
在过去的几个月里,Yelp 一直在不断地向大家分享着他们的数据管道的情况(文章列表见页尾)。这是一套基于 Python 的工具,可以实时地将数据流向需要它们的服务,并随之加以必要的数据处理。这一系列的文章讲述了如何从 MySQL 中将消息复制出来、如何跟踪模式的变化及演进、并最终分享了如何把数据接入到 Redshift 和 Salesforce 等不同类型的目标存储。
幸好 Yelp 非常慷慨,他们不只是分享了自己的设计思路和经验,更是赶在圣诞节之前向大家献上了一份大礼,把主要模块开源出来了!
在读过了所有这些关于我们的数据管道的文章之后,可能你会觉得我们这些 Yelp 的人不过是像一个孩子在向大家炫耀他的新玩具一样,肯定会自己捂得严严的,不会和大家分享。但是和大多数有了新玩具又不会分享的孩子一样,我们愿意分享——所以我们最终决定要把我们的数据管道的主体部分开源出来,然后大家就可以开心地迎来新年假期了。
闲话少说,下面这些就是 Yelp 为大家的假期准备的圣诞礼物:
- MySQL Streamer 会不断地查看 MySQL 的 binlog,得到最新的表变更操作。Streamer 负责捕获 MySQL 数据库上的单条数据更改操作,并把它封装成 Kafka 消息,发布到 Kafka 的某个 Topic 中。如果有必要,也会做模式转换。
- Schematizer 服务会跟踪每一条消息所使用的模式信息。在有新模式出现时,Schematizer 会处理注册消息,并为下游的表生成更改计划。
- Data Pipeline clientlib 为生产和消费 Kafka 消息提供了非常易用的接口。有了 clientlib,就再也不必关心 Kafka 的 Topic 名字、加密或消费者程序的分区情况了。你可以站在表和数据库的角度去考虑问题,不必关心其它细节。
- Data Pipeline Avro utility 包提供了读写 Avro 模式的 Python 接口。它也可以为表的主键等模式信息提供枚举类,这一点 Yelp 在实践中发现非常有用。
- Yelp Kafka 库扩展了 Kafka-python 包,并提供了多重处理消费者组等新功能。这个库可以帮助大家非常高效地与 Kafka 进行交互。这个库也让用户可以判断出 Yelp 内部的 Kafka 跨区域部署情况。
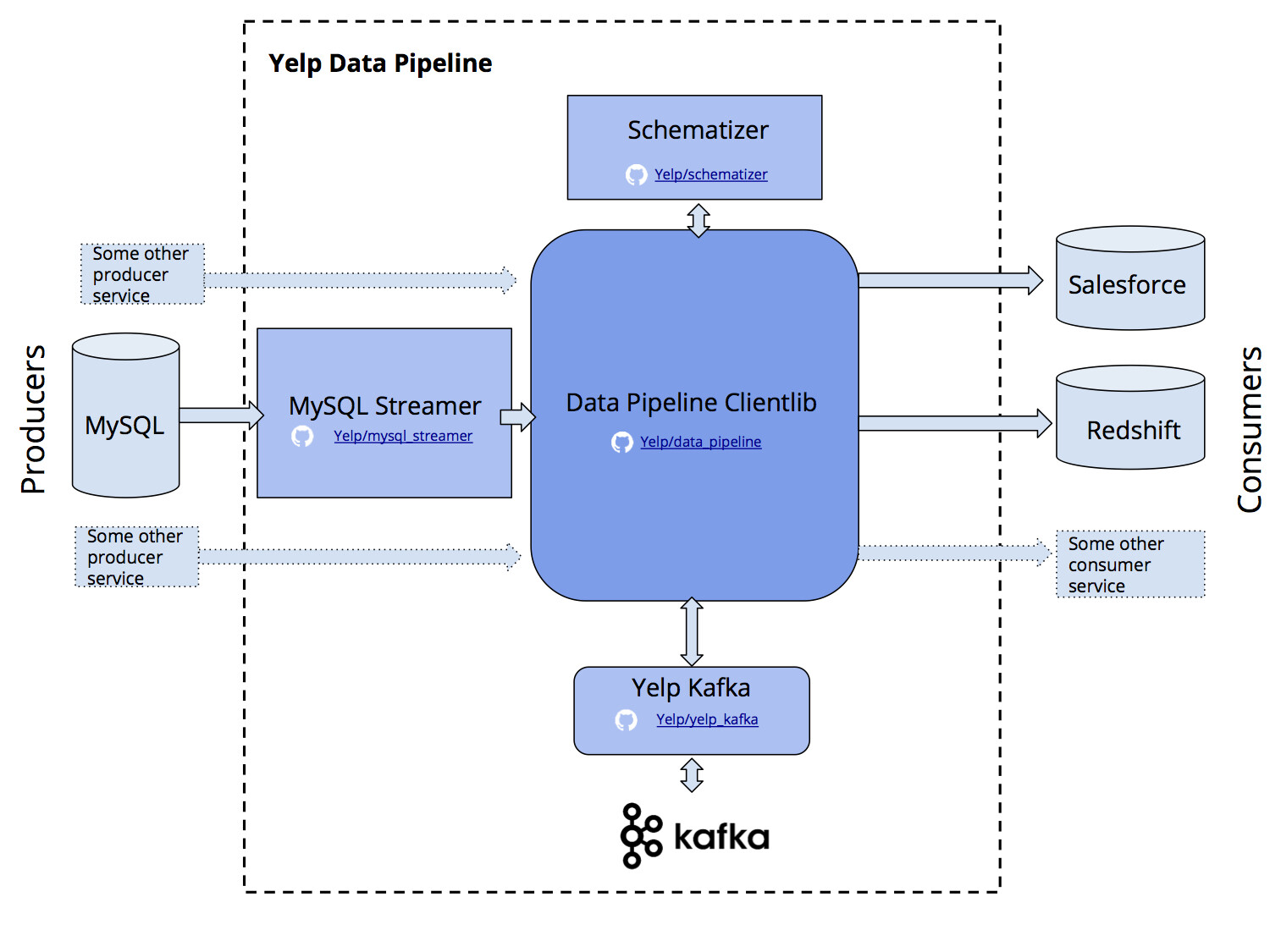
数据管道中不同组成部分的概览图。单个服务用方形表示,而共享包用圆角表示。
这些项目每个都有 Docker 化的服务,你可以很容易地把它们用到你的架构中。我们希望对于每个用 Python 构建实时流处理程序的开发者来说,它们都能有用。
有了之前的文章介绍,现在又有了开源的代码,相信有许多数据处理工程师的圣诞假期都会过得无比充实了。
Yelp 的系列文章深度讲解了他们如何用“确保只有一次”的方式把 MySQL 数据库中的改动实时地以流的方式传输出去,他们如何自动跟踪表模式变化、如何处理和转换流,以及最终如何把这些数据存储到 Redshift 或 Salesforce 之类的数据仓库中去。
第一篇:一天几十亿条消息:Yelp 的实时数据管道。(英文)
第二篇: Yelp 的实时流技术之二:将 MySQL 表数据变更实时流到 Kafka 中。(英文)
第三篇: Yelp 的实时流技术之三:不止是模式存储服务的 Schematizer 。(英文)
第四篇: Yelp 的实时流技术之四:流处理器 PaaStorm 。(英文)
第五篇: Yelp 的实时流技术之五:数据管道之 Salesforce Connector 。(英文)
第六篇: Yelp 的实时流技术之六:近实时地将 Kafka 中的数据流入 Redshift 。(英文)
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论