

剪枝是深度学习中用来帮助开发更小、更高效神经网络的技术。它是一种模型优化技术,通过移除权重张量中冗余的值来实现模型优化。它实现了神经网络的压缩,让神经网络运行得更快,减少了网络训练的计算开销,这在把模型部署到手机或者其他终端设备上时显得尤为重要。在这篇指南中,我们会浏览一下神经网络剪枝领域的一些研究论文。
Pruning from Scratch(2019)
这篇论文的作者提出了网络剪枝流水线,能够从一开始训练模型时就进行剪枝。基于 CIFAR10 和 ImageNet 数据集做的压缩分类模型实验,可以看出这个流水线减少了原来通用流水线方法里产生的预训练开销,同时还增加了网络的精度。
论文网页:https://arxiv.org/abs/1909.12579
下图所示是传统剪枝过程的 3 个阶段。这个过程包括预训练、剪枝和微调。
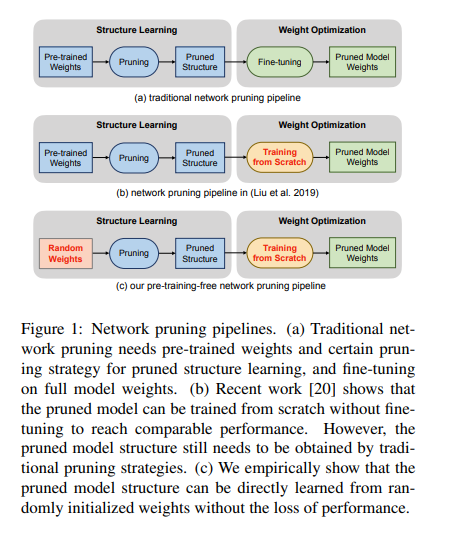
来源:https://arxiv.org/pdf/1909.12579.pdf
这篇论文里提出的剪枝技术需要构建一条剪枝流水线,这条流水线可以从随机初始化权重开始进行学习得到。该论文方法给每个网络层赋予标量门值,从而学习得到通道的重要性。
该论文方法为了改善模型在稀疏正则化下的性能,对通道重要性做了优化。在这个优化过程中,不用更新随机权重,之后,在给予一定资源限制的情况下,使用二分查找策略来决定剪枝后模型的通道数量配置。
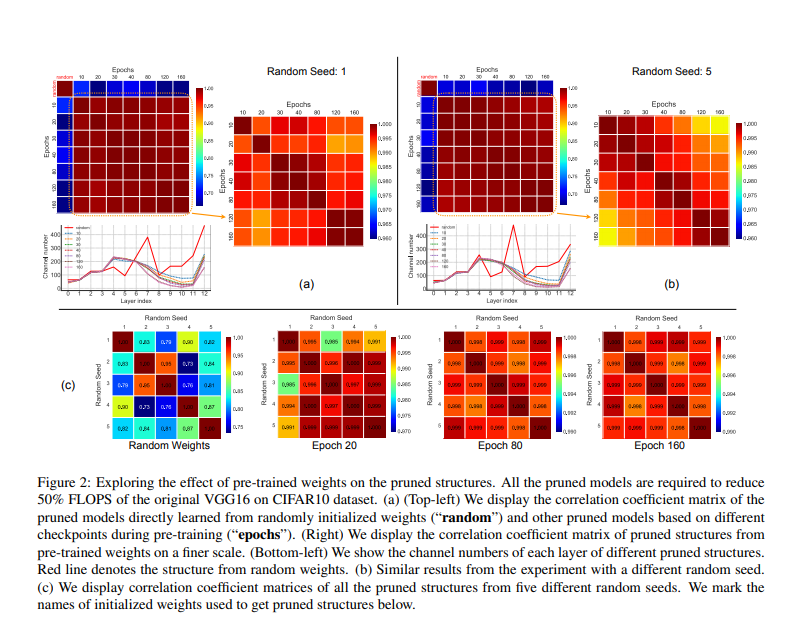
来源:https://arxiv.org/pdf/1909.12579.pdf
这里让我们看一下不同数据集上的模型精度:
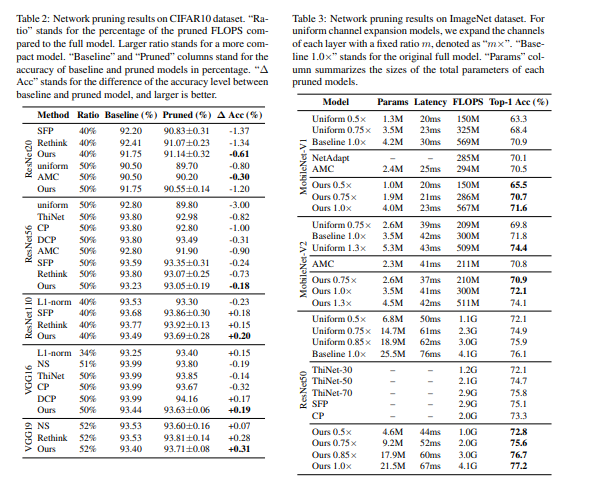
来源:https://arxiv.org/pdf/1909.12579.pdf
在把模型部署到低算力的设备上(如智能手机)时,优化机器学习模型显得特别重要(也很复杂)。
Adversarial Neural Pruning(2019)
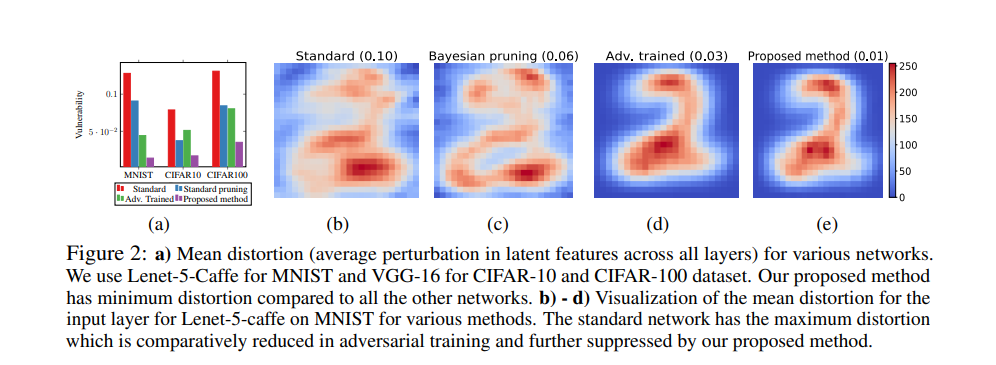
这篇论文研究了具有对抗性扰动的网络隐特征的畸变问题。论文提出的方法通过学习一个贝叶斯剪枝掩码来抑制那些畸变较高的特征,这样可以最大化对抗性偏差上的健壮性。
作者研究了深度神经网络里隐特征的不稳定性。论文方法提出裁剪掉不稳定的特征,而保留健壮性的特征。这是在贝叶斯框架下通过对抗式学习剪枝掩码来实现的。
来源:https://arxiv.org/pdf/1908.04355.pdf
论文网页:https://arxiv.org/abs/1908.04355
对抗式神经剪枝(ANP:Adversarial Neural Pruning)在对抗式训练的概念中结合了贝叶斯剪枝方法。这个方法的基本情况如下:
它是一个标准的卷积神经网络
它是一个对抗式训练网络
它是采用 beta-Bernoulli dropout 方法的对抗式剪枝方法
这个对抗式训练网络通过易损抑制代价函数进行正则化
这个对抗式神经剪枝网络通过易损抑制代价函数进行正则化
以下表格显示了这个模型的性能表现。
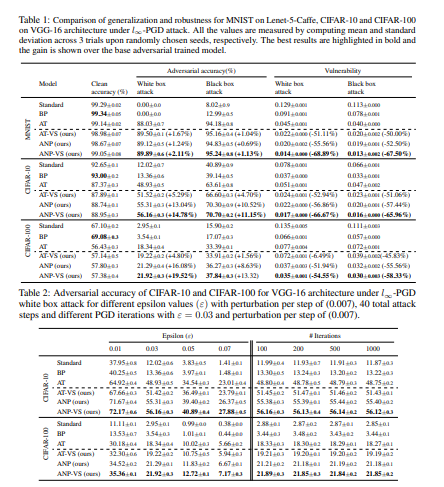
来源:https://arxiv.org/pdf/1908.04355.pdf
Rethinking the Value of Network Pruning(ICLR 2019)
这篇论文提出的网络剪枝方法分为两部分。裁剪后的目标模型要么是由人工设计出来,要么是由剪枝算法计算得到。在该论文实验部分,作者还对比了两种结果,即从头开始训练一个裁剪过的模型,以及对继承的权重进行微调训练这两种训练方式的结果,每种结果里的网络类型都包含人工预定义网络和算法自动生成的网络两种。
论文页面:https://arxiv.org/abs/1810.05270v2
下图显示了预定义的结构化剪枝结果,使用的是基于 L1-norm 的过滤器剪枝。每一层会剪掉一定比例的过滤器,即 L1-norm 较小的那一部分过滤器。Pruned Method 这一列显示了预定义的模型配置清单。论文观察到,每一行,从头训练的模型都达到了至少和微调模型同样水平的精度。
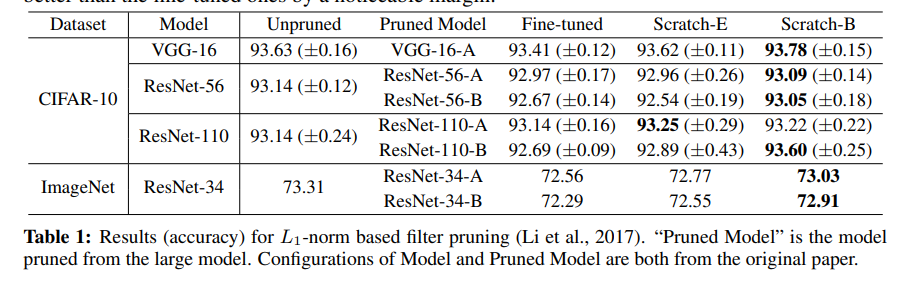
来源:https://arxiv.org/pdf/1810.05270v2.pdf
如下图显示,ThiNet 用贪婪方式对通道进行剪枝,剪掉的是对下一层激活值影响最小的那些通道。
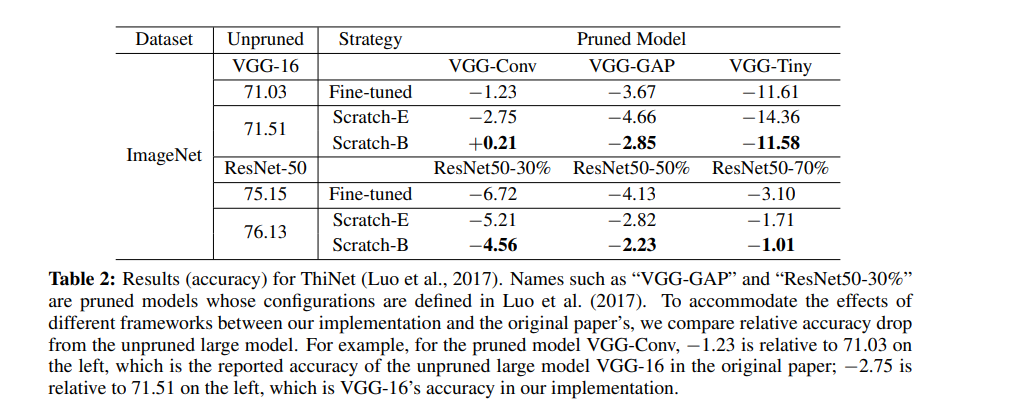
来源:https://arxiv.org/pdf/1810.05270v2.pdf
下一个表格显示了 Regression-based Feature Reconstruction 方法得到的结果。这个方法最小化下一层的特征图重建误差,以此来对通道剪枝。这个优化问题是通过 LASSO 回归来解决的。
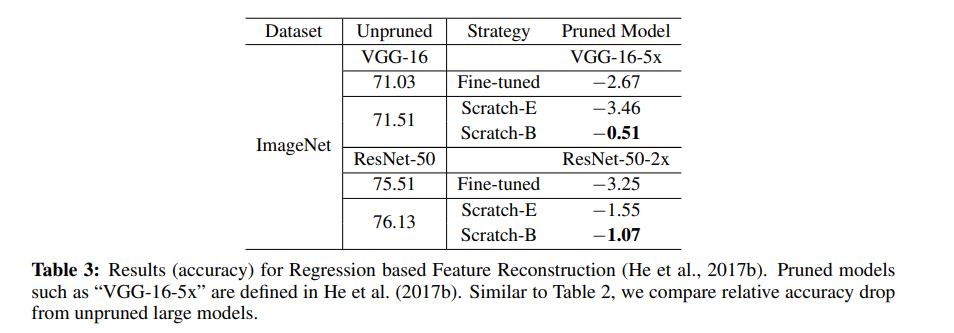
来源:https://arxiv.org/pdf/1810.05270v2.pdf
对于 Network Slimming 方法,在训练时,L1-sparsity 将 Batch Normalization 层的缩放因子施加在了每层通道上。训练完成之后,具有较低缩放因子的通道就会被裁剪掉。这个方法在不同层之间比较通道缩放因子,所以能够自动生成目标网络架构。
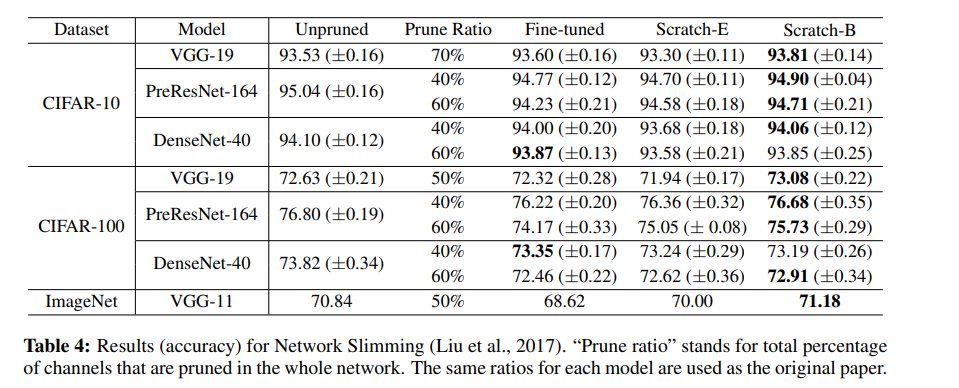
来源:https://arxiv.org/pdf/1810.05270v2.pdf
Network Pruning via Transformable Architecture Search(NeurIPS 2019)
这篇论文提出将神经网络搜索方法(https://heartbeat.fritz.ai/research-guide-for-neural-architecture-search-b250c5b1b2e5)直接应用于某个网络,在搜索空间内给这个网络设置不同的通道数和层大小。裁剪后网络的损失最小化有助于学习最终通道的数量。裁剪后网络的特征图是由 K 个基于概率分布采样的特征图片段组成。损失被反向传播到网络权重和参数化分布上。

论文网页:https://arxiv.org/abs/1905.09717v5
该论文方法根据每个分布的最大概率得到裁剪后网络的宽度和深度。这些参数是通过原始网络知识的转移来学习得到的。该论文在 CIFAR-10、CIFAR-100 和 ImageNet 数据集上对模型进行了实验。
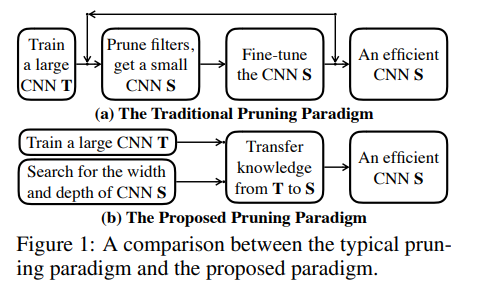
来源:https://arxiv.org/pdf/1905.09717v5.pdf
这个剪枝方法包含三个阶段:
用一个标准的分类训练过程,来训练一个未裁剪过的大型网络
通过可转移架构搜索(TAS:Transformable Architecture Search)方法来搜索小网络的深度和宽度。TAS 旨在搜索网络的最优大小。
通过简单的知识蒸馏(KD:Knowledge Distillation)方法将信息从未裁剪的网络转移至搜索到的小网络中。
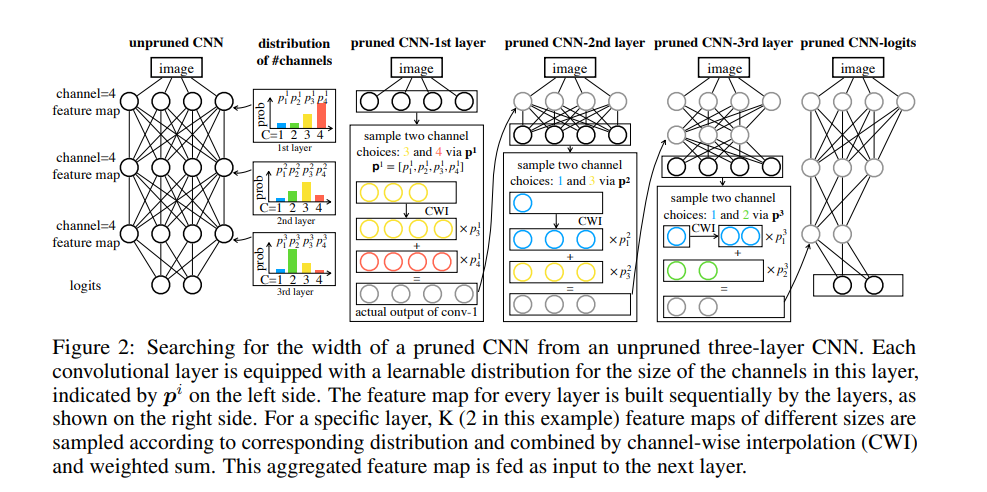
来源:https://arxiv.org/pdf/1905.09717v5.pdf
以下表格是在 ImageNet 数据集上,使用不同的 ResNets 网络和不同的剪枝算法的结果对比:
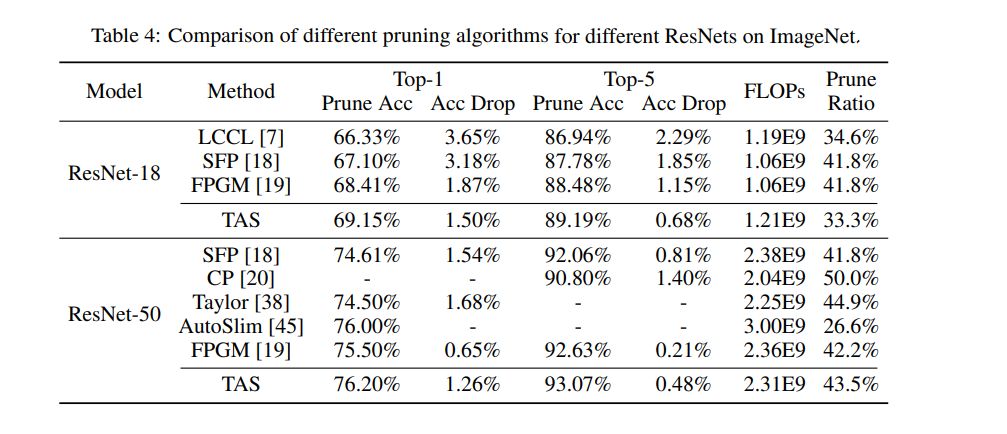
来源:https://arxiv.org/pdf/1905.09717v5.pdf
Self-Adaptive Network Pruning(ICONIP 2019)
这篇论文提出通过自适应网络剪枝方法(SANP:Self-Adaptive Network Pruning)来减少 CNN 网络的计算开销。这个方法为每一个卷积层都引入了一个显著性和裁剪模块(SPM:Saliency-and-Pruning Module)。这个模块学习预测显著性评分,并将剪枝方法用于每个通道。SANP 根据每层和每个样本来决定裁剪策略。

论文网页:https://arxiv.org/abs/1910.08906
正如在以下架构图里看到的那样,显著性和裁剪模块嵌入在卷积网络的每一层里。这个模块为通道预测显著性评分,这是从输入特征开始的,然后为每个通道生成裁剪方法。
卷积中对于裁剪值为 0 的通道,卷积会跳过这类通道不进行卷积。之后,对主干网络和 SPM 的分类代价目标函数进行联合训练。该方法会在每一层的裁剪决策基础上估计计算开销。
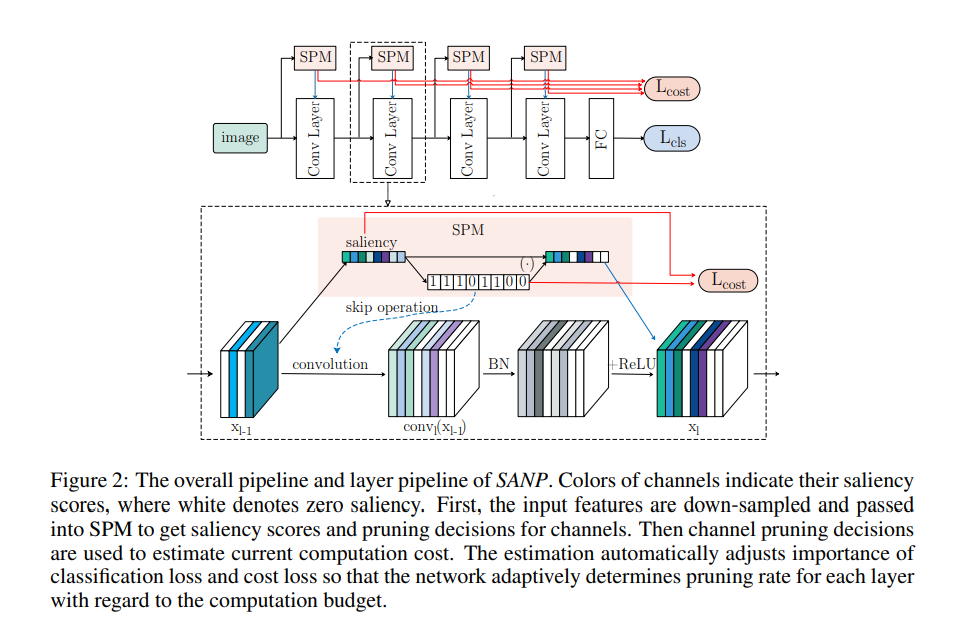
来源:https://arxiv.org/pdf/1910.08906.pdf)df/1910.08906.pdf
这个方法的实验结果显示如下:
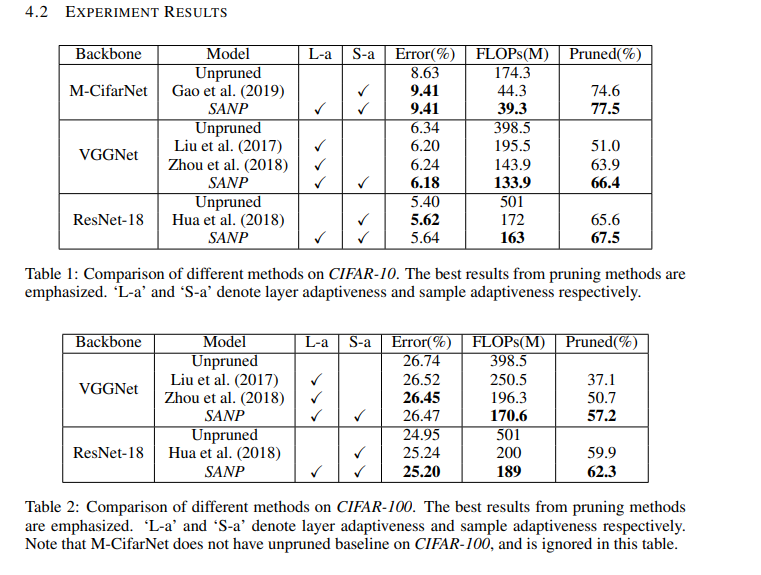
来源:https://arxiv.org/pdf/1910.08906.pdf
Structured Pruning of Large Language Models(2019)
这篇论文提出的剪枝方法基于低秩分解和增广拉格朗日 10 范式正则化(http://amsacta.unibo.it/1129/1/lagrange_methods.pdf)。10 范式正则化放宽了结构化剪枝的约束,而低秩分解可以保留矩阵的致密结构。

论文网页:https://arxiv.org/abs/1910.04732
正则化项可以让网络选择移除哪些权重。权重矩阵被分解为两个小矩阵,然后就可以确定这两个矩阵间的对角型掩码。在训练期间,通过 10 范式正则化给这个掩码剪枝,增广拉格朗日方法用来控制这个模型最终的稀疏程度。作者将其方法称为分解 L0 剪枝(FLOP:Factorized L0 Pruning)。
使用的字符级语言模型来自 enwik8 数据集,它包含 Wikipedia 上的 100 兆字节数据。该论文用 FLOP 方法在 SRU 和 Transformer-XL 模型上进行了评估。以下显示了一些实验结果数据。
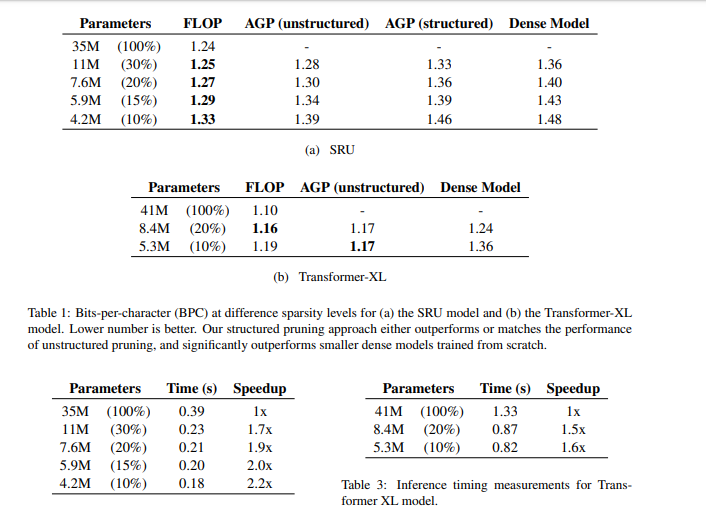
来源:https://arxiv.org/pdf/1910.04732.pdf
结语
我们现在应该了解了一些最常用的、最新的剪枝技术。以上提及链接的论文和摘要也包含了代码实现。
原文链接:
https://heartbeat.fritz.ai/research-guide-pruning-techniques-for-neural-networks-d9b8440ab10d

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论