


研究背景
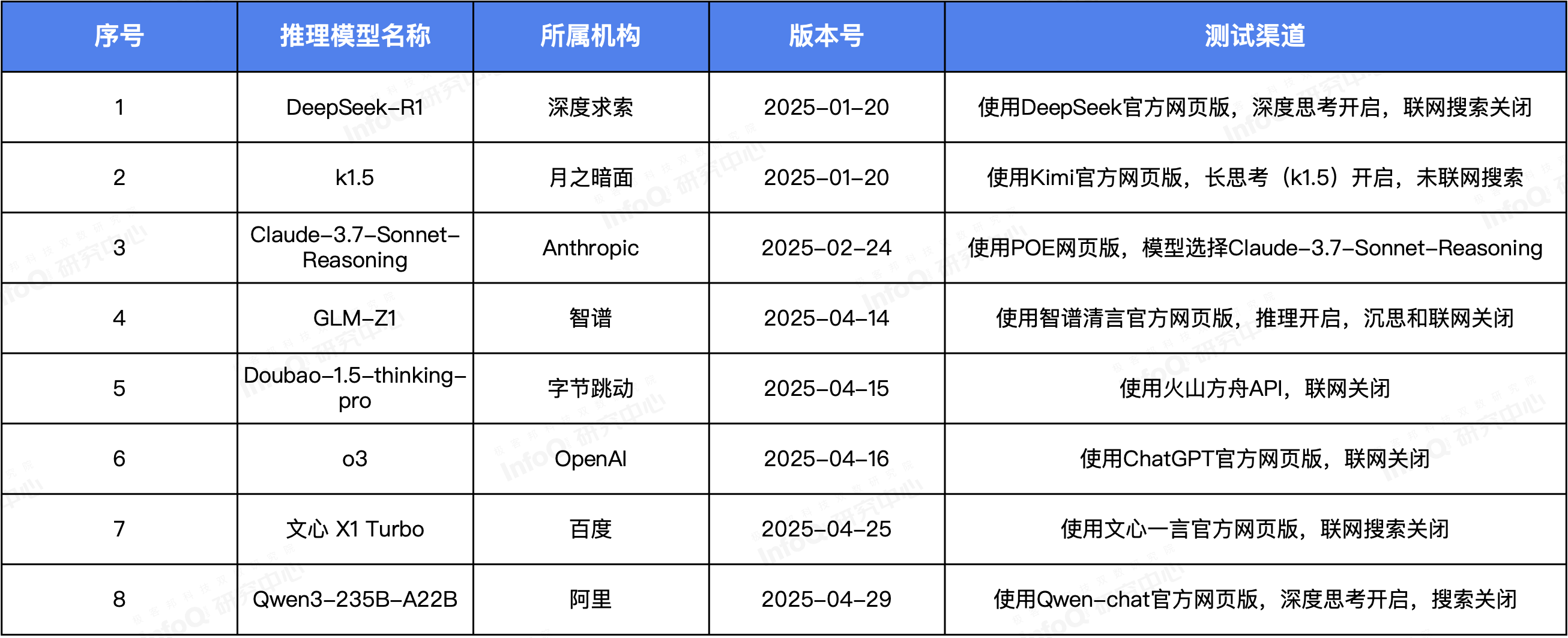
近期国内外以推理能力为核心的推理模型频繁发布,InfoQ 研究中心在对推理模型的训练原理、能力表现等进行深入分析后,围绕逻辑推理、数学推理、语言推理、多步推理、幻觉控制五大核心领域共计 300 道测试题目,对包括 DeepSeek-R1、k1.5、Claude-3.7-Sonnet-Reasoning、GLM-Z1、Doubao-1.5-thinking-pro、o3、文心 X1 Turbo、Qwen3-235B-A22B 在内的八款热门推理模型进行了全面评估。
InfoQ 研究中心希望通过这次评估,帮助技术领域的同仁更深入地了解国内外推理模型在各维度推理领域的表现,从而为大模型的持续进步和应用实施提供参考和助力。
测试结果
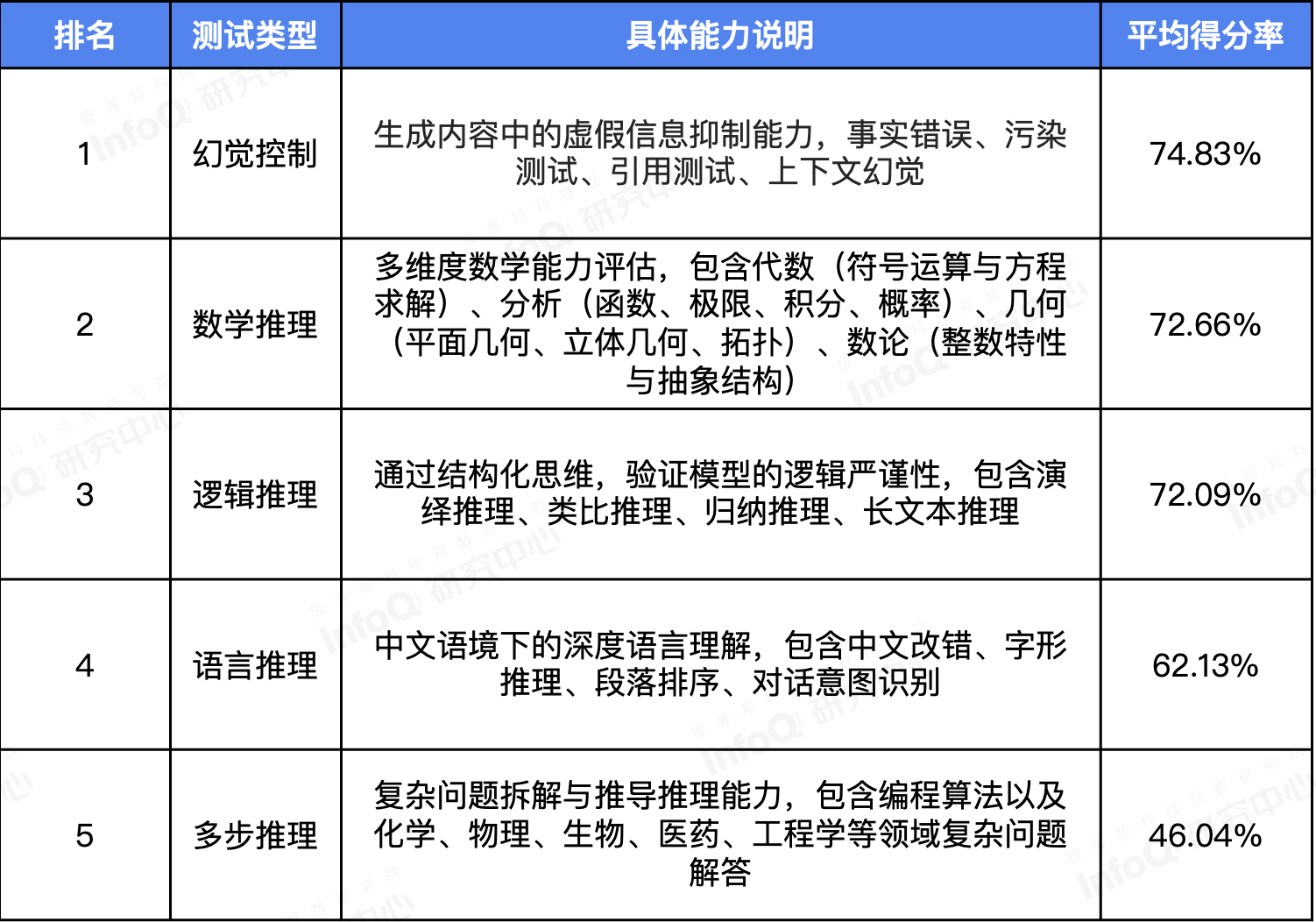
整体来看,推理模型在幻觉控制、数学推理、逻辑推理都表现出了比较亮眼的成绩,但多步推理的短板仍然较为明显。
引用测试中,推理模型幻觉呈现更加隐蔽的特点,并且擅于虚构各类具体数据或者生成具体论文/报告/产品名称,让推理模型的输出看起来更有依据。
推理模型在以数字、符号为代表的代数和分析领域得分较高,但涉及到平面或空间的几何结构时,思考时间变长,准确率也有所下降。
推理模型在文本长度增加、场景复杂度增加的情况下,准确性存在明显下降。
推理模型在对话意图识别上优势明显,部分模型对中文汉字的字形结构存在基础认知,例如左右、上下、独字以及包围结构等,但在认知准确性上仍有一定优化空间。
在面对化学、物理、生物、医药、工程学等领域的复杂问题时,推理模型的思考时间是所有维度中最长的,准确性也是最低的。
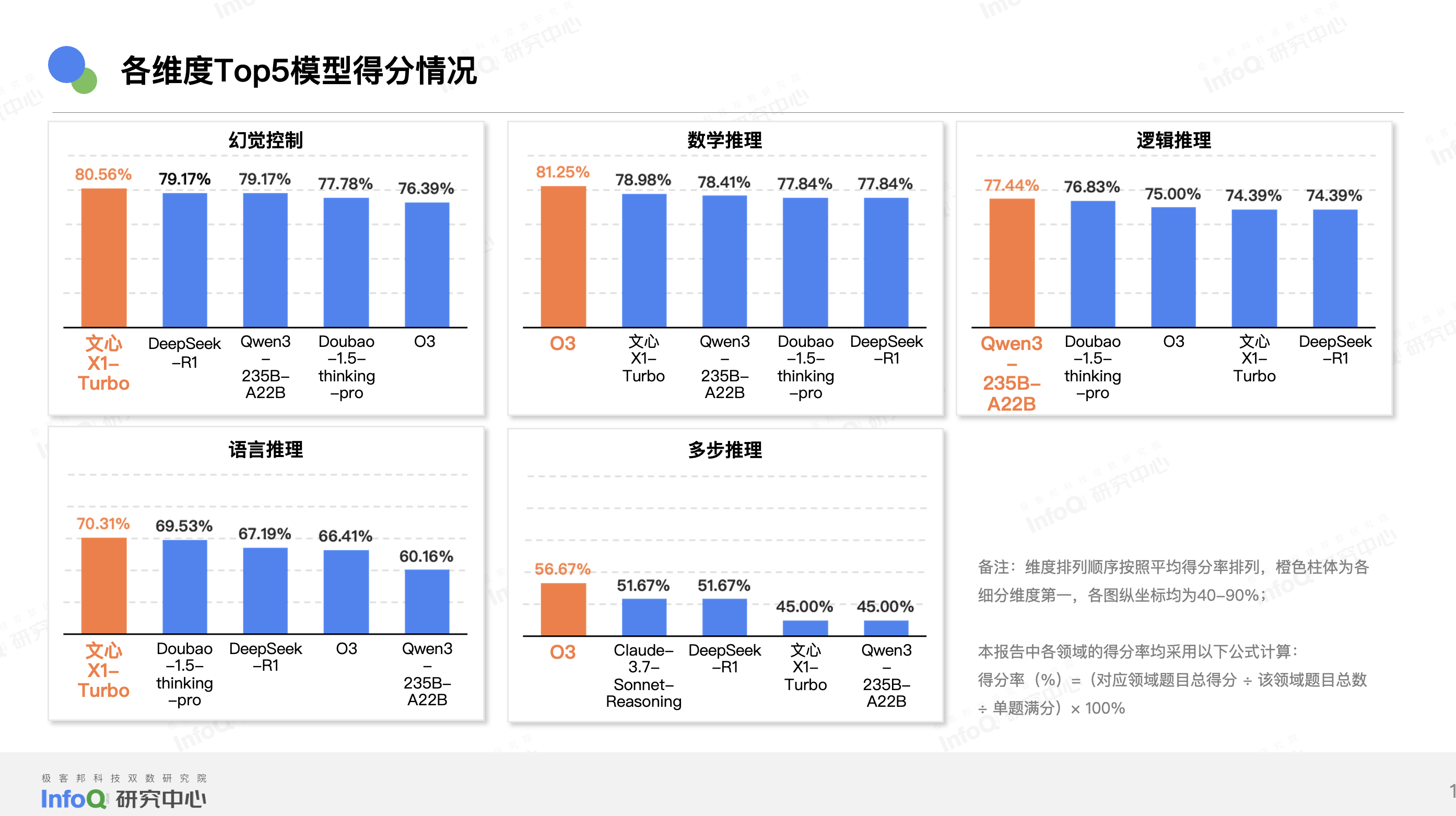
各能力维度 Top5 模型
从各维度推理模型的表现来看,O3 和文心 X1-Turbo 均在两个细分维度位居第一,O3 在数学推理和多步推理两个维度位居第一,文心 X1 Turbo 在幻觉控制和语言推理两个维度位居第一,Qwen3-235B-A22B 在逻辑推理维度位居第一。
除了准确性外,报告还在回答准确性与思考时长之间的关系进行了研究。
报告目录
● 推理模型发展阶段和发展因素分析
● 推理模型测评体系和结果分析
● 推理模型未来展望














评论