
在不久前的 Hadoop 峰会上,Facebook 的工程师 Andrew Ryan 分享了他们如何使用 Namenode 和 Avatarnode 提升 HDFS 可靠性的方法。Ryan 从 2009 年开始,就参与到了 Facebook 的 Hadoop 开发中。在他的帮助下,Facebook 的 Hadoop 和 HDFS 数据基础设施,从一个数据中心的单个 600TB 集群,发展到了多个数据中心超过 100 多个 HDFS 集群。
Ryan 首先分析了 HDFS 的 Namenode 机制。
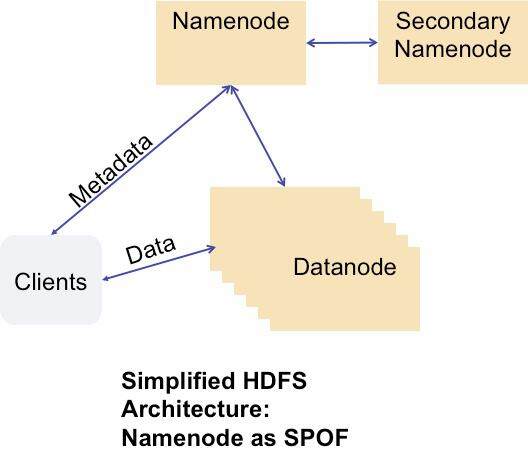
图:Namenode,单点故障点
在 HDFS 中,客户端通过 Namenode 服务器完成文件系统的元数据操作,并与一个 Datanode 池通信,以发送和接受文件系统数据。数据在多个 Datanode 上都有复制,因此一个 Datanode 宕机不会出现数据丢失,对集群也不应是致命问题。
但是 Namenode 就不是这样,所有的元数据操作都要通过它完成。如果 Namenode 不可用,任何客户端就无法从 HDFS 完成读写操作,虽然客户端仍可以从 Datanode 中读出单个数据块,但是整个 HDFS 就处于宕机状态,所有依赖于 HDFS 的用户和应用就无法正常工作。
因此,HDFS Namenode 是一个单点故障点(SPOF)。
Ryan 指出:在 Facebook,他们希望知道这个问题的影响范围,并尝试找出解决这个问题的方法。
Data Warehouse 是 Facebook 最大的 HDFS 部署之一,他们用其完成传统的 HadoopMapReduce 工作:有一些非常大的集群运行 MapReduce 批处理。由于集群很大,Namenode 的负载非常高,CPU、内存、磁盘和网络都常常处于很大的压力之下。他们的统计发现:在 Data Warehouse 发生的问题中,41% 是由 HDFS 造成的,这也是最大的问题肇因。
Ryan 接下来指出:如果能有某种高可用的 Namenode 方案,也许能防止 10% 的 Data Warehouse 问题和突发的宕机时间,这仍然是一个巨大的胜利,因为这让他们可以执行计划好的软件与硬件维护操作。实际上,他们估计这可以减少他们 50% 计划好的宕机时间,而之前在这些时间里集群都是不可用的。
下图是他们的高可用 Namenode HDFS 架构的简化版本。
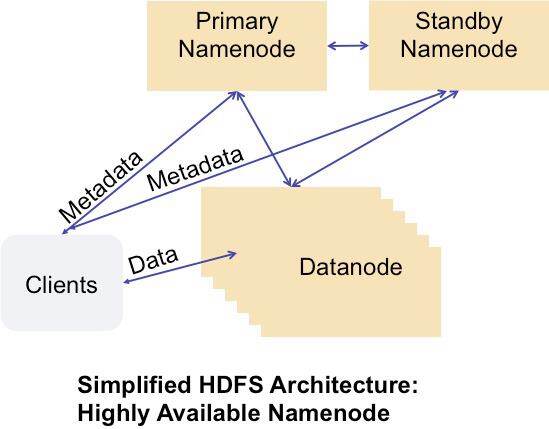
图:高可用的 Namenode
在这个架构中,客户端可以与 Primary Namenode 或是 Standby Namenode 通信,Datanode 也可以向这两个服务器发送块报告,实现了高可用的 Namenode——Avatarnode。
Ryan 提到:Facebook 在两年前就开始研究 Avatarnode。现在,这已经是一个开源项目,提供高可用的 Namenode,支持热切换。目前,在 Facebook 中,Avatarnode 已经进入生产环境,并运行在他们最大的 Hadoop Data Warehouse 集群中。
Avatarnode 是一个双节点的、高可用的 Namenode,需要手工完成故障切换。它将现有的 Namenode 代码包装在一个 Zookeeper 层中。Avatarnode 的基本概念包括:
- Primary Avatarnode 和 Standby Avatarnode 角色可互换。
- 当前的 Primary Avatarnode 主机名保存在 Zookeeper 中。
- 修改后的 Datanode 的块报告要同时发送给 Primary Avatarnode 和 Standby Avatarnode。
- 修改后的 HDFS 客户端在开始每次事务前,要检查 Zookeeper,如果以此事务失败,要再次检查 Zookeeper。即使 Avatarnode 发生故障切换,一次写操作也可以得以完成。
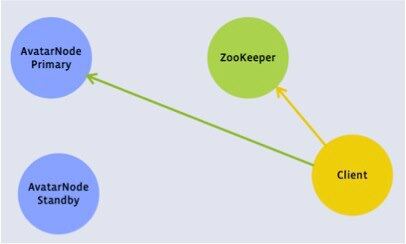
图:客户端视角
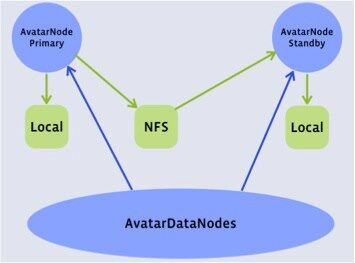
图:Datanode 视角
Ryan 指出:接下来,他们要进一步提升 Avatarnode,并将其整合在一个通用的高可用框架中,使之能够完成不需人工参与的、自动化的、安全的故障切换。
读者可以访问 GitHub 上 Facebook 发布的 Hadoop 版本,其中包括 Avatarnode 源代码。
除了 Facebook 之外,还有其他公司也致力于解决这个问题,包括:
- Appistry, 2010 年就发布了一个完全分布式的文件系统
- MapR 的 Hadoop 版本也提供高可用的文件系统
- Apache 的 Hadoop 2.0 中,也包括了 Cloudera 的最新发布版本
InfoQ 的读者,不知道您对如何解决 Namenode 高可用问题有何意见和看法?欢迎在评论中分享您的经验。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论