

摘要:如今,为开发新产品和服务,许多公司纷纷开始关注实时数据流应用程序。企业必须首先了解不同事件流系统的优势和差异,才能选出与其业务需求最匹配的技术。基准测试是各企业比较和衡量不同技术性能的一种方法。为了使该测试有参考价值,必须准确开展测试,并输出准确的信息。遗憾的是,总有诸多因素会影响基准测试的准确性。
Confluent 最近开展了一次基准测试,对比 Kafka、Pulsar 和 RabbitMQ 的吞吐量和延迟差异。Confluent 博客显示,Kakfa 能够以“低延迟”实现“最佳吞吐量”,而 RabbitMQ 能够以“较低的吞吐量” 达到 “低延迟”。总体而言,基准测试结果显示 Kafka 在“速度”方面无疑更胜一筹。
Kafka 技术成熟完善,但当今众多公司(从跨国公司到创新型初创公司)还是首先选择了 Pulsar。在近期举办的 Splunk 峰会 conf20 上,Splunk 公司首席产品官 Sendur Sellakumar 对外宣布,他们决定用 Pulsar 取代 Kafka:
“...我们已把 Apache Pulsar 作为基础流。我们把公司的前途压在了企业级多租户流的长期架构上。”
-- Splunk 首席产品官 Sendur Sellakumar
很多公司都在使用 Pulsar,Splunk 只是其中一例。这些公司之所以选择 Pulsar,是因为在现代弹性云环境(如 Kubernetes)中,Pulsar 能够以经济有效的方式横向扩展处理海量数据,不存在单点失效的问题。同时,Pulsar 具有诸多内置特性,诸如数据自动重平衡、多租户、跨地域复制和持久化分层存储等,不仅简化了运维,同时还让团队更容易专注于业务目标。
开发者们最终选择 Pulsar 是因为 Pulsar 这些独特的功能和性能,让 Pulsar 成了流数据的基石。
了解了这些情况后,还需仔细研究 Confluent 的基准测试设置和结论。我们发现有两个问题存在高度争议。其一,Confluent 对 Pulsar 的了解有限,这正是造成结论不准确的最大根源。如不了解 Pulsar,就不能用正确的衡量标准来测试 Pulsar 性能。
其二,Confluent 的性能测试基于一组狭窄的测试参数。这限制了结果的适用性,也无法为读者提供不同工作负载和实际应用场景相匹配的准确结果。
为了向社区提供更准确的测试结果,我们决定解决这些问题并重复测试。重要调整包括:
我们调整了基准测试设置,包含了 Pulsar 和 Kafka 支持的各持久性级别,在同一持久性级别下对比两者的吞吐量和延迟。
我们修复了 OpenMessaging 基准测试(OMB)框架,消除因运用不同实例产生的变量,并纠正了 OMB Pulsar 驱动程序中的配置错误。
最后,我们测量了其他性能因素和条件,例如分区的不同数量和包含 write、tailing-read 和 catch-up read 的混合工作负载,更全面地了解性能。
完成这些工作之后,我们重复了测试。测试结果显示,对于更接近真实工作负载的场景,Pulsar 的性能明显优于 Kafka,而对于 Confluent 在测试中所应用的基本场景,Pulsar 性能与 Kafka 性能相当。
以下各部分将重点说明本次测试得出的最重要结论。在 StreamNative 基准测试结果章节,我们详细介绍了测试设置和测试报告。
StreamNative 基准测试结果概要
在与 Kafka 的持久性保证相同的情况下,Pulsar 可达到 605 MB/s 的发布和端到端吞吐量(与 Kafka 相同)以及 3.5 GB/s 的 catch-up read 吞吐量(比 Kafka 高 3.5 倍)。Pulsar 的吞吐量不会因分区数量的增加和持久性级别的改变而受到影响,而 Kafka 的吞吐量会因分区数量或持久性级别的改变而受到严重影响。
表 1:在不同工作负载及不同持久性保证下,Pulsar 与 Kafka 的吞吐量差异
在不同的测试实例(包括不同订阅数量、不同主题数量和不同持久性保证)中,Pulsar 的延迟显著低于 Kafka。Pulsar P99 延迟在 5 到 15 毫秒之间。Kafka P99 延迟可能长达数秒,并且会因主题数量、订阅数量和不同持久性保证而受到巨大影响。
表 2:在不同订阅数量及不同持久性保证下,Pulsar 与 Kafka 端到端 P99 延迟差异
表 3:在不同主题数量及不同持久性保证下,Pulsar 与 Kafka 端到端 P99 延迟差异
Pulsar 的 I/O 隔离显著优于 Kafka。在有消费者 catch up 读取历史数据时,Pulsar P99 发布延迟仍然在 5 毫秒左右。相比之下,Kafka 的延迟会因 catch up read 而受到严重影响。Kafka P99 发布延迟可能会从几毫秒增加到几秒。
表 4:在 catch up read 下,Pulsar 和 Kafka P99 发布延迟差异
我们所有的基准测试均开源(Github 网址:https://github.com/streamnative/openmessaging-benchmark),感兴趣的读者可以自行生成结果,也可更深入研究该测试结果及仓库中提供的指标。
尽管我们的基准测试比 Confluent 的基准测试更准确全面,但并未涵盖全部场景。归根结底,通过自己的硬件/实际工作负载进行的测试,是任何一个基准测试都替代不了的。我们也鼓励各位读者评估其他变量和场景,并利用自己的设置和环境进行测试。
深入探究 Confluent 基准测试
Confluent 将 OpenMessaging 基准测试(OMB)框架作为其基准测试的依据,并进行了一些修改。在本节中,我们将说明在 Confluent 基准测试中发现的问题,并阐述这些问题如何影响 Confluent 测试结果的准确性。
Confluent 的设置问题
Confluent 基准测试结论不正确是因为 Pulsar 参数设置不合理。我们会在 StreamNative 基准测试部分详细讲解这些问题。除了 Pulsar 调优问题,Confluent 针对 Pulsar 和 Kafka 设置了不同的持久性保证。持久性级别会影响性能,两个系统的持久性设置相同,对比才具有参考价值。
Confluent 工程师对 Pulsar 采用默认持久性保证,该保证比 Kafka 的持久性级别高。增加持久性级别会严重影响延迟和吞吐量,所以 Confluent 测试对 Pulsar 提出了比 Kafka 更高的要求。Confluent 使用的 Pulsar 版本尚不支持将持久性降低到与 Kafka 相同的级别,但 Pulsar 即将发布的版本支持该级别,在本次测试中也使用了该级别。如果 Confluent 工程师在两个系统上使用的持久性设置相同,那么测试结果显示的对比应该是准确的。我们当然不会因 Confluent 工程师未使用尚未发布的功能而指责他们。然而,测试记录并不能提供必要的情景,而且将其视为同等持久性设置的结果。本文会提供额外的情境说明。
OMB 框架问题
Confluent 基准测试遵循 OMB 框架指南,该指南建议在多个事件流系统中使用同一实例类型。但在测试中,我们发现同一类型的不同实例存在大量偏差,尤其是发生磁盘 I/O 故障的情况下。为了最大程度地减少这种差异,我们在每次运行 Pulsar 和 Kafka 时都使用了相同实例,我们发现这些实例在很大程度上改进了结果的准确性,磁盘 I/O 性能的微小差异可能会对系统整体性能造成较大差异。我们提议更新 OMB 框架指南,并在未来考虑采用这个建议。
Confluent 研究方法的问题
Confluent 基准测试仅测试了几种有限的场景。例如,实际工作负载包括写入、 tailing read 和 catch-up read。当某一消费者正在读取日志“尾部”附近的最新消息时,即发生 tailing-read,Confluent 只测试了这一种场景。相比之下,catch-up read 在消费者有大量历史消息时发生,必须消耗至 “catch-up” 位置到日志的尾部消息,这是实际系统中常见的关键任务。如果不考虑 catch-up read,则会严重影响写入和 tailing read 的延迟。由于 Confluent 基准测试只关注吞吐量和端到端延迟,所以未能就各种工作负载下的预期行为提供全面结果。为了进一步让结果更接近实际应用场景,我们认为对不同数量的订阅和分区进行基准测试至关重要。很少有企业只关心具有几个分区和消费者的少量主题,他们需要有能力容纳具有不同主题/分区的大量不同消费者,以映射到业务用例中。
我们在下表中概述了 Confluent 研究方法的具体问题。
表 5:Confluent 基准测试研究方法的问题
Confluent 基准测试的诸多问题源于对 Pulsar 的了解有限。为帮助大家后续开展基准测试时避免这些问题,我们和大家分享一些 Pulsar 技术见解。
为了开展准确的基准测试,需了解 Pulsar 的持久性保证。我们将以此问题作为切入点进行探讨,先总体概述分布式系统的持久性,然后说明 Pulsar 和 Kafka 在持久性保证上的差异。
分布式系统持久性概述
持久性是指在面对诸如硬件或操作系统故障等外部问题时,对系统一致性和可用性的维持能力。诸如 RDBMS 单节点存储系统依靠 fsync 写入磁盘来确保最大的持久性。操作系统通常会缓存写入,在发生故障时,写入可能会丢失,但 fsync 将确保将这些数据写入物理存储中。在分布式系统中,持久性通常来自数据复制,即将数据的多个副本分布到可独立失效的不同节点。但不应将本地持久性(fsync 数据)与复制持久性混为一谈,两者目的不同。接下来我们会解释这些特性的重要性及主要区别。
复制持久性和本地持久性
分布式系统通常同时具备复制持久性和本地持久性。各种类型的持久性由单独的机制控制。可以灵活组合使用这些机制,根据需要设置不同的持久性级别。
复制持久性通过一种算法创建数据的多个副本实现,所以同一数据可存储在多个位置,可用性和可访问性均得以提高。副本的数量 N 决定了系统的容错能力,很多系统需要“仲裁”或 N/2 + 1 个节点来确认写入。在任何单个副本仍然可用的情况下,一些系统可以继续服务现有数据。这种复制机制对于处理彻底丢失实例数据至关重要,新实例可从现有副本中重新复制数据,这对可用性和共识性也至关重要(本节不展开探讨该问题)。
相比之下,本地持久性决定了各个节点级别对确认的不同理解。本地持久性要求把数据 fsync 到持久存储,确保即使发生断电或硬件故障,也不会丢失任何数据。数据的 fsync 可确保机器在短时间内出现故障恢复后,节点拥有先前确认的全部数据。
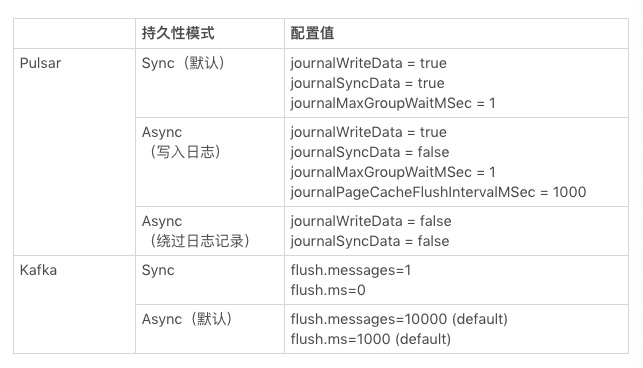
持久性模式:同步和异步
不同类型的系统提供不同级别的持久性保证。通常,系统的整体持久性受以下因素影响:
系统是否将数据 fsync 到本地磁盘
系统是否将数据复制到多个位置
系统何时确认复制到对等系统
系统何时确认写入客户端
在不同的系统中,这些选择差异很大,并非所有系统都支持用户控制这些值。缺少其中某些机制的系统(例如非分布式系统中的复制),持久性更低。
我们可以定义两种持久性模式,两者均可控制系统何时确认写入供内部复制,以及何时 写入到客户端,即“同步”和“异步”。这两种模式操作如下。
同步持久性:仅在数据成功 fsync 到本地磁盘(本地持久性)或复制到多个位置(复制持久性)后,系统才向对等系统/客户端返回写入响应。
异步持久性:在数据成功 fsync 到本地磁盘(本地持久性)或复制到多个位置(复制持久性)前,系统会向对等系统/客户端返回写入响应。
持久性级别:测量持久性保证
持久性保证以多种形式存在,这取决于以下变量:
数据是否存储在本地,是否在多个位置复制或符合这两种情况
何时确认写入(同步/异步)
与持久性模式一样,为区分不同的分布式系统,我们为持久性定义了四个级别。表 6 列出了从最高持久性到最低持久性的各个级别。
表 6:分布式系统的持久性级别
多数分布式关系数据库管理系统(例如 NewSQL 数据库)均可保证最高级别的持久性,所以将这类系统归为 1 级。
与数据库一样,Pulsar 属于 1 级系统,默认提供最高级别的持久性。此外,Pulsar 可针对每种应用分别自定义所需的持久性级别。相比之下,Kafka 大部分的生产环境部署都配置在 2 级或 4 级。据悉,通过设置 flush.messages=1 和 flush.ms=0,Kafka 也能达到 1 级标准。但这两项配置会严重影响吞吐量和延迟,我们会在基准测试中详细讨论这个问题。
下面我们从 Pulsar 入手,详细探究各系统的持久性。
Pulsar 的持久性
Pulsar 提供各级别的持久性保证,可将数据复制到多个位置,并将数据 fsync 到本地磁盘。Pulsar 拥有两种持久性模式(即上文所述的同步和异步)。用户可以根据使用场景自定义设置,单独使用某一模式,或组合使用。
Pulsar 利用筏等效、基于仲裁的复制协议来控制复制的持久性。通过调整 ack-quorum-size 和 write-quorum-size 参数可以调整复制持久性模式。表 7 列出了这些参数的设置,表 8 列出了 Pulsar 支持的持久性级别。(Pulsar 复制协议和共识算法不属于本文探讨范围,我们会在后续的博客中深入探讨该领域。)
表 7:Pulsar 持久性配置设置
表 8:Pulsar 持久性级别
Pulsar 通过向日志磁盘写入和(或)fsync 数据来控制本地持久性。Pulsar 还提供选项,通过表 9 中的配置参数来调整本地持久性模式。
表 9:Pulsar 本地持久性模式参数
Kafka 的持久性
Kafka 提供 3 种持久性级别:1 级,2 级(默认设置)和 4 级。Kafka 在 2 级提供复制持久性,在 4 级无法提供持久性保证,因为不具备在确认写入之前将数据 fysnc 到磁盘的能力。通过设置 flush.messages=1 和 flush.ms=0,Kafka 可以达到 1 级系统级别,但 Kafka 几乎没有在生产环境部署过这种配置。
Kafka 的 ISR 复制协议控制复制持久性。通过调整与此协议关联的 acks 和 min.insync.replicas 参数,可以调整 Kafka 的复制持久性模式。表 10 列出了这些参数的设置。表 11 列出了 Kafka 支持的持久性级别。(有关 Kafka 复制协议的详细说明不属于本文探讨范围,我们将在后续博客中深入挖掘 Kafka 协议和 Pulsar 协议的差异。)
表 10:Kafka 的持久性配置设置
表 11:Kafka 持久性级别
与 Pulsar 不同,Kafka 不会将数据写入单独的日志磁盘。Kafka 会先确认写入操作,再将数据 fsync 到磁盘。这种操作可最大程度减少写入和读取之间的 I/O 争用,并防止性能降低。
通过对每条消息设置 flush.messages = 1 和 flush.ms = 0,Kafka 可以提供 fsync 功能,并且大大降低消息丢失的可能性,但这样会严重影响吞吐量和延迟。因此,这种设置几乎从未用于生产环境部署。
Kafka 无法传输日志数据,如果遇到机器故障或断电,就有丢失数据的风险。这个缺陷很明显,影响很大,这也是腾讯计费系统选用 Pulsar 的主要原因之一。
Pulsar 和 Kafka 在持久性方面的差异
Pulsar 的持久性设置灵活,用户可根据具体需要,优化持久性设置,满足各个应用程序、应用场景或硬件配置的要求。
Kafka 灵活性较差,根据场景限制,不能确保在两个系统中的持久性设置相同。这样就比较难进行基准测试。为解决这一问题,OMB 框架建议使用最接近的可用设置。
了解了这些背景后,我们来看看 Confluent 基准测试中的问题。Confluent 尝试模拟 Pulsar 的 fsync 行为,在他们的基准测试中,Confluent 为 Kafka 设置了异步持久性功能,为 Pulsar 设置了同步持久性功能。这种不对等导致测试结果不正确,作出的性能判断也有失偏颇。我们的基准测试显示,Pulsar 与 Kafka 性能匹敌甚至超过 Kafka,同时 Pulsar 还提供更强的持久性保证。
StreamNative 基准测试
为了更准确了解 Pulsar 性能,我们需要使用 Confluent 基准测试来解决这些问题。我们将焦点放在调整 Pulsar 的配置上,确保两个系统的持久性设置相同,并纳入其他性能因素和条件,例如不同的分区数量和混合工作负载,从而测量不同应用场景下的性能。在下面的章节我们会详细说明我们测试中的配置调整。
StreamNative 测试设置
我们的基准测试设置囊括 Pulsar 和 Kafka 支持的全部持久性级别。这样,我们才可对同一持久性级别下的吞吐量和延迟进行比较。我们使用的持久性设置如下。
复制持久性设置
我们的复制持久性设置与 Confluent 相同,未做任何变动,为保持完整性,此处沿用表 12 所列的设置。
表 12:复制持久性设置
Pulsar 新特性(新特性:https://github.com/apache/bookkeeper/pull/2401)为应用程序提供了跳过日志记录的选项,从而放宽了本地持久性保证,避免了写入放大,提高了写入吞吐量。(该特性在下一版 Apache BookKeeper 提供)。我们没有把它设置成默认特性,因为还是有可能丢失消息,所以并不建议在大多数场景下使用。
为确保两种系统性能对比准确,我们在基准测试中使用了该特性。绕过 Pulsar 的日志记录可提供与 Kafka 默认 fsync 设置相同的本地持久性保证。
Pulsar 的新特性包括本地持久性模式(Async - Bypass journal)。 我们利用此模式配置 Pulsar,保持与 Kafka 本地持久性默认级别相匹配。表 13 列出了基准测试的具体设置。
StreamNative 框架
我们在 Confluent OMB 框架分支 发现了一些问题,并修复了 OMB Pulsar 驱动程序中的一些配置错误。我们开发了新的基准测试代码(包括下述修复程序),都放在开源仓库中。
修复 OMB 框架问题
Confluent 遵循 OMB 框架建议,利用两套实例— 一套用于 Kafka,一套用于 Pulsar。在我们的基准测试中,我们分配了一组三个实例来增强测试的可靠性。在首个测试中,我们在 Pulsar 上运行了三个实例。然后利用同一组实例对 Kafka 进行同样的测试。
我们使用同一台机器对不同系统进行基准测试,在每次运行前都清除文件系统页面缓存,确保当前的测试不受到此前测试的影响。
修复 OMB Pulsar 驱动程序配置问题
我们修复了 Confluent 的 OMB Pulsar 驱动程序配置中的许多错误。以下各节将介绍我们对 broker、bookie、生产者、消费者和 Pulsar image 所作的具体调整。
调整 Broker 配置
Pulsar broker 利用 managedLedgerNewEntriesCheckDelayInMillis 参数,确定 catch-up 订阅在向其消费者分发消息前必须等待的时长(以毫秒为单位)。在 OMB 框架中,此参数的值设置为 10,这是 Confluent 基准测试结论不准的主要原因,Confluent 基准测试结论是 Pulsar 延迟比 Kafka 高。我们将该值更改为 0, 模拟 Kafka 在 Pulsar 上的延迟行为。更改后,所有测试场景中,Pulsar 的延迟都显著低于 Kafka。
为了优化性能,我们将 bookkeeperNumberOfChannelsPerBookie 参数值从 16 增加到 64,防止 broker 和 bookie 之间的任何单个 Netty 渠道成为瓶颈。当 Netty IO 队列中堆积大量消息时,该瓶颈会导致高延迟。
我们将在 Pulsar 文档中提供更清晰的指南,帮助用户优化端到端的延迟。
调整 Bookie 配置
我们为 Bookie 添加了新的配置,在绕过日志记录时测试 Pulsar 性能。Pulsar 和 Kafka 持久性保证势均力敌。
为测试该特性的性能,我们基于 Pulsar 2.6.1 官方发行版构建了自定义镜像,涵盖了该调整。(详情查看 Pulsar Image。)
我们手动配置了以下设置绕过 Pulsar 中的日志记录。
此外,我们将 journalPageCacheFlushIntervalMSec 参数的值从 1 改成 1000,在 Pulsar 中对异步本地持久化进行基准测试(journalSyncData = false)。将该值调高后,Pulsar 可按如下所述模拟 Kafka 的刷写行为。
Kafka 通过将文件系统页面缓存刷写到磁盘来确保本地持久性。数据由一组称为 pdflush 的后台线程刷写。可以设置 Pdflush,两次刷写之间的等待时长通常设置为 5 秒。将 Pulsar 的 journalPageCacheFlushIntervalMSec 参数设置为 1000,相当于 Kafka 上的 5 秒 pdflush 间隔。更改后,我们即可更精确地对异步本地持久性进行基准测试,并对 Pulsar 和 Kafka 进行更准确的比较。
调整生产者配置
我们的批处理配置与 Confluent 相同,但有一个例外:即我们增加了切换间隔,使其比批处理间隔更长。具体来说,我们将 batchingPartitionSwitchFrequencyByPublishDelay 参数值从 1 更改为 2。这一更改确保 Pulsar 的生产者在每个批处理期间仅集中于一个分区。
将切换间隔和批处理间隔设置为相同的值会导致 Pulsar 频繁切换分区,产生过多的小规模批处理,并可能影响吞吐量。把切换间隔设置大于批处理间隔,可最大程度降低这种风险。
调整消费者配置
当应用程序无法快速处理传入消息时,Pulsar 客户端利用接收方队列施加反压。消费者接收方队列的规模会影响端到端延迟。与规模较小的队列相比,规模较大的队列可以预取和缓存更多消息。
这两项参数确定接收方队列的规模:receiverQueueSize 和 maxTotalReceiverQueueSizeAcrossPartitions。Pulsar 按下述方式计算接收方队列规模:
Math.min(receiverQueueSize, maxTotalReceiverQueueSizeAcrossPartitions / number of partitions)
例如,如果将 maxTotalReceiverQueueSizeAcrossPartitions 设置为 50000,当有 100 个分区时,Pulsar 客户端会在每个分区上将消费者的接收方队列规模设置为 500。
在我们的基准测试中,maxTotalReceiverQueueSizeAcrossPartitions 从 50000 增加到 5000000。这种调优确保了消费者不会施加反压。
Pulsar image
我们构建了自定义的 Pulsar 版本(v.2.6.1-sn-16),其中包括上文所述的 Pulsar 和 BookKeeper 修复。2.6.1-Sn-16 版本基于 Pulsar 2.6.1 官方发行版本,可从 https://github.com/streamnative/pulsar/releases/download/v2.6.1-sn-16/apache-pulsar-2.6.1-sn-16-bin.tar.gz 下载。
StreamNative 测试方法
我们调整了 Confluent 基准测试的测试方法,通过实际工作负载全面了解性能。具体对测试作了如下调整:
为评估以下内容,添加了 catch-up read
处理 catch-up read 时,每个系统可达到的最大吞吐量
写入如何影响发布和端到端延迟
更改分区数量,查看每个更改如何影响吞吐量和延迟
更改订阅数量,查看每个更改如何影响吞吐量和延迟
我们的基准测试场景测试了下述各类工作负载:
最大吞吐量:各系统可达到的最大吞吐量?
发布与 Tailing Read 延迟:各系统在给定的吞吐量下可达到的最低发布和端到端拖延延迟?
Catch-up read: 从大量待办事项中读取消息时,各系统可实现的最大吞吐量?
混合工作负载:消费者执行 catch-up 操作时,每个系统可以实现的最低发布和端到端拖延延迟级别是多少?Catch-up read 如何影响发布延迟和端到端拖延延迟?
Testbed
OMB 框架建议,对于实例类型和 JVM 配置,使用特定的 testbed 定义;对于生产者、消费者和服务器端,使用工作负载驱动程序配置。我们的基准测试使用了与 Confluent 相同的 testbed 定义。关于这些 testbed 定义,可查看 Confluent OMB 仓库中 StreamNative 分支 。
下面将重点介绍我们所观察到的磁盘吞吐量和磁盘 fsync 延迟。要解释基准测试结果,必须考虑这些硬件指标。
磁盘吞吐量
我们的基准测试采用与 Confluent 相同的实例类型,具体为 i3en.2xlarge (带 8 个 vCore,64 GB RAM,2 x 2、500 GB NVMe SSD)。我们确认 i3en.2xlarge 实例可支持两个磁盘间高达 655 MB/s 的写入的吞吐量。请参阅下文 dd 结果。
磁盘数据同步延迟
在进行延迟相关测试时,重要的是捕获 NVMe SSD 上的 fsync 延迟。我们观察到,这 3 个实例的 P99 fsync 延迟在 1 毫秒到 6 毫秒之间,如下图所示。如前所述,不同情况下磁盘发生很大差异,主要体现在该延迟中,我们发现有一组实例延迟一致。
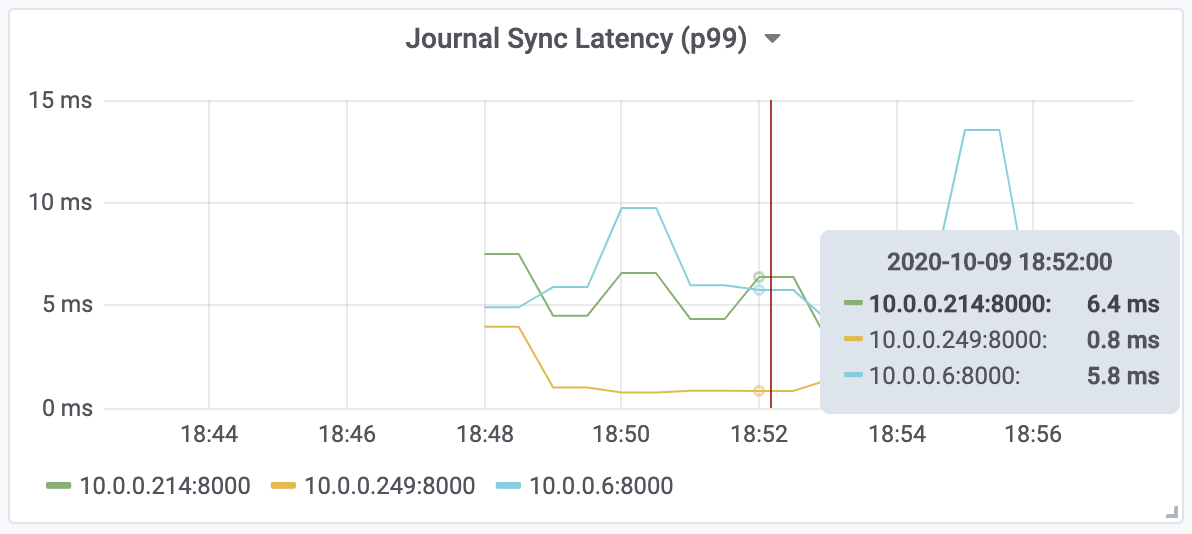
图 1-1:3 个不同实例的 P99 fsync 延迟
StreamNative 基准测试结果
下文将总结我们的基准测试结果。如需查看完整的基准测试报告,可以在 StreamNative 官网下载或者在 openmessaging-benchmark 仓库查看。
最大吞吐量测试
最大吞吐量测试旨在确定在处理不同持久性保证的工作负载(包括发布和 tailing-read)时,各系统可实现的最大吞吐量。我们更改了主题分区的数量,查看每个更改如何影响最大吞吐量。
我们发现:
将持久性保证(同步复制持久性,同步本地持久性)配置为 1 级时,Pulsar 的最大吞吐量约为 300 Mb/s ,这是日志磁盘带宽的物理极限。有 100 个分区时,Kafka 可达到 420 MB/s 左右。值得注意的是,在持久性为 1 级时,Pulsar 配置为一个磁盘用作日志磁盘进行写入,另一个磁盘用作 ledger 磁盘进行读取;而 Kafka 同时使用两个磁盘进行读取和写入。尽管 Pulsar 的设置能够提供更好的 I/O 隔离,但其吞吐量也受单个磁盘最大带宽(〜300 MB/s)的限制。为 Pulsar 配置备用磁盘,能够实现更具成本效益的运行。此议题会在后续博客中探讨。
当将持久性(同步复制持久性和异步本地持久性)配置为 2 级时,Pulsar 和 Kafka 均可达到约 600 MB/s 的最大吞吐量。两个系统都达到了磁盘带宽的物理极限。
Kafka 在一个分区上的最大吞吐量仅为 Pulsar 最大吞吐量的二分之一。
Pulsar 的吞吐量不会因更改分区数量而受到影响,但 Kafka 的吞吐量会受到影响。
当分区数量从 100 增加到 2000 时,Pulsar 保持了最大吞吐量(在 1 级持久性保证下约为 300 MB/s,在 2 级持久性保证下约为 600 MB/s)。
当分区数量从 100 个增加到 2000 个时,Kafka 的吞吐量下降一半。
发布和端到端延迟测试
发布和端到端延迟测试旨在确定在处理不同持久性保证的工作负载(包括发布和 tailing-read)时,各系统可实现的最低延迟。我们修改了订阅数量和分区数量,以了解每个更改如何影响发布和端到端延迟。
我们发现:
在所有测试用例中,Pulsar 的发布和端到端延迟都显著(数百倍)低于 Kafka,这评估出了各种持久性保证以及不同数量的分区和订阅。即使分区数量从 100 增加到 10000 或订阅数量从 1 增加到 10,Pulsar P99 发布延迟和端到端延迟都在 10 毫秒之内。
订阅数量和分区数量变化会对 Kafka 的发布和端到端延迟产生巨大影响。
当订阅数量从 1 增加到 10 时,发布和端到端延迟均从约 5 毫秒增加到约为 13 秒。
当主题分区数量从 100 增加到 10000 时,发布和端到端延迟都从约 5 毫秒增加到约 200 秒。
Catch-up read 测试
Catch-up read 测试旨在确定在处理仅包含 catch-up read 的工作负载时各系统可实现的最大吞吐量。测试开始时,生产者以每秒 200K 的固定速率发送消息。生产者发送了 512GB 数据后,消费者开始读取收到的消息。消费者处理了累积消息,当生产者继续以相同速度发送新消息时,消费者可以和生产者保持同步。
处理 catch-up read 时,Pulsar 的最大吞吐量比 Kafka 快 3.5 倍。 Pulsar 的最大吞吐量为 3.5 GB/s(350 万条消息/秒),而 Kafka 的吞吐量仅为 1 GB/s(100 万条消息/秒)。
混合工作负载测试
混合工作负载测试旨在确定 catch-up read 对混合工作负载中的发布和 tailing read 的影响。在测试开始时,生产者以每秒 200K 的固定速率发送消息,而消费者以 tailing 模式消费消息。生产者产生 512GB 消息后,将启动一组新的 catch-up 消费者,从头开始读取所有消息。同时,生产者和现有的 tailing-read 消费者继续以相同的速度发布和使用消息。
我们使用不同的持久性设置对 Kafka 和 Pulsar 进行了测试,发现 catch-up read 会严重影响 Kafka 的发布延迟,但对 Pulsar 的影响很小。Kafka P99 发布延迟从 5 毫秒增加到 1-3 秒,而 Pulsar P99 发布延迟保持在几毫秒到数十毫秒之间。
结论
基准测试通常仅呈现业务逻辑和配置选项的狭窄组合,可能反映或不反映实际应用场景或最佳实践,这是基准测试比较棘手的部分。基准测试可能会因其框架、设置和研究方法的问题而有失偏颇。我们在 Confluent 最近的基准测试中发现了这些问题。
应社区要求,StreamNative 团队着手开展该基准测试,从而就 Pulsar 的真实性能提供见解和看法。为了使基准测试更加准确,我们修复了 Confluent 基准测试中存在的问题,同时添加了新的测试参数,帮助我们深入探究各技术在真实用例中的对比结果。
根据我们的基准测试结果,在同一持久性保证下,在类似真实应用场景的工作负载中,Pulsar 性能超过 Kafka;在 Confluent 应用的同样有限测试用例中,Pulsar 可达到与 Kafka 相同的端到端吞吐量。此外,在每个不同的测试实例(包括不同的订阅数量、主题数量和持久性保证)中,Pulsar 的延迟优于 Kafka, 并且 I/O 隔离也比 Kafka 更好。
如前所述,任何一个基准测试均不能代替各自硬件上按真实工作负载所做的测试。我们鼓励读者使用自己的设置和工作负载来测试 Pulsar 和 Kafka,以了解每个系统在特定生产环境中的性能。如果你对 Pulsar 最佳实践有任何疑问,请直接联系我们或随时加入 Pulsar Slack。
未来几个月,我们会发布一系列博客,帮助社区更好地理解并利用 Pulsar 满足各自业务需求。我们会介绍 Pulsar 在不同工作负载和设置中的性能,介绍如何在不同的云提供商和本地环境中选择和调整硬件大小,以及如何利用 Pulsar 构建最具成本效益的流媒体平台。
作者简介:
郭斯杰,StreamNative 联合创始人兼 CEO。郭斯杰从事消息和流数据行业十多年,是消息和流数据资深专家。在创立 StreamNative 前,他联合创办过 Streamlio 公司,专注实时解决方案。他曾任 Twitter 消息基建团队技术负责人,联合创建了 DistributedLog 和 Twitter EventBus。在雅虎任职期间,他带领团队开发了 BookKeeper 和 Pulsar。他是 Apache BookKeeper 副总裁和 Apache Pulsar PMC 成员。
李鹏辉,StreamNative 软件工程师,Apache Pulsar Committer/PMC 成员。李鹏辉曾任职智联招聘,期间他作为主要推动者将 Apache Pulsar 落地智联招聘。他的工作经历始终围绕消息系统和微服务,目前已全力投入到 Pulsar 的世界中。
参考链接:
StreamNative 基准测试报告:https://github.com/streamnative/openmessaging-benchmark/blob/master/blog/benchmarking-pulsar-kafka-a-more-accurate-perspective-on-pulsar-performance.pdf
StreamNative 基准测试 Github 地址:https://github.com/streamnative/openmessaging-benchmark
腾讯计费系统为何选择使用 Pulsar :https://mp.weixin.qq.com/s/hyg79Q5pzDP6-PZXG72TUQ
Pulsar image 下载地址:https://github.com/streamnative/pulsar/releases/download/v2.6.1-sn-16/apache-pulsar-2.6.1-sn-16-bin.tar.gz
OpenMessaging 基准测试(OMB)框架:http://openmessaging.cloud/docs/benchmarks/

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论 2 条评论