的。这里需要两个步骤来完成。首先,用数据集中播客的标题通过 iTunes API 搜索相关的播客。然后使用另外一个 API 通过播客 ID 查找到与该播客关联的 iTunes 网页,并使用 BeautifulSoup 库从其中提取标题和描述信息。
因为 API 查询和网页抓取都比较耗费时间,所以我尽量减少了我的数据集。在查询 API 之前,我使用 guess_ language 包删除那些不是英语类的播客。在网络抓取之前,我删除了那些在过去 45 天内没有发布剧集的播客(因为我只需要活跃的播客)。不过,我在尝试下载数据时遇到了一些问题。首先,iTunes API 有一个速率限制,但不会告诉你它具体是多少。因此,查询会在开始一段时间之后就会出现超时现象,于是我的脚本就被挂起了。我使用下面的函数解决了这个问题,这个函数允许我测试当前 API 查询的 URL 是否正常,如果异常就等待和重试。60 秒内进行四次重试直到成功。
def check_url(url, num_tries, wait_secs): """Check whether a url is valid. Allows multiple checks with waiting in between.""" import time import urllib2 for x in range(0, num_tries): try: urllib2.urlopen(url) str_error = None except urllib2.URLError as str_error: pass if str_error: time.sleep(wait_secs) else: break return str_error
第二,标题搜索并不总是奏效。有时我会得不到任何结果,有时我会得到很多(在播客标题较短的情况下更容易出现,如“This American Life”或“Serial”)。因为我不想不断地手动干预,所以我丢弃掉了那些标题没有精准匹配到一个结果的播客。因为这个策略导致最终丢掉了很多流行的播客,我通过从 iTunes Charts.net*[脚注 2]* 获取到的数据做了这部分播客的补全。最后,得到了一个约包含 6,000 个播客的数据集。
自然语言处理
我有了每个播客的标题和描述,是时候将文本数据转换为可以用来做相似性分析的形式了。第一步:预处理。
文本预处理
因为我想构建一种可以描述每个播客的算法,我把来自一个播客的所有文本数据连接在一起变成一个长文档 _[脚注 3]_。接下来,我需要去掉一些无用的文本数据。没有找到一个适合所有情况的解决方案。你需要仔细研究数据集(这意味着需要查看大量原始数据),以及该数据集中是否存在可能会影响算法效果的内容。在这个情况下,我选择删除这些内容:
1. 混合字母数字
一些播客在标题或说明中包括季 / 剧集编号(例如,“S4E11”),但绝大多数不包括。如果我将这种数据保留下来,那么有这种编号的播客将被标记为彼此更相似。但是因为我对内容相似性更感兴趣,这对我的算法没有意义。
2. 日期
类似地,一些播客在其描述中包括日期(例如,“5 月 26 日星期四”),但绝大多数不包括。我删除了一周中的几天和一年中的几个月,因为这对我定义的相似性指标没有任何意义。
3. 赞助声明
播客赚钱的主要方式是在剧集中播放广告。在某些情况下,这些赞助商公司也会在剧集描述中说明(例如,“此播客由 Squarespace 赞助…”)。虽然有这种可能——具有相同公司赞助商的播客在内容上更相似,我不想做这种假设,所以我尽量从数据中删除这些语句。
清洗数据后,下一步是将长字符串的文本向量化(用分词后独立的单词代表原始的文本字符串)。使用正则表达式从文本中删除任意非字母数字字符,然后使用来自 NLTK 的 RegexpTokenizer 用空格来分割文本。同时我也使用 stop_words 包去除了高频字(例如,a,the 或 or)。最后,使用 NLTK PorterStemmer 对每个单词进行提取词干去掉后缀。这步带来好处是相关词(例如,walk, walks, walking, walked)都被转换成相同的词干。 以下是完整的过程:
我们从原始文本开始:
‘Sure people who arent fascinated by cats and all of their uniquely feline awesomeness might be unable to tell a calico from a tortoiseshell, let alone a Burmese from a Balinese’
分词后:
[‘Sure’, ‘people’, ‘who’, ‘arent’, ‘fascinated’, ‘by’, ‘cats’, ‘and’, ‘all’, ‘of’, ‘their’, ‘uniquely’, ‘feline’, ‘awesomeness’, ‘might’, ‘be’, ‘unable’, ‘to’, ‘tell’, ‘a’, ‘calico’, ‘from’, ‘a’, ‘tortoiseshell’, ‘let’, ‘alone’, ‘a’, ‘Burmese’, ‘from’, ‘a’, ‘Balinese’]
去掉停用词:
[‘Sure’, ‘people’, ‘fascinated’, ‘cats’, ‘uniquely’, ‘feline’, ‘awesomeness’, ‘might’, ‘unable’, ‘tell’, ‘calico’, ‘tortoiseshell’, ‘let’, ‘alone’, ‘Burmese’, ‘Balinese’]
提取词干后:
[u’sure’, u’peopl’, u’fascin’, u’cat’, u’uniqu’, u’felin’, u’awesom’, u’might’, u’unabl’, u’tell’, u’calico’, u’tortoiseshel’, u’let’, u’alon’, u’burmes’, u’balines’]
创建语料库
此时,我们有每个播客的词干列表。现在,我们需要将这些字符串列表转换为数字向量,可以最终用于计算播客之间的相似性。对于所有的剩余处理,将使用功能强大的 gensim 包。它有优秀的文档和教程,为了达成目的,还需要一个称为 simserver 的文档相似性服务器。Simserver 提供了一种独立于内存且高效的存储方式来存储所有文本数据,并在我的网站的后台运行,这样可以为每个查询的播客提供相似性结果。它也支持在线更新,这意味着我可以添加新的播客到我的数据集,而不会中断当前用户。
使用 gensim 的第一件事是为文档语料库创建一个字典(在我的例子中,每个播客列表的词干是一个“文档”)。此字典包含唯一“token”(即,词干)的条目以及其在所有播客中出现的频率。这个频率信息对我们后续的工作有很重要的意义。
一旦定义了字典中的所有的词干,就可以将每个播客的词干列表转换为更高效的向量表示形式,称为“词袋”。例如,可以说 Meownster 文档包括’cat’27 次,'paw’15 次,以及’felin’5 次。我们可以取长字符串列表,并将其重新表示为元组列表,其中第一个值指示与该词干相关联的整数,第二个值指示该词干的频率:[(0,27),(1,15),(2,5)]。
变换语料库
现在可以使用这些向量表示形式来计算播客之间的相似性。但至少有两个原因,不能这样做。
首先,目前是将代表播客所有的单词视为同等,即使我们知道这是不成立的。例如,“摔跤”可能是语料库中一个非常低频的词,但对于关于摔跤的播客来说,这是一个非常有区分度的词:如果我们发现两个播客都包含“摔跤”多次,有很大的概率表明了这两个播客内容是相似的。相反,像“今天”这样的词语可能在整个语料库中高频出现 ; 即使两个播客都包含“今天”这个词,这并不能说明它们的内容相似(例如,一个可能是关于今天的新闻,另一个可能是关于今天发布的电影)。
为了解决这个问题,我应用了 TF-IDF (叫做词频 - 逆文档频率)变换了原来的词袋表示方法。在输出结果中,语料库中不常出现的词被赋予比语料库中经常出现的词更大的权重。这正是我们期望的(例如,摔跤 > 今天)。
原始模型的第二个问题是在我的语料库中包含大量特征,有大约 174,000 个独立的词干。通常来说减少模型中的特征数量是个好主意。出于实际原因,为每个播客存储100 个值比存储174,000 个值更有效率。也许违反直觉,较少的特征也有助于改善模型效果。这是因为模型中的许多特征是多余的,不能提供额外独特的信息。例如,如果我们知道播客包含单词“cat”100 次,此外它还包含单词“feline”50 次,不告诉我们任何新的线索- 已经有一个很好的猜测它可能是关于猫的。然后,可以将“cat”和“feline”(也许其他词,如“fur”和“paw”)归约成一个“猫”特征,更好地表示一个主题而不是用个别词。
在NLP 中,有许多不同的方法来解决这个问题。Gensim 的simserver 包括三个选项:LSI(潜在语义索引),LDA(线性判别式分析)和对数熵。我试过所有三个,发现LSI 最适合我的数据集(为了易于理解的LSI 工作原理的概述,见这里)。选择哪一个是最好的呢?因为没有一个标准的计算两个播客之间相似度的模型(如果有的话就不需要构建算法模型了),这一切都用一种原始方式完成的:用眼睛观察。我用TF-IDF 模型在所有变换后数据上运行,为每个播客输出一个更短的向量。然后,通过计算任意两个向量之间的余弦相似性,分别用每个模型为一个特定的测试集中的播客计算出一些最相似的播客,然后进行评测对比。下面是Meowster 的评测结果。可以看到,即使在调整模型的参数(降维)之前,LSI 的推荐效果也是非常好的。通过观察数据,为LSI 模型设置好主题的数量(发现100 个主题对我最有效)。

评估模型
上文提到过因为没有一个标准的计算两个播客之间相似度的模型,那么如何评估模型呢?理想情况下,我可以访问有关个人用户如何评价播客的数据或个人用户订阅的播客。目前是不能从iTunes 获得,但能够得到一些关于播客订阅的信息。对于流行的播客,iTunes 会展现“听众也订阅了”_[脚注4]_ 的推荐结果。通常假设共同订阅的两个播客应该比两个随机播客更相似。因此,如果比较来自模型的相似性分数,共同订阅的播客应当具有比随机播客更高的相似性。这就是我得到的结论。
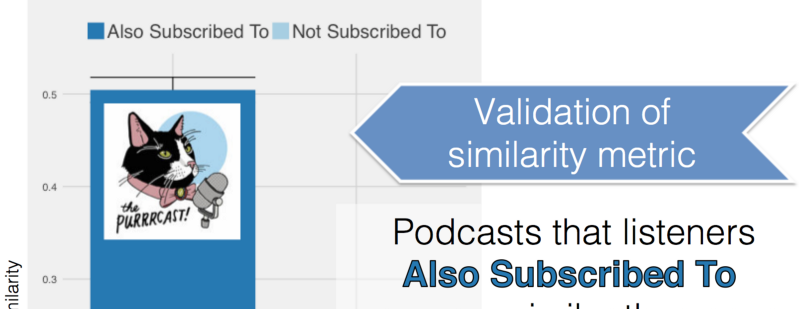
这些就是 thesauropod.us 的内部实现原理!这个工作花费了 3 个星期,最终的结果我也很满意。没有什么能比构建你自己真正使用的东西更令人兴奋。
脚注
- 如果您有权访问 Enterprise Partner Feed ,则可以下载所有元数据,但 Insight 项目周期短所以我没办法及时获取权限。
- 我能够通过解析他们提供的 iTunes 网址从而直接识别播客的 ID。
- 如果我想创建一个剧集推荐算法,我会把每个剧集的文本分成单独的文档。
- 因为在 iTunes 应用程序中获得的推荐结果(最多 15 个)比网站上的推荐结果(最多 5 个),所以在抓取播客数据的时候,我使用 PycURL 来模仿 iTunes 用户代理。
查看英文原文: Thesauropod.us: Building a Podcast Recommendation Algorithm
感谢杜小芳对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论