写在前面
Max Grigorev 最近写了一篇文章,题目是《What every software engineer should know about search》,这篇文章里指出了现在一些软件工程师的问题,他们认为开发一个搜索引擎功能就是搭建一个 ElasticSearch 集群,而没有深究背后的技术,以及技术发展趋势。Max 认为,除了搜索引擎自身的搜索问题解决、人类使用方式等之外,也需要解决索引、分词、权限控制、国际化等等的技术点,看了他的文章,勾起了我多年前的想法。
很多年前,我曾经想过自己实现一个搜索引擎,作为自己的研究生论文课题,后来琢磨半天没有想出新的技术突破点(相较于已发表的文章),所以切换到了大数据相关的技术点。当时没有写出来,心中有点小遗憾,毕竟凭借搜索引擎崛起的谷歌是我内心渴望的公司。今天我就想结合自己的一些积累,聊聊作为一名软件工程师,您需要了解的搜索引擎知识。
搜索引擎发展过程
现代意义上的搜索引擎的祖先,是 1990 年由蒙特利尔大学学生 Alan Emtage 发明的 Archie。即便没有英特网,网络中文件传输还是相当频繁的,而且由于大量的文件散布在各个分散的 FTP 主机中,查询起来非常不便,因此 Alan Emtage 想到了开发一个可以以文件名查找文件的系统,于是便有了 Archie。Archie 工作原理与现在的搜索引擎已经很接近,它依靠脚本程序自动搜索网上的文件,然后对有关信息进行索引,供使用者以一定的表达式查询。
互联网兴起后,需要能够监控的工具。世界上第一个用于监测互联网发展规模的“机器人”程序是 Matthew Gray 开发的 World wide Web Wanderer,刚开始它只用来统计互联网上的服务器数量,后来则发展为能够检索网站域名。
随着互联网的迅速发展,每天都会新增大量的网站、网页,检索所有新出现的网页变得越来越困难,因此,在 Matthew Gray 的 Wanderer 基础上,一些编程者将传统的“蜘蛛”程序工作原理作了些改进。现代搜索引擎都是以此为基础发展的。
搜索引擎分类
- 全文搜索引擎
当前主流的是全文搜索引擎,较为典型的代表是 Google、百度。全文搜索引擎是指通过从互联网上提取的各个网站的信息(以网页文字为主),保存在自己建立的数据库中。用户发起检索请求后,系统检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户。从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据存储层中调用;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos 引擎。
- 目录索引类搜索引擎
虽然有搜索功能,但严格意义上不能称为真正的搜索引擎,只是按目录分类的网站链接列表而已。用户完全可以按照分类目录找到所需要的信息,不依靠关键词(Keywords)进行查询。目录索引中最具代表性的莫过于大名鼎鼎的 Yahoo、新浪分类目录搜索。
-
元搜索引擎
元搜索引擎在接受用户查询请求时,同时在其他多个引擎上进行搜索,并将结果返回给用户。著名的元搜索引擎有 InfoSpace、Dogpile、Vivisimo 等,中文元搜索引擎中具代表性的有搜星搜索引擎。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,如 Dogpile,有的则按自定的规则将结果重新排列组合,如 Vivisimo。
相关实现技术
搜索引擎产品虽然一般都只有一个输入框,但是对于所提供的服务,背后有很多不同业务引擎支撑,每个业务引擎又有很多不同的策略,每个策略又有很多模块协同处理,及其复杂。
搜索引擎本身包含网页抓取、网页评价、反作弊、建库、倒排索引、索引压缩、在线检索、ranking 排序策略等等知识。
- 网络爬虫技术
网络爬虫技术指的是针对网络数据的抓取。因为在网络中抓取数据是具有关联性的抓取,它就像是一只蜘蛛一样在互联网中爬来爬去,所以我们很形象地将其称为是网络爬虫技术。网络爬虫也被称为是网络机器人或者是网络追逐者。
网络爬虫获取网页信息的方式和我们平时使用浏览器访问网页的工作原理是完全一样的,都是根据 HTTP 协议来获取,其流程主要包括如下步骤:
1)连接 DNS 域名服务器,将待抓取的 URL 进行域名解析(URL------>IP);
2)根据 HTTP 协议,发送 HTTP 请求来获取网页内容。
一个完整的网络爬虫基础框架如下图所示:
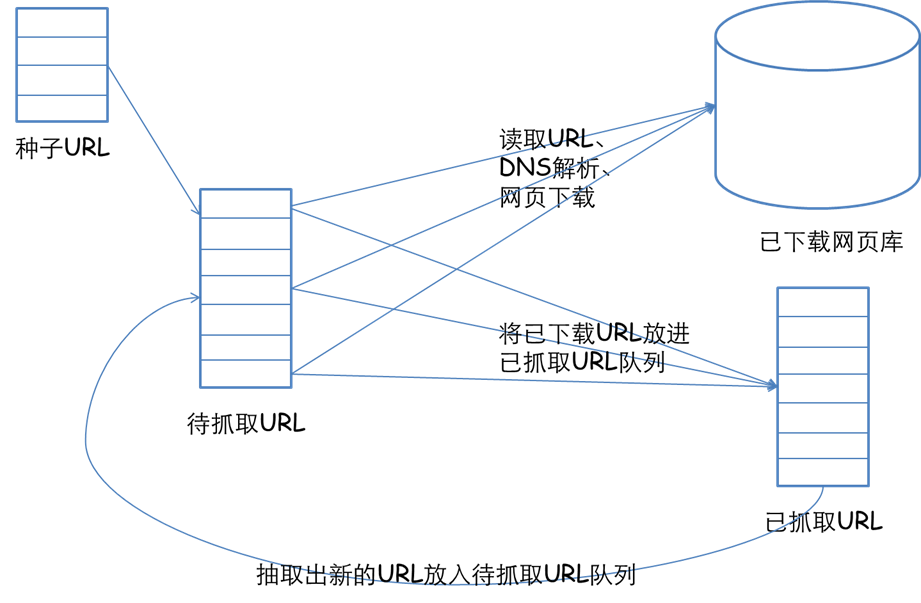
整个架构共有如下几个过程:
1)需求方提供需要抓取的种子 URL 列表,根据提供的 URL 列表和相应的优先级,建立待抓取 URL 队列(先来先抓);
2)根据待抓取 URL 队列的排序进行网页抓取;
3)将获取的网页内容和信息下载到本地的网页库,并建立已抓取 URL 列表(用于去重和判断抓取的进程);
4)将已抓取的网页放入到待抓取的 URL 队列中,进行循环抓取操作;
- 索引
从用户的角度来看,搜索的过程是通过关键字在某种资源中寻找特定的内容的过程。而从计算机的角度来看,实现这个过程可以有两种办法。一是对所有资源逐个与关键字匹配,返回所有满足匹配的内容;二是如同字典一样事先建立一个对应表,把关键字与资源的内容对应起来,搜索时直接查找这个表即可。显而易见,第二个办法效率要高得多。建立这个对应表事实上就是建立逆向索引(inverted index)的过程。
- Lucene
Lucene 是一个高性能的 java 全文检索工具包,它使用的是倒排文件索引结构。
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
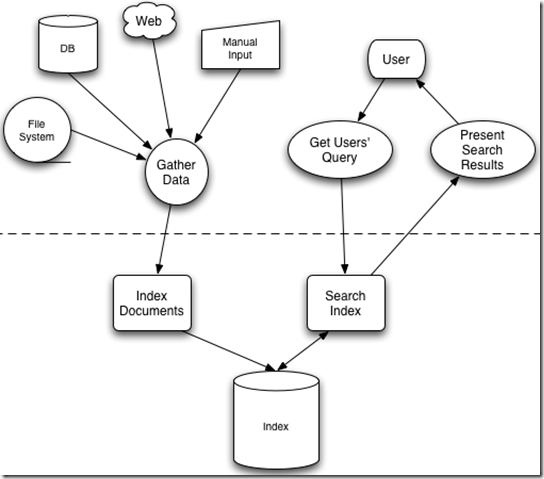
非结构化数据中所存储的信息是每个文件包含哪些字符串,也即已知文件,欲求字符串相对容易,也即是从文件到字符串的映射。而我们想搜索的信息是哪些文件包含此字符串,也即已知字符串,欲求文件,也即从字符串到文件的映射。两者恰恰相反。于是如果索引总能够保存从字符串到文件的映射,则会大大提高搜索速度。
由于从字符串到文件的映射是文件到字符串映射的反向过程,于是保存这种信息的索引称为反向索引 。
反向索引的所保存的信息一般如下:
假设我的文档集合里面有 100 篇文档,为了方便表示,我们为文档编号从 1 到 100,得到下面的结构
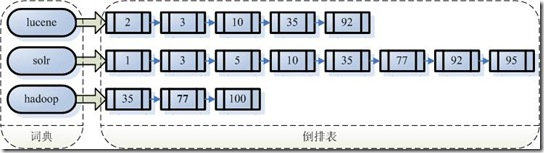
每个字符串都指向包含此字符串的文档 (Document) 链表,此文档链表称为倒排表 (Posting List)。
- ElasticSearch
Elasticsearch 是一个实时的分布式搜索和分析引擎,可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。Elasticsearch 是一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎,但是 Lucene 只是一个框架,要充分利用它的功能,需要使用 JAVA,并且在程序中集成 Lucene。Elasticsearch 使用 Lucene 作为内部引擎,但是在使用它做全文搜索时,只需要使用统一开发好的 API 即可,而不需要了解其背后复杂的 Lucene 的运行原理。
- Solr
Solr 是一个基于 Lucene 的搜索引擎服务器。Solr 提供了层面搜索、命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式)。它易于安装和配置,而且附带了一个基于 HTTP 的管理界面。Solr 已经在众多大型的网站中使用,较为成熟和稳定。Solr 包装并扩展了 Lucene,所以 Solr 的基本上沿用了 Lucene 的相关术语。更重要的是,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。通过对 Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。此外,很多 Lucene 工具(如 Nutch、 Luke)也可以使用 Solr 创建的索引。
- Hadoop
谷歌公司发布的一系列技术白皮书导致了 Hadoop 的诞生。Hadoop 是一系列大数据处理工具,可以被用在大规模集群里。Hadoop 目前已经发展为一个生态体系,包括了很多组件,如图所示。
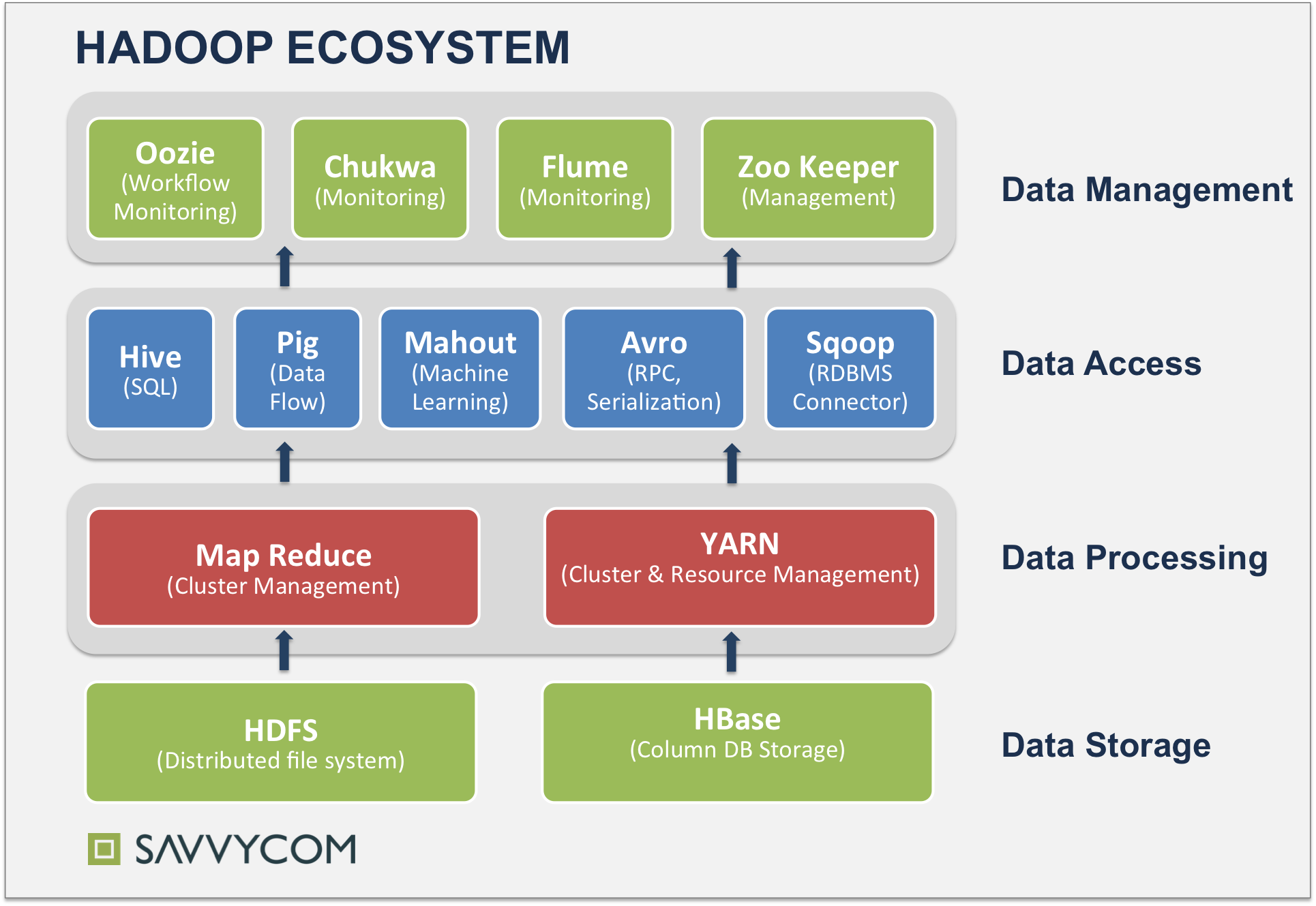
Cloudera 是一家将 Hadoop 技术用于搜索引擎的公司,用户可以采用全文搜索方式检索存储在 HDFS(Hadoop 分布式文件系统)和 Apache HBase 里面的数据,再加上开源的搜索引擎 Apache Solr,Cloudera 提供了搜索功能,并结合 Apache ZooKeeper 进行分布式处理的管理、索引切分以及高性能检索。
- PageRank
谷歌 Pagerank 算法基于随机冲浪模型,基本思想是基于网站之间的相互投票,即我们常说的网站之间互相指向。如果判断一个网站是高质量站点时,那么该网站应该是被很多高质量的网站引用又或者是该网站引用了大量的高质量权威的站点。
- 国际化
坦白说,Google 虽然做得非常好,无论是技术还是产品设计,都很好。但是国际化确实是非常难做的,很多时候在细分领域还是会有其他搜索引擎的生存余地。例如在韩国,Naver 是用户的首选,它本身基于 Yahoo 的 Overture 系统,广告系统则是自己开发的。在捷克,我们则更多会使用 Seznam。在瑞典,用户更多选择 Eniro,它最初是瑞典的黄页开发公司。
国际化、个性化搜索、匿名搜索,这些都是 Google 这样的产品所不能完全覆盖到的,事实上,也没有任何一款产品可以适用于所有需求。
自己实现搜索引擎
如果我们想要实现搜索引擎,最重要的是索引模块和搜索模块。索引模块在不同的机器上各自进行对资源的索引,并把索引文件统一传输到同一个地方(可以是在远程服务器上,也可以是在本地)。搜索模块则利用这些从多个索引模块收集到的数据完成用户的搜索请求。因此,我们可以理解两个模块之间相对是独立的,它们之间的关联不是通过代码,而是通过索引和元数据,如下图所示。
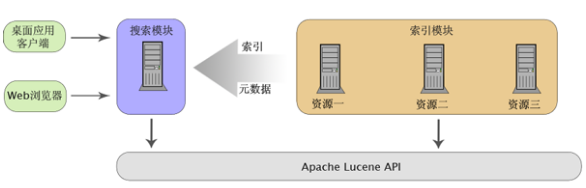
对于索引的建立,我们需要注意性能问题。当需要进行索引的资源数目不多时,隔一定的时间进行一次完全索引,不会占用很长时间。但在大型应用中,资源的容量是巨大的,如果每次都进行完整的索引,耗费的时间会很惊人。我们可以通过跳过已经索引的资源内容,删除已不存在的资源内容的索引,并进行增量索引来解决这个问题。这可能会涉及文件校验和索引删除等。另一方面,框架可以提供查询缓存功能,提高查询效率。框架可以在内存中建立一级缓存,并使用如 OSCache 或 EHCache 缓存框架,实现磁盘上的二级缓存。当索引的内容变化不频繁时,使用查询缓存更会明显地提高查询速度、降低资源消耗。
搜索引擎解决方案
- Sphinx
俄罗斯一家公司开源的全文搜索引擎软件 Sphinx,单一索引最大可包含 1 亿条记录,在 1 千万条记录情况下的查询速度为 0.x 秒(毫秒级)。Sphinx 创建索引的速度很快,根据网上的资料,Sphinx 创建 100 万条记录的索引只需 3~4 分钟,创建 1000 万条记录的索引可以在 50 分钟内完成,而只包含最新 10 万条记录的增量索引,重建一次只需几十秒。
- OmniFind
OmniFind 是 IBM 公司推出的企业级搜索解决方案。基于 UIMA (Unstructured Information Management Architecture) 技术,它提供了强大的索引和获取信息功能,支持巨大数量、多种类型的文档资源(无论是结构化还是非结构化),并为 Lotus®Domino®和 WebSphere®Portal 专门进行了优化。
下一代搜索引擎
从技术和产品层面来看,接下来的几年,甚至于更长时间,应该没有哪一家搜索引擎可以撼动谷歌的技术领先优势和产品地位。但是我们也可以发现一些现象,例如搜索假期租房的时候,人们更喜欢使用 Airbub,而不是 Google,这就是针对匿名 / 个性化搜索需求,这些需求是谷歌所不能完全覆盖到的,毕竟原始数据并不在谷歌。我们可以看一个例子:DuckDuckGo。这是一款有别于大众理解的搜索引擎,DuckDuckGo 强调的是最佳答案,而不是更多的结果,所以每个人搜索相同关键词时,返回的结果是不一样的。
另一个方面技术趋势是引入人工智能技术。在搜索体验上,通过大量算法的引入,对用户搜索的内容和访问偏好进行分析,将标题摘要进行一定程度的优化,以更容易理解的方式呈现给用户。谷歌在搜索引擎 AI 化的步骤领先于其他厂商,2016 年,随着 Amit Singhal 被退休,John Giannandrea 上位的交接班过程后,正式开启了自身的革命。Giannandrea 是深度神经网络、近似人脑中的神经元网络研究方面的顶级专家,通过分析海量级的数字数据,这些神经网络可以学习排列方式,例如对图片进行分类、识别智能手机的语音控制等等,对应也可以应用在搜索引擎。因此,Singhal 向 Giannandrea 的过渡,也意味着传统人为干预的规则设置的搜索引擎向 AI 技术的过渡。引入深度学习技术之后的搜索引擎,通过不断的模型训练,它会深层次地理解内容,并为客户提供更贴近实际需求的服务,这才是它的有用,或者可怕之处。
作者介绍
周明耀,2004 年毕业于浙江大学,工学硕士。13 年软件研发经验,近 10 年技术团队管理经验,4 年分布式计算、大数据技术经验。出版书籍包括《大话 Java 性能优化》、《深入理解 JVM&G1 GC》、《技术领导力 - 码农如何才能带团队》。个人微信号 michael_tec,个人公众号“麦克叔叔每晚 10 点说”出品人,每天发布一篇技术短文。
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




